Spark application is submitted by spark-submit to the Spark cluster running, then the spark-submit in the end submitted what, how clusters are scheduled to run below 11 Xiangjie.
0. spark-submit submit jobs
0.1 startup script parsing
Analysis of spark-submit the final script source code shows the command to execute Java script ./bin/spark-class class of,. / Bin / spark-class script to start the class is org.apache.spark.launcher.Main, spark-submit mode This class will start at SparkSubmitCommandBuilder.java class, end up calling package org.apache.spark.deploy.SparkSubmit.scala.
/ **
* Launching of the Main Gateway Spark A file application. The main application entry start Spark
*
* This Program Handles Setting up Dependencies The CLASSPATH with Relevant Spark Spark and the Provides processing path settings related classes dependent
* a layer over the different cluster managers and deploy modes that Spark supports. abstraction layer provides a different deployment modes supported Spark, encapsulation of the differences trunked mode
* /
Object SparkSubmit {
Task 0.2 parsing - set to submit the task of running the main class
Depending on the cluster model, the task will be resolved on different nodes.
a. CLIENT mode (local mode), when the primary type of task provided runs directly submitting node.
b. CLUSTER mode, this time will be, the main type of task running on the node provided by the cluster of cluster allocation schedule. (Details of the specific allocation skip)
1. The long-awaited --SparkContext
/ **
* Main entry Point for Spark functions on this page. A SparkContext Represents by SparkContext at The Connection to A Spark Spark is the main entrance to the cluster, the cluster is responsible for establishing the connection,
* Cluster, and the Create CAN BE Used to RDDs, Accumulators and Broadcast that the Variables ON cluster. At the same time can create RDD, accumulators and broadcast variables.
*
* Active Only One SparkContext On May BE per JVM. `By You MUST STOP () before the Spark` The Active SparkContext each running a JVM SparkContext example only.
This new new One Creating A * Limitation On May Eventually BE removed;.. See More Details for SPARK-2243
*
* @param the Spark A config file application The Config Object in the Describing Configuration Settings in the Any.
* The overrides The default config configs the this AS AS Well System Properties .
* /
class SparkContext (config: SparkConf) the extends Logging {
In Spark, SparkContext responsible for communication, application of resources, task assignment and monitoring the cluster. Can be understood as an example corresponds to a SparkContext Spark Driver Program (Spark application), present in the entire life cycle of the task.
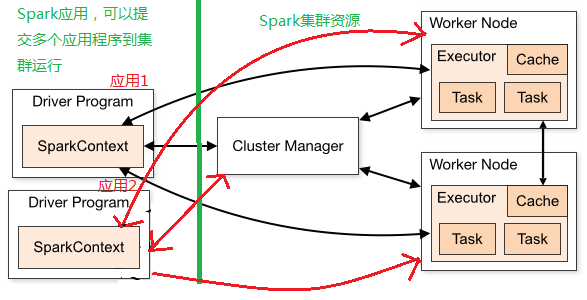
Spark developing applications first need to get SparkContext objects, SparkSession and StreamingContext front will create SparkContext object instance.
def getOrCreate(): SparkSession = synchronized {
...
val sparkContext = userSuppliedContext.getOrElse {
// set app name if not given
val randomAppName = java.util.UUID.randomUUID().toString
val sparkConf = new SparkConf()
options.foreach { case (k, v) => sparkConf.set(k, v) }
if (!sparkConf.contains("spark.app.name")) {
sparkConf.setAppName(randomAppName)
}
val sc = SparkContext.getOrCreate(sparkConf)
private[streaming] val sc: SparkContext = {
if (_sc != null) {
_sc
} else if (isCheckpointPresent) {
SparkContext.getOrCreate(_cp.createSparkConf())
} else {
throw new SparkException("Cannot create StreamingContext without a SparkContext")
}
}
SparkContext contains four core objects: DAGScheduler, TaskScheduler, SchedulerBackend, MapOutputTaskMaster, described in detail later in the four core subject.
