EDITORIAL
This paper describes the Unix / Linux five kinds of network IO model, however. In order to better understand the concepts mentioned below five network IO, and we need to clarify these concepts below.
User space and kernel space
The computer usually has a memory space of a certain size, such as a computer has 4GB of address space, but the program does not fully use these address spaces, as these address space is divided into user space and kernel space of. Users can use the application user space memory mentioned here refers to the use of memory space application to application, not the real address space access. Here is a look at what the user space and kernel space:
User space
User space is the area where the conventional process, what is the normal process, the conventional process is open Task Manager to see:
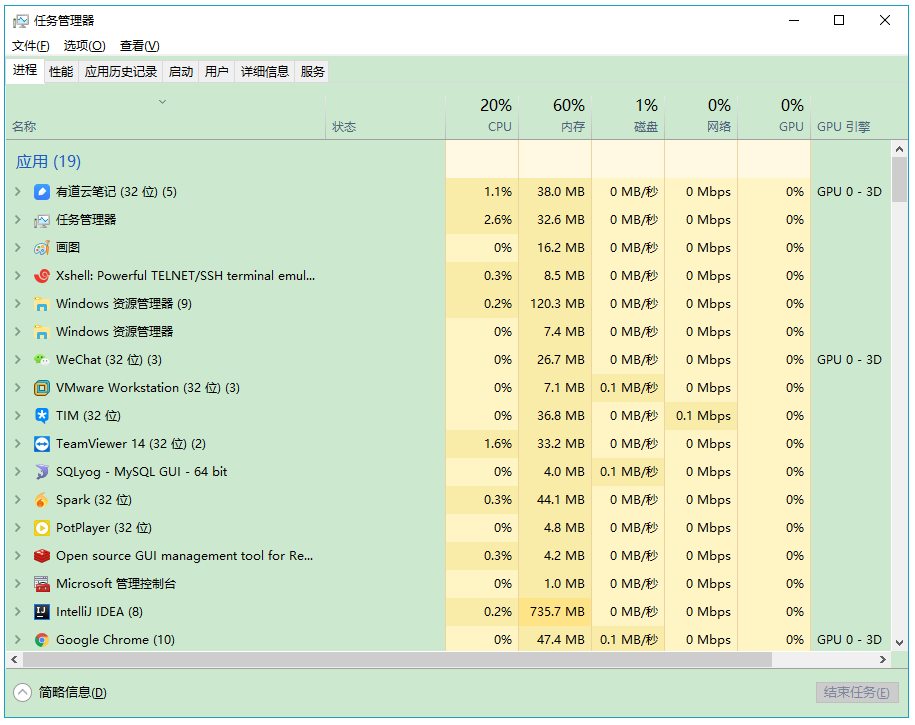
JVM is a conventional process, stationed in user space, user space non-privileged areas, such as can not directly access the hardware devices in the area of code execution.
Kernel space
Kernel space mainly refers to a running operating system scheduler is used, the use of virtual memory or the like connected to the program logic hardware resource. Kernel code have special rights, such as the device can communicate with the controller, controls the entire region of the operating state for the process. And I / O-related point is: All I / O are directly or indirectly through the kernel space.
Why, then, should be divided user space and kernel space? This is also to ensure the stability and security of the operating system. The user program can not directly access the hardware resources, if the user program needs to access hardware resources, you must call interface provided by the operating system, this procedure call interface is the system call. Each system call will present the data exchange between the two memory space, typically a network transmission system call is, first data transmitted over the network data received from the remote machine to the kernel space, then from user space to kernel space for the user program.
The following figure depicts a more vivid by this process:
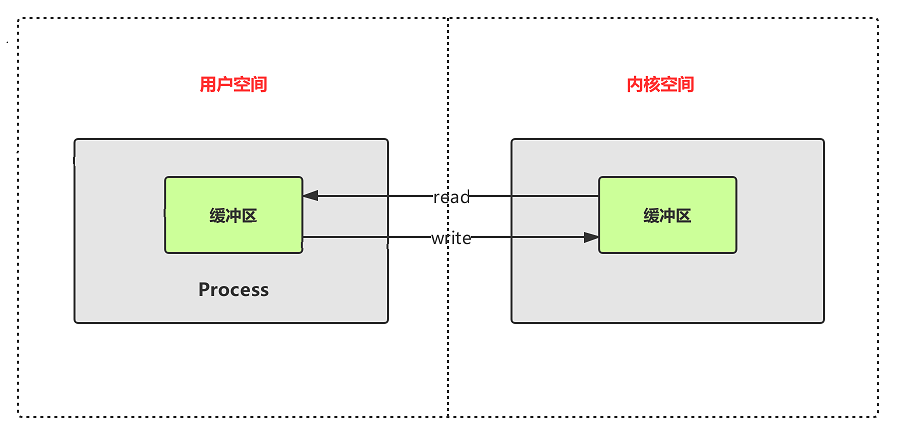
Tips: Copy this kernel space and user space data is very time-consuming, though to keep the safety and stability of the program running, but part of the expense of efficiency. However, the current operating system has been optimized for the good of this one, this is not the focus of our discussion.
