First, define the problem
1. Definitions
Gold Point Game: N players, each person write a rational number between 0 and 100 or two (not including 0 or 100), submitted to the server, the server calculates the average of all the numbers at the end of the current round, and then multiply 0.618, to give a G value. G closest player number (absolute value) obtained submissions-N, G farthest from the player gets points -2, 0 points to other players. Only one player does not score points when participating.
In our game, each player can submit two figures, a total of eleven groups (including Zou Yan teacher) Twenty two numbers and calculate the mean and then by 0.618 to get the number of gold G.
2. Difficulties
This game difficulty lies in the following few:
( 1) the number of participants more games, everyone's strategy is completely different and unknown, it is difficult to have a specific theoretical derivation can accurately estimate a golden point.
(2) winner-take-all mechanism. One can get a lot of winning points, but failed once only deduct 2 points. Therefore, the need for a strategic distribution point failed to upset the balance of gold is an issue to be considered, it would be just to get scores of strategy combined with good results may be obtained in general.
( 3) is to use the simplest strategy is to strengthen the depth and reinforcement learning or used together to learn, to be judged based on actual results rather than directly through qualitative and quantitative analysis of the result.
Second, the method modeling
We use two algorithms during the experiment, are the simplest use of q-learning methods and Deep q-learning Network method. The following were introduced.
1.q-learning method
QLearning is a reinforcement learning algorithm of value-based, Q is the Q (s, a) is in s state at a certain time (s∈S), take the desired action a (a∈A) action can get benefits environmental feedback will be rewarded reward r according to the action agent, so the main idea is to build into a Q-table to store the Q value of the State and action, and then select the action can get the maximum benefit based on the Q value.
| Q-Table |
a1 |
a2 |
| s1 |
q(s1,a1) |
q(s1,a2) |
| s2 |
q(s2,a1) |
q(s2,a2) |
| s3 |
q (s3, a1) |
q (s3, a2) |
Then we use the time difference method to derive update formula. The method combines the time difference Monte Carlo sampling methods and dynamic programming methods bootstrapping ( using the successor states the estimated current value of the function value of the function ) so that he can apply model-free algorithm and is a single step update faster. Function value is calculated as follows :
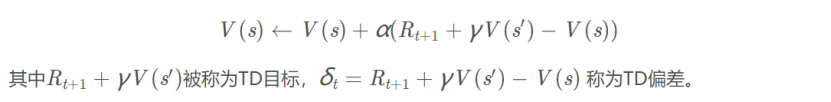
According to the above derivation of Q for value calculation, so have Q values we can learn, i.e. Q-table update process, wherein α is the learning rate, γ is the decay constant incentive, a method using the time difference method is updated .
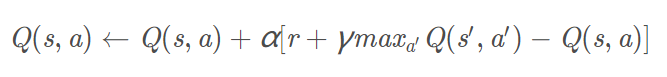
Is the formula Q-learning formula updated in accordance with the next state S 'to select the maximum of Q (S ' , A ' ) value by a decay value γ plus a real return , ie as Q reality, according to the previous Q table inside Q (s, a) a Q estimate.
The algorithm is as follows:

In this method, we have taken the strategy is to modify the parameters taken over Action . The learning rate, E-and Greedy , and several other parameters are set values of the four different gradients, and then make a 64 set of experiments, we found the best match parameters. Secondly, the action , the two figures have been submitted are the same, this is not enough, we get the equivalent of a digital digital competition with two other people, so we will spend two numbers returned were a golden point on a golden point * 0.618 , gold penultimate point, penultimate point gold * 0.618 , in the past three golden points in the past three golden points * 0.618 , over the past five golden point, in the past five gold points * 0.618 , geometric average over the past two golden points, the arithmetic average of each match, get eight different Action .
We also used a number of different submit 99 of action to disrupt the random and found that the gold point change is more obvious ups and downs, making a lot of model predictions inaccurate.
2.Deep Q Learning Algorithm
With the traditional Q Learning compared to the algorithm, DQN without Q table records Q value, but with a neural network to predict the Q value, and thus learn the best course of action by continuously updating the neural network.
They point to the history list gold converts the input data into the neural network of the depth ( state S) , with CNN ( convolutional neural network ) to predict the operation of a (a1, a2, a3 .... ), and the corresponding Q (s, a1), Q (s, a2 ), Q (s, a3) ... then updated neural network algorithm (NN) parameters (W, B ...) , to update the NN , to optimize the optimal model solution.
