First, the acquaintance file operations.
Introduction:
Now this world, if you can operate all software files are gone, such as word, wps, etc., then your friend sent me qq give you a file, the file name is: beautiful models stewardess nurse Contact .txt, All the boys here, then after you receive this document, your heart whether there is a trace of impulse, of course, they are not the kind Mensao people, in fact, we are more curious, just want to see what is written inside, only nothing more, never touch. But I can say that all file operations software all gone, then you are not 100 claws scratching heart, frantically, Oh. Do not worry Yeah, you forget it? Did you learn Python as a programming language, this language can certainly control functions of the file. I believe in this powerful force, you can, must be able to learn.
Now, I assume, now allows you to use Python to develop a software to manipulate the file, you need to think what parameters you need it?
File Path : D: \ beautiful models stewardess nurse Contact .txt (the file you want to operate, we must know the location of this file)
Encoding : utf-8, gbk, gb2312 .... ( yesterday just finished coding, in fact, file data storage, data storage you need to know the encoded data is stored in what coding)
Operating modes : read-only, write-only, append, read write, read and write ....


The computer system is divided into: three parts, computer hardware, operating systems, applications. We use python or applications written in other languages if you want to put down permanent preservation of data must be stored in the hard disk, which involves the application to operate the hardware is well known, the application can not access the hardware directly, which use to the operating system. Operating system, the complex hardware manipulation packaged into a simple interface to the user / application uses, wherein the file is an operating system to the application program operates the hard disk virtual concept, the user or application program by operating the file, you can be their own data permanently preserved .
At this point you need to use software to create a file, which just write something, and then stored in any disk (as much as possible path is simpler) in.
Then create a py file, using the Python code to open the file.
f = open ( 'd: \ young woman nurse LORI .txt', MODE = 'R & lt', encoding = 'UTF-. 8') Content reached, f.read = () Print (Content) f.close () Result: Title is it is good
Next is the explanation of the above code:
F: is a variable, it will typically be written f, f_obj, file, f_handler, fh, and the like, it is called a file handle.
open: is the operating system (windows, linux, etc.) call the Python function.
'd: \ young woman nurse LORI .txt': This is the path to the file.
mode: Define your mode of operation is: r read mode.
encoding: not a specific encoding or decoding, he is the statement: what encoding the file open this use. In general: your files saved what encoding, opened in what ways, usually with utf-8 (some using gbk).
f.read (): You want to manipulate files, such as reading a file, write to the file content, etc., must be operated by a file handle.
close (): close the file handle (file handle can be understood as a space, the existence of this space in memory, we must take the initiative to shut down).
With the concept of files, we do not need to go to consider details of the operation of the hard drive, just need to focus on the process of file operations:
# 1 Open a file, obtain the file handle and assignment to a variable f = open ( 'a.txt', 'r', encoding = 'utf-8') # default open mode is on the R & lt # 2. By the file handle operating Data = reached, f.read () #. 3. Close file f.close ()
Practice the above code, possible problems:
1. path problem.

This file is not found, it is likely that your file path wrong.
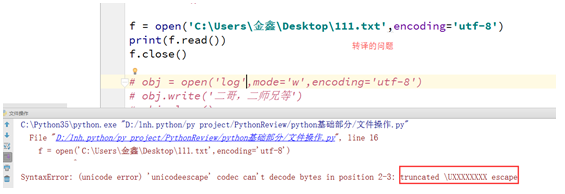
Your path inside the \ character and later had some kind of 'chemical reaction', this screenshot \ D at this time \ is not a path separator, \ D will have a special meaning, in fact, with \ t, \ n, line breaks as well, so for this situation, you should be resolved:
A solution: 'C: \\ Users \ Jinxin \ Desktop \\ 111.txt' Wherever the path of a chemical reaction occurs, one more \ this is in front of \ on the back of \ translates, tells the computer that just want a simple It represents \ path only.
Two solutions : r'C: \\ Users \ jinxin \ Desktop \\ 111.txt 'in front of the path of a whole plus r. ( Recommended )
Relative path and absolute path:
1. absolute path: starting from the root directory of the disk until the file name
2. Relative path: a file folder, file relative to the current program is located in the same terms if a file is relatively Road King is the file name if we have to use up one folder under ../ relative path, you can write directly to the file name.
2. The coding problem

The problem is that when you open coding and encoding files stored with this encoding inconsistencies caused. For example, when the file was saved with the word software, word software default encoding is utf-8, but when you use python code is open, with the gbk, then this will be the error.
Operation mode file operations are divided into three categories: read, write, append. Each category there are some specific method, then the next we classification of these methods.