Tips: the ratio of how to allocate user space and kernel space is a problem, is assigned to the user more space for the user to use the program, or to keep the first core has plenty of room to run, or to strike a balance. In the current Windows 32-bit operating systems, the default user space: kernel space ratio is 1: 1, while the ratio in the default 32-bit Linux system is 3: 1 (3GB user space, 1GB kernel space).
Synchronous and asynchronous
Synchronous and asynchronous is an idea, touched upon the field will be more, the I / O field (synchronous IO, asynchronous IO), the request to call the field (synchronous request, asynchronous requests, synchronous calls, asynchronous calls). Although it involved in a variety of areas, but the idea is the same. Synchronous and asynchronous, the real concern is the message communication mechanism .
Synchronize
To "call" for example, so-called synchronous, that is, when issuing a "call request", until no results, the "call request" not to return, but once you get the call returns a return value . In other words, the "caller" active wait for the results, "callee" in . We usually like to write, Method A call Math.random () method, Method B calls String.substring () methods are synchronous call because the caller waiting to return to take the initiative in these methods.
asynchronous
The so-called asynchronous, by contrast, when an asynchronous call request is made, the caller will not get the results immediately after the execution of the real results of this request, the result might just be a pseudo immediately returned . Therefore, the asynchronous call applies to those scenes of data consistency is not very high, or very time-consuming process is executed scene. If such a scenario, we want to get results for asynchronous calls, "callee" may be notified by the state to inform the caller, or by calling the callback function to deal with this, there is a corresponding Java in the Future / FutureTask, wait / notify reflect this idea.
Blocking and non-blocking
Blocking and non-blocking, or in fact for the process to determine the state of the thread. For example below, the user process to read data from the operating system kernel buffer when the data at this time if the kernel buffer not ready, then, one way is to be used operating system user process blocked there, so this time the status of the user process will be blocked from running state to state, which is blocked.
Knowing the basics of the above, then we officially entered the Linux network IO model.
Linux network IO model
Before understanding the five network I / O model, we must first have a clear network IO event, which will involve an object, what steps will experience:
IO network related to the subject
For a network IO (here we read, for example), it would involve two system objects, one is calling the IO process or thread, and the other is the Linux kernel space and user space.
Step process to perform I / O operations
Process performs I / O operations, boils down to, is to issue a request to the operating system, or let it write the buffer data row cleaner (write), or the buffer is filled with data (read). Use this mechanism to handle all process data in and out of operation, the task of the internal mechanisms operating system process, its complexity may be unimaginable, but Conceptually, it is very straightforward and easy to understand, for a network IO, here we read, for example, when a read operation occurs, it will go through two stages:
Kernel buffer to prepare data
Kernel buffer data copied to the user buffer
Several differences IO model is reflected in two stages, the following detailed description of several of these IO models.
Blocking IO
When the user calls the recvfrom process begins this function, the IO began the first phase: the kernel buffer to prepare the data . For network IO, the data is sent only to the accumulation of a certain amount of time, this time kernel buffer must wait for enough data to come. In the user side of the buffer, the user process will always be the operating system blocked , the kernel buffer when data is ready, then it will copy data kernel buffer to the user buffer, and then wake up by the operating system is blocked the user process and the results returned to the user process and user process at this time was up and running again. Therefore, blocking feature is the IO IO performed in two stages have been blocked .
