nginx——keepalived
1.keepalived basic overview of high availability
What is High Availability
Generally refers to two machines start with the exact same business system, when there is a machine down the machine, another server can quickly take over for user access is no perception.
What usually use high availability software
Hardware use F5
Software keepalived
How to achieve high availability keepalilved
keepalived software is based, virtual routing redundancy protocol VRRP VRRP protocol implementation, mainly used to address single points of failure
So how vrrp was born, what is the principle?
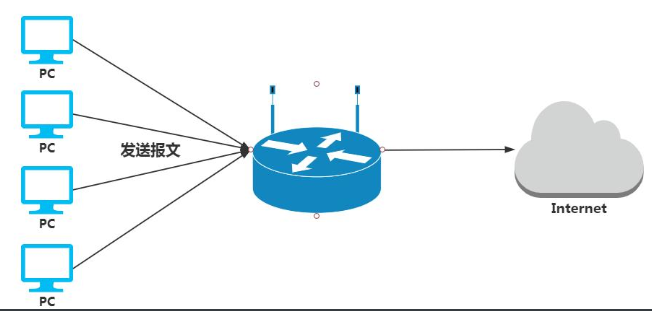
For example, the company's network is the Internet through the gateway, then if the router fails, the gateway can not forward packets, and this time everyone can not get online, how to do?
Common practice is to add a router Taipei street shop, but the problem is, if our primary gateway master fails, the user is required to manually backup point, if too many users to modify them will be very troublesome.
One problem: Suppose the user will have to modify is the backup point, then the master router repaired how to do?
Second problem: Suppose Master gateway fails, we will backup gateway is configured as a master gateway ip if you can?
In fact, it does not work, because the PC for the first time to find the Master gateway through the ARP broadcast MAC address and IP address, the information will be written to the ARP cache table, after the PC is connected through the information that is connected to the cache table and then forwards the packet, but even if we changed the IP address is a unique Mac, pc packets will still be sent to the master. (Except PC ARP cache table expiration, initiated when ARP broadcast again in order to obtain a new corresponding backup Mac address and IP address)
How can we fail automatically transferred, this time VRRP appeared, we actually increase a VRRP virtual MAC address (VMAC) and virtual IP address (VIP) in and outside Master Backup in the form of software or hardware, then in this case, when the PC requests VIP, either Master or Backup processing process, PC will only record information VMAC and VIP in the ARP cache table.
Keepalived use high availability scenarios
Business system typically needs to ensure 7 × 24 hours without DOWN machine, such internal OA system, company personnel are required every day use, Down machine is not allowed, as a business systems always available
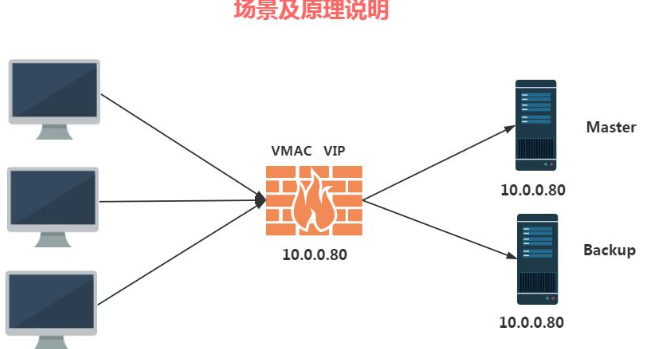
1, how to determine who is the master node who is back node (elections, priority)
2, if Master fault, Backup automatically take over, then the Master will reply to seize power it (try to seize non-preemptive)
3, if both servers think they are Master what the problem is (split brain) appears
keepalived high availability installation configuration
2.1 practice environment configuration
| effect | IP | Character |
|---|---|---|
| Node 1 | 10.0.0.5 | Master |
