I want to dream life into a science, then put the dream into reality. - Marie Curie
Outline
The key word is a group of words on behalf of an important part of the article, has important applications in document retrieval, automatic summarization, text clustering / classification and so on. In reality a large number of text does not contain keywords, which makes it more convenient too difficult to get the text message, it automatically extract keywords technology has important value and significance.
Keyword extraction classification
- Supervised
- Unsupervised
Although supervised high precision, but need to maintain a rich vocabulary, requires a lot of tagging data, labor costs are too high.
Unsupervised not need to mark data, so these algorithms to extract more applications in keywords. For example, TF-IDF algorithm, TextRank LDA topic model algorithms and algorithms.
TF-IDF algorithm
TF-IDF (Term Frequency - Inverse Document Frequency) is a statistical calculation based on a word often used to reflect the importance of the corpus for an article document.
Is the term frequency TF (Term Frequency), IDF is the inverse document frequency index (Inverse Document Frequency). TF-IDF's main idea is: If the frequency of occurrence of a word in a document high, that TF high; and other documents rarely appear in the corpus, that is, low DF, ie high IDF, this is considered word has a good ability to distinguish between categories.
Is a term frequency TF (Term Frequency), t represents the frequency of occurrence of words in the document d, the formula:
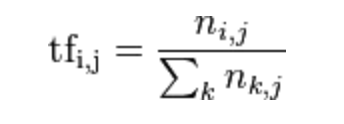
In which the numerator is the number of times the word appears in the document, and the denominator is all the words in a file and the number of times of appearance.
IDF is the inverse document frequency (Inverse Document Frequency), represents the corpus of documents that contain the word t number of reciprocal formula:
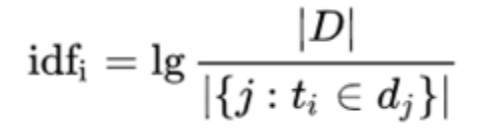
Wherein, | D |: total number of documents in the corpus, | {j: ti∈dj} | ti word contains the number of files, if the word is not in the corpus, will lead dividend zero, using the following general 1+ | {j: ti∈dj} |.
Then calculate the product of TF and IDF:
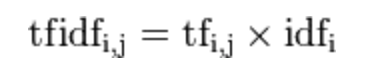
Therefore, TF-IDF tend to filter out common words, keep your important words. For example: Some words, "the," "a," "possible" appears in more than each article, but the article does not have the ability to distinguish between categories.
TextRank algorithm
TextRank algorithm from the corpus, only a single article document analysis can extract keywords of the document, this method was first used in automatic summary of the document, based on analysis of the sentence dimensions, use TextRank scored for each sentence, pick out the highest score n-sentence as the key sentence of the document, in order to achieve the effect of automatic summarization.
TextRank basic idea comes from Google founders Larry Page and Sergey Brin PageRank algorithm built in 1997. The core idea of the text in a word regarded as nodes in the graph, interconnected by side, to form a map where different nodes have different weights, high weight node can be used as keywords.
PageRank thought:
- The number of links. A web page is the more links to other pages, indicating that the more important this page.
- Link quality. A heavy page is a higher authority web links, also show that the more important this page.
TextRank with the idea of PageRank to explain it:
- Many point to a word is a word, then it indicates that the word is more important.
- Pointing to a word is a word TextRank high value, then TextRank value of this word is correspondingly increased.
Formula is as follows:
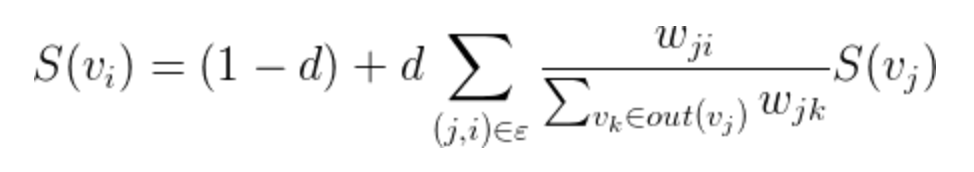
Right TextRank a heavy word i i depends on various points in the connected component j (j, i) the heavy weight of this edge, and j points to the sum of the weights of the other side and the damping coefficient d and generally 0.85.
TextRank keyword extraction steps:
- The given text is divided according to complete sentences.
- For each sentence, word segmentation and POS tagging process, and stop words filtered out, leaving only the designated part of speech of words, such as nouns, verbs and so on.
- Construction FIG keyword G = (V, E), where V is the set of nodes, step 2 produced by the keyword candidate composition, and then use an edge between any two co-occurrence relationship structure, there is an edge between two nodes words only if they correspond in length window current CPC K, K represents the window size.
- According to TextRank formula, iterative convergence elect weight topK words as keywords.
- Step 4 obtained from the most significant k words, marked in the original text, if the formation of the adjacent phrases, then combined into a multi-word keywords.
A keyword extraction LDA topic model based on
In most cases, TF-IDF algorithm and TextRank algorithm will be able to meet, but some scenes can not be extracted from the literal meaning of the key words, for example: an article about a healthy diet, which describes the various benefits of fruits and vegetables on the body but the whole article did not explicitly appear healthy word, this case in front of the two algorithms obviously can not extract the healthy underlying theme of this information, this time the topic model comes in handy.
LDA (Latent Dirichlet Allocation) by David Blei, who proposed in 2003, the theoretical foundation for the Bayesian theory, LDA co-occurrence information based on the analysis of words, fitting words - Documentation - theme distribution, and then the word, the text is mapped to a semantic space.
Real
- jieba has been achieved based on the keyword extraction TF-IDF algorithm, as follows:
import jieba.analyse
text = '城市绿化是栽种植物以改善城市环境的活动。 城市绿化作为城市生态系统中的还原组织 城市生态系统具有受到外来干扰和破坏而恢复原状的能力,就是通常所说的城市生态系统的还原功能。'
#获取关键词
tags = jieba.analyse.extract_tags(text, topK=3)
print(u"关键词:")
print(" ".join(tags))Results of the:
关键词:
生态系统 城市绿化 城市- jieba also been achieved based on keyword TextRank extraction algorithm, as follows:
import jieba.analyse
text = '城市绿化是栽种植物以改善城市环境的活动。 城市绿化作为城市生态系统中的还原组织 城市生态系统具有受到外来干扰和破坏而恢复原状的能力,就是通常所说的城市生态系统的还原功能。'
result = " ".join(jieba.analyse.textrank(text, topK=3, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v')))
print(u"关键词:")
print(result)Results of the:
关键词:
城市 破坏 还原- LDA based on keywords extracted by Gensim library is completed, as follows:
import jieba
import jieba.analyse as analyse
import gensim
from gensim import corpora, models, similarities
text = '城市绿化是栽种植物以改善城市环境的活动。 城市绿化作为城市生态系统中的还原组织 城市生态系统具有受到外来干扰和破坏而恢复原状的能力,就是通常所说的城市生态系统的还原功能。'
# 停用词
stop_word = ['的', '。', '是', ' ']
# 分词
sentences=[]
segs=jieba.lcut(text)
segs = list(filter(lambda x:x not in stop_word, segs))
sentences.append(segs)
# 构建词袋模型
dictionary = corpora.Dictionary(sentences)
corpus = [dictionary.doc2bow(sentence) for sentence in sentences]
# lda模型,num_topics是主题的个数
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=8)
print(lda.print_topic(1, topn=3))Results of the:
0.037*"城市" + 0.037*"城市绿化" + 0.037*"生态系统"