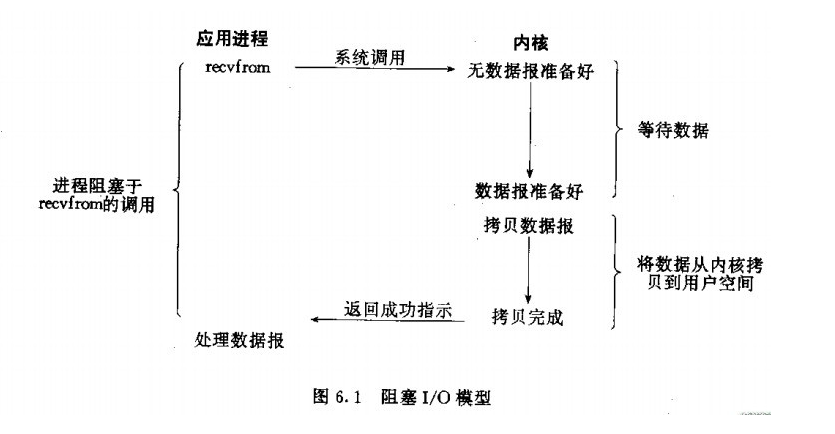
Non-blocking IO
As can be seen from the figure, when a user process issues a read operation, the kernel buffer if the data is not yet ready, so it does not block the user process, but immediately returns an error . From the perspective of the user process, it initiates a read operation after, and is not blocked, but immediately got a result. User process is the result of a judgment error, it knows that the data was not ready, so it can be sent again read operation, and thus go on indefinitely, here are the first stage has been in rotation. Once the data the kernel buffer is ready, and again received a read request of the user process, then it will immediately copy the data from the kernel buffer to the user buffer, and then returned to the user thread, this is the second stage. So, in fact, the user process has not been blocked by the operating system in the first phase, but the need to constantly ask about kernel buffers data is not good. Only in the second stage of data copied to when it will be blocked .
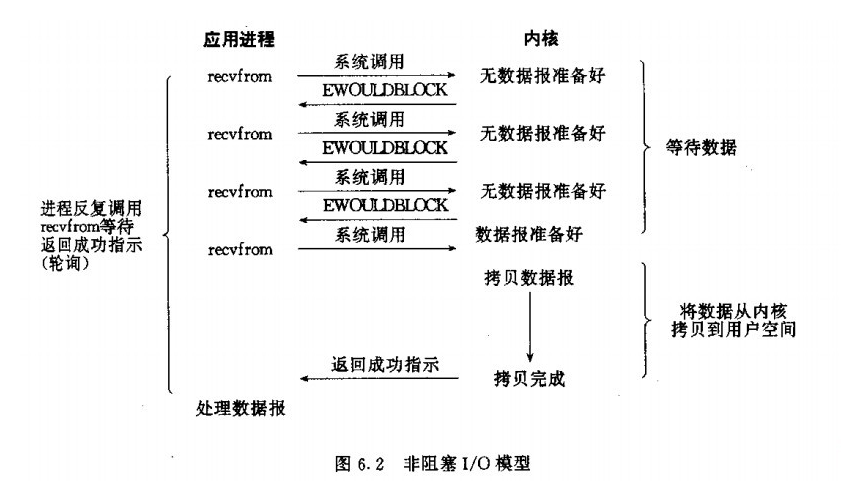
IO multiplexing
IO is actually multiplexed through a mechanism, a plurality of process may be monitored described fd, fd once a ready (ready generally read or write-ready), the corresponding program can be notified of the read and write operations, this mechanism there are select, pselect, poll, epoll, but they are essentially synchronous IO.
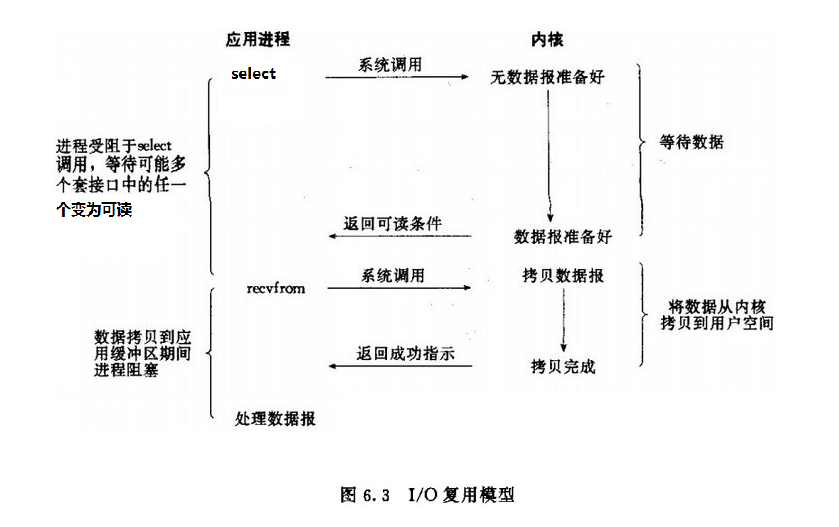
Note that the above blocking and non-blocking IO IO user processes are just a call recvfrom function, and here the user process will then call a select function, when a user process called select, then the whole process will be blocked, while at the same time, operating the system will "monitor" all select data corresponding responsibility socket kernel buffer, when data corresponding to any socket kernel buffer is ready, it will return notification readable condition. At this time, the user process further read operation, the data is copied from the kernel buffer to the user buffer.
