One: Learn
- String concept
- String operations
- 字符串函数:eval()、len()、lower()、upper()、swapcase()、capitalize()、title()、center()、ljust()、rjust()、zfill()、count()、find()、rfind()、index()、rindex()、lstrip()、rstrip()、strip()、ord()、chr()、split()、splitlines()、join()、max()、min()、replace()、startswith()、endswith()、encode()、decode()、isalpha()、isalnum()、isdigit()、isupper()、islower()、istitle()、isspace()
II: String concept
1. The string is a single or double quotes any text
'ABC'
"ABC"
2. Create a string
str1 = "learn python3!"
Three: string operations
1. String connection
str2 = "hello "
str3 = "world!"
str4 = str2 + str3
print("str4 =", str4)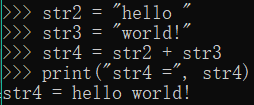
2. Repeat the output string
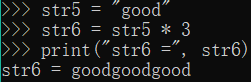
str5 = "Good"
STR6 = str5. 3 *
Print ( "STR6 =", STR6)
3. Access the string of a single character
# subscript characters look through the index, an index from 0
# string name [subscript]
STR7 = "the Test IS A Good Girl!"
Print (STR7 [1])

str7 [1] = "a" # string immutable
print (str7)

4, taken in a portion of the string
# String name [index Start: End index], belonging to the closed-open interval
STR7 = "A Good Test IS Girl!"
Str8 STR7 = [7:16]
Print ( "Str8 =", Str8)
# intercepted from the head to the prior to set the mark, not including the end of the index
STR9 STR7 = [0:. 6] # STR7 [:. 6]
Print ( "STR9 =", STR9)
# set to the standard from the beginning to the end, taken
str10 = str7 [17: ] # STR7 [:. 6]
Print ( "str10 =", str10)

The analysis determines whether the string is present
str11 = "test is a good girl"
print("good" in str11)
print("good1" not in str11)

6. formatted output
#% d% s% f placeholder
Print ( "Test IS A Good Girl")
NUM = 10
Print ( "NUM =", NUM)
Print ( "% D NUM =" NUM%)

= STr12 "Test"
F = 10.1234567890
#%. decimal place. 2F 3, are rounded
print ( "num =% d, str12 =% s, f =% .2f"% (num, str12, f))

Four: String Functions
1. eval (str) function
Function: string str as effective expression evaluated and returns the calculation result
the eval = num1 ( "123")
Print ( "num1 value:% D" num1%)
Print (type (num1))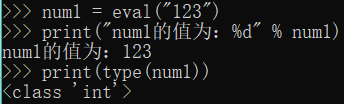
print(eval("-123"))
print(eval("12-3"))
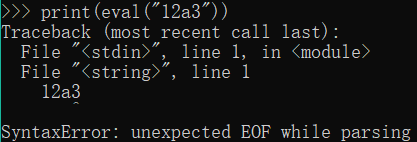
print(eval("12a3"))
2.len (str) function
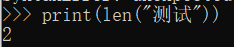
Function: Returns the length of the string (number of characters, not the number of bytes, a Chinese character is a)
print (len ( "test"))
3.str.lower () function
Function: Converts a string in uppercase letters to lowercase, the original string unchanged
str13 = "TEST is A GooD GirL"
print(str13.lower())
print(str13)

4.str.upper () function
Function: Converts a string lowercase letters to uppercase letters, the original string unchanged
str14 = "TEST is A GooD GirL!测试"
print(str14.upper())
print(str14)

5.str.swapcase()
Function: Converts a string to uppercase letters lowercase letters, uppercase to lowercase, the original string unchanged
str15 = "Test Is A Good Girl!测试"
print(str15.swapcase())

6.str.capitalize()
Function: the first letter capitalized, other lowercase, the original string unchanged
str16 = "test is a good girl!测试"
print(str16.capitalize())

7.str.title()
Function: The first letter of each word uppercase, lowercase other, the original string unchanged
str17 = "test is a good girl"
print(str17.title())

8.str.center(width[,fillchar])
Function: Returns a string that specifies the width of the center, as a string FillChar filled, the default is a space filling
str18 = "test is a good girl"
print(str18.center(40,"*"))

9.str.ljust (width [, fillchar])
Function: Returns a string that specifies the width of the left-justified, FillChar string of filling, the default is a space filling
str19 = "test is a good girl"
print(str19.ljust(40,"*"))

10.str.rjust(width[,fillchar])
Function: Returns a string that specifies the width of the right-aligned, a string FillChar filled, the default is a space filling
str19 = "test is a good girl"
print(str19.rjust(40,"*"))

11.str.zfill(width)
Function: Returns a string specified width, the left side is filled with 0
str20 = "test is a good girl"
print(str20.zfill(40))

