Redis use a bitset (bitmap) to the amount of active Statistics Day
1 BitMap Introduction
Bitmap (i.e. Bitset), a string of consecutive binary digits (0 or 1), a position where each offset (offset), bitmap is set to 0 or 1 by the smallest unit 'bit, indicates an element or a value corresponding to the state.
From the beginning Redis 2.2.0 version adds setbit, getbit, bitcountand several other bitmap related commands. Although the new command, but does not add new data type, because setbitsuch orders is only in the setextension on. Perform AND, OR, XOR, and other operations on the bit bitmap.
2 Related command
(1)SETBIT key offset value
Of the key string stored value, set or clear the bits (bit) on the specified offset. Bit set or cleared depending on the value parameter, it may be 0 or may be one . When the key is not present, automatically generates a new string value.
String stretching performed (grown) to ensure that it can be value stored in the specified offset. When the extended string value, a blank position 0 is filled.
offset must be greater than or equal to 0 and less than 2 ^ 32 (bit map is limited to the 512 MB).
对使用大的 offset 的 SETBIT 操作来说,内存分配可能造成 Redis 服务器被阻塞。
redis> SETBIT bit 10086 1
(integer) 0
即将偏移量10086上的位设置为1.
(2)GETBIT key offset
对 key 所储存的字符串值,获取指定偏移量上的位(bit)。
当 offset 比字符串值的长度大,或者 key 不存在时,返回 0 。
redis> SETBIT bit 10086 1 (integer) 0 redis> GETBIT bit 10086 (integer) 1
(3)BITCOUNT key [start] [end]
计算给定字符串中,被设置为 1 的比特位的数量。
一般情况下,给定的整个字符串都会被进行计数,通过指定额外的 start 或 end 参数,可以让计数只在特定的位上进行。
start and end parameters and settings GETRANGE command Similarly, negative values can be used: for example, -1 is the last bit, and -2 represent the penultimate bit, and so on.
Absence of key is treated as an empty string, so the absence of a key for BITCOUNT operation, the result is 0 .
redis> SETBIT bits 0 1 # 0001 (integer) 0 redis> BITCOUNT bits (integer) 1
3 Use BitMap active amount of statistics day
Assume that such a scenario, if each site has 100 million users, then we how to count the number of landing on this site or which users have logged on this site.
The most common approach is to design a user registration table user_login:
user_uid login_date
0 2017-7-1
1 2017-7-1
0 2017-7-2
If an average of one a day log on once, then 100 million users one week will produce 1 * 1 * 7 = 700 million data month will produce three billion data, which is great pressure on the database, just statistics about user login, no need to spend so many resources.
This time we can use bitmap reids to solve.
Whether the user is logged can be represented by 0/1, 0 represents the user does not log in, 1 logged in, you can indicate whether 1bit user login.
The amount of data 100 million users a day also 1 0000 0000bit = 11.92m, meaning that the user login information day will produce the amount of data 11.92m. The amount of data a month will 357.63m.
The specific implementation process (in order to facilitate experiments, we assume that four user id are: 0,1,2,3, statistics two days Login amount):
mon: 1010 (0 users logged in, user login 1, 2 users logged in, user login 3)
tue: 1101 (0 user login, a user is not logged in, the user log 2, log 3 users)
127.0.0.1:6379> setbit mon 0 0 (integer) 1 127.0.0.1:6379> setbit mon 1 1 (integer) 1 127.0.0.1:6379> setbit mon 2 0 (integer) 0 127.0.0.1:6379> setbit mon 3 1 (integer) 0 127.0.0.1:6379> 127.0.0.1:6379> setbit tue 0 1 (integer) 1 127.0.0.1:6379> setbit tue 1 0 (integer) 1 127.0.0.1:6379> setbit tue 3 1 (integer) 0 127.0.0.1:6379> setbit tue 4 1 (integer) 1 127.0.0.1:6379>
If you want to count these two days users are logged in, you can use bit operation AND:
127.0.0.1:6379> bitop AND result mon tue (integer) 1 127.0.0.1:6379> getbit result 0 (integer) 0 127.0.0.1:6379> getbit result 1 (integer) 0 127.0.0.1:6379> getbit result 2 (integer) 0 127.0.0.1:6379> getbit result 3 (integer) 1 127.0.0.1:6379>
Mon tue can see and do and operation, and the results for the result: 1000, then the user can log in 3 consecutive days, two days other users log on only one day.
