Source url: https://github.com/zhzhair/stepsrank-spring-boot.git.
1. Create a sub-table 32, the data insertion step counting the number of steps the user with analog upload timer task;
2. Item Start initialization: the front 200 of the recording sheet 32 is inserted into a set mongodb (table), after emptying into the front 200 name is recorded,
and the number (threshold) of step 200 into Redis;
3. Upload the number of steps, the number of steps when the user is greater than a threshold value, MongoDB is inserted, or not inserted into the recorded MongoDB;
4. regular tasks with every 10 seconds delete records in the table 205 mongodb later;
5. update timer task number (threshold) of 200 to redis step every one second, while the top 200 into the recording redis queue;
6. ranked first to query the number of steps redis queue, finding out went to check mongodb table.
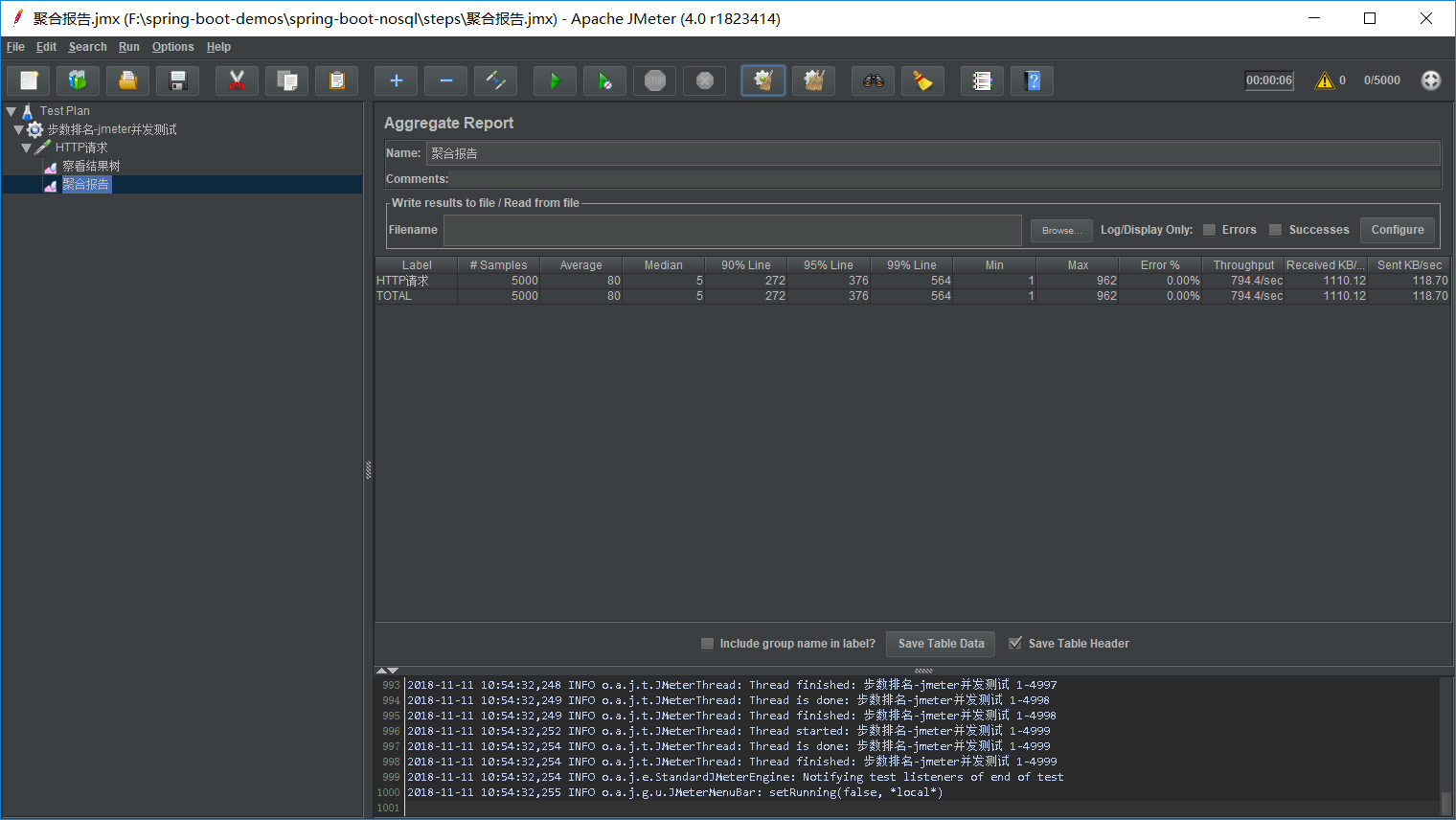
7.jmeter concurrent test to see query performance.
