A paper target
1. fetch requests + BeautifulSoup embarrassments Encyclopedia of text;
2. crawl nickname, sex, age, post content, like the number of points, the number of comments;
2. crawled write the contents of txt.
Second, the implementation process
1. Obtain page source
DEF get_html (URL): # give page source code library requests HTML = requests.get (URL) .text return HTML
2. Check the source code to find the target structure to crawl
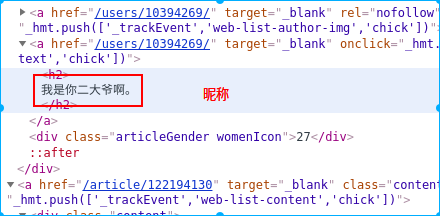

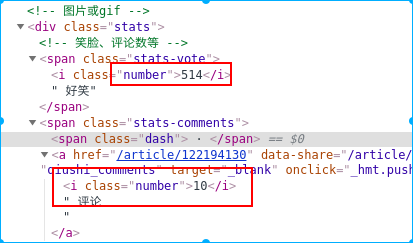
3. Locate these things you can write the following code to crawl
soup = BeautifulSoup(html,'lxml') datas = soup.find(id="content-left")#获取全部内容标签 data_list = datas.find_all(class_="article") for data in data_list: contents = data.find(class_="content").text.replace('\n','')#获取内容 name = data.find('h2').text.replace('\n', '' ) # Get the nickname age_gender = Data.Find (class_ = " articleGender " ) # get sex IF age_gender IS not None: CLL = age_gender [ ' class ' ] IF ' womenIcon ' in CLL: Gender = ' female ' elif ' manIcon ' in CLL: Gender = ' M ' the else : gender = '' age = age_gender.string else: gender = '' age = '' votes = data.find(class_="stats-vote").find(class_="number").text#获取点赞数 comments = data.find(class_="stats-comments").find(class_="number").text#获取评论数
4. all code following meat
Import requests from BS4 Import the BeautifulSoup DEF get_html (URL): # give page source code library requests HTML = requests.get (URL) .text return HTML DEF get_Data (HTML): Soup = the BeautifulSoup (HTML, ' lxml ' ) DATAS = soup.find (the above mentioned id = " content-left " ) # get the entire contents of the label DATA_LIST = datas.find_all (class_ = " Article This article was " ) for the Data in DATA_LIST: contentsData.Find = (the class_ = " Content " ) .text.replace ( ' \ n- ' , '' ) # acquires the content name = Data.Find ( ' H2 ' ) .text.replace ( ' \ n- ' , '' ) # get the nickname age_gender = Data.Find (class_ = " articleGender " ) # get sex IF age_gender IS not None: CLL = age_gender [ ' class '] if 'womenIcon' in cll: gender = '女' elif 'manIcon' in cll: gender = '男' else: gender = '' age = age_gender.string else: gender = '' age = '' votes = data.find(class_="stats-vote").find(class_="Number " ) .text # Acquisition Point Number Like Comments = Data.Find (the class_ = " stats-Comments " ) .find (the class_ = " Number " ) .text # acquires Comments dict = { ' nickname ' : name, ' gender ' : Gender, ' old ' : Age, ' content ' : contents, ' points of praise ' : votes, ' comments ' :comments } the yield dict DEF get_txt (dict): Print ( ' - ' + ' is written ...... ' ) with Open ( ' embarrassments Encyclopedia .txt ' , ' A + ' , encoding = ' UTF-. 8 ' ) AS F: for I in dict: f.write (STR (I) + ' \ n- ' ) Print ( ' --- ' + ' writing has been completed ' ) DEF main (): forI in Range (1,20 ): Print ( ' are crawling page% d ' , I) URL = ' https://www.qiushibaike.com/text/page/{}/ ' .format (I) HTML = get_html (URL) dict = get_Data (HTML) get_txt (dict) IF the __name__ == ' __main__ ' : main ()
5. Thanks for watching.