Chapter VII To be honest, like a revelation, after the end of a dream, just finished this chapter. I could not very well absorbed, so the next time, good knowledge points to comb it again, good summary.
(1) and patted chapter concepts
Keywords: Keywords are the value of a data item data element.
Lookup table: dynamic lookup tables and static lookup table. Dynamic lookup table can look at the same time to make changes to the operating table (insert, and delete), static lookup table is not.
Average length: All P I C I sum, P is the probability of finding, C is the number of keyword comparison.
(2) sequential search
Data elements defined:
typedef struct { the KeyType Key; // key field in the InfoType otherinfo; // Other Information fields } ElemType;
Defined sequence table
typedef struct { elemType * R & lt; // base address of the memory space int the Length; // current length } SSTable;
Sequential search: Find the setting method Sentinel
int search_seq(SSTable ST,KeyType key) { ST.R[0].key=key;//哨兵 for(int i=ST.Length;ST.R[i].key!=key;--i);//从后往前找 return i; }
(3) binary search
Prerequisites: linear table storage structure must be adopted and sequentially ordered.
int search_Bin (SSTable ST, the KeyType Key) { int Low = . 1 ; int High = ST.Length; the while (Low <= High) { MID = (High + Low) / 2 ; IF (Key == ST.R [MID ] .key) return MID; the else IF (Key <ST.R [MID] .key) High = mid- . 1 ; // preceding sub lookup table the else Low = MID + . 1 ; // Find the sub-table after a } return 0 ; // not found in the table elements to be examined }
Compare binary search to find success in the number of keywords up to a maximum depth of the tree.
(3) block search (index sequential search)
Block search is interposed between the binary search and sequential search
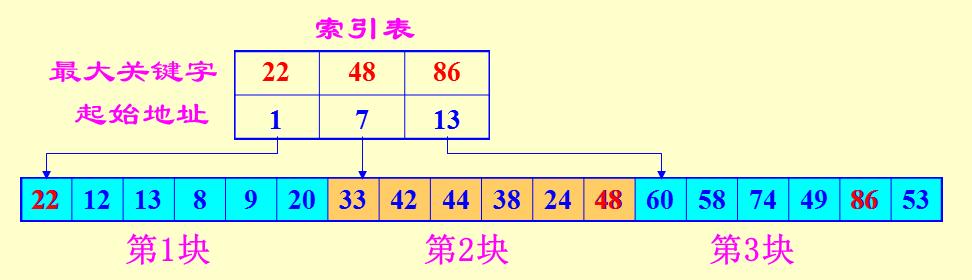
(1) determines a recording block to be examined is located (sequential search or binary search)
(2) in order to find the block
Block search advantages: easy insertion and deletion operations, without a large movement. The need to increase storage space for a table index
(4) binary sort tree (binary search tree)
Definitions: (1) If the left subtree is not empty, then the values of all the nodes in the left subtree of the root node are less than the value of its
(2) if non-empty, then the value of the right subtree of all the nodes have a value greater than a right subtree of the root of its.
(3) left and right subtrees are also binary sort tree
Recursive binary sort tree lookup (based on binary chain store):
SearchBST BSTree (BSTree T, the KeyType Key) { // If the search is successful, returns a pointer to the node, otherwise, returns NULL IF ((T) || T-Key ==> data.key!) Return T; the else IF (Key <T-> data.key) return searchBST (T-> lchild, Key); // Find in the left subtree of the else return searchBST (T-> rchild, Key); // Find the right subtree }
Insert binary sort tree (insert based on the look complete) and creation (creation is based on the insertion completed)
void InsertBST (BSTree & T, elemType E) { IF (! T) { S = new new BSTNode; S -> Data = E; S -> lchild = -S-> rchild = NULL; T = S; } the else IF (E .key <T-> data.key) InsertBST (T -> lchild, E); // inserted in the left subtree of the else IF (e.key> T-> data.key) InsertBST (T -> rchild, E); // inserted into the right subtree }
Create a binary sort tree
void createBST (BSTree & T) { T = NULL; // initializes an empty tree >> CIN E; the while (! = e.key endflag) // endflag custom end flag { InsertBST (T, E); // insert binary sort tree in CIN >> E; } }
Remove binary sort tree: (1) deleting the node is a leaf node of the tree structure does not change, simply modify the pointer of the parent node.