Second file operations: reading
2.1 r mode
Opened read-only file, the file pointer will be placed at the beginning of the file. It is the most frequently used mode of operation is the default mode, if a file is not set mode, then the default mode of operation using the r file.
for example:
f = open ( 'path1 / small child .txt', MODE = 'R & lt', encoding = 'UTF-. 8') MSG reached, f.read = () f.close () Print (MSG) Results: High round Yifei Cecilia Yang Zi Faye
Can be seen by the above example, the contents of my little baby all read this document out, then read how a file can read it? Here we look at different methods of reading the file.
The Read 2.1.1 ()
the Read () to read the contents of files all out; drawbacks if the file will be very large memory footprint, easily lead to memory Ben collapse.
f = open ( 'path1 / small child .txt', MODE = 'R & lt', encoding = 'UTF-. 8') MSG reached, f.read = () f.close () Print (MSG) Results: High round Yifei Cecilia Yang Zi Faye
2.1.2 read(n)
When read () Reads a specified what position to read
In the mode r, n in accordance with the character read.
f = open('path1/小娃娃.txt',mode='r',encoding='utf-8')
msg = f.read(3)
msg1 = f.read()
f.close()
print(msg)
print(msg1)
结果:
高圆圆
刘亦菲
张柏芝
杨紫
王菲
2.1.3 readline()
readline()读取每次只读取一行,注意点:readline()读取出来的数据在后面都有一个\n
f = open('path1/小娃娃.txt',mode='r',encoding='utf-8')
msg1 = f.readline()
msg2 = f.readline()
msg3 = f.readline()
msg4 = f.readline()
f.close()
print(msg1)
print(msg2)
print(msg3)
print(msg4)
结果:
高圆圆
刘亦菲
张柏芝
杨紫
解决这个问题只需要在我们读取出来的文件后边加一个strip()就OK了
f = open('path1/小娃娃.txt',mode='r',encoding='utf-8')
msg1 = f.readline().strip()
msg2 = f.readline().strip()
msg3 = f.readline().strip()
msg4 = f.readline().strip()
f.close()
print(msg1)
print(msg2)
print(msg3)
print(msg4)
结果:
高圆圆
刘亦菲
张柏芝
杨紫
2.1.4 readlines()
readlines() 返回一个列表,列表里面每个元素是原文件的每一行,如果文件很大,占内存,容易崩盘。
f = open('log',encoding='utf-8')
print(f.readlines())
f.close()
# 结果['666666\n', 'fkja l;\n', 'fdkslfaj\n', 'dfsflj\n', 'df;asdlf\n', '\n', ]
上面这四种都太好,因为如果文件较大,他们很容易撑爆内存,所以接下来我们看一下第五种:
2.1.5 for循环
可以通过for循环去读取,文件句柄是一个迭代器,他的特点就是每次循环只在内存中占一行的数据,非常节省内存。
f = open('../path1/弟子规',mode='r',encoding='utf-8')
for line in f:
print(line) #这种方式就是在一行一行的进行读取,它就执行了下边的功能
print(f.readline())
print(f.readline())
print(f.readline())
print(f.readline())
f.close()
注意点:读完的文件句柄一定要关闭
2.2 rb模式
rb模式:以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。记住下面讲的也是一样,带b的都是以二进制的格式操作文件,他们主要是操作非文字文件:图片,音频,视频等,并且如果你要是带有b的模式操作文件,那么不用声明编码方式。
可以网上下载一个图片给同学们举例:
当然rb模式也有read read(n) readline(),readlines() for循环这几种方法,我在这就不一一演示了。
三. 文件操作:写
第二类就是写,就是在文件中写入内容。这里也有四种文件分类主要四种模式:w,wb,w+,w+b,我们只讲w,wb。
3.1 w模式
如果文件不存在,利用w模式操作文件,那么它会先创建文件,然后写入内容.
