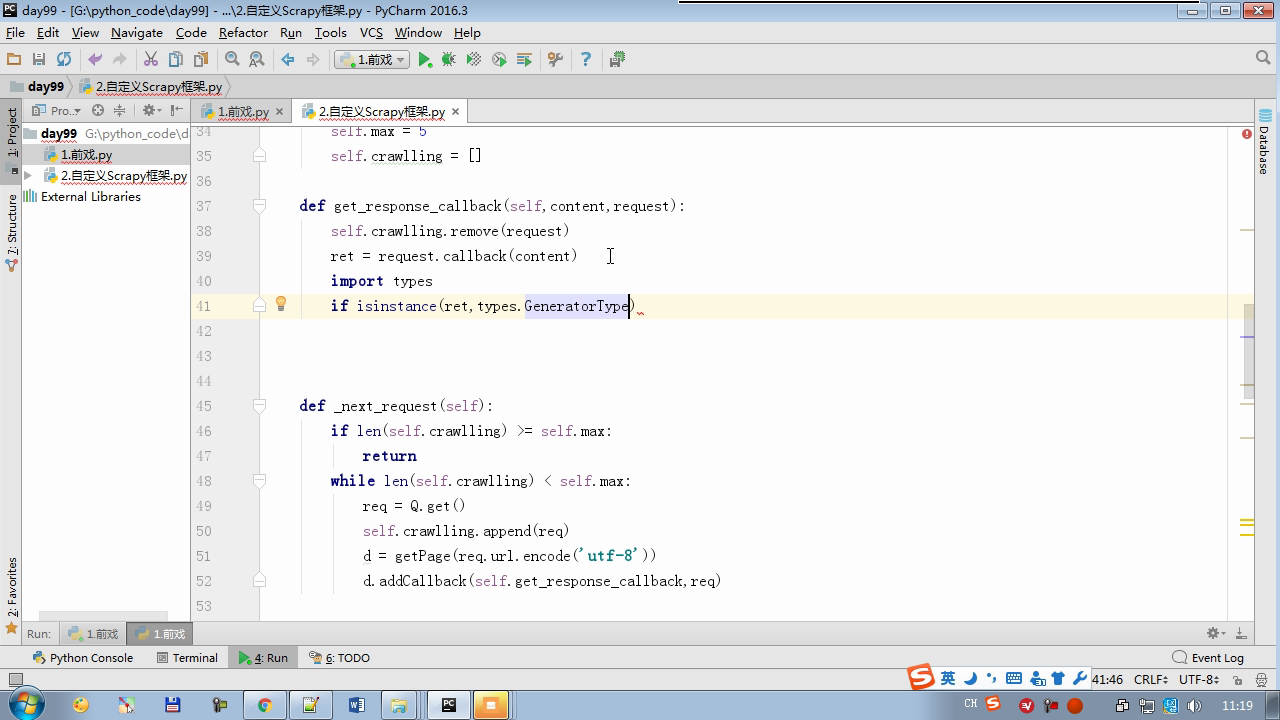
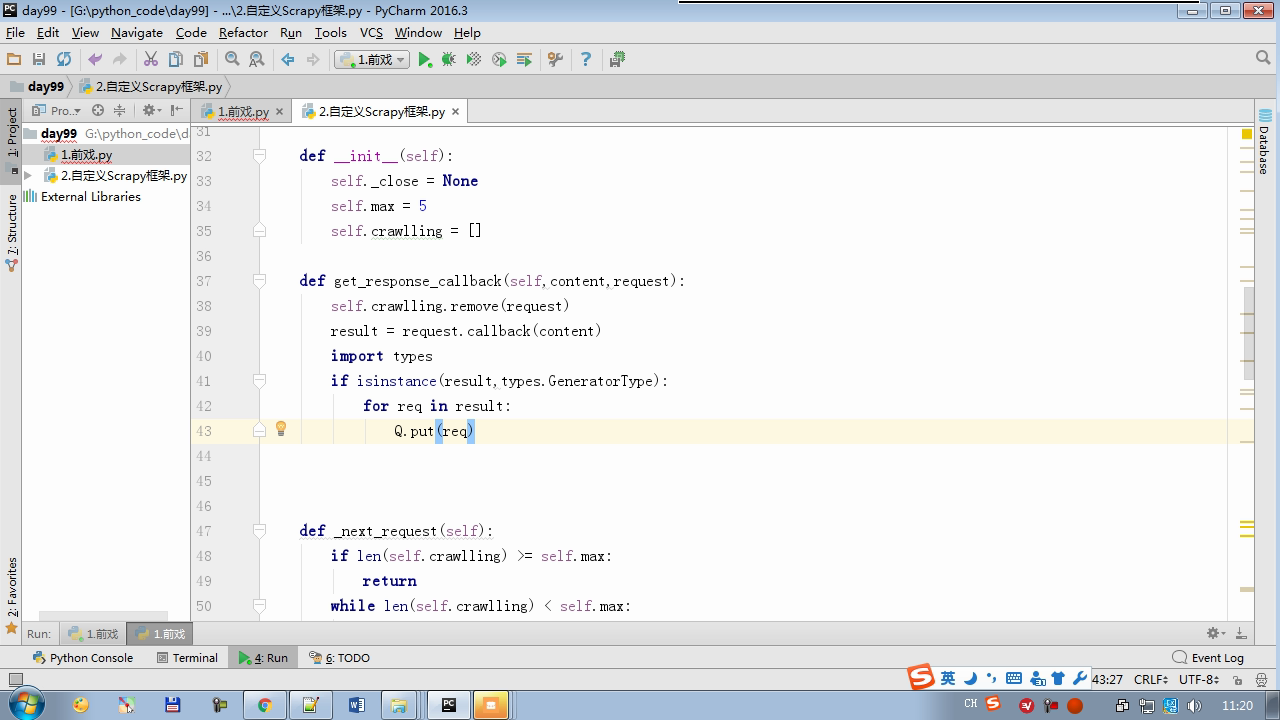
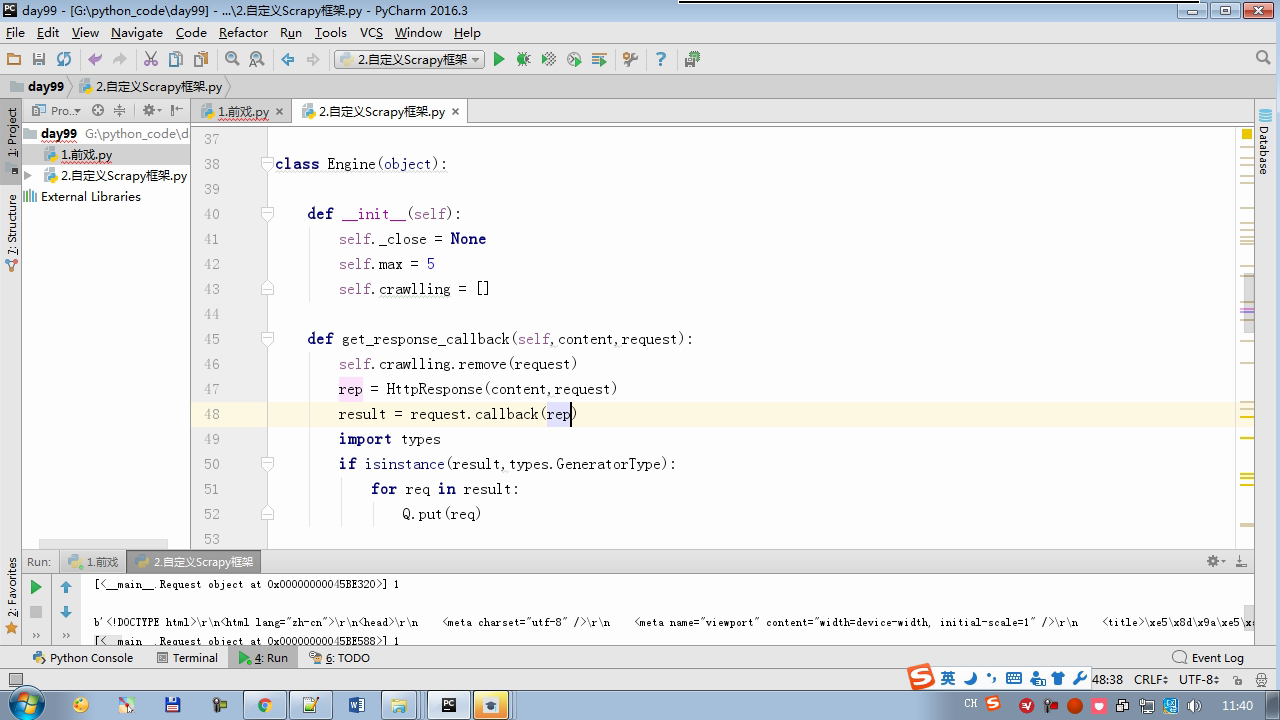
isinstance (result, types.GeneratorType) determines whether the generator
Will wait for the queue is empty, block = False range will complain
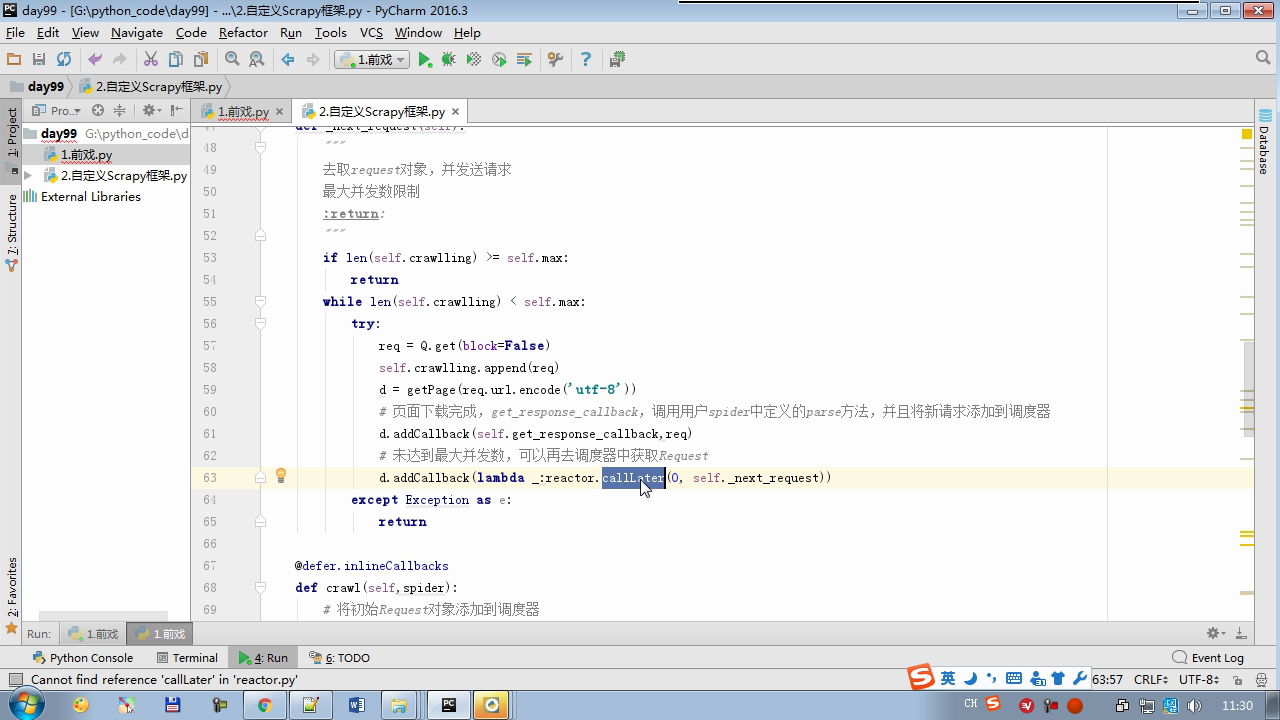
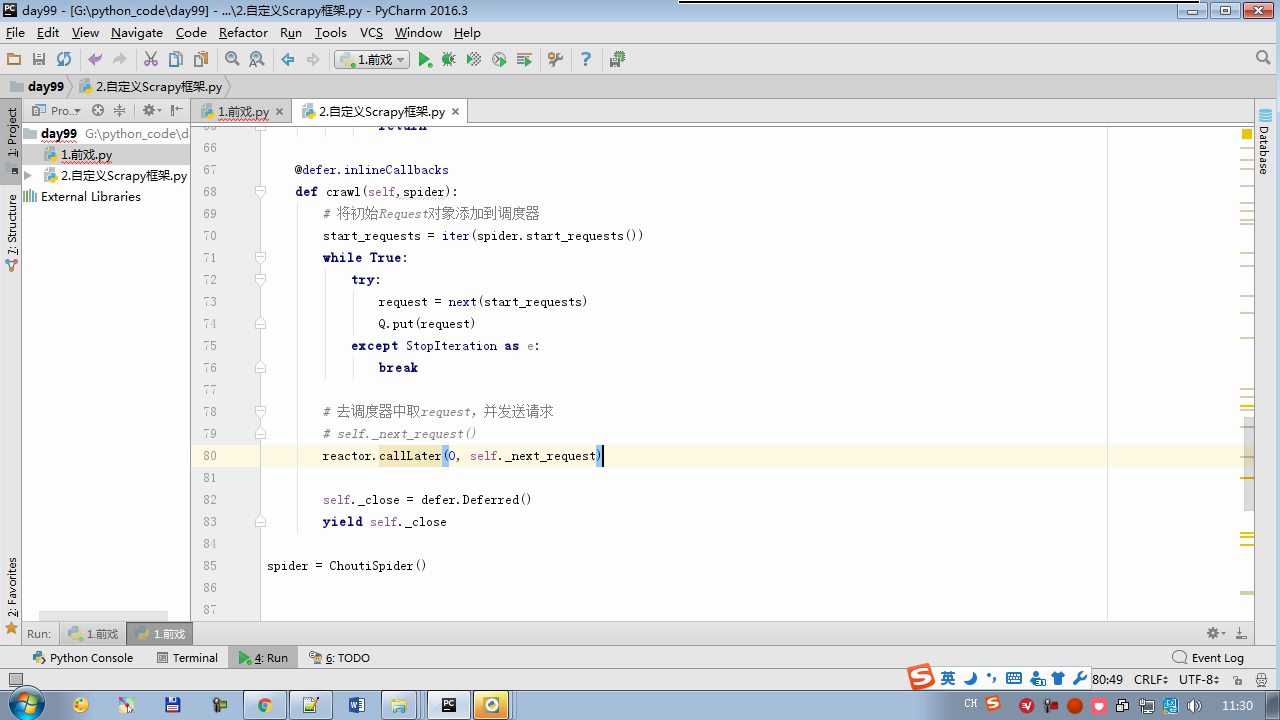
reactor.callLater(0,self.next_request)


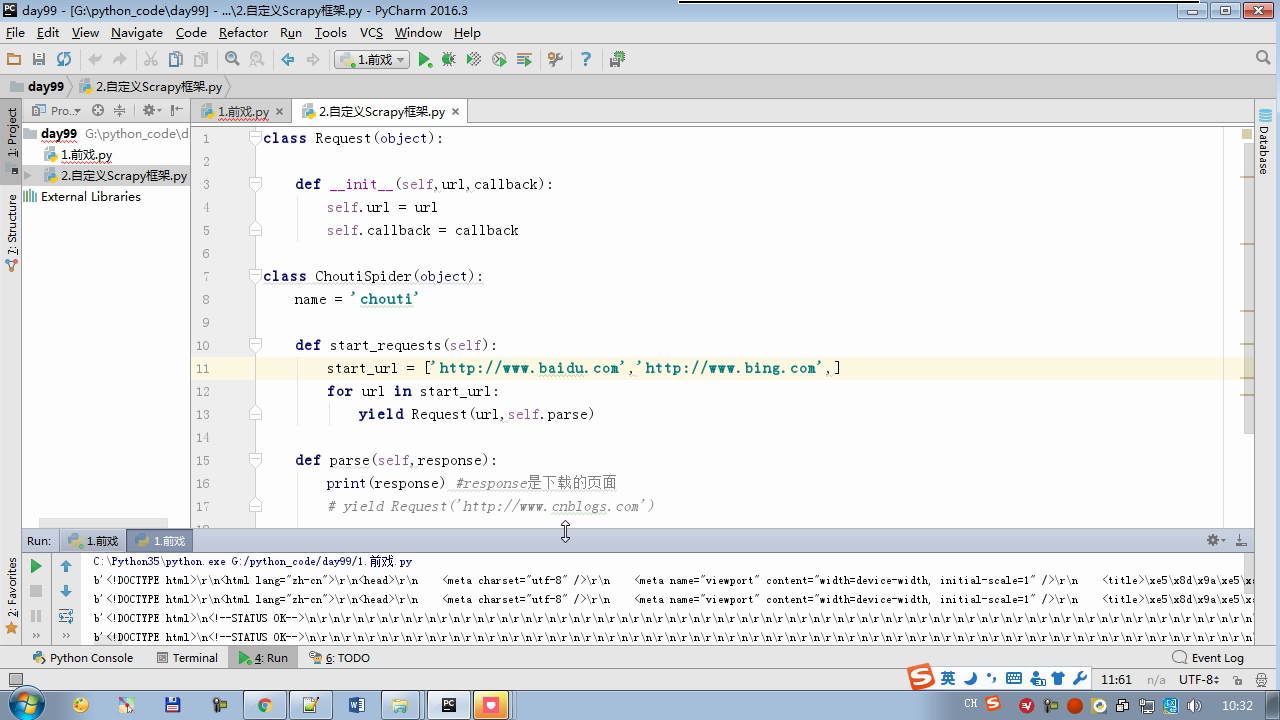