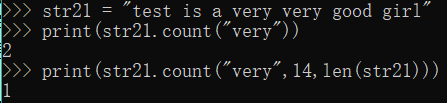
12.str.count(s[,start][,end])
Function: Returns the number of string str string s occurs, it is possible to specify a range, is not specified the default range from start to finish
str21 = "test is a very very good girl"
print(str21.count("very"))
print(str21.count("very",14,len(str21)))
13.str.find(s[,start][,end])
Function: from left to right if the detected character string contained in the string s, you can specify a range, is not specified the default range from start to finish
The result returned is the first occurrence of the string s start index, without or -1
str22 = "test is a very very good girl"
print(str22.find("very"))
print(str22.find("very",14,len(str22)))
print(str22.find("ddd")) #返回-1

14.str.rfind(s[,start][,end])
Function: string from right to left detector is included in the string s, you can specify a range, is not specified the default range from start to finish
returned result is the first occurrence of the string s start index, without or -1
str23 = "test is a very very good girl"
print(str23.rfind("very"))
print(str23.rfind("very",0,15))
print(str23.rfind("ddd")) #返回-1

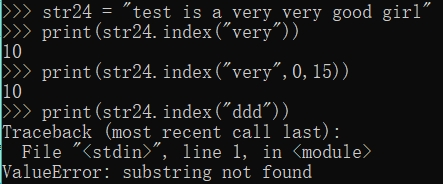
15.str.index (s [, start] [ , end])
with the find () the same, but if s does not exist when it will report an exception
Function: from left to right if the detected character string contained in the string s, you can specify a range, is not specified the default range from start to finish
returned result is the first occurrence of the string s start index
= str24 "Test Very Good Very IS A Girl"
Print (str24.index ( "Very"))
Print (str24.index ( "Very", 0,15))
Print (str24.index ( "ddd")) # find less than would be error, error
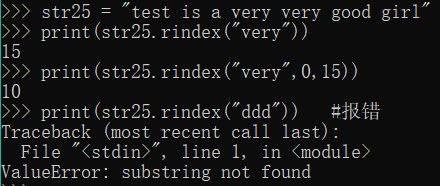
16.str.rindex(s[,start][,end])
Like rfind (), but if s does not exist when it will report an exception
Function: string from right to left detector is included in the string s, you can specify a range, is not specified the default range from start to finish
returned result is the first occurrence of the string s start index
str25 = "test is a very very good girl"
print(str25.rindex("very"))
print(str25.rindex("very",0,15))
print(str25.rindex("ddd")) #报错
17.str.lstrip(s)
Function: str interception on the left side of characters specified, the default is a space
str26 = " test is a very good girl"
print(str26.lstrip())
str26 = "*****test is a very good girl"
print(str26.lstrip("*"))

18.str.rstrip(s)
Function: str interception on the right side of characters specified, the default is a space
str27 = "test is a very good girl "
print(str27.rstrip())
str27 = "*****test is a very good girl*****"
print(str27.rstrip("*"))

19.str.strip (s)
Function: Extract the specified character str left and right sides, the default is a space
str28 = "****test is a very good girl****"
print(str28.strip("*"))
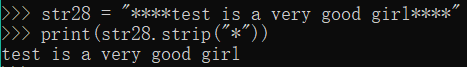
20.ord (s), CHR (97)
ord (s) Function: returns the ASCII value of the character
chr (97) Function: returns the ASCII value corresponding letter
str29 = "z"
print(ord(str29))
print(chr(90))

21. Comparison of the size of the string
# Beginning with the first character who Comparison ASCII value of large, whoever large
# If the first character equal, then the second and so on
print("baaa" > "azzz")

22.split(str="",num)
# Taken to a delimiter string str, num specified, only the character strings taken num
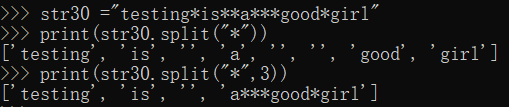
= str30 "Testing ** * IS * A *** Good Girl"
Print (str30.split ( "*"))
Print (str30.split ( "*", 3)) taken three times the value of #, the remainder being a overall
23.splitlines ([keepends]) in accordance with (\ r \ n \ r \ n) separated by the cutting line
#keeppends == True line breaks will be retained, the default is False
str31 =''' testing is a good girl!
testing is a nice girl!
testing is a handsome girl!'''
print(str31.splitlines())
print(str31.splitlines(True))

