
Everyone is welcome to Star us on GitHub:
Distributed full-link causal learning system OpenASCE: https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
Large model-driven knowledge graph OpenSPG: https://github.com/OpenSPG/openspg
Large-scale graph learning system OpenAGL: https://github.com/TuGraph-family/TuGraph-AntGraphLearning
On April 25th and 26th, the Global Machine Learning Technology Conference was held at the Hyatt Regency Global Harbor Hotel in Shanghai! Wang Qinlong, head of open source DLRover at Ant Group, delivered a keynote speech on "DLRover Training Fault Self-Healing: Significantly Improving the Computing Power Efficiency of Large-Scale AI Training" at the conference, sharing how to quickly self-heal from failures under kilo-calorie large-scale model training operations. Wang Qinlong introduced the technical principles and use cases behind DLRover, as well as the practical effects of DLRover on large community models.

Wang Qinlong, who has been engaged in the research and development of AI infrastructure at Ant for a long time, led the construction of the elastic fault tolerance and automatic expansion and contraction projects of Ant distributed training. He has participated in multiple open source projects, such as ElasticDL and DLRover, a 2023 Vibrant Open Source Contributor of the Open Atomic Foundation, and a 2022 T-Star Outstanding Engineer of Ant Group. Currently, he is the architect of Ant AI Infra open source project DLRover, focusing on building stable, scalable and efficient large-scale distributed training systems.
Large model training and challenges
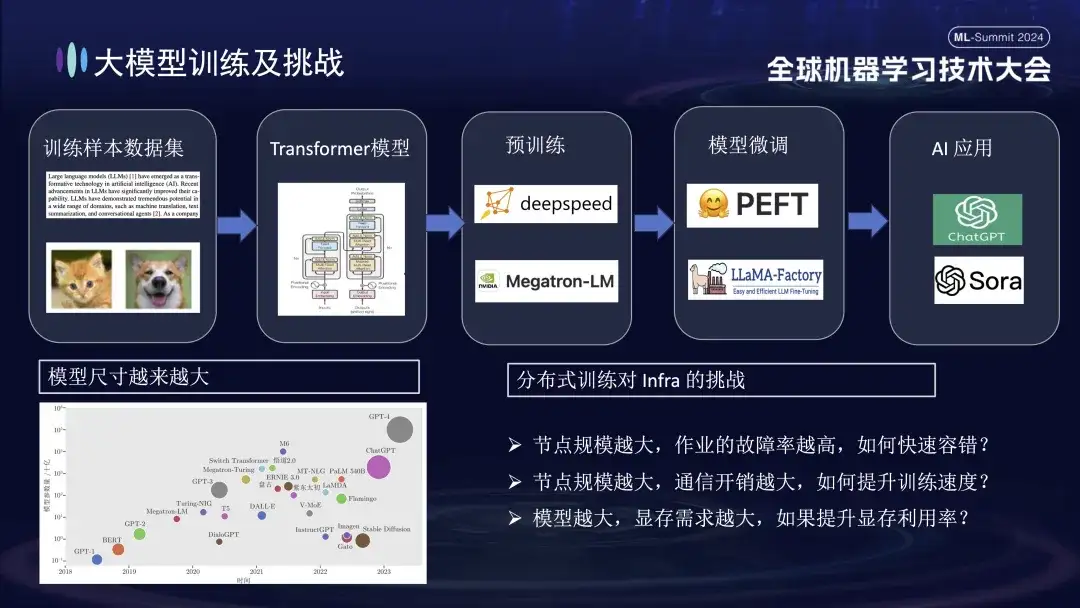
The basic process of large model training is shown in the figure above. It requires the preparation of training sample data sets, the construction of the Transformer model, pre-training, model fine-tuning, and finally building a user AI application. As large models move from one billion parameters to one trillion parameters, the growth in training scale has led to a surge in cluster costs and also affected the stability of the system. The high operation and maintenance costs brought by such a large-scale system have become an urgent problem that needs to be solved during the training of large models.
- The larger the node size, the higher the job failure rate. How to quickly tolerate faults ?
- The larger the node size, the greater the communication overhead. How to improve the training speed ?
- The larger the node size, the greater the memory requirement. How to improve the memory utilization ?
