The code used in this blog, see end of this article
The similarity measure two pictures there are many algorithms, this paper describes the engineering field say the most commonly used one picture similarity algorithm --Hash algorithm. Hash algorithm is accurate to say that there are three, namely the average hash algorithm (aHash), perceptual hashing algorithm you (pHash) and the difference Haha Xi algorithm (dHash).
Hamming distance Hash algorithms are three kinds of images acquired by hash value, then compare the two pictures hash value (the concept of Han Ming visible from the public this number "," a text) to measure the two pictures are similar. The more similar the two images, the smaller the number of hash Hamming distance of two pictures. The following article will introduce the three Hash algorithm.
1 Average hashing algorithm (aHash)
1.1 algorithm steps
The average hash algorithm Hash algorithms are the three most simple one, it is obtained by the following Hash value image several steps, and these steps are (1) Image scaling; (2) to grayscale; ( 3) the mean pixel count; (4) according to the similarity calculating average fingerprint. The algorithm is as follows:
| step | specific contents |
|---|---|
| Zoom Image | Enter the picture sizes vary, in order to enter a unified image, unified will scale the image size is 8 * 8, received a total of 64 pixels. |
| Grayscale | Some input is single-channel grayscale images, some three-channel RGB color map, some are four-channel RGBA color map. In order to unify the standard input is also the next step, the non-single-channel single-channel grayscale images are converted. Wherein RGB three-channel single-channel switch algorithm are the following categories: 1. Floating-Point Arithmetic: R & lt Gray = 0.3 G + 0.59 B + 0.11 2. Method integer: Gray = (R & lt 30 + G 59 + B . 11) / 100 . 3. shifting method: Gray = (R & lt 76 + G 151 * + 28 B) >>. 8; 4. average method: Gray = (R & lt + G + B) /. 3; 5. The only take green: Gray = G; |
| The average pixel count | Previous available by a 8x8 matrix of integers G, calculates the average of all the elements of this matrix, it is assumed that a |
| According to calculate the average pixel fingerprint | Initialization input picture ahash = "" left to right, line by line traversing each pixel matrix G if row i and column j element G (i, j)> = a, then ahash + = "1" if the i-th row j column element G (i, j) <a , then ahash + = "0" |
The value obtained ahash picture, two pictures comparing the Hamming distance values ahash, typically a group of pictures that the Hamming distance is less than 10 images.
Specific examples 1.2
This picture is Lena diagram to illustrate.

FIG 1 Lena (Origin) FIG.
FIG 2 FIG Lena into 8x8 size
3 Switch Lena FIG 8x8 size gradation
Wherein the size of the Lena into 8x8 matrix corresponding to the data:
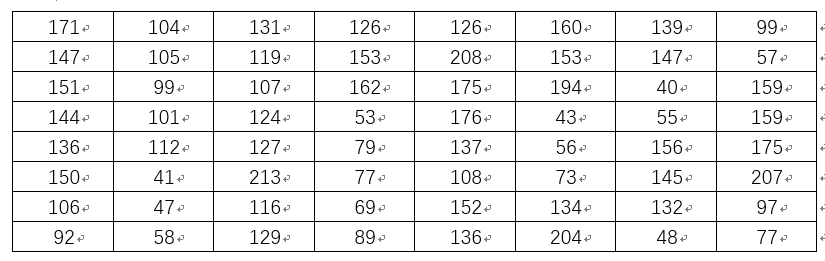
Content is obtained as the mean of all elements in the matrix a = 121.328125, the above-described matrix element is greater than or equal to a set to 1, the elements of a set to less than 0, can be obtained:
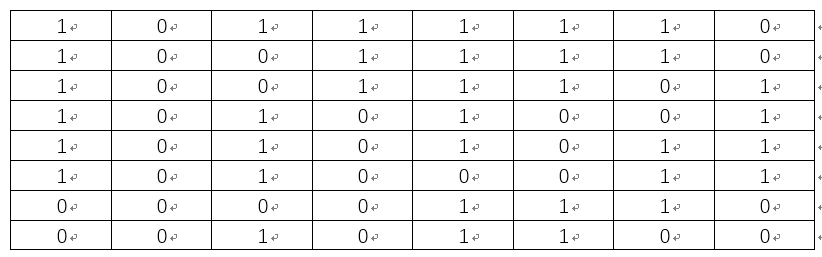
所以可得Lena图的aHash为
1011111010011110100111011010100110101011101000110000111000101100
将二进制形式ahash转十六进制hash为
be9e9da9aba30e2c
为了测试aHash算法的效果,我们用一张带噪声Lena(noise)图和与Lena不一样的Barbara做图片相似度对比实验,其中Lena(noise)和Barbara如下:

