Introduction:
First grab one page of data - "View more information see the reason why is because the page -" so you can grab the first page of data, recycle page you can get all the data
Was arrested Address: http://jhsjk.people.cn/result/?area=402
divided 3

Grab all the titles one data
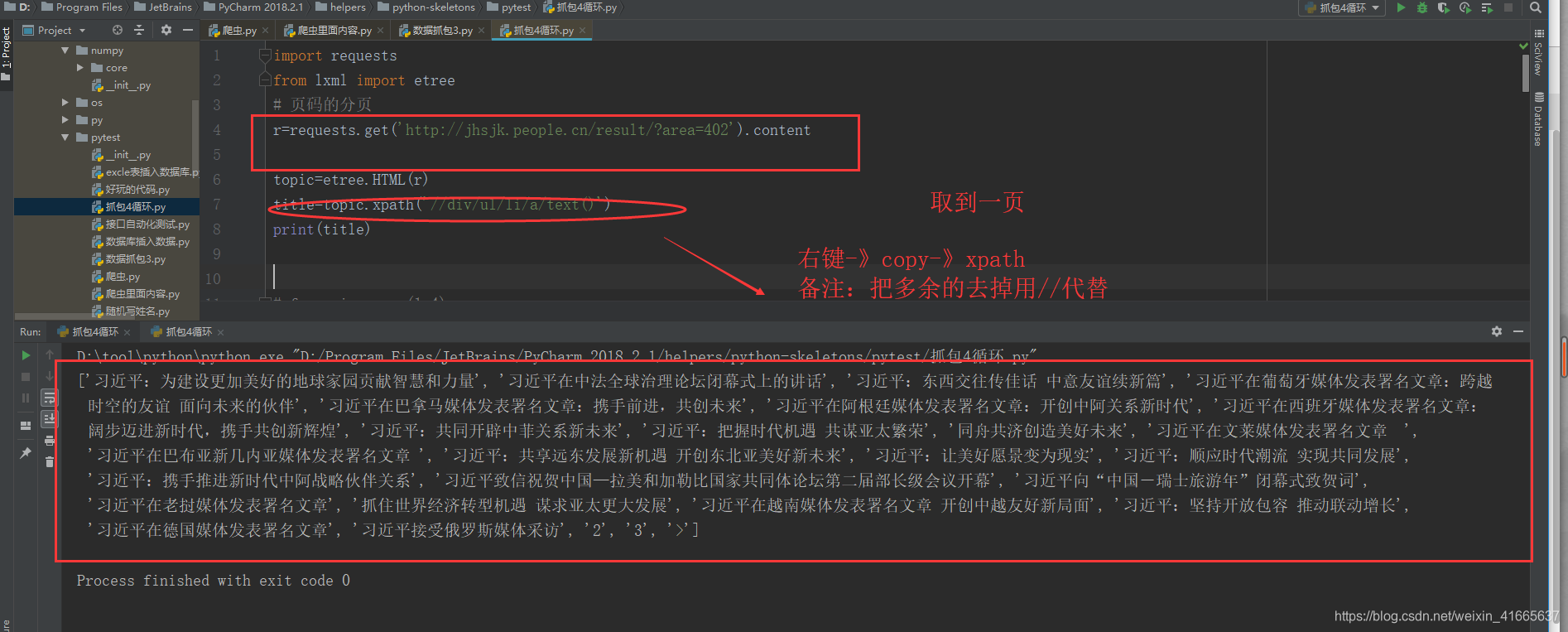

import requests
from lxml import etree
# 页码的分页
r=requests.get('http://jhsjk.people.cn/result/?area=402').content
topic=etree.HTML(r)
title=topic.xpath('//div/ul/li/a/text()')
print(title)
``
==========翻页
分析

翻页

运用到代码中

import requests
from lxml import etree
for a in range(1,4):
m=‘http://jhsjk.people.cn/result/’+str(a)+’?area=402’
l=requests.get(m).content
topic=etree.HTML(l)
title=topic.xpath('//div/ul/li/a/text()')
for x in title:
print(x)