Ant AI Engineering Technology Stack
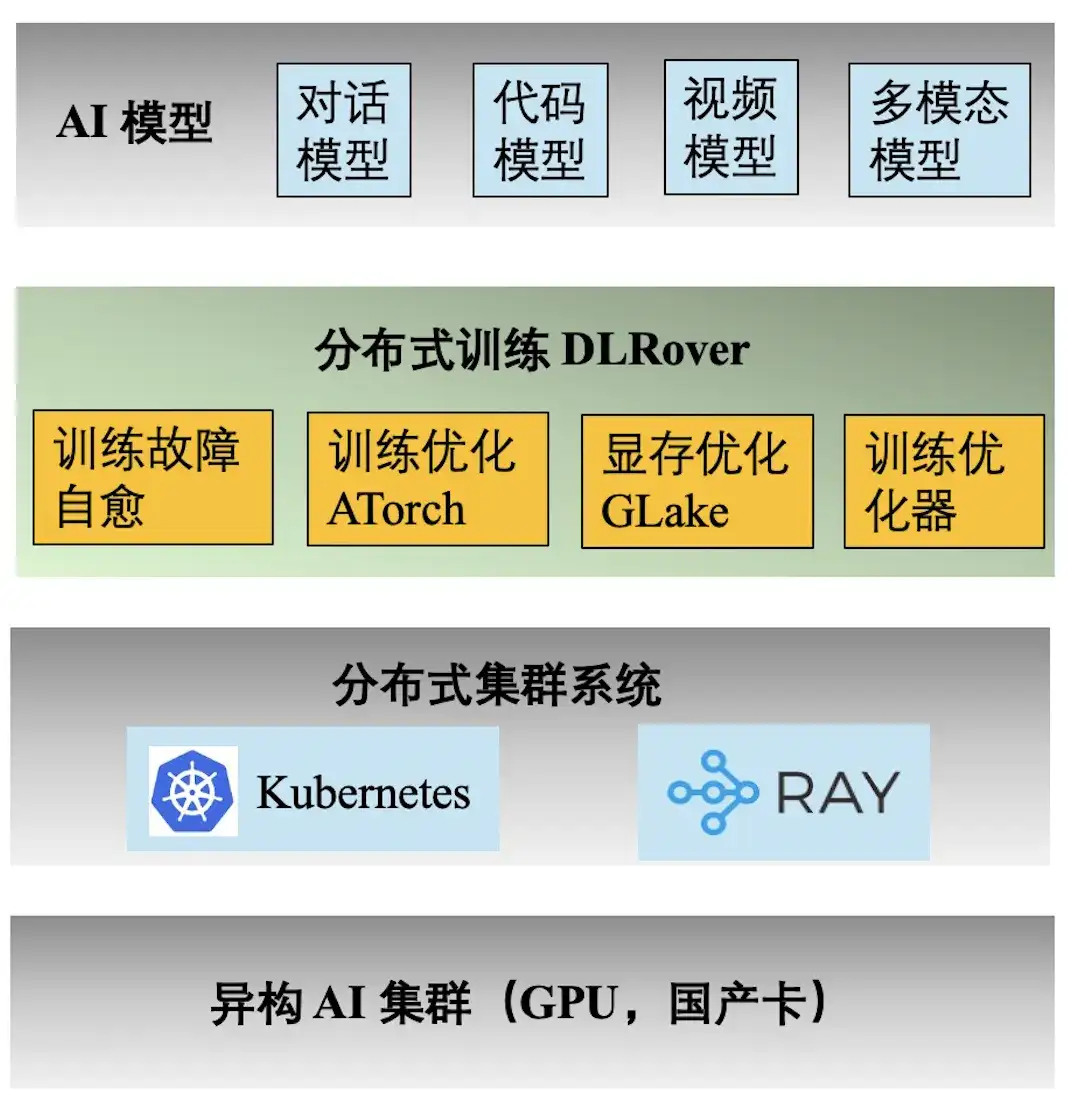
The above figure shows the engineering technology stack of Ant AI training. The distributed training engine DLRover supports a variety of training tasks for Ant's dialogue, code, video and multi-modal models. The following are the main features provided by DLRover:
- **Self-healing of training faults:** Increase the effective time of kilo-calorie distributed training to >97%, reducing the computing power cost of large-scale training faults;
- **Training Optimization ATorch:** Automatically select the optimal distributed training strategy based on the model and hardware. Increase the computing power utilization rate of the Kcal (A100) cluster hardware to >60%;
- **Training optimizer:** The optimizer is equivalent to the navigation of model iteration, which can help us achieve the goal in the shortest path. Our optimizer improves convergence acceleration by 1.5x compared to AdamW. Relevant results were published in ECML PKDD '21, KDD'23, NeurIPS '23;
- **Video memory and transmission optimization GLake: **During the training process of large models, a lot of video memory fragments will be generated, which greatly reduces the utilization of video memory resources. We reduce training memory requirements by 2-10 times through integrated memory + transmission optimization and global memory optimization. The results were published at ASPLOS'24.