This figure and blocking IO The graphic is actually not much difference, in fact, even more worse. Because this requires the use of two system call (select and recvfrom), and blocking IO only calls a system call (recvfrom). However, calling select advantage is that it can handle multiple socket at the same time. Better (So, if the number of the connection process is not very high, use select the web server may not use multiple threads than + IO blocking of web server performance, but also more likely to delay.
Tips: emphasize the advantages of select is not able to handle faster connections for a single, but that can handle more connections.
In IO multiplexing model, in fact, for each socket, usually set to non-blocking, but, as shown above, the entire process is actually the user has been blocked. Users simply select the function process is blocked, instead of being blocked socket IO to (or can be understood as the operating system is blocked).
There must be someone to ask that the role does not select multiple user process is blocked, then these user process and server to establish a socket to monitor them to see which data corresponding socket kernel buffer is ready, and then notify the user process, allowing users to process Zaifayici recvfrom request for data copy. That's also the way the role of epoll, epoll why people say it more efficient? Now, I will introduce in detail why epoll higher efficiency. To know that we have to first look at the Linux select, poll, epoll function.
We first look at the Linux-select, poll, epoll specific role of what is, what is the difference?
select
select function monitoring FD (disk descriptor Note: Linux the system components are in the form of a disk descriptor, for example, socket) divided into three categories, namely writefds, readfds, and exceptfds. After calling the select function will block until fd Ready (data read, write, or there except), or a timeout (timeout specified waiting time, if the return is immediately set to null), it will be just that All fd corresponding set of identifiers fd_set monitoring (Note that this data will be in the kernel buffer in place of fd logo will be marked with a marker) is returned to the user process and user process again to find out where the kernel buffer to traverse fd_set region of fd is ready data identifier, then go recvfrom transmission request, second stage begins.
select advantages:
- select now almost on all platforms supported by its good cross-platform support is also one of its advantages.
select Disadvantages:
big drawback is the select number fd of a single process can be monitored there is a certain limit, which consists of FD_SETSIZE limit, default is 1024, if you modify it, you need to recompile the kernel, but this will bring down the network efficiency .
Kernel address space and user address space each time the data is replicated copy at select models All fd; fd as the number of increase, only a small part fd may be active, but when select each call will traverse the entire fd_set, check each fd data ready state, which leads to low efficiency.
poll
The nature of the poll and select no difference, it will also tell the whole fd_set to the user process. And select different is that it does not limit the maximum number of connections, because it is based on a linked list to store.
poll Disadvantages:
Kernel address space and user address space under the model each time data replication is to copy all of fd.
There is a characteristic poll: trigger level, if fd reported in a ready state, not processed, it will report again when the next poll fd; fd increases when the linear scan results in performance degradation.
epoll
epoll support level trigger and edge trigger, the biggest feature is that edge-triggered, it only tells what the process fd becomes ready state, and only notice once. Another feature is, epoll using event -ready mode of notification by registered epoll_ctl fd, once the fd ready, the kernel uses a similar callback callback mechanism to activate the fd, epoll_wait can be notified.
epoll advantages:
There is no maximum limit concurrent connections, fd limit its maximum supported by the operating system file handles;
Efficiency improvement, unlike select and poll, epoll will only active (data in the ready state) fd operate, because epoll fd is achieved according to each of the above callback function in the kernel implementation, it is only active fd will take the initiative to call the callback function, fd other idle state will not. epoll performance is not limited by the total number of fd.
select / poll requires the kernel to fd message notification to the user space, and epoll by kernel and user space mmap same memory implementation.
epoll fd has two operation modes: LT (level trigger) and ET (edge trigger), the default mode is LT.
Tips:
the difference between ET and LT mode model are as follows:
LT Mode: When epoll_wait event descriptor detects this event and notifies the application, the application may not process the events immediately to the next call epoll_wait, will respond again application and notify this event.
ET mode: When epoll_wait detected descriptor events and event notification application, the application must handle the event immediately, if not addressed, the next call epoll_wait, will not respond to the application again and notice this event.
Here with a look at the table to show the difference between several functions:
| category | select | poll | epoll |
|---|---|---|---|
| The maximum number of connections supported | Restrictions by the FD_SETSIZE | Based on the list storage, there is no limit | Maximum handle limit by the system |
| The impact of surge fd | Fd lead to low performance linear scanning | With select | Based on the realization callback fd, no performance degradation problem |
| Message passing mechanism | Message to the kernel needs to user space, kernel needs to copy | With select | epoll be achieved through shared memory kernel and user space |
Here, we probably know why epoll higher than the efficiency of the select and poll.
