Serialization concept
- Serialization (the Serialization) refers to the structure of the object into a byte stream.
- Deserialize (Deserialization) is the sequence of the reverse process. I.e., flow back into the byte structured object.
- Java serialization (java.io.Serializable)
Hadoop serialized characteristics
- Serialization format features:
- Compact: efficient use of storage space.
- Fast: small overhead reading and writing data
- Scalable: transparently read the old data format
- Interoperability: supports interactive multi-language
- Hadoop serialization format: Writable
Action Hadoop serialized
- Serialization in the role of the two distributed environment: The inter-process communication, permanent storage.
- Hadoop inter-node communication.
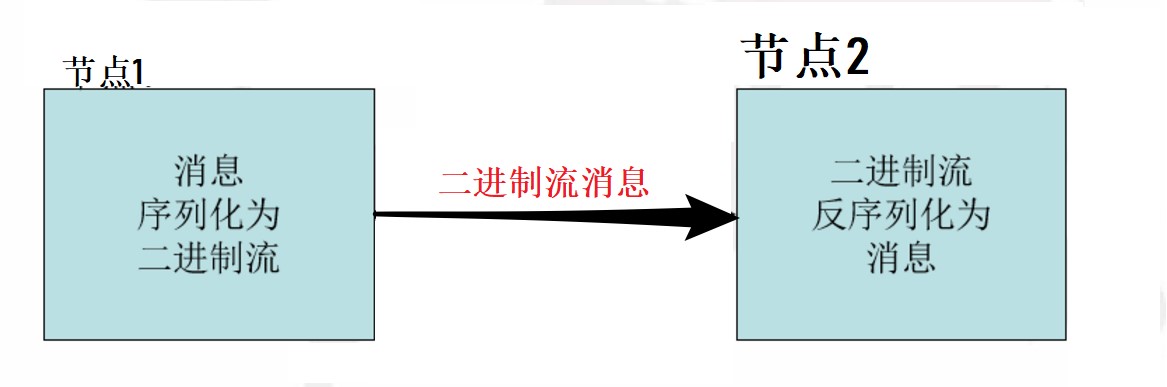
Writable Interface
Writable the interface is according to a simple, effective and DataOutput serialized object DataInput achieved any Key and Value MR Writable must implement the interface.

Any key MR must implement the interface WritableComparable

Writable common implementation class
Text is generally believed that it is equivalent to java.lang.String of Writable. For UTF-8 sequence.
Example:
Text test = new Text("test");
IntWritable one = new IntWritable(1);


Custom Writable class
- Writable
- Each object is to write into the serialized output stream
- readFields the input stream of bytes is deserialized