4 Use bitmap line statistics on the number of users to achieve
Suppose now that we want to record on the line frequency users on your site, for example, calculate the line how many days the user A, the line how many days the user B, and so on, as data, so decided to which users participate in beta testing and other activities - - this mode can be used SETBIT and BITCOUNT to achieve.
比如说,每当用户在某一天上线的时候,我们就使用 SETBIT ,以用户名作为 key ,将那天所代表的网站的上线日作为 offset 参数,并将这个 offset 上的为设置为 1 。
举个例子,如果今天是网站上线的第 100 天,而用户 peter 在今天阅览过网站,那么执行命令 SETBIT peter 100 1 ;如果明天 peter 也继续阅览网站,那么执行命令 SETBIT peter 101 1 ,以此类推。
当要计算 peter 总共以来的上线次数时,就使用 BITCOUNT 命令:执行 BITCOUNT peter ,得出的结果就是 peter 上线的总天数。
也可以实现类似签到的功能。
5 总结
优点占用内存更小,查询方便,可以指定查询某个用户,数据可能略有瑕疵,对于非登陆的用户,可能不同的key映射到同一个id,否则需要维护一个非登陆用户的映射,有额外的开销。
缺点如果用户非常的稀疏,那么占用的内存可能会很大。
参考:
拼多多面试真题:如何用Redis统计独立用户访问量! https://mp.weixin.qq.com/s?__biz=MzUxOTAxODc2Mg==&mid=2247485077&idx=1&sn=9adbf940d7e821d73bff4247e17dda41&chksm=f98146f0cef6cfe652aba3381b7babcc260e6d4a10dd66b90bae1abd552e7d765486d90dc069&scene=21#wechat_redirect
用redis的bitmap方式统计上亿访问量的周活跃用户 https://www.jianshu.com/p/62cf39db5c2f
二 Redis的热key问题如何解决
1 什么是热key问题
所谓热key问题就是,热点 key,指的是在一段时间内,该 key 的访问量远远高于其他的 redis key, 导致大部分的访问流量在经过 proxy 分片之后,都集中访问到某一个 redis 实例上。
突然有几十万的请求去访问redis上的某个特定key。那么,这样会造成流量过于集中,达到物理网卡上限,从而导致这台redis的服务器宕机。那接下来这个key的请求,就会直接怼到你的数据库上,导致你的服务不可用。
其实生活中也是有不少这样的例子。比如XX明星结婚。那么关于XX明星的Key就会瞬间增大,就会出现热数据问题。
ps:hot key和big key问题,大家一定要有所了解。
2 怎么发现热key
方法一:凭借业务经验,进行预估哪些是热key
其实这个方法还是挺有可行性的。比如某商品在做秒杀,那这个商品的key就可以判断出是热key。缺点很明显,并非所有业务都能预估出哪些key是热key。
方法二:在客户端进行收集
Before operating this way is redis, add a line of code statistics. So there are many statistics this way, it can be to external communication system sends a notification message. Drawback is caused by the invasion of the client code.
Method three: do collect Proxy layer
Some cluster architecture is below, Proxy can be Twemproxy, unified entrance. Proxy reporting in the collection can be done layer, but the drawback is obvious that not all redis cluster architecture has proxy.
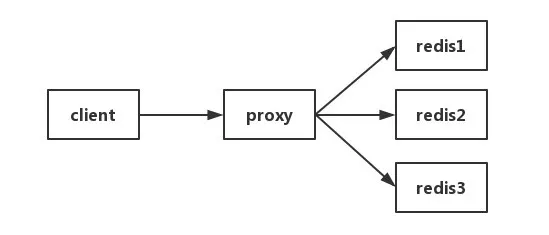
Method four: command comes with redis
(1) monitor command, which you can grab a real-time command redis received by the server, and then write the code is valid and statistics of the hot key. Of course, there are also ready-made analysis tool can give you use, such as redis-faina. But the order under conditions of high concurrency, memory has increased explosion risks, but also reduce the performance of redis.
(2) hotkeys parameters, redis 4.0.3 provides key hotspots redis-cli of discovery, coupled with -hotkeys option to the implementation of redis-cli. But the argument in the course of implementation, if the key is more, the implementation is relatively slow.
