At 1:52 p.m. on September 22, 2019: 59- 22 September 2019 14:40:25
is given by the number of input and output data to $ \ left (x ^ {( i)}, y ^ {(i) } \ right) $ training data set consisting of target supervised learning is to learn a better mapping of the input $ x ^ {(i)} $ output $ y ^ {(i)} $ a. Used to predict a new input corresponding to the output.
Wherein the input $ x ^ {(i)} $ known input features (features), output $ y ^ {(i)} $ called the target variable or tag (target). A pair of input and output $ \ left (x ^ {( i)}, y ^ {(i)} \ right) $ called a training example or training samples (training example). $ m $ composed of a training example training set (Training SET) \ (\ left \ {\ left (X ^ {(I)}, {^ Y (I)} \ right); I =. 1, \ ldots, m \ right \} \) .
We \ (\ mathcal {X} \ ) to represent the input space, with $ \ mathcal {Y} $ represents the output space, targeted supervised learning is given training set \ (\ left \ {\ left (x ^ {(I)}, {^ Y (I)} \ right); I =. 1, \ ldots, m \ right \} \) , learn a good from the input space to the output space mapping \ (h: \ {} X-mathcal \ mapsto \ mathcal the Y} {\) . This mapping is also called the hypothesis (hypothesis). The following figure shows the training set, the relationship between the learning algorithm, the input is assumed that output.
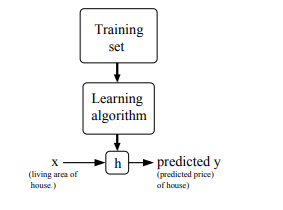
The target variable $ y ^ {(i)} $ are continuous, it can be divided into regression (regression problem) and classification (classification problem).