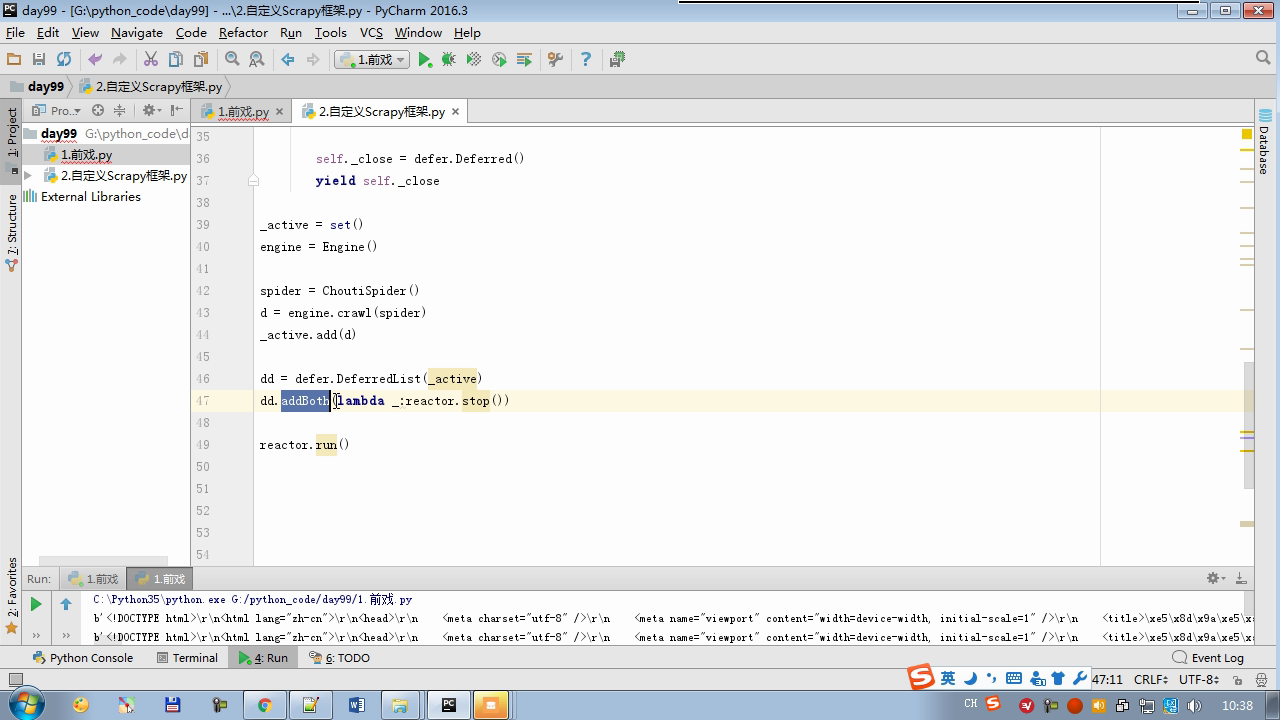
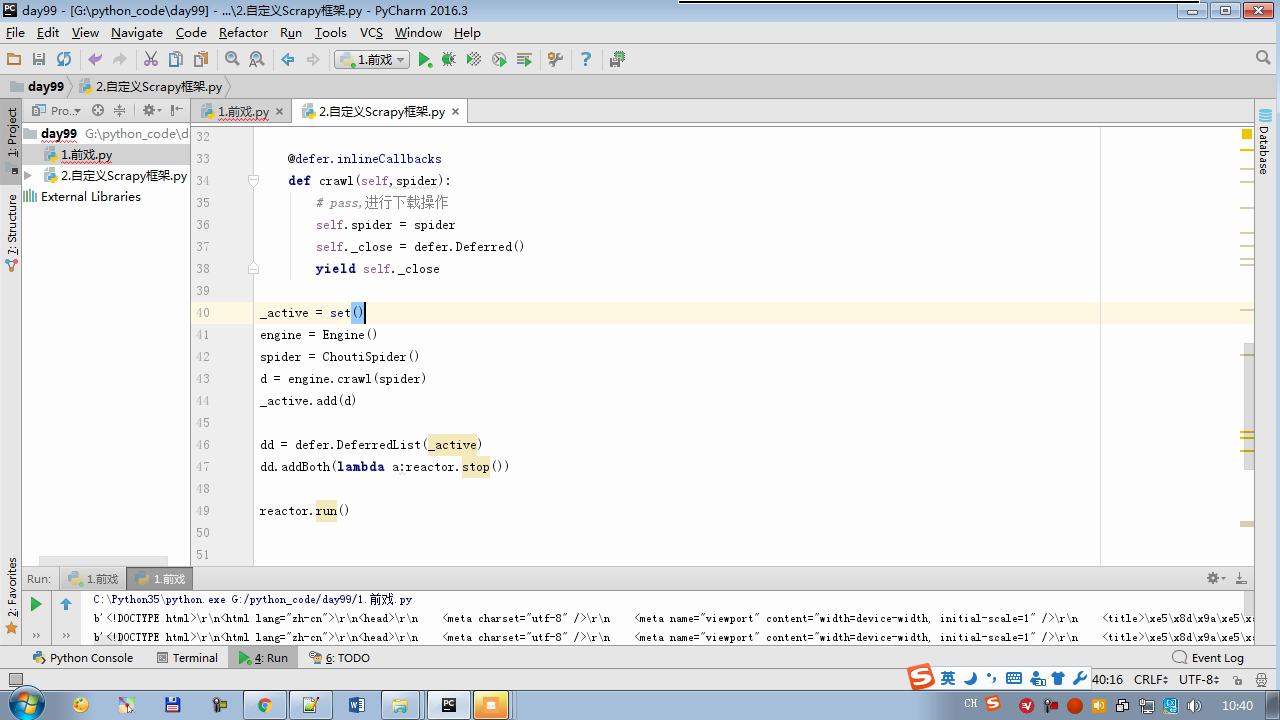
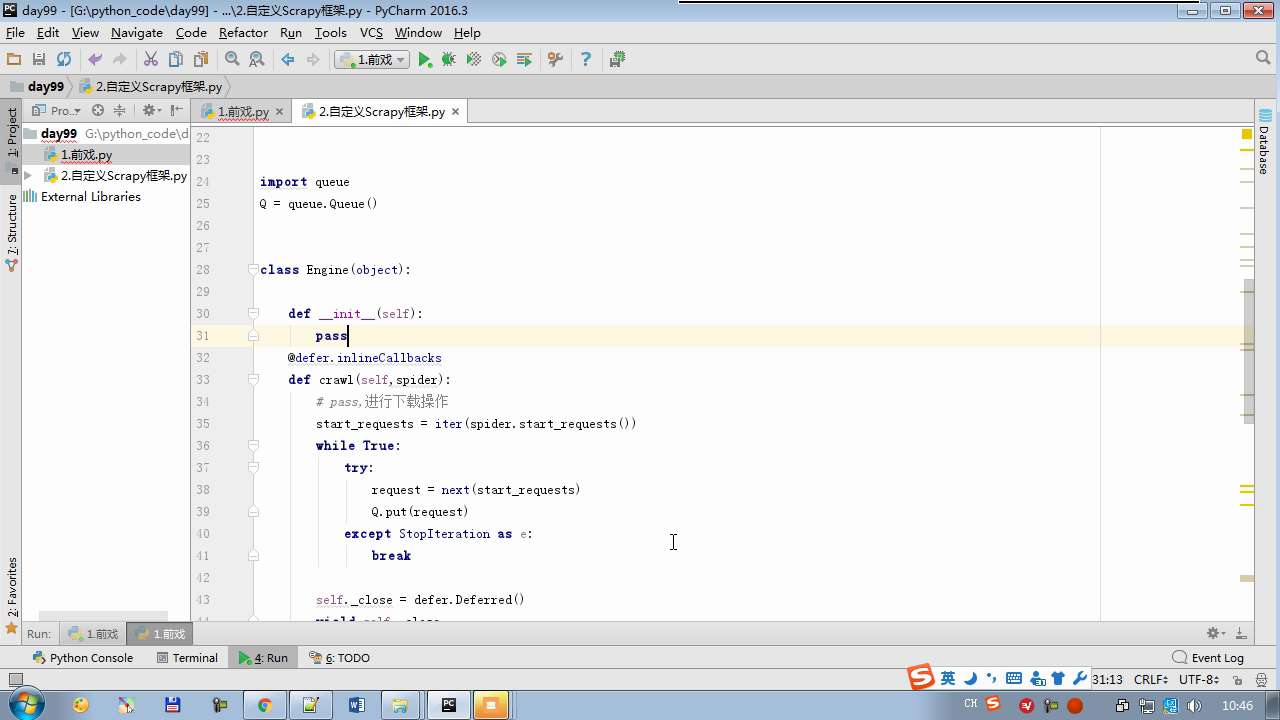
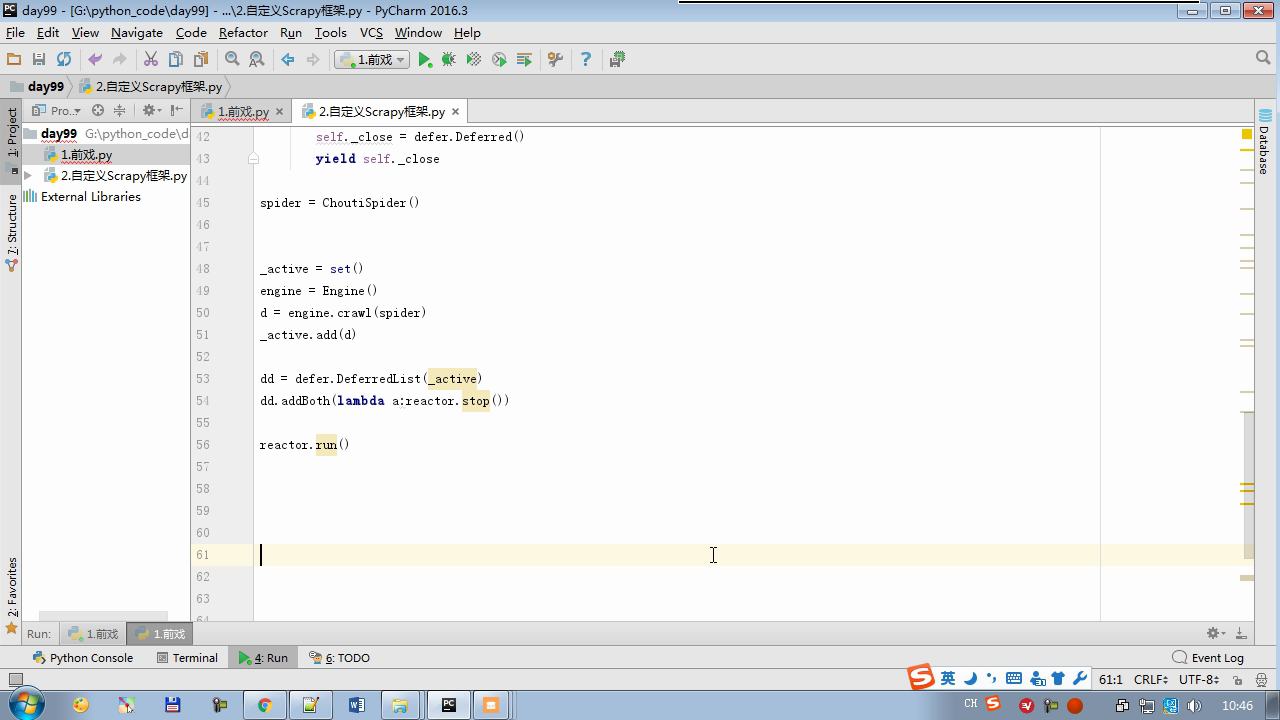
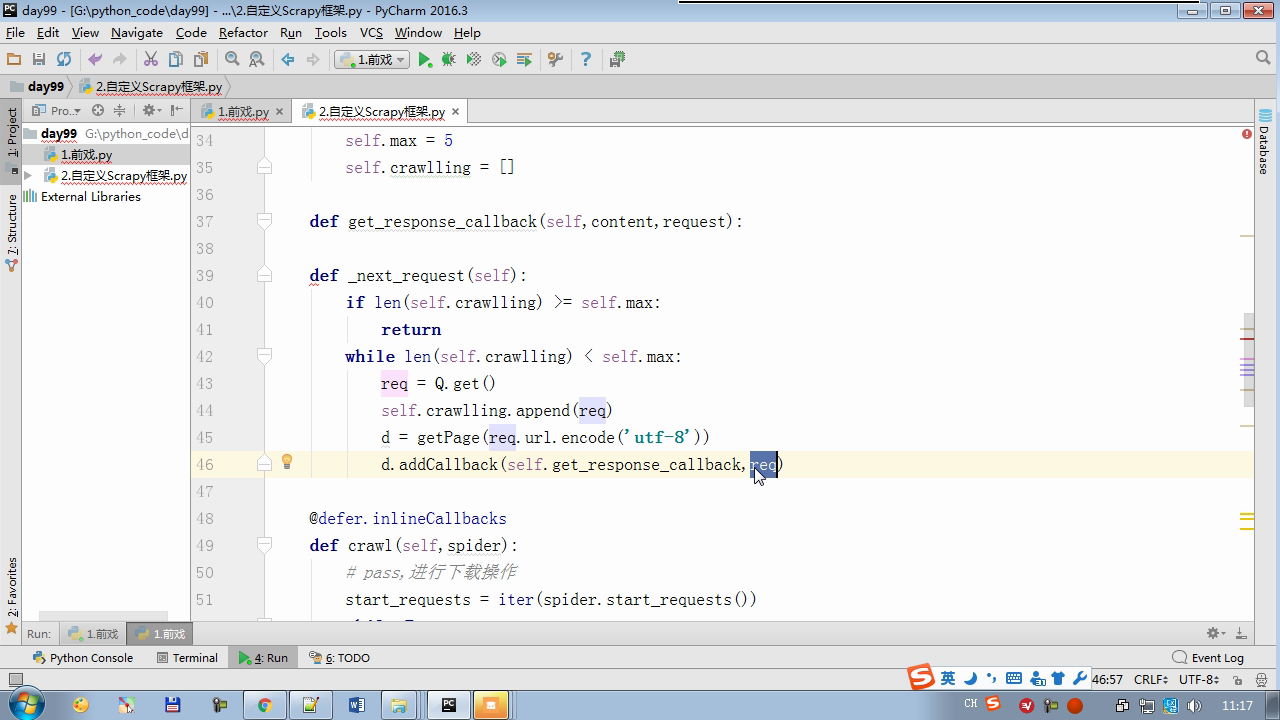
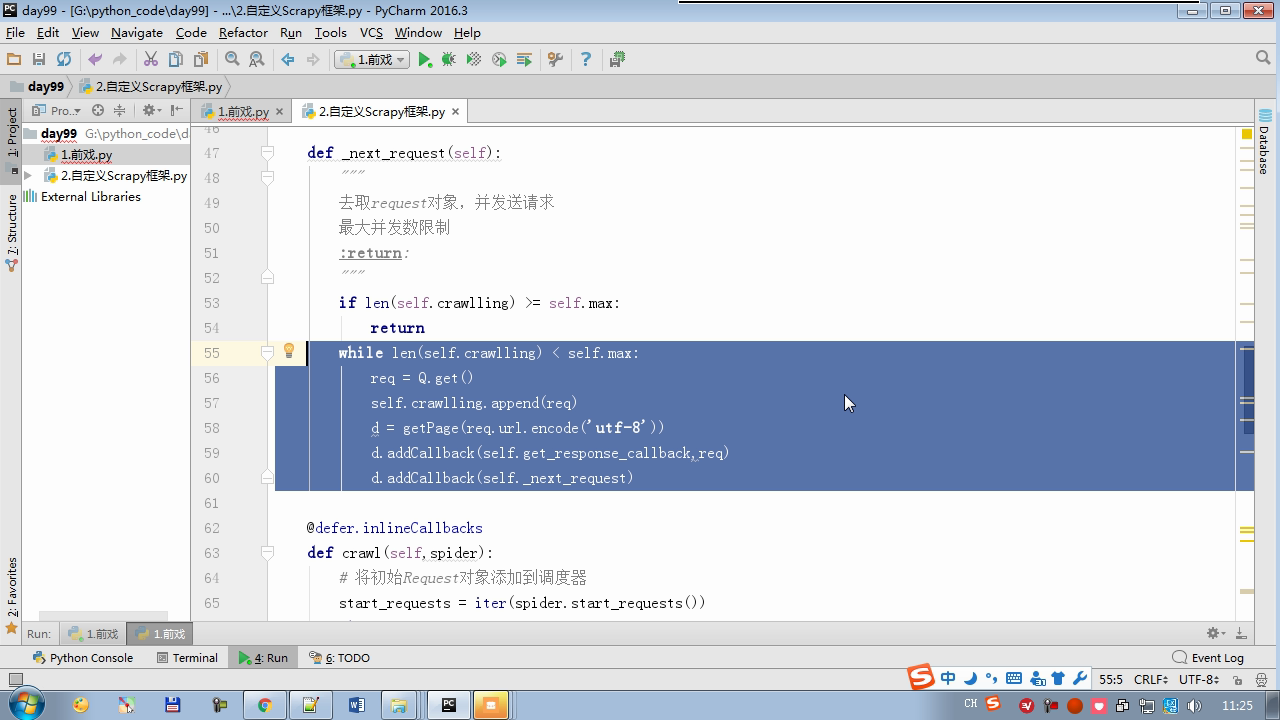
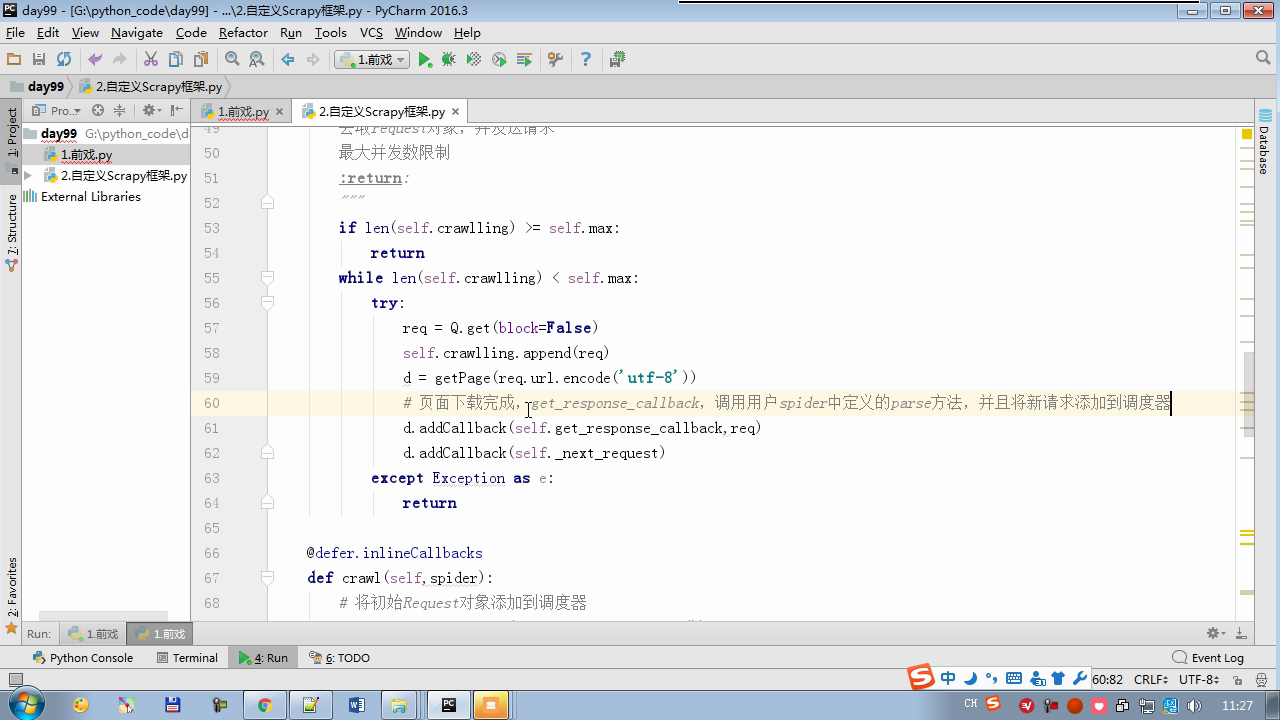
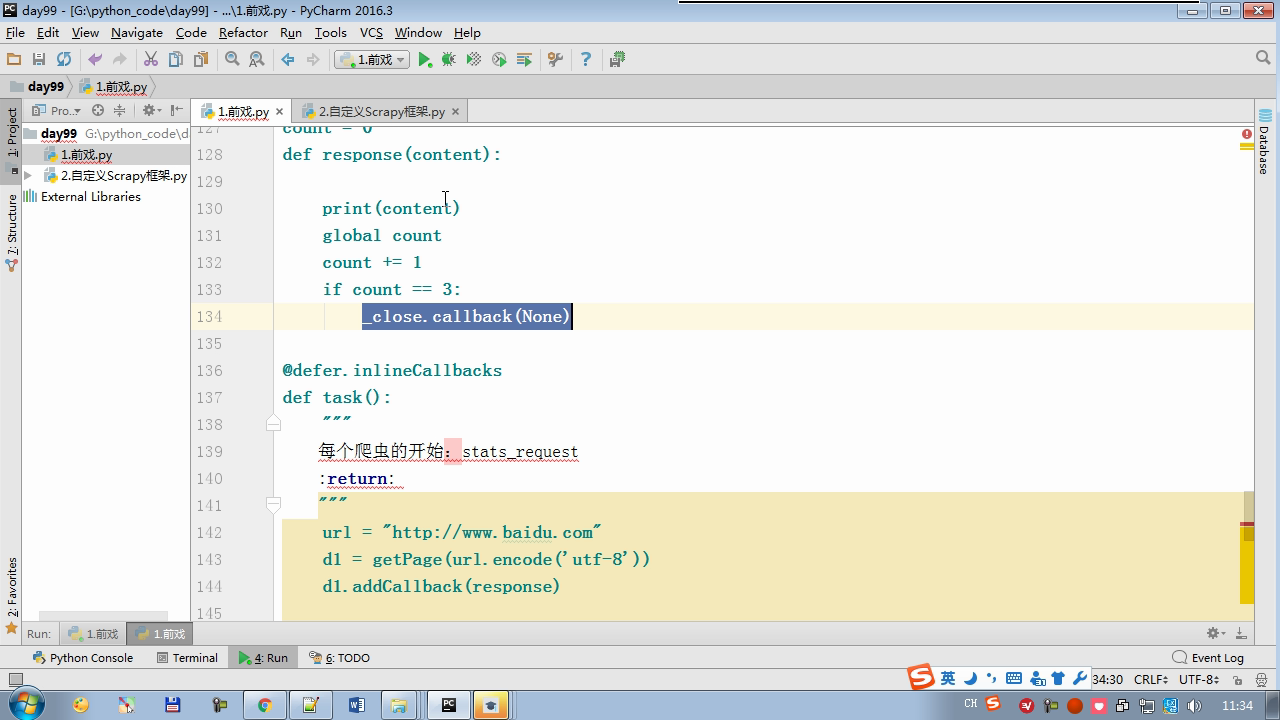
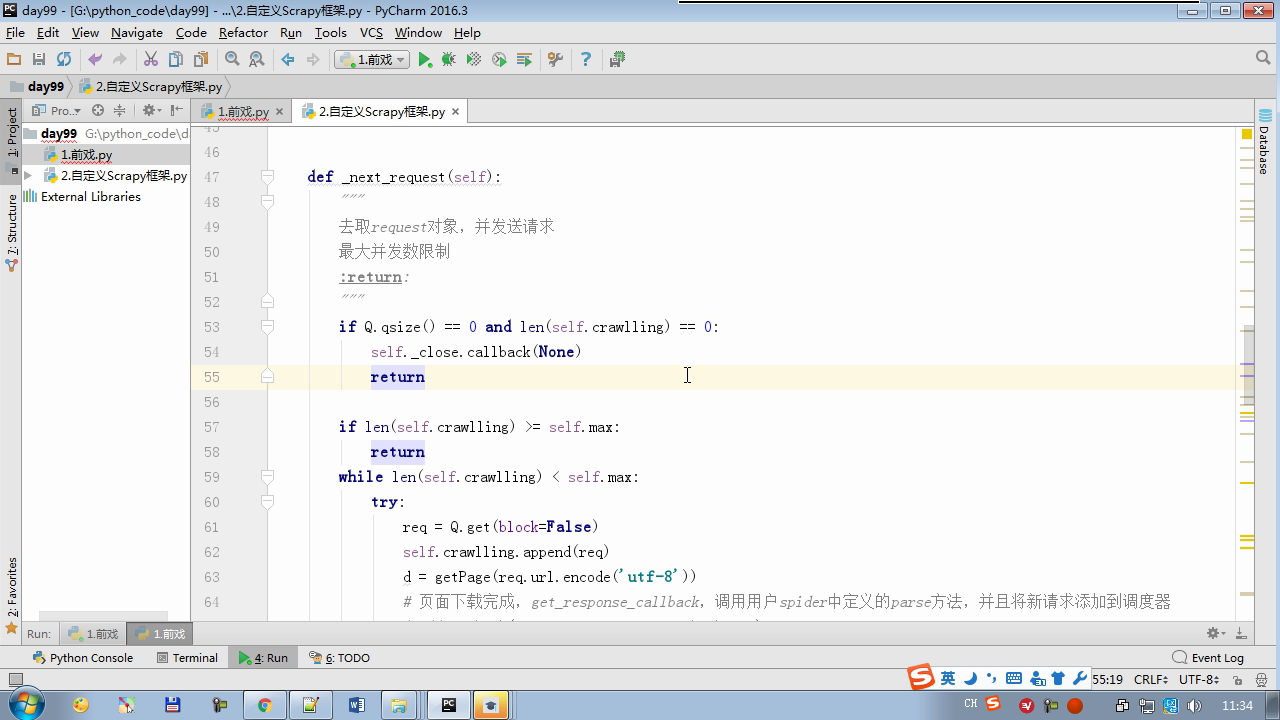
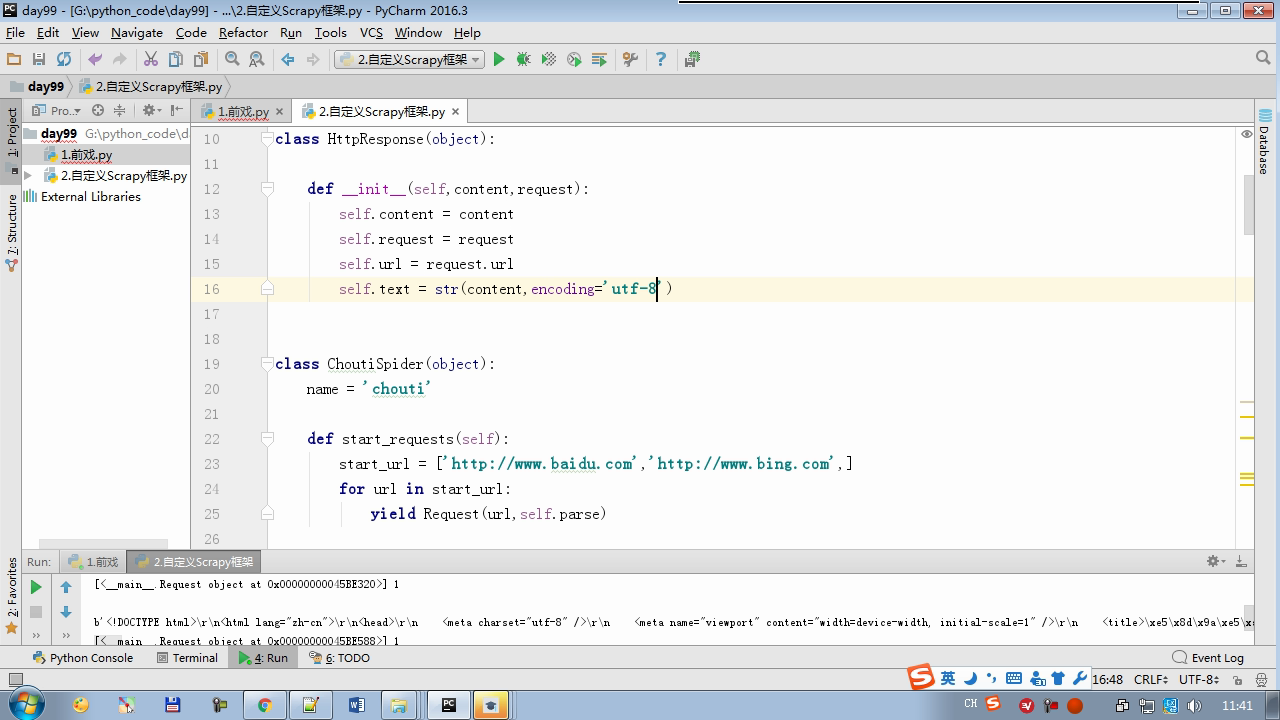