(2) delete nodes only the left subtree or only a right subtree, then the value you want to make a left or right child subtree directly into the left sub-tree to its parent node.
f->lchild=p->lchild;(f->lchild=p->rchild)
(3) Remove nodes left subtree and right subtree is not empty, (1) increasing the depth of the tree, so P * F left subtree left subtree, right subtree * P * S is right subtree to replace * S * P. (2) so that a direct precursor of * P * P or alternatively directly to a subsequent (to the left sub-tree, the maximum point truncated maximum alternative keywords truncated junction point)
(5) a balanced binary tree (AVL tree)
Features: (1) the absolute value of the difference between the depth of the left subtree and right subtree of not more than 1, (2) the left and right subtree is the subtree balanced binary tree
Balancing factor: the difference between the depth of the left subtree and right subtree
Create a balanced binary tree: binary sort tree based process, if the characteristics of the balanced binary tree destruction, is to be adjusted: locate the insert from the node nearest ancestor node and the absolute value of the balance factor exceeds 1, to the root node minimal subtree called unbalanced subtree limit the scope of the rebalanced subtree tree.
(6) B- tree (balanced, orderly, multi-channel)
m tree
(1) Each node in the tree has at most m subtrees;
(2) If the root node is not a leaf node, then at least two subtrees
(3) all non-terminal nodes except the root node having at least m / 2 takes up the entire subtree
(4) all leaf nodes appear on the same level, with no information (for the failed node
(5) all non-terminal nodes up to m-1 keyword
(7) B + tree
(1) n-trees of nodes in the subtree has n keywords
(2) All leaf nodes contains information about all keywords
(3) all non-terminal nodes can be seen as an index
(8) Find a hash table (hash lookup)
(1) and hash function Hash Address: storing a corresponding relation with the key KEY and the position p, p = H (key), p hash address
(2) a hash table: a finite contiguous address space (one-dimensional array)
(3) conflict and synonyms: possible to get the same hash address for different keywords, a phenomenon known as conflict. Keyword has the same function value of the hash function is referred to as synonyms.
Constructor hash function: 1, numerical analysis method (previously known set of keywords) 2, middle-square method, after taking several keywords squared intermediate or combination thereof (not known in advance hash table) as the hash address
3, folding process, the key is divided into several portions of the same number of bits, and then take these portions and superimposing the hash address (fewer bits adapted hash address, the key bits more) * 4, in addition to the number of I stay, H (key) = key% p, p is no greater than the length of the table. (Typically a prime number)
Conflict: 1. Open address method (will generate secondary aggregation): H I = (H (Key) D + I ) = mi The% l, 2,3 ..., K (K <= m-1) ( 1) linear probing method (imagine cycle table) when a conflict occurs, the empty cells to find the next unit sequentially address the conflict, if the last unit finds also not found, continue to search for the header returns, know where to find space. Not found, the overflow process (2) Secondary Detection Method D I =. 1 2 , -1 2 , 2 2 , -2 2 , ... (. 3) detecting a pseudo-random method, D I = pseudo random sequence
2, link address method (the adjacency list class, will not produce secondary aggregation)
Find the hash table (opening address method):
#define m 20 is typedef struct { KeyType Key; InfoType otherinfo; } the HashTable [m]; int searchHash (the HashTable the HT, KeyType Key) { H0 = H (Key); // the hash function to calculate a hash address IF (the HT [ h0] .key == 0 ) return - . 1 ; // If h0 is empty, then the check element is not present the else IF (the HT [h0] .key == Key) return h0; the else { for (I = . 1 ; I <m; ++ I) { Hi = (H0 + I)% m; // accordance with the calculated hash address a linear detection method if(The HT [hi] .key == 0 ) return - . 1 ; // if hi is empty, then the check element is not present the else IF (the HT [hi] .key == Key) return hi; } return - . 1 ; } }
The last goal completed half and learn Chapter VII, this has to be raised, Chapter VII did not learn very well. Work had not been made, so the next, is to Chapter VII of the job is complete, and a good review Chapter VII, as well as review the wrong title of Chapter VI.