introduction
For simple identification code and a number of images, we need to use pytesseract and the corresponding Tesseract engine, it is open source OCR engine. Help us do some simple image recognition
Of course, in order to better identify the picture, some of the pixels of the picture is relatively low, we will do a certain gray scale processing, image recognition convenience , reference https://www.jb51.net/article/141428.htm
In the image recognition process, we should pay attention to identify the image content not to close borders
For a single number we have to do the appropriate processing parameters, otherwise not identify them.
We can get from gitHUB the Tesseract engine, and the corresponding training data, now with New Version 4.0, the download URL: https: //github.com/tesseract-ocr/tesseract/wiki
First, install pytesseract and PIL
PIL full name: Python Imaging Library, python image processing library that supports multiple file formats, and provides powerful image processing and graphics capabilities.
Due to the PIL only supports Python 2.7, so on the basis of the PIL created Pillow library, support for the latest Python 3.x.
1, pip install command
pip install pytesseract
pip install Pillow
2, using pycharm editor installed, the following procedure.
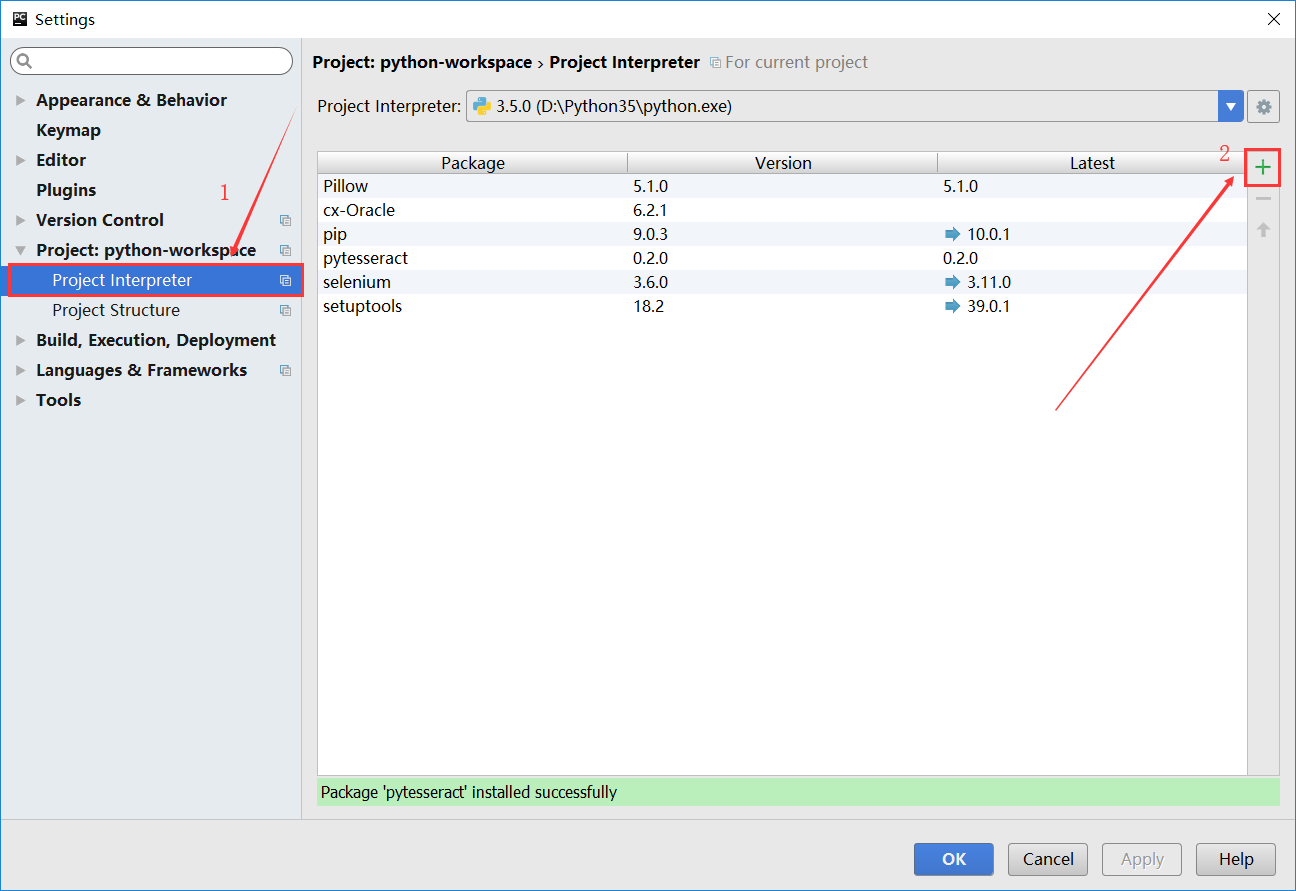