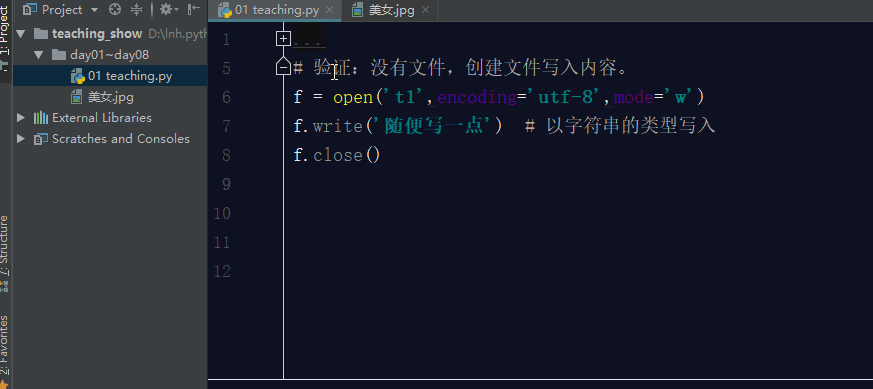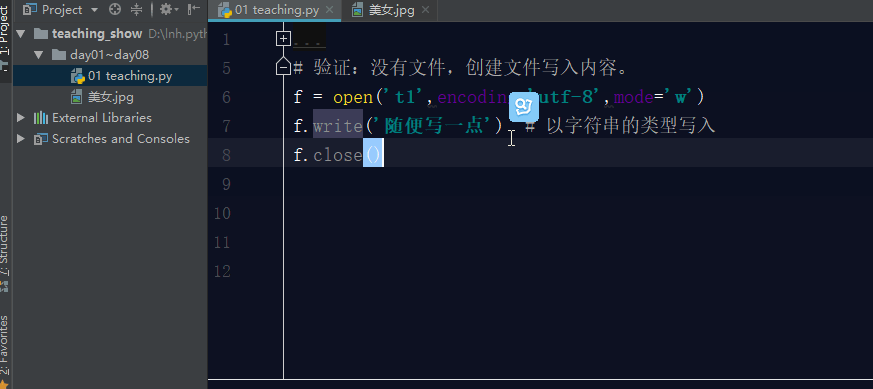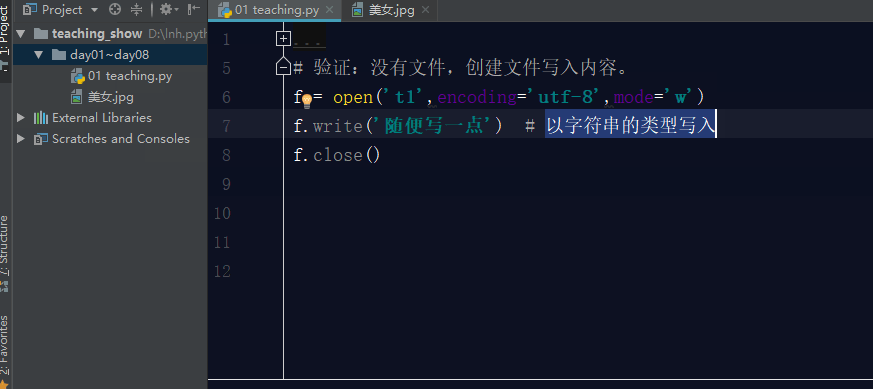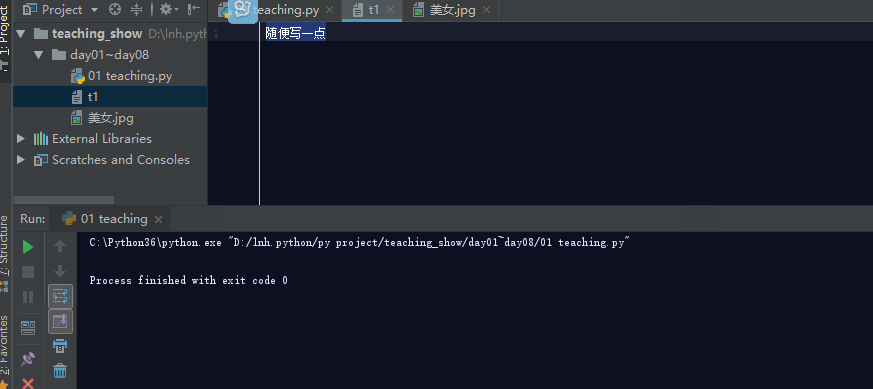
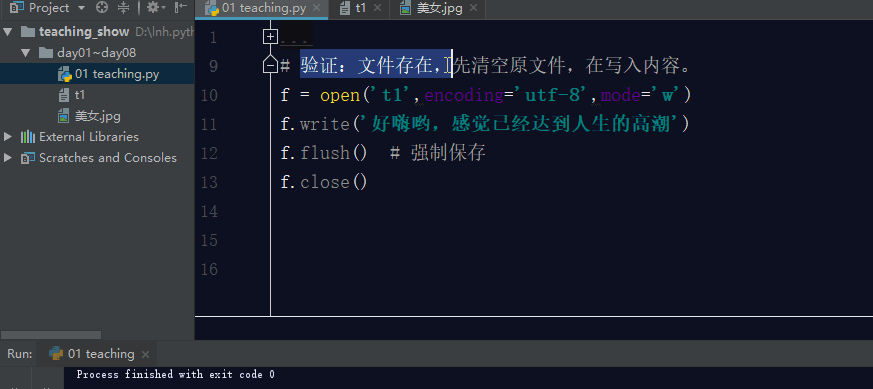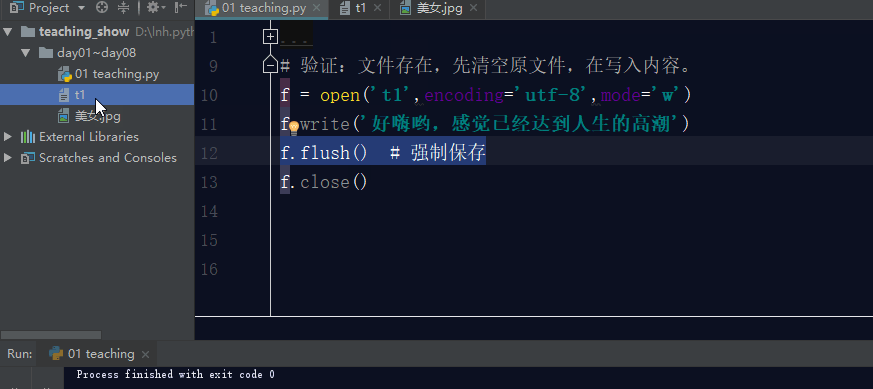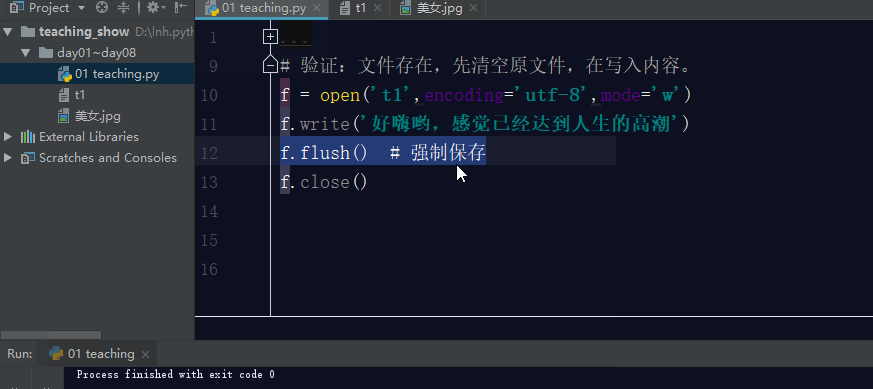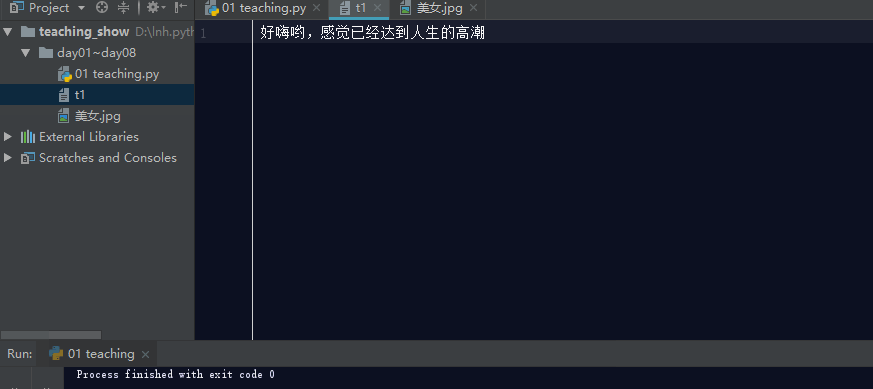