Method five: Ethereal own assessment
Redis clients using the TCP protocol to interact with the server, the communication protocol used is the RESP. Write your own program listening port, parses the data according to protocol rules RESP for analysis. The disadvantage is the high cost of development, maintenance difficulties, there is the possibility of loss.
3 How to solve
There are two current industry
(1) using a secondary cache
Such as the use ehcache, or it may be a HashMap. After you find the hot key, the hot key is loaded into the JVM system.
This hot key for the request, taken directly from the jvm, but will not come redis layer.
Assuming that there are over one hundred thousand requests for the same key, if not the local cache, a hundred thousand requests directly to hate on the same redis up.
Now suppose that your application layer has 50 machines, OK, you have jvm cache. A hundred thousand average spread out requests, there are 2,000 requests per machine, the JVM will be taken from the value of the value, and then returns the data. Avoid hundred thousand requests to hate on the same redis situation.
(2) hot backup key
This program is very simple. Do not let the key go on the same redis not on the list. We put this key, on multiple redis are not enough of a deposit. Next, there is a time hot key request comes, we will randomly select a backup on the redis, visit value, return data.
Redis assumed that the number of clusters is N, the steps shown in FIG.

Pseudo-code as follows:

4 Industry Solutions
In the project operation, the automatic discovery of the hot key, and the program automatically processed in two major steps:
(1) monitoring hot key (2) to do the processing notification system
(1) monitor hot key
1, there is praise solutions : for JedisPool and Jedis class native jedis package to do the transformation, integration in JedisPool initialization TMC "hot spots found in" + "local cache" initialization logic functions Hermes-SDK package, theJedisclient cache when the first layer interacts server proxyHermes-SDKinteraction, thus completing the transparent access to "hot probe" + "local cache" function. From a monitoring perspective, the key value for every packet Jedis-Client access request, Hermes-SDK asynchronous event will be reported to the access key Hermes cluster server through its communication module, to which a "hot probe" according to the reported data .
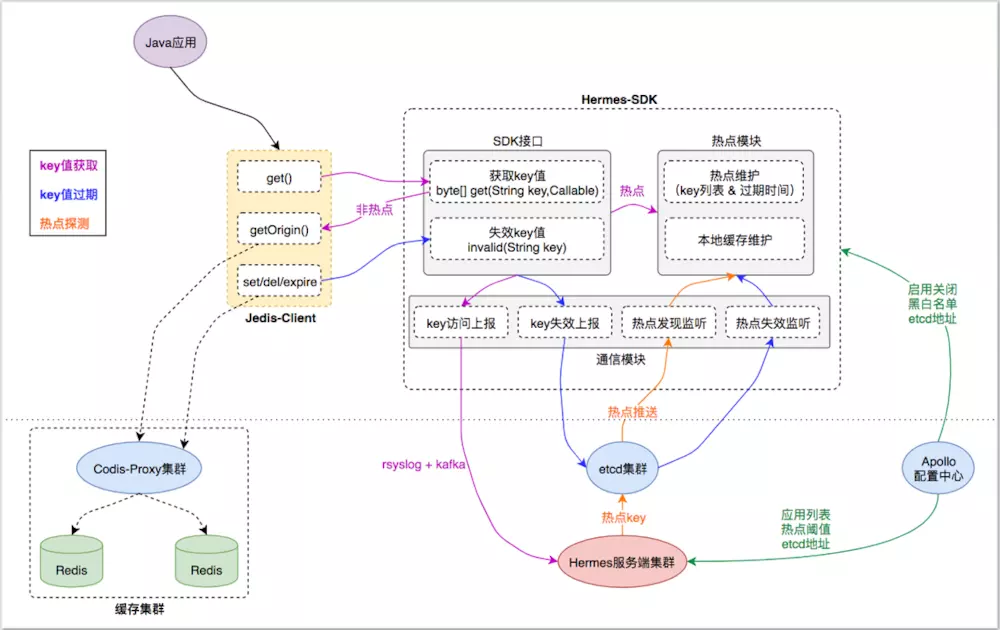
Module division:
Jedis-Client: Java application direct access cache server interaction with the native interface definition tantamount Jedis-Client;
Hermes-SDK: RESEARCH from "hot spots found local cache +" function SDK package, Jedis-Client by interacting with its respective capabilities to integrate;
