It leads to problems: in distributed projects, what we use to ensure the global id generation ??
Method one. First, we consider all possible to generate the UUID.
It is the universal unique identifier UUID (Universally Unique Identifier), also called in other languages GUID, can generate a length 32-bit globally unique identifier.
String uuid = UUID.randomUUID().toString()
Example result:
046b6c7f-0b8a-43b9-b35d-6489e6daee91
But we use it has one drawback:
Although it can protect the globally unique, but 32 occupy too long, and he was out of order, warehousing poor performance
Why UUID disorder can lead to poor performance storage it?
This involves the B + tree index division :
Because relational database is the index of our structure the B + tree, for example to take the ID field, each node of the index tree is stored with the ID number.
If our ID to insert in ascending order, such as 8,9,10 gradually insert new ID will only last a node is inserted into them. When the last node is full, a new node will fission. This insert is inserted into the relatively high performance, such as the minimum number of split node, and full use of the space for each node.
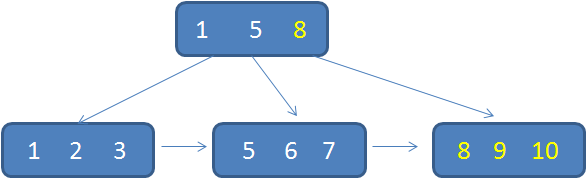
However, if we insert completely disordered, not only will lead to some intermediate nodes produce division, will be in vain to create a lot of unsaturated node, thereby greatly reducing the database insert performance.
Method two: increment primary key database
Suppose the table named table has the following structure:
id feild
35 a
Every time the generated ID to access the database, execute the following statement:
begin;
REPLACE INTO table ( feild ) VALUES ( 'a' );
SELECT LAST_INSERT_ID();
commit;
REPLACE INTO meaning is to insert a record, if a unique index values in the table encounter conflict, then replace the old data.
Thus, each time a can be incremented's ID.
To improve performance, can be used in a distributed system DB proxy request a different sub-library, each different sub-library set the initial value, and the number of steps equal to the sub-library:
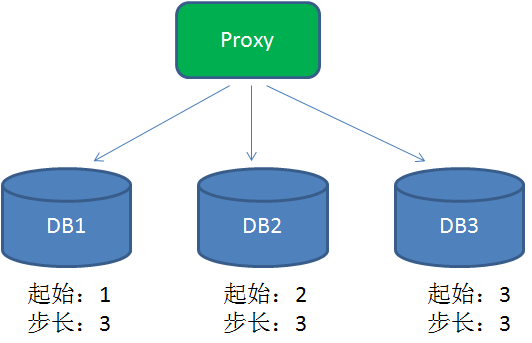
Thus, DB1 generated ID is 1,4,7,10,13 ...., DB2 is generated ID 2,5,8,11,14 .....
Disadvantages:
As a result of the database generation ID heavily dependent not only affect performance, and hang up the database once the service is no longer available.
Method 3 : Snowflake
What snowflake algorithm
It is an algorithm twitter adoption, the purpose is to generate globally unique trend in a distributed system and the ID is incremented
snowflake algorithm generated ID structure is like? Let's look at the following figure:
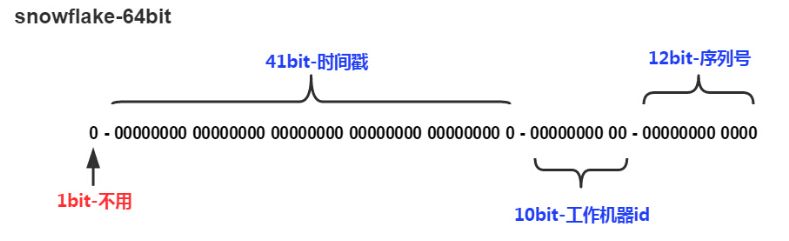
SnowFlake the generated ID is divided into a total of four parts:
1. The first
Occupation 1bit, its value is always 0, no practical effect.
2. timestamp
Occupation 41bit, accurate to the millisecond, can accommodate a total of about 69 years.
3. Working machine id
Occupied 10bit, wherein the upper 5bit data center ID (datacenterId), low work 5bit node ID (workerId), 1024 do more nodes can be accommodated.
4. The serial number
12bit occupied, this value is the same node on the same millisecond, cumulatively from 0 up to 4095 may be accumulated.
SnowFlake globally unique ID number algorithm can generate up to it in the same millisecond? Just do a simple multiplication:
The same number of milliseconds ID = 1024 X 4096 = 4194304
This figure in most concurrency scenarios are adequate.
SnowFlake code implements (a tool class)
public class SnowFlakeUtils {
// timestamp starting
private final static long START_STMP = 1480166465631L;
// number of bits occupied by each part, on three
private final static long SEQUENCE_BIT = 12; // number of bits occupied by the sequence number
private final static long MACHINE_BIT = 5; // number of bits occupied by the machine identification
private final static long DATACENTER_BIT = 5; // number of bits occupied by the data center
The maximum value of each part //
private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
// Each part of the shift to the left
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;
private long datacenterId; // Data Center
private long machineId; // machine identification
private long sequence = 0L; // SEQ ID
private long lastStmp = -1L; // time stamp on
public SnowFlakeUtils(long datacenterId, long machineId) {
if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {
throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
}
this.datacenterId = datacenterId;
this.machineId = machineId;
}
// generates the next ID
public synchronized long nextId() {
Long currStmp = getNewstmp ();
if (currStmp < lastStmp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currStmp == lastStmp) {
// if the condition represented in the current call and the last call ms falls within the same, only the third portion, the sequence number increment is determined to be unique, so by +1.
sequence = (sequence + 1) & MAX_SEQUENCE;
// the same sequence number of milliseconds has reached the maximum, we can only wait for the next millisecond
if (sequence == 0L) {
currStmp = getNextMill();
}
} else {
// different within milliseconds, the sequence number is set to 0
// to execute this branch on the premise that currTimestamp> lastTimestamp, explain this contrast with the last call to call, it is no longer the same within a millisecond, and this time the serial number can be re-set to zero the back.
sequence = 0L;
}
lastStmp = currStmp;
// is relatively few milliseconds, the machine ID number and self-energizing splicing
return (currStmp - START_STMP) << TIMESTMP_LEFT // timestamp part
| DatacenterId << DATACENTER_LEFT // data center section
| MachineId << MACHINE_LEFT // machine identification section
| Sequence; // part of the serial number
}
private long getNextMill() {
Long mill = getNewstmp ();
while (mill <= lastStmp) {
mill = getNewstmp ();
}
return mill;
}
private long getNewstmp() {
return System.currentTimeMillis();
}
}
We can be imported directly into the project to use
SnowFlake algorithm advantages:
1. DB is not dependent on generation ID, generated entirely in memory, high-performance availability.
2.ID downward trend increase, subsequent insertion index tree when better performance.
SnowFlake algorithm drawbacks:
It depends on the consistency of the system clock. If a machine clock callback system, may cause a conflict ID, ID or disorder.