Successful installation:
When installing pytesseract, install pillow, so we only need to install pytesseract can be.
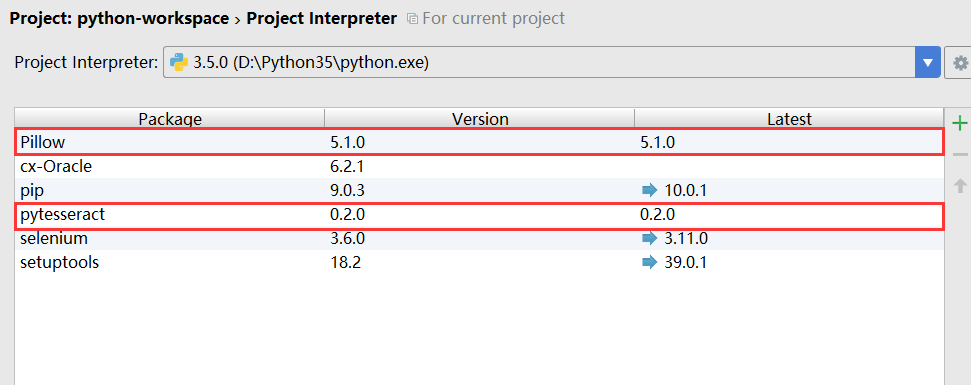
3. Try to run,
Source as follows:

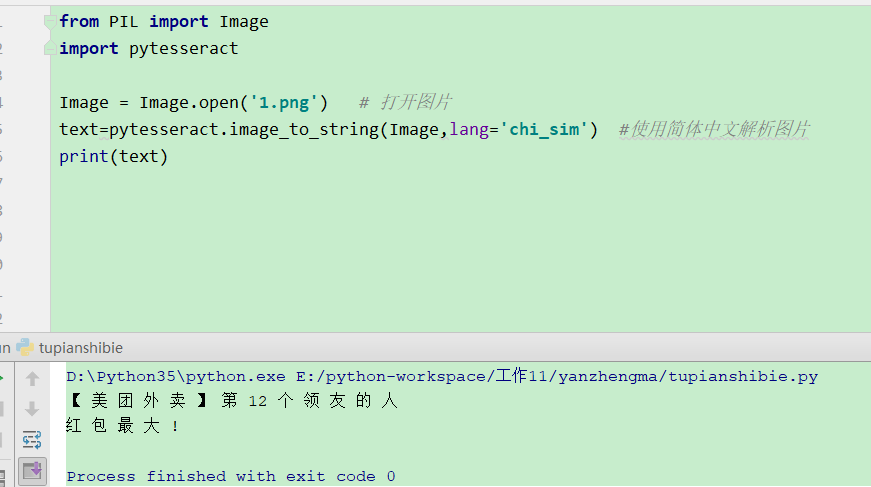
1 from PIL import Image
2 import pytesseract
3
4 Image = Image.open('1.png') # 打开图片
5 text = pytesseract.image_to_string(Image,lang='chi_sim') #使用简体中文解析图片
6 print(text)
出现报错,如下图,
原因:没有安装识别引擎tesseract-ocr
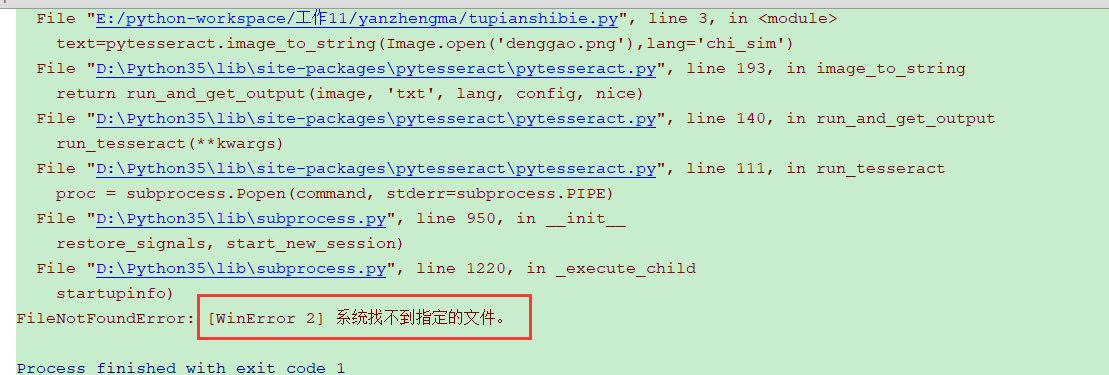
二、安装识别引擎tesseract-ocr
1.Tesseract是开源的OCR引擎。Tesseract最初设计用于英文识别,经过改进引擎和训练系统,它能够处理其它语言和UTF-8字符。Tesseract 3.0能够处理任何Unicode字符,但并非在所有语言上都工作得很好。Tesseract在庞大字符集语言(比如中文)上较慢,但是工作良好。
下载链接: https://pan.baidu.com/s/1J0HNoVhX8WexS_5r0k2jDw 密码: ywc3

