1. abs (), all () function
Print (ABS (-1)) # ABS absolute value Print (All ([l, 2,3, ' . 1 ' ])) # determines whether true Print (All ([l, 2,3, '' ]) ) Print (All ( '' )) # If iterable "list" is empty, returns True

2.any () as long as one is true, then this iteration object that is true
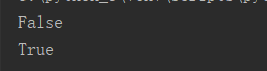
print(any([0,''])) print(any([0,'',1]))
3.bin () is converted into a binary number
Print (bin (13 is)) # Results: 0b1101 wherein 0b represents a binary

4.bool () to False are: empty, None, 0 the rest are True
print(bool('')) print(bool(None)) print(bool(0))

5.bytes bytes function returns a new object that is a 0 <= x <integer in the range of 256 immutable sequence. It is an immutable version of bytearray.
grammar
The following are the bytes syntax:
class bytes([source[, encoding[, errors]]])
parameter
- If the source is an integer, it returns an array of length initialization of the source;
- If the source is a string, then the specified encoding the string into a sequence of bytes;
- If the source type to be iterative, the element must be an integer [0, 255] in;
- If the source is coincident with buffer interface object, this object can also be used to initialize bytearray.
- If you do not enter any parameters, the default is to initialize the array is 0 element.
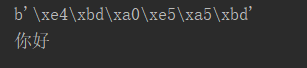
= name ' Hello ' Print (bytes (name, encoding = ' UTF-. 8 ' )) Print (bytes (name, encoding = ' UTF-. 8 ' ) .decode (encoding = ' UTF-. 8 ' )) # what What is certain is necessary to decode encoded with
6.divmod () function is the remainder and divisor calculation result combined tuple returns a quotient and a remainder (a // b, a% b).
Print (divmod (10,3)) # used for pagination Results: (3, 1) represents the three points, the last remaining one must add, the operation is: 10 divided by 3, the first result takes The second business results take the remainder Print (divmod (10,2)) # result: (5, 0) representing minutes to 5

7.express () function expression 1. string 2. calculates the data structure string extracted
= Express ' . 1 + 2 * (. 3 / 3-1) -2 ' # result -1.0 Print (the eval (Express)) # calculates expression string in the data structure 1. 2. string extract

Value 8. (1) max comparison method is to start with the first embodiment by comparing the position of the elements, which would begin from the digital comparator, thereby obtaining the correct user name and age
Can not be compared between different (2) max () built-in function type
# Max () takes the maximum value min () takes a minimum value L = [1,3,100,-1,2 ] Print (max (L)) Print (min (L))

(4) The default comparison is a dictionary of key
= {age_dic ' No. _age. 1 ' : 10, ' No. _age 2 ' : 58, ' No. _age. 3 ' : 90 }
Print ( ' ====> ' , max (ZIP (age_dic.values (), age_dic.keys ()))) # conversion using the first zipper zip () method to iterables (values, keys) in the form of tuples,
# then use max () method are compared, max is the first embodiment of the method comparison value from the first location by a comparison element, which would begin from the digital comparator, thereby obtaining the correct user name and age
# max () can not be compared between different types of built-in functions
# default dictionary is compared Key
Print (max (age_dic)) # The results: No. 3 _age

(5) a little more complicated data comparing
people =[ { 'name':'alex','age':1000}, {'name':'peiqi','age':10000}, {'name':'yuanhao','age':9000}, {'name':'linhaifeng','age' : 18 is } ] Print (max (people, Key = the lambda DIC: DIC [ ' Age ' ])) # decompose the process is as follows: RET = [] for Item in people: ret.append (Item [ ' Age ' ]) Print (RET) Print (max (RET))

9.zip () built-in function
print(list(zip(('a','b','c'),(1,2,3)))) print(list(zip(('a','b','c'),(1,2,3,4)))) print(list(zip(('a','b','c','d'),(1,2,3)))) p = {'name':'alex','age':18,'gender':'none'}#字典 print(list(zip(p.keys(),p.values())))

10.chr () Function: obtaining a digital value string in ASCII codes chr () by an integer as argument and returns a corresponding character. Instead the ord () function is CHR () function; the ord () function is CHR () function (for 8-bit ASCII string) or unichr () function (for Unicode object) pairings, it a character (length string 1) as a parameter and returns the corresponding ASCII data, or Unicode value, if the given Unicode character beyond your Python definition, a TypeError exception is thrown.
#chr()函数 功能:获取数字在ASCII 码中的字符串值 chr() 用一个整数作参数,返回一个对应的字符。 print(chr(100)) #ord()函数与chr()函数相反;ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数, # 返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。 print(ord('d'))

11.pow()函数 方法返回 xy(x的y次方) 的值。
print(pow(3,3))#3**3 3的三次方 print(pow(3,3,2))##3**3%2 ,3的三次方 之后除以2 取余数

12.reversed() 元素反转
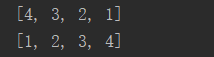
#reversed() 元素反转 l = [1,2,3,4] print(list(reversed(l))) print(l)
13.set()函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等
#round() 四舍五入
#round() 四舍五入 print(round(5.5)) #set()函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等 x = set('runoob') y = set('google') print(x&y) #交集 print(x|y)#并集 print(x-y)#差集 print(y-x)#差集 print(x,y)#原始去重功能
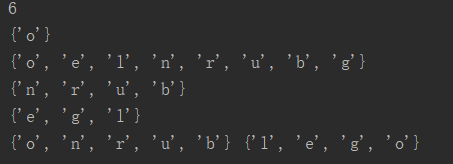
14.sorted() 功能:从小到大排序
#sorted() 功能:从小到大排序 l = [3,4,1,2,5,8,4] l1 = [3,4,1,2,5,8,'s',4] #排序本质就是在比较大小,不同类型之间不可以比较大小 print(sorted(l)) # print(sorted(l1))#报错 # sorted() 按照年龄进行从小到大排序 people =[ { 'name':'alex','age':1000}, {'name':'peiqi','age':10000}, {'name':'yuanhao','age':9000}, {'name':'linhaifeng','age':18} ] print(sorted(people,key=lambda dic:dic['age']))

15.str() 转换成字符串
# str() 转换成字符串 print(str('1')) print(type(str({'a':1}))) #转换为字符串类型,并打印类型 dic_str = str({'a': 1}) print(type(eval(dic_str)))#字符串最终转换为字典并打印类型
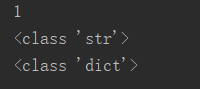
16.type()函数,判断数据类型
msg = '123' if type(msg) is str: msg = int(msg) res =msg +1 print(res)

17._import_()当导入的包名格式为字符串时使用它来导入
import test #--->导入包名,但是无法导入格式为字符串格式的包名这时候需要用_import_() test.say_hi() #如果需要导入的包名是字符串格式,则需要使用_import_() module_name = 'test' m = __import__(module_name) m.say_hi()