24. "". Join (seq), the specified string delimiter, all the elements are combined into a seq string
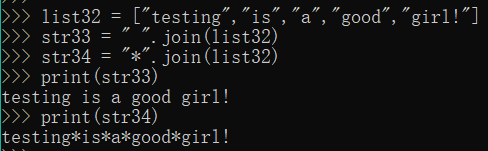
list32 = ["testing","is","a","good","girl!"]
str33 = " ".join(list32)
str34 = "*".join(list32)
print(str33)
print(str34)
25.max (str), find the maximum element string
str35 = "testing is a nice girl!"
print(max(str35))

26.min (str), find the smallest element string, Ascii by comparing the smallest spaces so that did not look like the same print
str36 = "testing is a nice girl!"
print(min(str36))

27.replace (old, new, num) num a string of old replaced by new, num not written by default all
= str37 "Testing Good Good Good IS A Girl!"
str38 = str37.replace ( "Good", "Nice") # replace all
Print (str37)
Print (str38)
str39 = str37.replace ( "Good", "Nice" 1) # replace only one
print (str39)

28.startswith (str [, start = 0] [end = len (str)]), determines whether within a given range is the beginning of a given string, the whole string default
str43 = "testing is a good girl!"
print(str43.startswith("testing"))
print(str43.startswith("tester"))
print(str43.startswith("testing",5,16))

29.endswith (str [, start = 0] [end = len (str)]), determines whether within a given range based on the end of a given string, the whole string default
str44 = "testing is a good girl!"
print(str44.endswith("girl"))
print(str44.endswith("tester"))
print(str44.endswith("girl",5,16))

30. The coding
#encode (encoding = "UTF-. 8", errors = "strict")
#encode (encoding = "UTF-. 8", errors = "the ignore"), the processing is not processing on behalf of the ignore
str45 = "testing is a good 测试!"
data46 = str45.encode()
print(data46)
print(type(data46))

31. decoding
#decode (encoding = "UTF-. 8", errors = "strict")
#decode (encoding = "UTF-. 8", errors = "the ignore"), the processing is not processing on behalf of the ignore
str47 = data46.decode ( "utf-8") # here to be consistent with the encoding in encoding
print(str47)

str48 = data46.decode ( "gbk", errors = "ignore") # here to be consistent with the encoding time encoding, inconsistencies will complain but my errors = "ignore", that is not handling errors, which would decode the garbled
print (str48)

32.isalpha (): all letters
# If there is at least one character string, and all characters are letters return True, otherwise False
= str48 "Testing IS A Good Girl"
Print (str48.isalpha ()) # returns False, because spaces
str48 = "testingisagoodgirl"
Print (str48.isalpha ())

33.isalnum (): full of numbers and letters
# If there is at least one character string, and all characters are letters or numbers return True, otherwise False
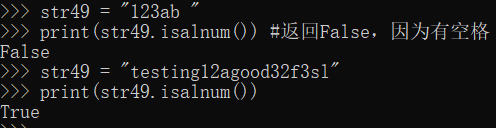
= str49 "123ab"
Print (str49.isalnum ()) # returns False, because there are spaces
str49 = "testing12agood32f3sl"
Print (str49.isalnum ())
34.isdigit (): all digital
# Returned if the string contains only numbers Ture, False otherwise
print ( "123" .isdigit () ) # returns True
Print ( "123a" .isdigit ()) # returns False, because the letter

35.isupper (): If the letters must be capitalized
# If there is at least an English character string, and all English characters are in uppercase, numbers and other characters does not matter returns True, otherwise False
= str50 "Ad"
Print (str50.isupper ()) # returns False, because the lowercase letters
str50 = "22ADF"
Print (str50.isupper ()) return True #

36.islower (): If the letters must be lowercase
# If there is at least one character string in English, and all English characters are lowercase, numbers and other characters it does not matter returns True, otherwise False
= str51 "the Ad"
Print (str51.islower ()) # returns False, because the capital letter
str51 = "# 123"
Print (str51.islower ()) # returns False, because there is a lower case letter
str51 = "22adf # @"
print (str51.islower ()) # returns True

37.istitle (): the title (the first letter of each word capitalized)
# If the string is the title returns True, otherwise False
print ( "Test Is" .istitle ( )) # returns True
Print ( "the Test IS" .istitle ()) # returns False, because there is the first letter of a word is not capitalized
print ( "testing is" .istitle ( )) # returns False, because the first letter of the word is not capitalized

38.isspace (): contains only whitespace (space, \ t, \ n, \ r, \ r \ n)
# If the string contains only whitespace returns True, otherwise False
print ( "" .isspace ()) # returns True
print ( "" .isspace ()) # returns True
print ( "\ t" .isspace ()) # returns True, because \ t is 4 out of space
print ( " \ n ".isspace ()) # returns True
Print (" \ r ".isspace ()) # returns True
Print (" \ r \ n ".isspace ()) # returns True