如果文件存在,利用w模式操作文件,先清空原文件内容,在写入新内容。
3.2 wb模式
wb模式:以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如:图片,音频,视频等。
举例说明:
我先以rb的模式将一个图片的内容以bytes类型全部读取出来,然后在以wb将全部读取出来的数据写入一个新文件,这样我就完成了类似于一个图片复制的流程。具体代码如下:

四. 文件操作:追加
第三类就是追加,就是在文件中追加内容。这里也有四种文件分类主要四种模式:a,ab,a+,a+b,我们只讲a。
4.1 a模式
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
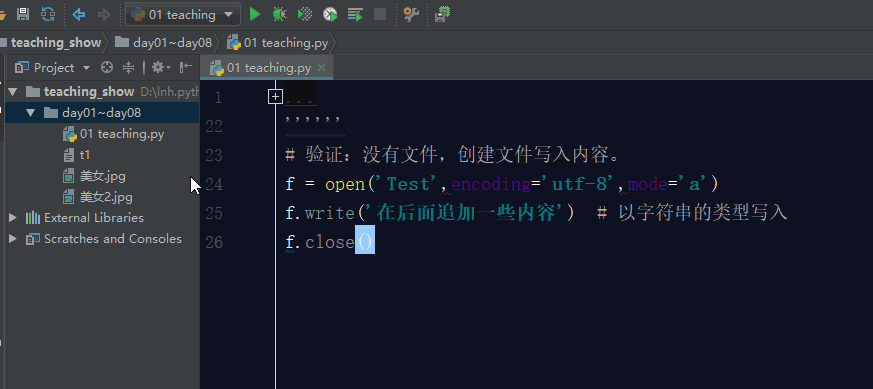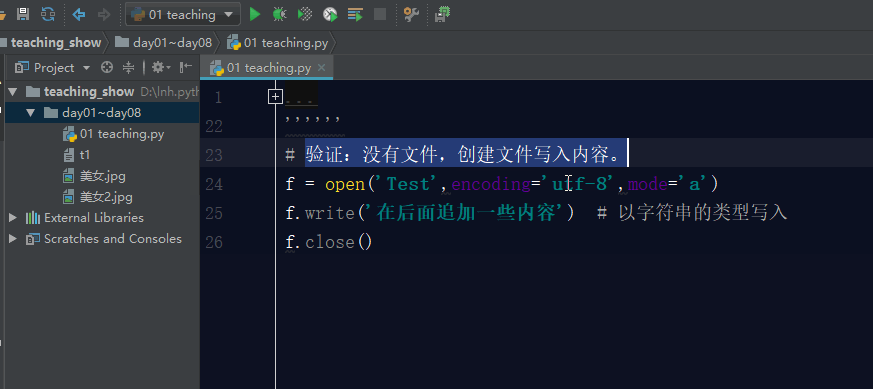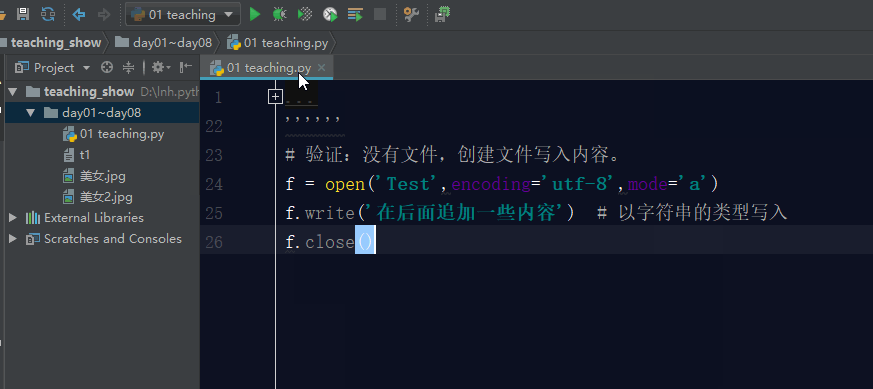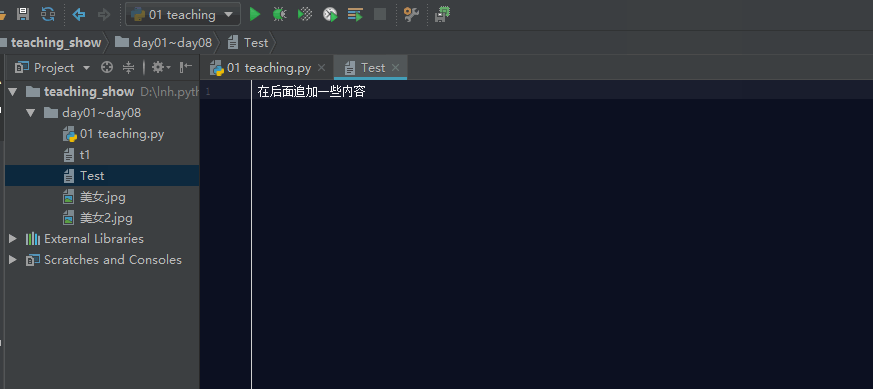
如果文件不存在,利用a模式操作文件,那么它会先创建文件,然后写入内容。

如果文件存在,利用a模式操作文件,那么它会在文件的最后面追加内容。
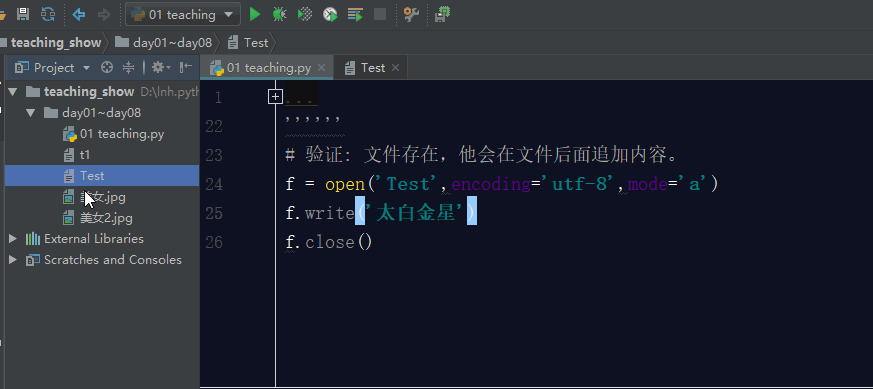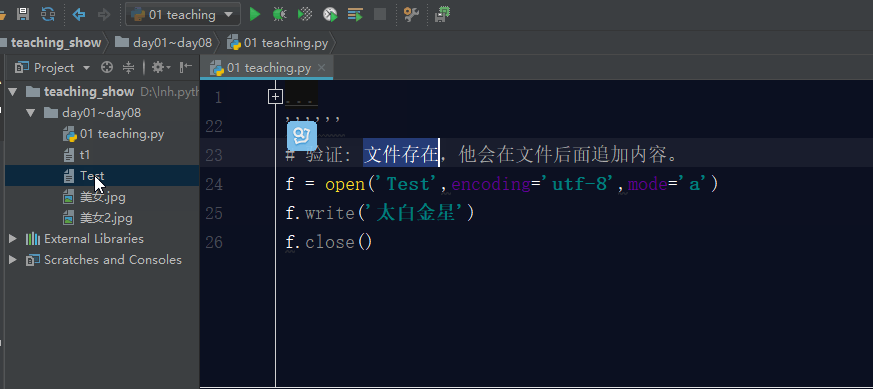