图4 Lena(noise)图

图5 Barbara图
通过aHash算法容易得三个图片的hash值,然后根据hanming距离计算Lena(origin).png和Lena(noise).png Barbar.png之间汉明距离,具体如下:
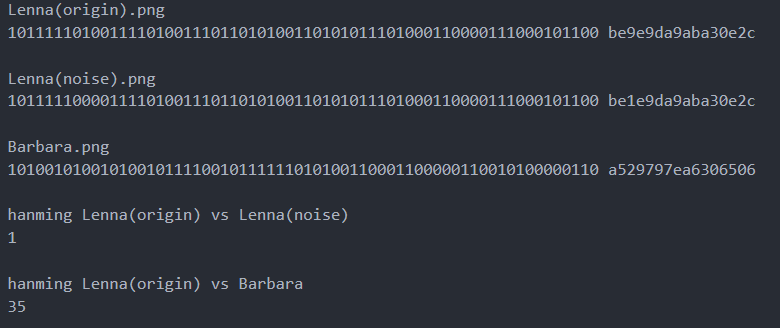
图6 aHash算法图片相似度实验
由上图可见aHash能区别相似图片和差异大的图片。
2 感知哈希算法(pHash)
2.1 算法步骤
感知哈希算法是三种Hash算法中较为复杂的一种,它是基于DCT(离散余弦变换)来得到图片的hash值,其算法几个步骤分别是(1) 缩放图片;(2)转灰度图; (3) 计算DCT;(4)缩小DCT; (5)算平均值;(6) 计算指纹。具体算法如下所示:
| 步骤 | 具体内容 |
|---|---|
| 缩放图片 | 统一将图片尺寸缩放为32*32,一共得到了1024个像素点。 |
| 转灰度图 | 统一下一步输入标准,将非单通道图片都转为单通道灰度图。 |
| 计算DCT | 计算32x32数据矩阵的离散余弦变换后对应的32x32数据矩阵 |
| 缩小DCT | 取上一步得到32x32数据矩阵左上角8x8子区域 |
| 算平均值 | 通过上一步可得一个8x8的整数矩阵G, 计算这个矩阵中所有元素的平均值,假设其值为a |
| 计算指纹 | 初始化输入图片的phash = "" 从左到右一行一行地遍历矩阵G每一个像素 如果第i行j列元素G(i,j) >= a,则phash += "1" 如果第i行j列元素G(i,j) <a, 则phash += "0" |
得到图片的phash值后,比较两张图片phash值的汉明距离,通常认为汉明距离小于10的一组图片为相似图片。
2.2 具体实例
仍用Lena图来说明.
图7 转为灰度32x32尺寸的Lena图

图8 灰度32x32尺寸Lena图对应的DCT矩阵
通过计算可得灰度32x32Lenna图对应的DCT矩阵左上角8x8区域子矩阵为:

很容得到如上矩阵所有元素的均值a= 77.35, 将上述矩阵中大于或等于a的元素置为1, 小于a的元素置为0,可得:
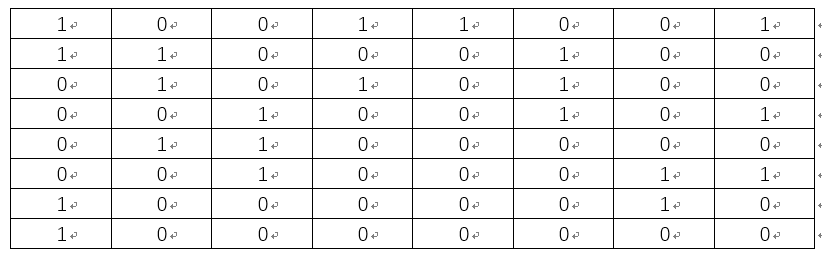
所以可得Lena图的pHash为
1001100111000100010101000010010101100000001000111000001010000000
将二进制形式phash转十六进制hash为
99c4542560238280
为了测试pHash算法的效果,同样用一张带噪声Lena(noise)图和与Lena不一样的Barbara做图片相似度对比实验。通过pHash算法容易得三个图片的hash值,然后根据hanming距离计算Lena(origin).png和Lena(noise).png Barbar.png之间汉明距离,具体如下:
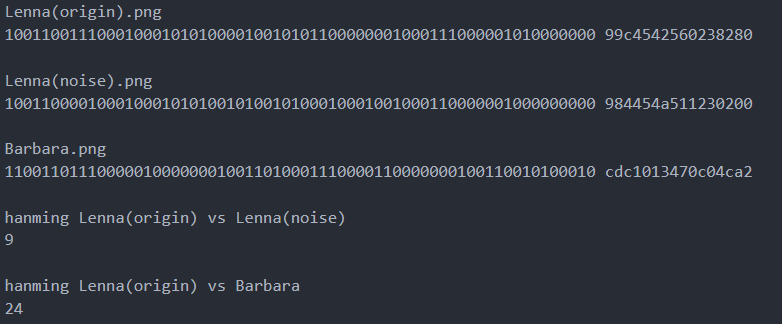
图9 pHash算法图片相似度实验
由上图可见pHash能区别相似图片和差异大的图片。
3 差异哈希算法(dHash)
3.1 算法步骤
相比pHash,dHash的速度要快的多,相比aHash,dHash在效率几乎相同的情况下的效果要更好,它是基于渐变实现的。其算法几个步骤分别是(1) 缩放图片;(2)转灰度图; (3) 计算DCT;
(4)缩小DCT; (5)算平均值;(6) 计算指纹。具体算法如下所示:
| 步骤 | 具体内容 |
|---|---|
| 小图片 | 统一将图片尺寸缩放为9x8,一共得到了72个像素点 |
| 转灰度图 | 统一下一步输入标准,将非单通道图片都转为单通道灰度图。 |
| 算差异值 | 当前行像素值-前一行像素值, 从第二到第九行共8行,又因为矩阵有8列,所以得到一个8x8差分矩阵G |
| 算平均值 | 通过上一步可得一个8x8的整数矩阵G, 计算这个矩阵中所有元素的平均值,假设其值为a |
| 计算指纹 | 初始化输入图片的dhash = "" 从左到右一行一行地遍历矩阵G每一个像素 如果第i行j列元素G(i,j) >= a,则dhash += "1" 如果第i行j列元素G(i,j) <a, 则dhash += "0" |
得到图片的phash值后,比较两张图片phash值的汉明距离,通常认为汉明距离小于10的一组图片为相似图片。
3.2 具体实例
仍用Lena图来说明.