| Node 2 | 10.0.0.6 | Backup |
| VIP | 10.0.0.3 |
2.2 on the master and backup are mounted keepalived
[root@lb01 ~]# yum install -y keepalived
[root@lb02 ~]# yum install -y keepalived2.3 Configuration node 1, Master
#找到配置文件
[root@lb02 ~]# rpm -qc keepalived
/etc/keepalived/keepalived.conf
/etc/sysconfig/keepalived
#编辑配置文件
[root@lb01 ~]# cat /etc/keepalived/keepalived.conf
global_defs { #全局配置
router_id lb01 #标识身份->名称
}
vrrp_instance VI_1 {
state MASTER #标识角色状态
interface eth0 #网卡绑定接口
virtual_router_id 50 #虚拟路由id
priority 150 #优先级
advert_int 1 #监测间隔时间
authentication { #认证
auth_type PASS #认证方式
auth_pass 1111 #认证密码
}
virtual_ipaddress {
10.0.0.3 #虚拟的VIP地址
}
}2.4 Configuration node 2, Backup
[root@lb02 ~]# cat /etc/keepalived/keepalived.conf
global_defs {
router_id lb02
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3
}
}2.5 Comparison difference keepalived configuration of master and Backup
| Keepalived configuration differences | Master Node Configuration | Backup Node Configuration |
|---|---|---|
| route_id (unique identification) | router_id lb01 | router_id lb02 |
| state (the role of the state) | state MASTER | state BACKUP |
| priority (priority election) | priority 150 | priority 100 |
2.6 start keepalived Master and Backup node
#Master节点
[root@lb01 ~]# systemctl start keepalived
[root@lb01 ~]# systemctl enable keepalived
#Backup节点
[root@lb02 ~]# systemctl start keepalived
[root@lb02 ~]# systemctl enable keepalived3. availability keepalived preemptive and non-preemptive
3.1 Both nodes start
#由于节点1的优先级高于节点2,所以VIP在节点1上面
[root@lb01 ~]# ip addr | grep 10.0.0.3
inet 10.0.0.3/32 scope global eth03.2 Close keepalived node 1
[root@lb01 ~]# systemctl stop keepalived
#节点2联系不上节点1,主动接管VIP
[root@lb02 ~]# ip addr | grep 10.0.0.3
inet 10.0.0.3/32 scope global eth03.3 keepalived restart at this time on the Master, will be forced to seize the VIP find
[root@lb01 ~]# systemctl start keepalived
[root@lb01 ~]# ip addr | grep 10.0.0.3
inet 10.0.0.3/32 scope global eth03.4 Configuration non-preemptive
1、两个节点的state都必须配置为BACKUP
2、两个节点都必须加上配置 nopreempt
3、其中一个节点的优先级必须要高于另外一个节点的优先级。
两台服务器都角色状态启用nopreempt后,必须修改角色状态统一为BACKUP,唯一的区分就是优先级。
Master配置
vrrp_instance VI_1 {
state BACKUP
priority 150
nopreempt
}
Backup配置
vrrp_instance VI_1 {
state BACKUP
priority 100
nopreempt
}3.5 to verify through the windows arp, whether a MAC address is switched
#查看VIP在节点1上面
[root@lb01 ~]# ip addr | grep 10.0.0.3
inet 10.0.0.3/32 scope global eth0
#windows查看Mac地址
#将节点1的keepalived停掉
[root@lb01 ~]# systemctl stop keepalived
#节点2接管VIP
[root@lb02 ~]# ip addr | grep 10.0.0.3
inet 10.0.0.3/32 scope global eth0
#再次查看mac地址
arp -a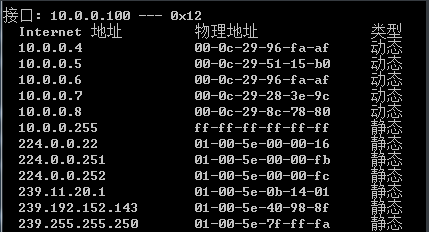
4. Fault split brain availability keepalived
For some reason, resulting in two keepalived highly available server within a specified time, we can not detect each other's heartbeat, ownership of resources and services to words, but this time the two high-availability servers are both still alive.