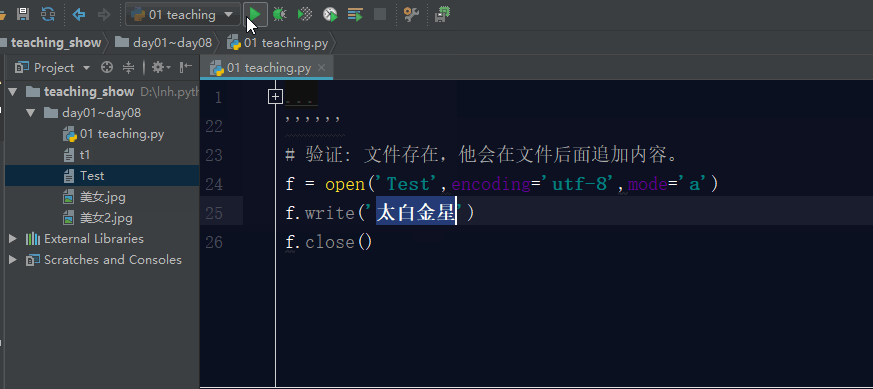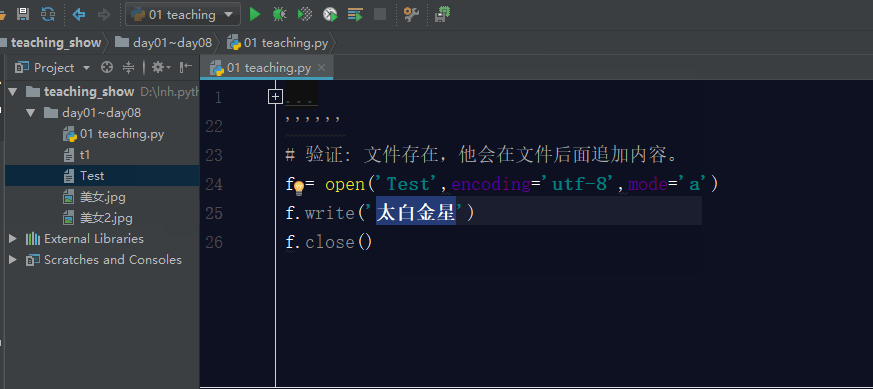
五. 文件操作的其他模式
大家发现了没有,咱们还有一种模式没有讲,就是那种带+号的模式。什么是带+的模式呢?+就是加一个功能。比如刚才讲的r模式是只读模式,在这种模式下,文件句柄只能进行类似于read的这读的操作,而不能进行write这种写的操作。所以我们想让这个文件句柄既可以进行读的操作,又可以进行写的操作,那么这个如何做呢?这就是接下来要说这样的模式:r+ 读写模式,w+写读模式,a+写读模式,r+b 以bytes类型的读写模式.........