IO drive signal
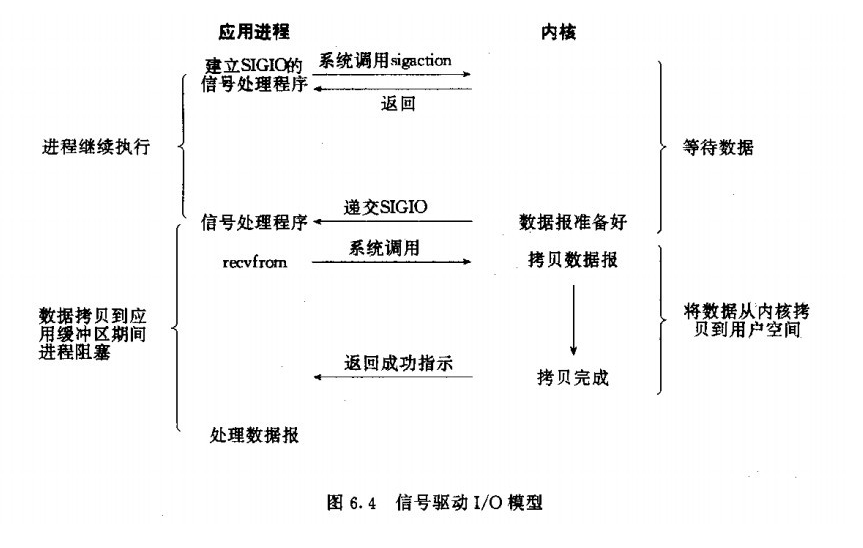
Processes and kernel handler of fd establish a sigio, and then do their own thing else, and does not block, when the kernel data ready when it will trigger Sigaction system call tells the user process data ready, at this time, a user process issues recvfrom the second stage.
Asynchronous IO
After a user process issues asynchronous IO, IO to return immediately all the work, the user process then you can do other things, but after all the kernel to complete. When the kernel data are ready, the kernel will automatically copy the data to the user space (user process is not blocked, here above are several different), sends a signal to the user process is completed after copying.
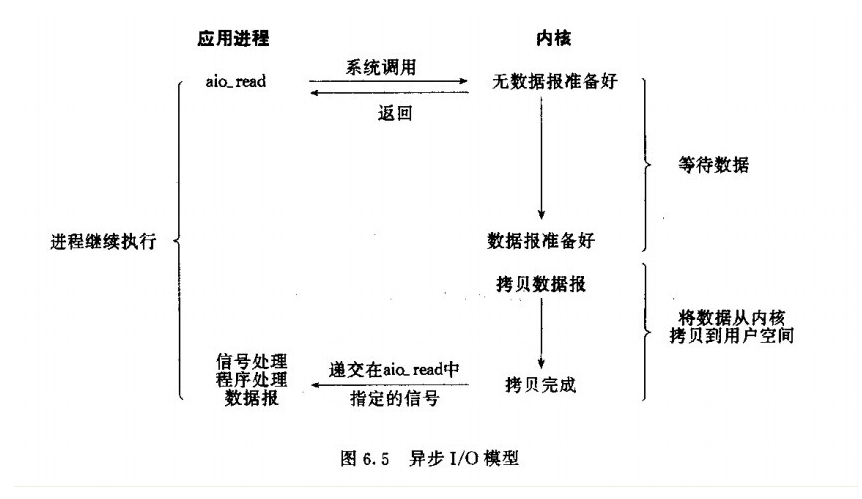
Tips: asynchronous IO under Linux actually with very little.
Finally, look at the comparison of Linux with Five network IO model:

Writing this network IO model is to back NIO-depth study and prepare Netty, also hopes to resolve some questions for everyone.
reference:
https://blog.csdn.net/baidu_39511645/article/details/78283680
https://www.cnblogs.com/wlwl/p/10291397.html
https://juejin.im/entry/585ba7038d6d810065d3d54a
https://www.cnblogs.com/xrq730/p/5074199.html
https://blog.51cto.com/xingej/1971598
https://www.cnblogs.com/javalyy/p/8882066.html
https://www.jianshu.com/p/6f132d27aeaf?utm_campaign
https://blog.csdn.net/u013374645/article/details/82808301
http://baijiahao.baidu.com/s?id=1604983471279587214&wfr=spider&for=pc