Hermes cluster server: receiving data cache access Hermes-SDK to the reported detection of hot spots, hot key will be pushed to the Hermes-SDK do local cache;
Cache cluster: a proxy layer and the storage layer, distributed cache to provide a unified service entry for the application client;
Basic components: etcd cluster, Apollo distribution center for TMC to provide a "cluster push" and "unified configuration" capabilities;
The basic process:
1) key value acquisition
1.Java 应用调用 Jedis-Client 接口获取key的缓存值时,Jedis-Client 会询问 Hermes-SDK 该 key 当前是否是 热点key;
2.对于 热点key ,直接从 Hermes-SDK 的 热点模块 获取热点 key 在本地缓存的 value 值,不去访问 缓存集群 ,从而将访问请求前置在应用层;
3.对于非 热点key ,Hermes-SDK 会通过Callable回调 Jedis-Client 的原生接口,从 缓存集群 拿到 value 值;
4.对于 Jedis-Client 的每次 key 值访问请求,Hermes-SDK 都会通过其 通信模块 将 key访问事件 异步上报给 Hermes服务端集群 ,以便其根据上报数据进行“热点探测”;
2)key值过期
1.Java 应用调用 Jedis-Client 的set() del() expire()接口时会导致对应 key 值失效,Jedis-Client 会同步调用 Hermes-SDK 的invalid()方法告知其“ key 值失效”事件;
2.对于 热点key ,Hermes-SDK 的 热点模块 会先将 key 在本地缓存的 value 值失效,以达到本地数据强一致。同时 通信模块 会异步将“ key 值失效”事件通过 etcd集群 推送给 Java 应用集群中其他 Hermes-SDK 节点;
3.其他Hermes-SDK节点的 通信模块 收到 “ key 值失效”事件后,会调用 热点模块 将 key 在本地缓存的 value 值失效,以达到集群数据最终一致;
3)热点发现
1.Hermes服务端集群 不断收集 Hermes-SDK上报的 key访问事件,对不同业务应用集群的缓存访问数据进行周期性(3s一次)分析计算,以探测业务应用集群中的热点key列表;
2.对于探测到的热点key列表,Hermes服务端集群 将其通过 etcd集群 推送给不同业务应用集群的 Hermes-SDK通信模块,通知其对热点key列表进行本地缓存;
4)配置读取
1.Hermes-SDK 在启动及运行过程中,会从 Apollo配置中心 读取其关心的配置信息(如:启动关闭配置、黑白名单配置、etcd地址...);
2.Hermes服务端集群 在启动及运行过程中,会从 Apollo配置中心 读取其关心的配置信息(如:业务应用列表、热点阈值配置、 etcd 地址...);
2、其他解决方案:自己抓包评估
先利用flink搭建一套流式计算系统。然后自己写一个抓包程序抓redis监听端口的数据,抓到数据后往kafka里丢。
接下来,流式计算系统消费kafka里的数据,进行数据统计即可,也能达到监控热key的目的。
(2)通知系统做处理
1、有赞解决方案:利用二级缓存进行处理。
有赞在监控到热key后,Hermes服务端集群会通过各种手段通知各业务系统里的Hermes-SDK,告诉他们:"老弟,这个key是热key,记得做本地缓存。"
于是Hermes-SDK就会将该key缓存在本地,对于后面的请求。Hermes-SDK发现这个是一个热key,直接从本地中拿,而不会去访问集群。
2、其他解决方案:
比如你的流式计算系统监控到热key了,往zookeeper里头的某个节点里写。然后你的业务系统监听该节点,发现节点数据变化了,就代表发现热key。最后往本地缓存里写,也是可以的。
参考
有赞透明多级缓存解决方案(TMC) https://www.jianshu.com/p/176c8f8b8eb1
谈谈Redis的热key问题如何解决 https://mp.weixin.qq.com/s?__biz=MzUxOTAxODc2Mg==&mid=2247485004&idx=1&sn=5b5e3d188959a5055ec69eb6c16fe75f&chksm=f9814629cef6cf3f27fd3824a9f2849a5f6baa008f4b0d585631027e4988ed0215da55844138&scene=21#wechat_redirect
[Redis] 20万用户同时访问一个热点Key,如何优化缓存架构? https://www.cnblogs.com/aiqiqi/p/10976161.html
三 Redis实现分布式锁及可能出现的问题和解决方案
1 为什么需要分布式锁
在单机的情况下,如果有多个线程要同时访问某个共享资源的时候,我们可以采用线程间加锁的机制,即当某个线程获取到这个资源后,就立即对这个资源进行加锁,当使用完资源之后,再解锁,其它线程就可以接着使用了。例如,在JAVA中,使用synchronize或者Lock等进行加锁。
但是到了分布式系统的时代,这种线程之间的锁机制,就没作用了,系统可能会有多份并且部署在不同的机器上,这些资源已经不是在线程之间共享了,而是属于进程之间共享的资源。 因此,为了解决这个问题,我们就必须引入「分布式锁」。 分布式锁,是指在分布式的部署环境下,通过锁机制来让多客户端互斥的对共享资源进行访问。
为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件:
* 互斥性。在任意时刻,只有一个客户端能持有锁。
* 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
* 具有容错性。只要大部分的Redis节点正常运行,客户端就可以加锁和解锁。
* 解铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
2 基于Redis分布式锁加锁方式