在这里咱们只讲一种就是r+,其他的大同小异,自己可以练练就行了。
#1. 打开文件的模式有(默认为文本模式): r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】 w,只写模式【不可读;不存在则创建;存在则清空内容】 a, 只追加写模式【不可读;不存在则创建;存在则只追加内容】 #2. 对于非文本文件,我们只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式) rb wb ab 注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码 #3,‘+’模式(就是增加了一个功能) r+, 读写【可读,可写】 w+,写读【可写,可读】 a+, 写读【可写,可读】 #4,以bytes类型操作的读写,写读,写读模式 r+b, 读写【可读,可写】 w+b,写读【可写,可读】 a+b, 写读【可写,可读】
5.1 r+模式
r+: 打开一个文件用于读写。文件指针默认将会放在文件的开头。

注意:如果你在读写模式下,先写后读,那么文件就会出问题,因为默认光标是在文件的最开始,你要是先写,则写入的内容会讲原内容覆盖掉,直到覆盖到你写完的内容,然后在后面开始读取。
六. 文件操作的其他功能
6.1 read(n)
1. 文件打开方式为文本模式时,代表读取n个字符
2. 文件打开方式为b模式时,代表读取n个字节
6.2 seek()
seek(n)光标移动到n位置,注意: 移动单位是byte,所有如果是utf-8的中文部分要是3的倍数
通常我们使用seek都是移动到开头或者结尾
移动到开头:seek(0)
移动到结尾:seek(0,2) seek的第二个参数表示的是从哪个位置进行偏移,默认是0,表示开头,1表示当前位置,2表示结尾
f = open("小娃娃", mode="r+", encoding="utf-8")
f.seek(0) # 光标移动到开头
content = f.read() # 读取内容, 此时光标移动到结尾
print(content)
f.seek(0) # 再次将光标移动到开头
f.seek(0, 2) # 将光标移动到结尾
content2 = f.read() # 读取内容. 什么都没有
print(content2)
f.seek(0) # 移动到开头
f.write("张国荣") # 写入信息. 此时光标在9 中文3 * 3个 = 9
f.flush()
f.close()
6.3 tell()
使用tell()可以帮我们获取当前光标在什么位置
f = open("小娃娃", mode="r+", encoding="utf-8")
f.seek(0) # 光标移动到开头
content = f.read() # 读取内容, 此时光标移动到结尾
print(content)
f.seek(0) # 再次将光标移动到开头
f.seek(0, 2) # 将光标移动到结尾
content2 = f.read() # 读取内容. 什么都没有
print(content2)
f.seek(0) # 移动到开头
f.write("张国荣") # 写入信息. 此时光标在9 中⽂文3 * 3个 = 9
print(f.tell()) # 光标位置9
f.flush()
f.close()
6.4 readable(),writeable()
f = open('Test',encoding='utf-8',mode='r')
print(f.readable()) # True
print(f.writable()) # False
content = f.read()
f.close()
class TextIOWrapper(_TextIOBase):
"""
Character and line based layer over a BufferedIOBase object, buffer.
encoding gives the name of the encoding that the stream will be
decoded or encoded with. It defaults to locale.getpreferredencoding(False).
errors determines the strictness of encoding and decoding (see
help(codecs.Codec) or the documentation for codecs.register) and
defaults to "strict".
newline controls how line endings are handled. It can be None, '',
'\n', '\r', and '\r\n'. It works as follows:
* On input, if newline is None, universal newlines mode is
enabled. Lines in the input can end in '\n', '\r', or '\r\n', and
these are translated into '\n' before being returned to the
caller. If it is '', universal newline mode is enabled, but line
endings are returned to the caller untranslated. If it has any of
the other legal values, input lines are only terminated by the given
string, and the line ending is returned to the caller untranslated.
* On output, if newline is None, any '\n' characters written are
translated to the system default line separator, os.linesep. If
newline is '' or '\n', no translation takes place. If newline is any
of the other legal values, any '\n' characters written are translated
to the given string.
If line_buffering is True, a call to flush is implied when a call to
write contains a newline character.
