A, Lucene Introduction
Lucene is a subproject 4 jakarta apache Software Foundation project team, is an open source full-text search engine tool kit, but it is not a complete full-text search engine, but a full-text search engine architecture, providing a complete query engine and index engine, part of the text analysis engine (English and German two kinds of Western languages). Lucene is designed to provide software developers with an easy-to-use toolkit to facilitate the realization of full-text search functions in the target system, or as a basis to establish a complete full-text search engine
Overview full-text search
For example, we have a folder or a disk has a lot of documents, notepad, world, Excel, pdf, according to the file which we would like to search keywords included. For example, we enter Lucene, Lucene contain all the contents of the file will be checked out. This is called full-text search.
So we should establish a mapping between the keywords and file. With this mapping relationship, we take a look at the Lucene architecture. Below is a chart Lucene information will appear, but it is also the essence of generalization.
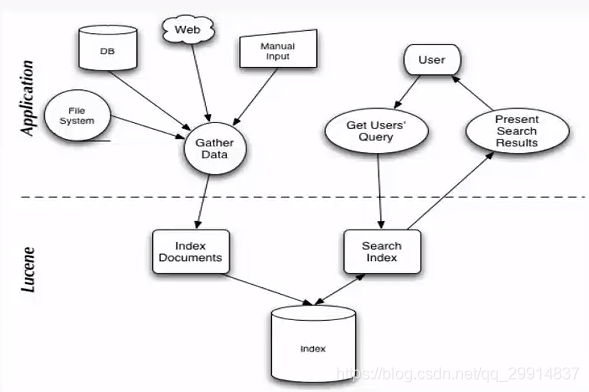
Lucene is used mainly in two steps:
1 Create an index, an index created for different files IndexWriter, and save it in a location index documents stored.
2 search keywords related documents by index.
Lucene mathematical model
documentation, field, word yuan
It is the atomic unit Lucene document search and indexing, the document comprising one or more domains of the containers, while the domain is in turn contains "real" content search word by the threshold processing technique to obtain a plurality of lexical unit.
For Example, a novel (fighting broke sky) information may be referred to a document, the novel also contains information on more than one domain, such as: title (fighting broke sky), author, profile, last updated, and so on, using the title of this domain segmentation technique and can obtain one or more LUs (bucket, breaking, Cang, dome).
Lucene file structure
Hierarchy
index index is stored in a directory
segment index may have a plurality of independent segments between, segments with the segment, adding a new document may create new segments, different sections can be combined into a new segment
document file is the basic unit to create the index, different documents stored in different segments, one segment may contain multiple documents
field domain, a document containing different types of information, can be split open index
term word, the smallest unit of the index, the data is through lexical analysis and language processing.
Two, lucene class described
1, IndexWriter
IndexWriter lucene one of the most important class, which is primarily used for documents indexed, the indexing process while controlling the parameters of use.
2, Analyzer
Analyzer Analyzer is used mainly for text analysis search engine encountered. Commonly used StandardAnalyzer analyzer, StopAnalyzer Analyzer, WhitespaceAnalyzer analyzer and the like.
3, Directory
Directory index storage location; lucene provides a place neither index stored in a disk, one is memory. The general index on the disk; lucene accordingly provides FSDirectory and RAMDirectory two classes.
Document Document; Document to be equivalent to an index of the unit, any document can be indexed want to have to be translated into Document object to be indexed.
4, IndexSearcher
IndexSearcher lucene is the most basic search tool, will be used to retrieve all IndexSearcher tool;
5, Query
Query query, lucene support fuzzy queries, semantic queries, phrase queries, combined queries, and so, if TermQuery, BooleanQuery , RangeQuery, WildcardQuery and some other categories.
. 6, the QueryParser
the QueryParser analysis tool is a user input, a user can scan a string input, generate Query object.