DQN There are two neural networks (NN) a relatively fixed network parameters, we called target-NET , to obtain Q- target (Q-target) value , further called eval_net used to obtain Q- Assessment (Q- eval) values. Back-propagation network is trained only real one, it is eval_net . target_net only forward propagation give q_target (R & lt q_target = + gamma] * max Q (s, a)). wherein Q (s, a) is through a plurality of target-net result of forward propagation.
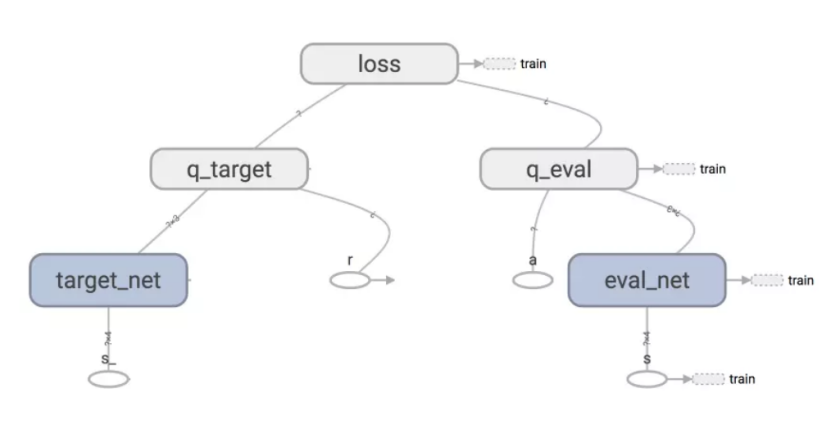
From the training data memory is randomly extracted, memory operations recorded in each of the states, reward, and the results of the next state (S, A, R & lt, S ') . Limited size of memory, when the data record is full, the next data overwrites the first data in memory, the memory is updated such coverage.
q_target network target_net will be regularly updated about the parameters, due target_net and eval_net structure is the same. Update q_target network parameter is directly q_eval copy parameters come on the line.
Random memory data in the learning, disturbed correlation between the experience, so that more efficient neural network updates, Fixed-Q Targets that target_net possible to update the delay parameters thus upset correlation.
The algorithm is as follows:

In our experiments implementation, we will enter the state to a defined network Q obtain n outputs, where n is the action number, each output representing the use of the action score. According to this round then actually selected action obtained, and it performs the Next State , can calculate the action a reward (penalty) corresponding with the reward (penalty) can be updated network parameters. Meanwhile, DQN having a memory unit, each time a plurality of samples from the sample as a batch this time Recent data network, instead of just using.
Third, the results analysis
In his own room test the q-learning and DQN after two robot networks, we found DQN network in the beginning might score higher than q-learning method, but at a later stage will be q-learning methods far throw off. Therefore, when we submitted using only a q-learning method.
On the first day of the 1000 round of competition, the results far exceeded our expectations. I would have thought of bot2 will lose to other uses DQN of BOT , but the result is the fact that we came in second place, behind leader and several several percentage. In the second day of the 10000 among the bout, I think my robot should be ranked in the second place, the results did not expect the process of ups and downs. We started very low score, came in far behind, but to the medium term, we suddenly force, far throw off the third, and first only a thin 100 extra points. To the 3000 round after my bot2 it has been stable in the first place, ahead of second place 400 or so points. Is supposed to open the black prepared to lie to win, I did not expect to 8500 when the bout, the first day of the first sudden over my bot2 . This is nothing, to 9970 when the round (a total of 10,000 rounds), lower than our original 400 points as third actually exceeded our final remaining thirty bout me impotent, lost 40 points. Really too difficult! But the process is really wonderful!
Before the race, we believe that the quality assessment model should not only be the final score, but the score and ranking of the middle of the process, and the final score is relatively poor. For example, we bot2 behind second place 40 points, in fact we had 14,000 extra points, then this 40 minutes is actually seem likely due to chance factors. If you continue to run down, second place would be likely to overtake us.
If more people or more numbers to match. Our approach necessarily apply, because we end up taking is the most simple modification action strategy, he is not susceptible to other use RNN , DQN affect other complex neural network has better robustness.
Finally, the evaluation of his teammates. Because my teammates have withdrawn, so the whole process of golden point game, from understanding to write code, test, maintenance is a person I do, but also finished third last, and only the second lower than the first a little, is quite satisfactory!