"""
def close(self, *args, **kwargs): # real signature unknown
关闭文件
pass
def fileno(self, *args, **kwargs): # real signature unknown
文件描述符
pass
def flush(self, *args, **kwargs): # real signature unknown
刷新文件内部缓冲区
pass
def isatty(self, *args, **kwargs): # real signature unknown
判断文件是否是同意tty设备
pass
def read(self, *args, **kwargs): # real signature unknown
读取指定字节数据
pass
def readable(self, *args, **kwargs): # real signature unknown
是否可读
pass
def readline(self, *args, **kwargs): # real signature unknown
仅读取一行数据
pass
def seek(self, *args, **kwargs): # real signature unknown
指定文件中指针位置
pass
def seekable(self, *args, **kwargs): # real signature unknown
指针是否可操作
pass
def tell(self, *args, **kwargs): # real signature unknown
获取指针位置
pass
def truncate(self, *args, **kwargs): # real signature unknown
截断数据,仅保留指定之前数据
pass
def writable(self, *args, **kwargs): # real signature unknown
是否可写
pass
def write(self, *args, **kwargs): # real signature unknown
写内容
pass
def __getstate__(self, *args, **kwargs): # real signature unknown
pass
def __init__(self, *args, **kwargs): # real signature unknown
pass
@staticmethod # known case of __new__
def __new__(*args, **kwargs): # real signature unknown
""" Create and return a new object. See help(type) for accurate signature. """
pass
def __next__(self, *args, **kwargs): # real signature unknown
""" Implement next(self). """
pass
def __repr__(self, *args, **kwargs): # real signature unknown
""" Return repr(self). """
pass
buffer = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
closed = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
encoding = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
errors = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
line_buffering = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
name = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
newlines = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
_CHUNK_SIZE = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
_finalizing = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
3.x
七. 打开文件的另一种方式
咱们打开文件都是通过open去打开一个文件,其实Python也给咱们提供了另一种方式:with open() as .... 的形式,那么这种形式有什么好处呢?
# 1,利用with上下文管理这种方式,它会自动关闭文件句柄。
with open('t1',encoding='utf-8') as f1:
f1.read()
# 2,一个with 语句可以操作多个文件,产生多个文件句柄。
with open('t1',encoding='utf-8') as f1,\
open('Test', encoding='utf-8', mode = 'w') as f2:
f1.read()
f2.write('老男孩老男孩')
这里要注意一个问题,虽然使用with语句方式打开文件,不用你手动关闭文件句柄,比较省事儿,但是依靠其自动关闭文件句柄,是有一段时间的,这个时间不固定,所以这里就会产生问题,如果你在with语句中通过r模式打开t1文件,那么你在下面又以a模式打开t1文件,此时有可能你第二次打开t1文件时,第一次的文件句柄还没有关闭掉,可能就会出现错误,他的解决方式只能在你第二次打开此文件前,手动关闭上一个文件句柄。
八. 文件的修改
文件的数据是存放于硬盘上的,因而只存在覆盖、不存在修改这么一说,我们平时看到的修改文件,都是模拟出来的效果,具体的说有两种实现方式:
方式一:将硬盘存放的该文件的内容全部加载到内存,在内存中是可以修改的,修改完毕后,再由内存覆盖到硬盘(word,vim,nodpad++等编辑器)
import os # 调用系统模块
with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f:
data=read_f.read() #全部读入内存,如果文件很大,会很卡
data=data.replace('alex','SB') #在内存中完成修改
write_f.write(data) #一次性写入新文件
os.remove('a.txt') #删除原文件
os.rename('.a.txt.swap','a.txt') #将新建的文件重命名为原文件
方式二:将硬盘存放的该文件的内容一行一行地读入内存,修改完毕就写入新文件,最后用新文件覆盖源文件
import os
with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f:
for line in read_f:
line=line.replace('alex','SB')
write_f.write(line)
os.remove('a.txt')
os.rename('.a.txt.swap','a.txt')
1. File a.txt content: the content of each row are trade name, price, number.
10. 3 Apple
Tesla. 1 100000
MAC 3000 2
Lenovo. 3 30000
Chicken 10. 3
through the code, which will be built into this data type: [{ 'name': ' apple', 'price': 10, 'amount': 3}, { 'name': 'tesla' , 'price': 1000000, 'amount': 1} ......] and calculates the total price.
2, the following documents:
-------
alex old boy python sponsor, founder.
alex is actually Simon.
Who is alex sb?
You're very funny, alex again Niubi, also could not conceal his senior Cock wire temperament.
----------
files are replaced in all uppercase alex SB.