图7 转为灰度9x8尺寸的Lena图
通过计算可得灰度9x8Lenna图数据矩阵为:
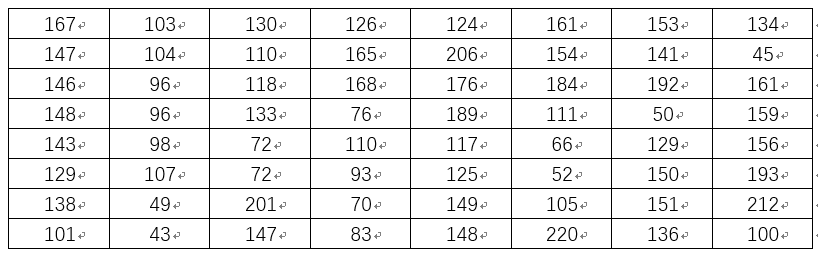
从第二行开始进行减去前一行操作,可得如下查分矩阵
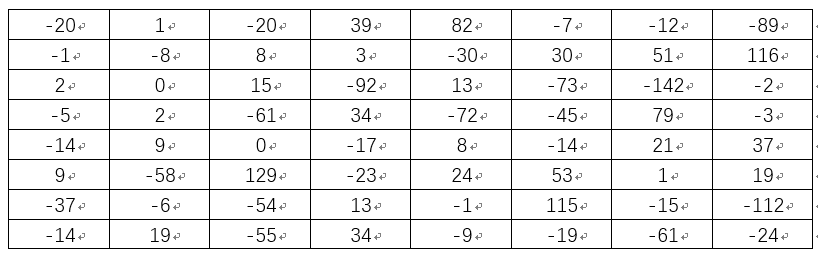
将上述矩阵中大于或等于0元素置为1, 小于a的元素置为0,可得:
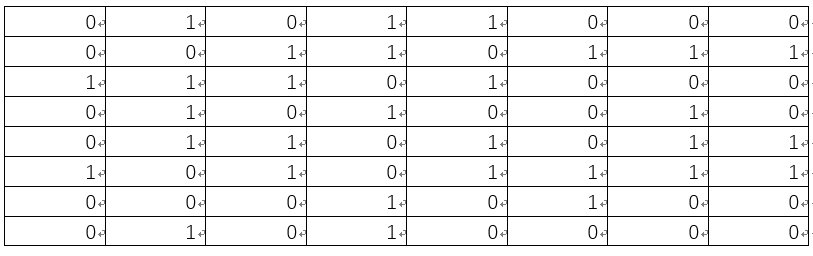
所以可得Lena图的dHash为
0101100000110111111010000101001001101011101011110001010001010000
将二进制形式dhash转十六进制hash为
99c4542560238280
为了测试dHash算法的效果,同样用一张带噪声Lena(noise)图和与Lena不一样的Barbara做图片相似度对比实验。通过pHash算法容易得三个图片的hash值,然后根据hanming距离计算Lena(origin).png和Lena(noise).png Barbar.png之间汉明距离,具体如下:

图9 dHash算法图片相似度实验
由上图可见dHash能区别相似图片和差异大的图片。
总结
关于图像相似度算法除了Hash算法,在传统算法领域中还有基于SIFT的匹配算法,基于Gist特征的匹配算法;在深度学习领域中有基于ResNet全连接的匹配算法。感兴趣的读者可以通过google来了解这些算法。
参考资料
432-Looks-Like-It
529-Kind-of-Like-That