from twisted.internet Import the Reactor # event loop (termination condition, all of the socket have been removed) from twisted.web.client Import getPage # socket objects (if the download is complete, the time automatically removed from circulation ...) from Twisted .internet Import the defer # defer.Deferred special socket objects (not retransmission request, manually remove) class the request (Object): DEF the __init__ (Self, URL, the callback): self.url = URL self.callback = the callback class the HttpResponse (Object): DEF __init__ (Self, Content, Request): self.content = content self.request = request self.url = request.url self.text = str(content,encoding='utf-8') class ChoutiSpider(object): name = 'chouti' def start_requests(self): start_url = ['http://www.baidu.com','http://www.bing.com',] for url in start_url: yield Request(url,self.parse) def parse(self,response): print(response) #response是下载的页面 yield Request('http://www.cnblogs.com',callback=self.parse) import queue Q = queue.Queue() class Engine(object): def __init__(self): self._close = None self.max = 5 self.crawlling = [] def get_response_callback(self,content,request): self.crawlling.remove(request) rep = HttpResponse(content,request) result = request.callback(rep) import types if isinstance(result,types.GeneratorType): for req in result: Q.put(req) def _next_request(self): """ 去取request对象,并发送请求 最大并发数限制 :return: """ print(self.crawlling,Q.qsize()) if Q.qsize() == 0 and len(self.crawlling) == 0: self._close.callback(None) return iflen (self.crawlling)> = self.max: return while len (self.crawlling) < self.max: the try : REQ = Q.get (Block = False) self.crawlling.append (REQ) D = the getPage (REQ. url.encode ( ' UTF-. 8 ' )) # page download is complete, get_response_callback, spider call parse user defined method, and adding a new request to the scheduler d.addCallback (self.get_response_callback, REQ) # does not reach the maximum concurrent number, Get Request vessel may go schedule d.addCallback ( the lambda _: reactor.callLater (0, self._next_request)) the except Exception AS E: Print (E) return @ defer.inlineCallbacks DEF crawl (Self, Spider): # adds the original Request object to the scheduler start_requests = ITER (spider.start_requests ()) the while True: the try : Request = Next ( start_requests) Q.put (request) the except the StopIteration AS E: BREAK # to fetch scheduler request, and sends a request # self._next_request () reactor.callLater (0, self._next_request) self._close = defer.Deferred () the yield self._close spider = ChoutiSpider() _active = set() engine = Engine() d = engine.crawl(spider) _active.add(d) dd = defer.DeferredList(_active) dd.addBoth(lambda a:reactor.stop()) reactor.run()