(1)错误方式一
setnx key value; (1) do something ...(2) del key;(3)
以上方式如果在(1)加锁成功后,但是在(2)抛出异常,则可能导致del指令没有被调用,这样就陷入死锁,锁永远不会被释放。
(2)错误方式二
为了解决(1)中可能出现的问题,可以在拿到锁后,给锁加上一个过期时间,比如:5秒,这样即使中间出现问题,也会在5秒后自动释放锁。
setnx key value; (1) expire key 5;(2) do something ...(3) del key;(4)
这种方式,由于(1)和(2)不是原子操作,因此也有可能在(1)执行成功后即抛出异常,而(2)没有执行,所以仍会出现上例中的死锁问题。
(3)正确加锁方式
方式一:
在Redis2.8版本,加入了一个原子的指令:
public static boolean tryLock(Jedis jedis, String lockName, String uniqueValue, int expireTime) { /* nxxx,这个参数我们填的是NX,意思是SET IF NOT EXIST,即当key不存在时,我们进行set操作;若key已经存在,则不做任何操作; expx,这个参数我们传的是PX,意思是我们要给这个key加一个过期的设置,具体时间由第五个参数决定。 */ String result = jedis.set(lockName, uniqueValue, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime); return LOCK_SUCCESS.equals(result); }
方式二:
public Boolean tryLock(String lockKey, String uniqueValue, long seconds) { return redisTemplate.execute((RedisCallback<Boolean>) redisConnection -> { Jedis jedis = (Jedis) redisConnection.getNativeConnection(); String result = jedis.set(lockKey, uniqueValue, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, seconds); if (LOCK_SUCCESS.equals(result)) { return Boolean.TRUE; } return Boolean.FALSE; }); }
不能使用 spring-boot 提供的 redisTemplate.opsForValue().set() 命令是因为 spring-boot 对 jedis 的封装中没有返回 set 命令的返回值, 这就导致上层没有办法判断 set 执行的结果,因此需要通过 execute 方法调用 RedisCallback 去拿到底层的 Jedis 对象,来直接调用 set 命令。
分布式锁要满足第四个条件解铃还须系铃人,通过给value赋值为uniqueValue,我们就知道这把锁是哪个请求加的了,在解锁的时候就可以有依据。uniqueValue可以使用UUID.randomUUID().toString()方法生成,或者使用当前线程的线程ID。而lockName则需要使用一个相同的常量,保证竞争的是同一个锁。
3 Redis分布式锁解锁
由于解锁即执行delete操作,将lockName的键值删除,但是如果直接使用Redis的del操作,无法判断当前的锁是否为当前线程加的锁,所以可以使用lua脚本的方式:
方式一:
/** * 释放分布式锁 * @param jedis Redis客户端 * @param lockName 锁 * @param resourcePath 请求标识 * @return 是否释放成功 */ public static boolean release(Jedis jedis, String lockName, String resourcePath) { //lua表达式,Redis执行是原子操作 String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end"; Object result = jedis.eval(script, Collections.singletonList(lockName), Collections.singletonList(resourcePath)); return RELEASE_SUCCESS.equals(result); }
方式二:
/** * 与 tryLock 相对应,用作释放锁 * @param lockKey * @param clientId * @return */ private static final String RELEASE_LOCK_SCRIPT = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end"; public Boolean releaseLock(String lockKey, String clientId) { return redisTemplate.execute((RedisCallback<Boolean>) redisConnection -> { Jedis jedis = (Jedis) redisConnection.getNativeConnection(); Object result = jedis.eval(RELEASE_LOCK_SCRIPT, Collections.singletonList(lockKey), Collections.singletonList(clientId)); if (RELEASE_SUCCESS.equals(result)) { return Boolean.TRUE; } return Boolean.FALSE; }); }
4 超时问题
Redis的分布式锁不能解决超时问题。如果在加锁和释放锁之间的业务逻辑执行得太长,以至于超出了锁的超时时间,这时候第一个线程持有的锁过期了,但是临界区的业务逻辑还没有执行完,而同时第二个线程就提前重新持有了这把锁,导致出现问题。
解决方案:
(1)是否可以通过合理地设置LockTime(锁超时时间)来解决这个问题?