- Achieve WritableComparable.
- Comparative Java object value: generally need to rewrite toString (), hashCode (), equals () method
Input processing class MapReduce
- 1、FileInputFormat:
- FileInputFormat is the base class for all data in the source file as InputFormat implemented, FileInputFormat save all job file as input, and implements the calculation method splits the input file. As for the method to obtain recorded it is different subclasses --TextInputFormat be achieved.
- 2、InputFormat:
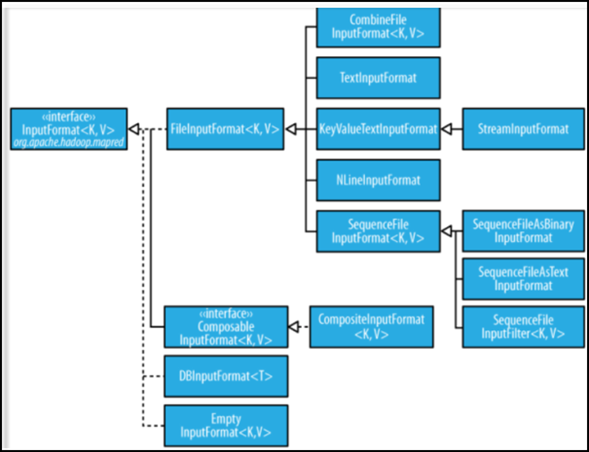
- InputFormat responsible for processing the input portion MR has three functions:
- Enter verify whether the job specification.
- The input file into InputSplit.
- RecordReader provide implementation classes, the Mapper InputSplit read for processing.
- InputFormat responsible for processing the input portion MR has three functions:
- 3、InputSplit:
- Before performing MapReduce, the original data is divided into a plurality of split, each split map as input a task during execution split map is decomposed into a recording (key-value pair), map handling each record in turn .
- FileInputFormat only divide larger than HDFS block file, so FileInputFormat results into a part of this document or this document.
- If a file size smaller than the block, will not be divided, and this is Hadoop processing efficiency of processing large files than the reason for the high efficiency of many small files.
- When Hadoop to handle many small files (file size is less than hdfs block size), because of FileInputFormat small files will not be divided, so every little file will be split as a task and assign a map, resulting in under efficiency.
- For example: a 1G file, it will be divided into 16 Split 64MB and assign 16 map-tasking, while 10,000 100kb file is processed 10 000 map tasks.
- 4、TextInputFormat:
- TextInputformat is the default handler classes, deal with ordinary text files.
- File as a record of each row, he will start the file offset of each row as the content key, each row as a value.
- Default to \ n Enter key or as a row.
- TextInputFormat inherited FileInputFormat.
InputFormat class hierarchy
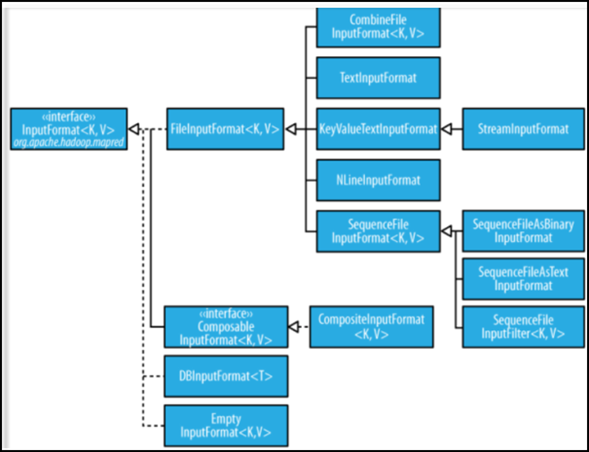
Other input class
- 1、CombineFileInputFormat
- A large number of small files is relative, hadoop more suitable to process a few large files.
- CombineFileInputFormat can alleviate this problem, it is designed for small files.
- 2、KeyValueTextInputFormat
- When each line of input data is two, and the tab-isolated form when, KeyValueTextInputformat process is very suitable for this file format.
- 3, NLineInputformat
- NLineInputformat can control the number of rows in each split data.
- 4、SequenceFileInputformat
- When the input file format is sequencefile when SequenceFileInputformat to be used as input.
Custom input format
- 1, the base class inherits FileInputFormat.
- 2, rewriting inside getSplits (JobContext context) method.
- 3, rewrite createRecordReader (InputSplit split, TaskAttemptContext context) method.
Hadoop output
- 1、TextOutputformat
- Default output format, the intermediate values tab key and value separated.
- 2、SequenceFileOutputformat
- The key and value sequencefile output format.
- 3、SequenceFileAsOutputFormat
- The key value and output as raw binary format.
- 4、MapFileOutputFormat
- The key and value write MapFile in. Because the key is MapFile ordered, so when write must ensure that records are written in the order of key values.
- 5、MultipleOutputFormat
- By default, a reducer will produce an output, but sometimes we want a reducer to produce more output, MultipleOutputFormat and MultipleOutputs can achieve this function.
Case realization:
data
136315798506613726230503248124681200
1363157995052138265441012640200
1363157991076139264356561321512200
1363154400022139262511062400200
13631579930441821157596115272106200
13631579950748413841341161432200
1363157993055135604396581116954200
13631579950331592013325731562936200
1363157983019137191994192400200
1363157984041136605779916960690200
13631579730981501368585836593538200
1363157986029159890021191938180200
1363157992093135604396589184938200
136315798604113480253104180180200
13631579840401360284656519382910200
13726230503248124681sum
DataBean class
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class DataBean implements Writable{
//电话号码
private String phone;
//上行流量
private Long upPayLoad;
//下行流量
private Long downPayLoad;
//总流量
private Long totalPayLoad;
public DataBean(){}
public DataBean(String phone,Long upPayLoad, Long downPayLoad) {
super();
this.phone=phone;
this.upPayLoad = upPayLoad;
this.downPayLoad = downPayLoad;
= + downPayLoad upPayLoad this.totalPayLoad;
}
/ **
* serialization
* Note: serialization and deserialization order and type must match
* /
@Override
public void Write (OUT of DataOutput) throws IOException {
// the TODO Auto-Generated Stub Method
out.writeUTF (Phone);
out.writeLong (upPayLoad);
out.writeLong (downPayLoad);
out.writeLong (totalPayLoad);
}
/ **
* deserialize
* /
@Override
public void readFields (of DataInput for primitive in) throws {IOException
// TODO Auto-Generated Stub Method,
this.phone=in.readUTF();
this.upPayLoad=in.readLong();
this.downPayLoad=in.readLong();
this.totalPayLoad=in.readLong();
}
@Override
public String toString() {
return upPayLoad +"\t"+ downPayLoad +"\t"+ totalPayLoad;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public Long getUpPayLoad() {
return upPayLoad;
}
public void setUpPayLoad(Long upPayLoad) {
this.upPayLoad = upPayLoad;
}
public Long getDownPayLoad() {
return downPayLoad;
}
public void setDownPayLoad(Long downPayLoad) {
this.downPayLoad = downPayLoad;
}
public Long getTotalPayLoad() {
return totalPayLoad;
}
public void setTotalPayLoad(Long totalPayLoad) {
this.totalPayLoad = totalPayLoad;
}
}
DataCount class
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class DataCount {
public static void main(String[] args) throws IOException, ClassNotFoundException,
InterruptedException {
// TODO Auto-generated method stub
Job job=Job.getInstance(new Configuration());
job.setJarByClass(DataCount.class);
job.setMapperClass(DataCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DataBean.class);
FileInputFormat.setInputPaths(job, args[0]);
job.setReducerClass(DataCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DataBean.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
public static class DataCountMapper extends Mapper<LongWritable, Text, Text, DataBean>{
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, Text, DataBean>.Context context)
throws IOException, InterruptedException {
String hang=value.toString();
String[] strings=hang.split("\t");
String phone=strings[1];
long up=Long.parseLong(strings[2]);
long down=Long.parseLong(strings[3]);
DataBean dataBean=new DataBean(phone,up, down);
context.write(new Text(phone), dataBean);
}
}
public static class DataCountReducer extends Reducer<Text, DataBean, Text, DataBean>{
@Override
protected void reduce(Text k2, Iterable<DataBean> v2,
Reducer<Text, DataBean, Text, DataBean>.Context context)
throws IOException, InterruptedException {
long upSum=0;
long downSum=0;
for(DataBean dataBean:v2){
upSum += dataBean.getUpPayLoad();
downSum += dataBean.getDownPayLoad();
}
DataBean dataBean=new DataBean(k2.toString(),upSum,downSum);
context.write(new Text(k2), dataBean);
}
}
}