Programming Brief:
Technical Architecture: java8, spring boot2.0.0, mysql, redis, mongodb, mybatis, swagger, jmeter, idea, maven.
(i) adding the test data: the new table 32 according to the user id 32 is added modulo test data to a different table, the timing to do the task, add or modify 300 records per second. User_id and table includes the number of steps step_count two fields, assuming that the cumulative number of steps passed a cell phone every once in a while, if the user has a record day on the modification of the number of steps of the user (to add a new number of steps), or added directly record. Part of the code as follows:
@LogForTask
@Scheduled (= the cron "? * * * * 0/1")
public void uploadStep () {// add or modify scheduled tasks 300 records per second
IntStream.range (0,300) .parallel () .forEach (I-> stepService.uploadStep (32));
}
(II) programming: in the case of high concurrent memory is a concern (out of memory exception!), a single document mongodb not put too much data, You need to set the disk is read out of memory. Taking into account the total number of steps in the first 200 will not be reduced, and the more backward the more "stable", so it can be used as a threshold to the query table "downsizing" to avoid a large table sort.
Initialization (i.e., start when the project): the table 32 needs to be pre mongodb 200 are placed in a document, 200 to replace the previous document and then the document bson while the number stored in step 200 to the inside redis, part code is as follows:
@Resource
Private StepService stepService;
private static StepService service;
@PostConstruct
public void init(){
service = this.stepService;
}
static void main public (String [] args) {
SpringApplication.run (StepsApplication.class, args);
// start the project initialization ranking
service.recordTopAll (32);
}
@Override
public void recordTopAll (int tableCount) {
mongoTemplate.dropCollection ( StepsTop.class); // delete the document
IntStream.range (0, tableCount) .parallel ( ) forEach (this :: insertOneTable);. // MySQL inserting data to the mongo document
/ * put before removing 200 list, mongo update the current document data for the list data * /
.. = new new Query Query Query () with (new new the Sort (Sort.Direction.DESC, "the totalCount")) limit (200 is);
List <StepsTop> = mongoTemplate list. Find (Query, StepsTop.class);
IF (list.isEmpty ()) return;
mongoTemplate.dropCollection (StepsTop.class);
mongoTemplate.insertAll (List);
/ * redis storage threshold - The first step 200 a number of * /
int size = Math.min (200 is, list.size ());
. redisTemplate.opsForValue () SET (redisKey, String.valueOf (List.get (size - . 1) .getTotalCount ()));
}
number of steps upload: redis do the data update timing of the task, increasing the threshold value, the number of steps compared with a threshold value every time the number of steps received or updated, than this threshold value gets out to check mongo, mongo document and then do the update or insert operation, this "more" will be very frequent, but redis "not afraid" high concurrency, we do not have to worry about. This greatly reduces the operation of the document mongo, mongo document to ensure that small amount of data, after sorting the data query and mongo document very quickly. Part of the code as follows:
@Override
public void uploadStep (int tableCount) {
int the userId new new = the Random () the nextInt (500_0000);.
Int. 1 + = new new StepCount the Random () the nextInt (5000);.
Integer COUNT = commonMapper.getStepCount (prefix tableCount the userId% +, the userId);
IF (COUNT = null) {!