SchedulerBackend is a traint, depending on the operating method, examples of different objects. To StandaloneSchedulerBackend, for example, has three main functions:
1. responsible for communication with the Master, the current registration procedure RegisterWithMaster;
2. Receive a cluster computing resources Excutor registered current application distribution and management Executors;
3. responsible for sending to a specific Task Executor execution.
During instantiation 1.1 SparkContext
1. SparkContext When instantiated, not all members of the process will be instantiated. createTaskScheduler SparkContext located block of code will be executed when the instantiation;
2. createTaskScheduler will return the corresponding tuple (SchedulerBackend, TaskScheduler) depending on the type of cluster, to Standalone an example, return (StandaloneSchedulerBackend, TaskSchedulerImpl);
// Create and start the scheduler
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's
// constructor
_taskScheduler.start()
3. Run _taskScheduler.start () method, SchedulerBackend (here StandaloneSchedulerBackend) which start method call;
4. The task-start method StandaloneSchedulerBackend the package information, the call StandaloneAppClientstart method (here only registered job information, and will not submit the job);
// Start executors with a few necessary configs for registering with the scheduler
val sparkJavaOpts = Utils.sparkJavaOpts(conf, SparkConf.isExecutorStartupConf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries ++ testingClassPath, libraryPathEntries, javaOpts)
val appUIAddress = sc.ui.map(_.appUIAddress).getOrElse("")
val coresPerExecutor = conf.getOption("spark.executor.cores").map(_.toInt)
...
client = new StandaloneAppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
client.start()
5. StandaloneAppClient (registered to the Master task of the client, not the Driver) method creates ClientEndPoint objects, call their onStart method, onStart will call registerWithMaster method to register with the Master;
2. Master task registration information
receive method Master of receipt of the registration information StandaloneAppClient, mainly to complete the following tasks:
1. Registration Application Information app
2. The successful registration informationdriver.send (RegisteredApplication (app.id, self) ) back to the requesting client registration StandaloneAppClient ( this time has been registered task )
3. Call the schedule method to allocate resources for the task
case RegisterApplication(description, driver) =>
// TODO Prevent repeated registrations from some driver
if (state == RecoveryState.STANDBY) {
// ignore, don't send response
} else {
logInfo("Registering app " + description.name)
val app = createApplication(description, driver)
registerApplication(app)
logInfo("Registered app " + description.name + " with ID " + app.id)
persistenceEngine.addApplication(app)
driver.send(RegisteredApplication(app.id, self))
schedule()
}
The method for resource allocation schedule main driver and the worker, and the specific Dirver Executor run the Worker; Worker assigning resources to tasks and starts the corresponding Dirver Executors and perform tasks.
/**
* Schedule the currently available resources among waiting apps. This method will be called
* every time a new app joins or resource availability changes.
*/
private def schedule(): Unit = {
if (state != RecoveryState.ALIVE) {
return
}
// Drivers take strict precedence over executors
val shuffledAliveWorkers = Random.shuffle(workers.toSeq.filter(_.state == WorkerState.ALIVE))
val numWorkersAlive = shuffledAliveWorkers.size
var curPos = 0
for (driver <- waitingDrivers.toList) { // iterate over a copy of waitingDrivers
// We assign workers to each waiting driver in a round-robin fashion. For each driver, we
// start from the last worker that was assigned a driver, and continue onwards until we have
// explored all alive workers.
var launched = false
var numWorkersVisited = 0
while (numWorkersVisited < numWorkersAlive && !launched) {
val worker = shuffledAliveWorkers(curPos)
numWorkersVisited += 1
if (worker.memoryFree >= driver.desc.mem && worker.coresFree >= driver.desc.cores) {
launchDriver(worker, driver) //加载Driver
waitingDrivers -= driver
launched = true
}
curPos = (curPos + 1) % numWorkersAlive
}
}
startExecutorsOnWorkers() // start Workers
}
3. Worker start Driver
3.1 Driver startup
Master LaunchDriver send a message to call the start method of the object after object is to create a DriverRunner After Worker, Worker receive the message, create a complete startup.
case LaunchDriver(driverId, driverDesc) =>
logInfo(s"Asked to launch driver $driverId")
val driver = new DriverRunner
Finally, start method will call prepareAndRunDriver start a process by Driver runDriver.
Methods downloadUserJar jar package to the user's local.
private[worker] def prepareAndRunDriver(): Int = {
val driverDir = createWorkingDirectory()
val localJarFilename = downloadUserJar(driverDir)
def substituteVariables(argument: String): String = argument match {
case "{{WORKER_URL}}" => workerUrl
case "{{USER_JAR}}" => localJarFilename
case other => other
}
// TODO: If we add ability to submit multiple jars they should also be added here
val builder = CommandUtils.buildProcessBuilder(driverDesc.command, securityManager,
driverDesc.mem, sparkHome.getAbsolutePath, substituteVariables)
runDriver(builder, driverDir, driverDesc.supervise)
}
Several Issues of 3.2 Driver
a. Driver means that the submitted application, are defined as follows in DriverDescription.
override def toString: String = s"DriverDescription (${command.mainClass})"
b. Driver is loaded in the Worker run, run on which specific Worker, assigned by the Master, worker.endpoint.send (LaunchDriver (driver.id, driver.desc)).
private def launchDriver(worker: WorkerInfo, driver: DriverInfo) {
logInfo("Launching driver " + driver.id + " on worker " + worker.id)
worker.addDriver(driver)
driver.worker = Some(worker)
worker.endpoint.send(LaunchDriver(driver.id, driver.desc))
driver.state = DriverState.RUNNING
}
Applications c. Driver is not submitted, the Worker Driver is instantiated DriverRunner objects, is the process Worker in a stand-alone, is responsible for managing the execution of the Driver and fail to restart.
/** * Manages the execution of one driver, including automatically restarting the driver on failure. * This is currently only used in standalone cluster deploy mode. */ private[deploy] class DriverRunner(
d. seen from the Master during registration and schedule application method, an application corresponding to a Driver, there may be a plurality of Worker (Executors).
4. Worker start Executor
Master schedule in startExecutorsOnWorkers method call will eventually send messages to LaunchExecutor Worker, by val manager = new ExecutorRunner ExecutorRunner object to instantiate a task to run.
ExecutorRunner method calls fetchAndRunExecutor create a new process to perform the task.
/**
* Download and run the executor described in our ApplicationDescription
*/
private def fetchAndRunExecutor() {
try {
// Launch the process
val builder = CommandUtils.buildProcessBuilder(appDesc.command, new SecurityManager(conf),
** appDesc.command to StandaloneSchedulerBackend incoming command, namely Worker nodes start ExecutorRunner, ExecutorRunner process will start CoarseGrainedExecutorBackend
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
In onStart CoarseGrainedExecutorBackend method, the registration request is sent to the RedisterExecutor Driver.
override def onStart() {
logInfo("Connecting to driver: " + driverUrl)
rpcEnv.asyncSetupEndpointRefByURI(driverUrl).flatMap { ref =>
// This is a very fast action so we can use "ThreadUtils.sameThread"
driver = Some(ref)
ref.ask[Boolean](RegisterExecutor(executorId, self, hostname, cores, extractLogUrls))
After processing the registration request Driver will return the results to the CoarseGrainedExecutorBackend registration, registration is successful CoarseGrainedExecutorBackend creates a new Executor executor, so far Executor created.
override def receive: PartialFunction[Any, Unit] = {
case RegisteredExecutor =>
logInfo("Successfully registered with driver")
try {
executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false)
} catch {
case NonFatal(e) =>
exitExecutor(1, "Unable to create executor due to " + e.getMessage, e)
}
* You can start multiple Executors each Worker, each Executor is a separate process.
* Flow chart below shows the user submits the task of Spark