但LockTime的设置原本就很不容易。LockTime设置过小,锁自动超时的概率就会增加,锁异常失效的概率也就会增加。
而LockTime设置过大,万一服务出现异常无法正常释放锁,那么出现这种异常锁的时间也就越长。我们只能通过经验去配置,一个可以接受的值,基本上是这个服务历史上的平均耗时再增加一定的buff。
(2)既然(1)的方法走不通,那么可以采用如下方法
我们可以先给锁设置一个LockTime,然后启动一个守护线程,让守护线程在一段时间后,重新去设置这个锁的LockTime。
实际操作中,我们要注意以下几点:
1、和释放锁的情况一致,我们需要先判断锁的对象是否没有变。否则会造成无论谁持有锁,守护线程都会去重新设置锁的LockTime。不应该续的不能瞎续。
2、守护线程要在合理的时间再去重新设置锁的LockTime,否则会造成资源的浪费。不能动不动就去续。
3、如果持有锁的线程已经处理完业务了,那么守护线程也应该被销毁。不能主人都挂了,守护者还在那里继续浪费资源。
代码实现:
public class SurvivalClamProcessor implements Runnable { private static final int REDIS_EXPIRE_SUCCESS = 1; SurvivalClamProcessor(String field, String key, String value, int lockTime) { this.field = field; this.key = key; this.value = value; this.lockTime = lockTime; this.signal = Boolean.TRUE; } private String field; private String key; private String value; private int lockTime; //线程关闭的标记 private volatile Boolean signal; void stop() { this.signal = Boolean.FALSE; } @Override public void run() { int waitTime = lockTime * 1000 * 2 / 3; while (signal) { try { Thread.sleep(waitTime); if (cacheUtils.expandLockTime(field, key, value, lockTime) == REDIS_EXPIRE_SUCCESS) { if (logger.isInfoEnabled()) { logger.info("expandLockTime 成功,本次等待{}ms,将重置锁超时时间重置为{}s,其中field为{},key为{}", waitTime, lockTime, field, key); } } else { if (logger.isInfoEnabled()) { logger.info("expandLockTime 失败,将导致SurvivalClamConsumer中断"); } this.stop(); } } catch (InterruptedException e) { if (logger.isInfoEnabled()) { logger.info("SurvivalClamProcessor 处理线程被强制中断"); } } catch (Exception e) { logger.error("SurvivalClamProcessor run error", e); } } if (logger.isInfoEnabled()) { logger.info("SurvivalClamProcessor 处理线程已停止"); } } }
在以上代码中,我们将waitTime设置为Math.max(1, lockTime * 2 / 3),即守护线程许需要等待waitTime后才可以去重新设置锁的超时时间,避免了资源的浪费。
同时在expandLockTime时候也去判断了当前持有锁的对象是否一致,避免了胡乱重置锁超时时间的情况。
然后我们在获得锁的代码之后,添加如下代码:
SurvivalClamProcessor survivalClamProcessor = new SurvivalClamProcessor(lockField, lockKey, randomValue, lockTime);//创建守护线程 Thread survivalThread = new Thread(survivalClamProcessor); survivalThread.setDaemon(Boolean.TRUE);//后台线程 survivalThread.start(); Object returnObject = joinPoint.proceed(args);//执行业务代码 survivalClamProcessor.stop();//业务代码执行完成后停止守护线程 survivalThread.interrupt();//中断线程 return returnObject;
这段代码会先初始化守护线程的内部参数,然后通过start函数启动线程,最后在业务执行完之后,设置守护线程的关闭标记,最后通过interrupt()去中断sleep状态,保证线程及时销毁。
参考:https://juejin.im/post/5c457f5a6fb9a049d37f6b55