commonMapper.updateSteps (prefix + tableCount the userId%, the userId, StepCount + COUNT);
} the else {
commonMapper.insertTables(prefix + userId%tableCount, userId, stepCount);
}
String tailSteps = redisTemplate.opsForValue().get(redisKey);
int totalCount = count == null?stepCount:count + stepCount;
if(tailSteps != null && totalCount > Integer.valueOf(tailSteps)){//步数超过阈值就插入或更新用户的记录
Query query = new Query(Criteria.where("userId").is(userId));
if(!mongoTemplate.exists(query,StepsTop.class)){
StepsTop stepsTop = new StepsTop();
stepsTop.setUserId(userId);
stepsTop.setTotalCount(stepCount);
mongoTemplate.insert(stepsTop);
}else{
System.out.println("update: " + tailSteps);
Update update = new Update();
update.set ( "totalStep", The totalCount);
mongoTemplate.upsert (Query, Update, StepsTop.class);
}
} the else {
StepsTop stepsTop new new StepsTop = ();
stepsTop.setUserId (the userId);
stepsTop.setTotalCount (StepCount);
mongoTemplate.insert (stepsTop);
}
}
timer task: updated once every 10 seconds threshold, delete data other than the document 200 mongo; mongo query from every second row of the top 200 of the ordered data to push redis queue, the ranking easily removed from redis. Part of the code as follows:
@ Override // update the threshold value, the document data deleting mongo than 200
public void flushRankAll () {
// new new Query Query Query = () with (new new the Sort (Sort.Direction.DESC, "The totalCount." .)) limit (201);
// List <StepsTop> mongoTemplate.find List = (Query, StepsTop.class); // prone highly concurrent scenario memory exception: out of memory exception
TypedAggregation <StepsTop> aggregation keyword = Aggregation.newAggregation (
StepsTop.class,
Project ( "userId", "totalCount"), // query field used in
the Sort (Sort.Direction.DESC, "totalCount"),
limit (200)
) .withOptions (. newAggregationOptions () allowDiskUse ( true) .build ()); // insufficient memory to disk read and write, to deal with high concurrency
AggregationResults <StepsTop> results = mongoTemplate.aggregate ( aggregation, StepsTop.class, StepsTop.class);
List <StepsTop> = results.getMappedResults List ();
IF (list.size () == 201) {
int = List.get The totalCount (199) .getTotalCount ();
Query Query Query1 new new = (Criteria.where ( "The totalCount ") .lt (The totalCount));
mongoTemplate.remove (Query1, StepsTop.class);
}
}
@ Override // query sorted the data before 200 redis queue to push
public void recordRankAll () {
// Query Query = new new Query (). With (new new the Sort (Sort.Direction.DESC, "totalCount")) .limit (200 is);
// List <StepsTop> mongoTemplate.find List = (Query, StepsTop.class);
TypedAggregation <StepsTop> = Aggregation.newAggregation aggregation (
StepsTop.class,
Project ( "the userId", "The totalCount"), // query field used
the Sort (Sort.Direction.DESC, "totalCount"),
limit (200)
.) .withOptions (newAggregationOptions () allowDiskUse (to true) .build ()); // insufficient memory to disk read and write respond to high concurrency
AggregationResults <StepsTop> Results = mongoTemplate.aggregate (aggregation, StepsTop.class, StepsTop.class);
List <StepsTop> results.getMappedResults List = ();
if(list.size() == 200){
List.get StepCount = Integer (199) .getTotalCount ();
redisTemplate.opsForValue () SET (redisKey, String.valueOf (StepCount));.
}
IF (list.isEmpty ()!) {
RedisListTemplate.delete (redisQueueKey);
noinspection an unchecked //
redisListTemplate.opsForList () rightPushAll (redisQueueKey, List);.
}
}
query list: now simple, directly to the query can redis queue, part of the code as follows:
@ApiOperation (value = "query step day total position number ", notes =" total number of steps ranking queries day ")
@RequestMapping (value =" / getRankAll ", Method RequestMethod.GET = {}, = {MediaType.APPLICATION_JSON_VALUE Produces})
public BaseResponse <List <>> getRankAll StepsRankAllResp (the begin int, int the pageSize) {
BaseResponse <List <>> StepsRankAllRespbase = new Base Response Response <> ();
List<StepsRankAllResp> list = stepService.getRankAllFromRedis(begin,pageSize);
if(list.isEmpty()) list = stepService.getRankAll(begin,pageSize);//redis查不到数据就从Mongo查
baseResponse.setCode(0);
baseResponse.setMsg("返回数据成功");
baseResponse.setData(list);
return baseResponse;
}
@Override//todo 从redis读取
public List<StepsRankAllResp> getRankAllFromRedis(int begin, int pageSize) {
List<StepsTop> stepsList = redisListTemplate.opsForList().range(redisQueueKey,begin,pageSize);
List<StepsRankAllResp> list = new ArrayList<>(stepsList.size());
for (int i = 0; i < stepsList.size(); i++) {
StepsRankAllResp stepsRankAllResp = new StepsRankAllResp();
StepsTop = stepsList.get StepsTop (I);
BeanUtils.copyProperties (stepsTop, stepsRankAllResp);
stepsRankAllResp.setRank (the begin + I +. 1);
List.add (stepsRankAllResp);
}
return List;
}
JMeter concurrent test: Access interface document - -http: // localhost: 8080 / swagger -ui.html /, Interface query adjustment position, adjusting the interface configuration 5000 for 5 seconds, the polymerization as follows: