Decision tree (decision tree)
Decision Tree: is a basic classification and regression methods. It is based on the characteristics of the process instance classification instance, we can consider the decision tree is a lot of if-then rule set.
Advantages: 1) training models generated readable, we can directly see the work has been constituted to generate a model of the way, because the model is the data attributes and categories constitute a tree.
2) Because it is a tree, so that the speed predicted classification, a tree could think about how much depth. Even if it is a binary tree with N data, depth and only logN.
Principle: decision tree model based on the principle of minimizing the loss function (in fact, most models are this principle)
Step: 1) feature selection (different algorithms, different choice, such as CART feature is randomly chosen m)
2) generates a decision tree (split is carried out continuously by attribute data, until the leaf node)
Now present the main decision tree algorithms: ID3, C4.5, the CART, RandomForest .....
Entropy:
(Introduction to entropy in Wu's book "mathematical beauty" has a very good introduction, strong presentation)
When it comes to decision tree algorithm, this is a must mention. Because when building decision trees, the selected node attributes are based on information entropy determined, based on information entropy is selected to determine which property is used to classify the current data set. "Entropy" is Shannon put forward. We know that information is useful, but how to quantitatively describe the size of this information yet. The "information entropy" is to solve this problem and put forward for the role of quantitative information.
The amount of information and it is a message of uncertainty has a direct relationship, when we for a time of uncertainty, we need more information to get to know it, on the contrary, if we are determined for one thing , then we need less information you can know about it. Therefore, from this perspective, we can consider how much the size of the amount of information is uncertain. But how to quantify the amount of information it (ie uncertainty)
Shannon given the formula: H = - (P1logP1 + P2logP2 + ....) (P (X) is the probability of occurrence)
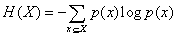
The greater the uncertainty of variables, the greater the entropy, the amount of information it needed to figure out the greater.
(1) ID3 algorithm:
Core: Application information gain criterion on each node of the decision tree to select a feature attribute (that is, information entropy we mentioned above)
step:
- Starting from the root, if only one kind or empty, return; calculating the information entropy values of all the properties, select the information gain the greatest attribute value as the current split node.
- Calculating the remaining attributes information gain, recursively calling the method
- Until each node can not continue to divide, that is the end of the same category of data on each node
Information gain calculation: g (D, A) = H (D) -H (D / A) (specifically, how computing can refer to Li Hang statistical learning this book)
H (D): the entropy of the original information indicating the unused attribute. H (D / A): A represents a property value using the entropy of a node. Information gain is the difference between the two.
(2) C4.5 algorithm
C4.5 is an improved version of ID3, ID3 uses information gain ratio, but there is a drawback is that the information gain will tend to choose more characteristic values, this will cause data overfitting. Therefore, the selection criterion using information gain C4.5 was characterized by improved ID3. Information gain is g (D, A) with the training data set D has a ratio of about A feature worth of entropy.
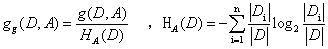
Other steps and ID3 same.
(3) CART algorithm
CART (classification and regression tree), classification and regression trees. Both can also be used for classification regression.
step:
- The decision tree is generated based on the training data set, the resulting decision tree as large as possible;
- Decision tree pruning, with validation set spanning tree pruning authentication, select the best tree. With minimal loss function as a pruning criterion.
Generating a decision tree (the CART) is actually a recursive process of constructing a binary tree, a regression tree with minimal square error principle, Gini coefficient (Gini index) principle classification tree.
(1) Regression Trees
The question of how to divide the input space?
Here heuristic method: Choice of variables X j (j) and its value as s divided data and variable cut cutting points, and the need to find the optimal s and j. Specific solving:
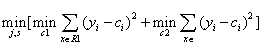
Through all the input variables to find the optimal segmentation traverse, so the space is divided into two spaces. Commonly referred to as least-squares regression tree.
(2) classification tree
Using the Gini index to choose the best features. In fact, the Gini index represents the collection of uncertainty, the greater the Gini index, the greater the uncertainty in the sample set, which is similar to the entropy. Gini index trend curve and the classification error rate almost.
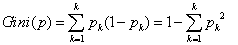 , Expressed categories K, and the probability of the sample belonging to class K P K.
, Expressed categories K, and the probability of the sample belonging to class K P K.
Select Gini index corresponding to the smallest eigenvalue and the cut points as an optimum features and optimal cut point.
(4) Random Forest algorithm
Core: in fact, the concept of integrated learning include (bagging, boosting), by integrating ballot improve the prediction accuracy.
The data selection:
(1) was repeated using the bootstrap data acquisition sampling with replacement, to avoid over-fitting the data. Thus obtaining a lot of training data, and they are independent, and may be parallel.
(2) random values m feature extraction and sampling the acquired sample decision tree constructed by CART.
(3) to build multiple decision trees, decision trees using these prediction vote
We can see, based classifiers (ie, every tree) their training data is not the same, they are not the same set of attributes , so that you can build a lot of differences of classifiers out, you can get by very well integrated prediction accuracy.
Is a forest planted a lot of trees to use this data to predict the forest.
Reproduced in: https: //www.cnblogs.com/GuoJiaSheng/p/3907842.html