因为tesseract-ocr默认不支持中文识别。
将下载到的文件:chi_sim.traineddata 放到Tesseract-OCR安装目录 D:\Program Files (x86)\Tesseract-OCR\tessdata 下,如图:
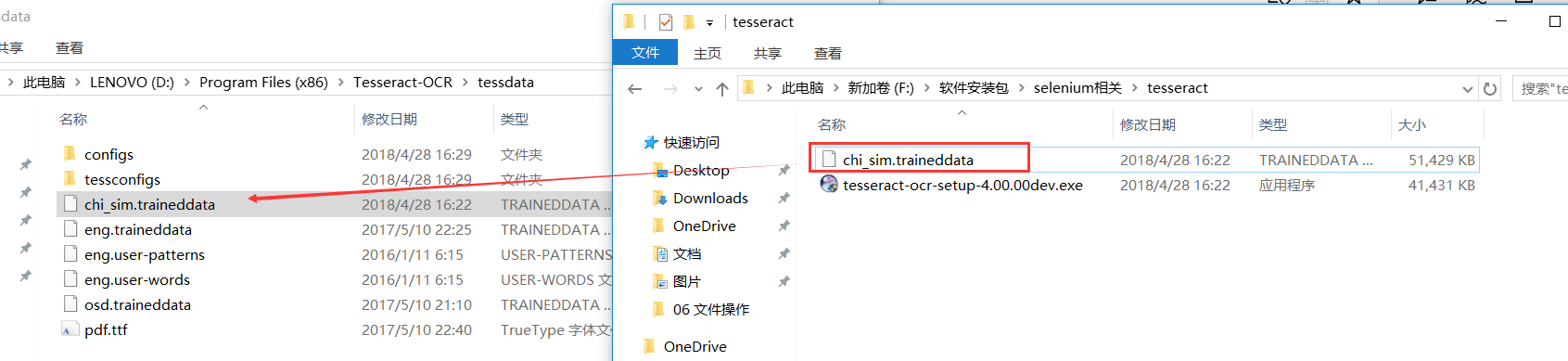
2,安装完成tesseract-ocr后,需要做一下配置 。
在Python安装目录(如:D:\Python35\Lib\site-packages\pytesseract) 中修改 pytesseract.py文件。

也可以通过pycharm,Ctrl+B 快速打开pytesseract源码文件:

3.尝试运行,出现如下报错:
pytesseract.pytesseract.TesseractError: (1, 'Error opening data file \\Program Files (x86)\\Tesseract-OCR\\chi_sim.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory. Failed loading language \'chi_sim\' Tesseract couldn\'t load any languages! Could not initialize tesseract.')

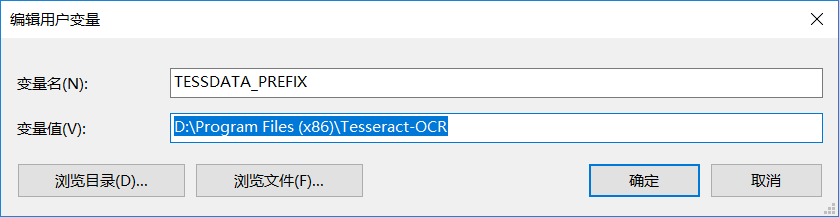
4.解决方法:将tessdata目录的上级目录所在路径:(默认为tesseract-ocr安装目录)添加至TESSDATA_PREFIX环境变量中,如下图:
注意:配置完环境变量需要重新打开pycharm编辑器(IDE)。
5.再次运行结果:图片识别成功!
但识别率不是很高,后期优化,持续更新。