4.1 split brain cause of the malfunction
1, the server network failure or loose cable
2, the server hardware failure Crash damage phenomena
3, are turned on standby firewall firewalld
4.2 split brain Symptom
#将节点1和节点2的防火墙都打开
[root@lb01 ~]# systemctl start firewalld
[root@lb02 ~]# systemctl start firewalld
#fireshark抓包查看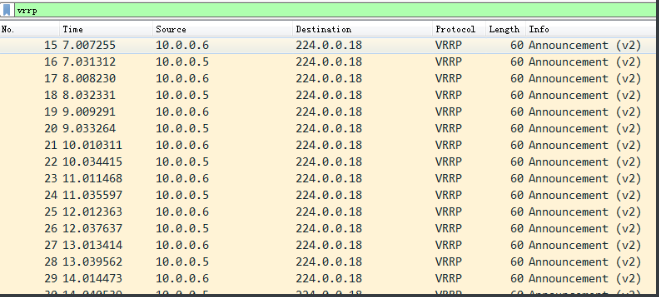
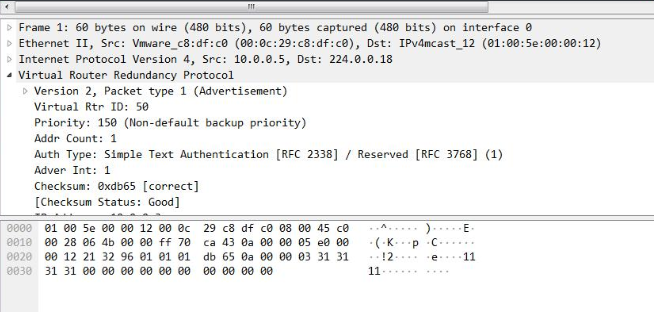
4.3 Failure Scenarios resolve split brain
#如果发生闹裂,则随机kill掉一台即可
#在备上编写检测脚本, 测试如果能ping通主并且备节点还有VIP的话则认为产生了列脑
[root@lb02 ~]# cat check_split_brain.sh
#!/bin/sh
vip=10.0.0.3
lb01_ip=10.0.0.5
while true;do
ping -c 2 $lb01_ip &>/dev/null
if [ $? -eq 0 -a `ip add|grep "$vip"|wc -l` -eq 1 ];then
echo "ha is split brain.warning."
else
echo "ha is ok"
fi
sleep 5
doneThe availability and nginx keepalived
5.1 Why domain name resolves to the VIP to access nginx?
Nginx default listens on all IP addresses, VIP will be blown on a single node, the equivalent of more than nginx that Taiwan is such a VIP card, so you can have access to the machine where the nginx
5.2 If nginx downtime, failure will lead to user requests, but does not hang keepalived will not be switched, so the need to write a script detects Nginx a viable state, if not the survival kill off keepalived
[root@lb01 ~]# mkdir /server/scripts
[root@lb01 ~]# vim /server/scripts/check_web.sh
#!/bin/sh
nginxpid=$(ps -C nginx --no-header|wc -l)
#1.判断Nginx是否存活,如果不存活则尝试启动Nginx
if [ $nginxpid -eq 0 ];then
systemctl start nginx
sleep 3
#2.等待3秒后再次获取一次Nginx状态
nginxpid=$(ps -C nginx --no-header|wc -l)
#3.再次进行判断, 如Nginx还不存活则停止Keepalived,让地址进行漂移,并退出脚本
if [ $nginxpid -eq 0 ];then
systemctl stop keepalived
fi
fi
#给脚本增加执行权限
[root@lb01 ~]# chmod +x /server/scripts/check_web.sh5.3 This script is called keepalived profiles lb01 host's
[root@lb01 ~]# cat /etc/keepalived/keepalived.conf
global_defs {
router_id lb01
}
#每5秒执行一次脚本,脚本执行内容不能超过5秒,否则会中断再次重新执行脚本
vrrp_script check_web {
script "/server/scripts/check_web.sh"
interval 5
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 50
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3
}
#调用并运行脚本
track_script {
check_web
}
}
#在Master的keepalived中调用脚本,抢占式,仅需在master配置即可。(注意,如果配置为非抢占式,那么需要两台服务器都使用该脚本)