Why failures lead to a waste of computing power
The reason why Ant pays special attention to the problem of training failures is mainly because machine failures during the training process significantly increase the training cost. For example, Meta announced the actual data for its large model training in 2022. When training the OPT-175B model, it used 992 80GB A100 GPUs, a total of 124 8-card machines. According to AWS GPU prices, it costs about 700,000 per day. . Due to the failure, the training cycle was extended by more than 20 days, thus increasing the computing power cost by tens of millions of yuan.

The picture below shows the distribution of faults encountered when training large models on Alibaba Cloud clusters. Some of these faults can be solved by restarting, while others cannot be repaired by restarting. For example, the card drop problem, because the faulty card is still damaged after restarting. The damaged machine must be replaced before the system can be restarted and restored.
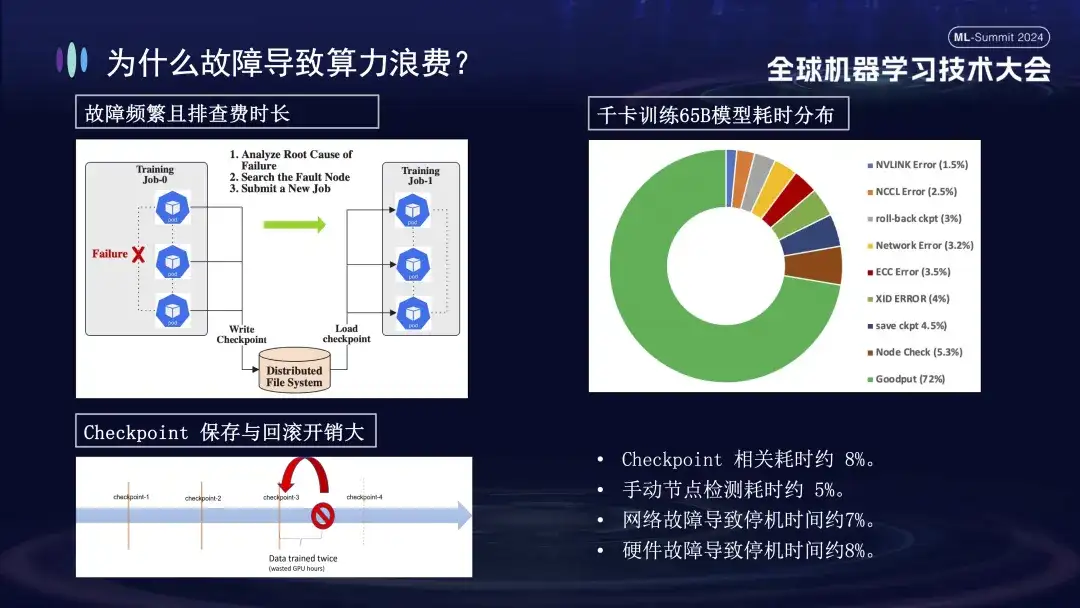
Why do training failures have such a big impact? First of all, distributed training requires multiple nodes to work together. If any node fails (whether it is a software, hardware, network card or GPU problem), the entire training process needs to be suspended. Secondly, after a training failure occurs, troubleshooting is time-consuming and laborious. For example, the commonly used manual inspection method now requires at least 1-2 hours to check once. Finally, training is stateful. To restart training, you need to recover from the previous training state before continuing, and the training state must be saved after a period of time. The saving process takes a long time, and failure rollback will also cause a waste of calculations. The right picture above shows the distribution of training time before we go online to perform self-healing. It can be seen that the relevant time of Checkpoint is about 8%, the time of manual node detection is about 5%, and the downtime caused by network failure is about 7%, hardware failure causes about 8% of downtime, and the final effective training time is only about 72%.
Overview of DLRover training fault self-healing functions

The picture above shows the two core functions of DLRover in fault self-healing technology. First of all, Flash Checkpoint can quickly save the state without stopping the training process and achieve high-frequency backup. This means that in the event of a failure, the system can immediately recover from the most recent checkpoint, reducing data loss and training time. Secondly, DLRover uses Kubernetes to implement an intelligent elastic scheduling mechanism. This mechanism can automatically respond to node failures. For example, if one fails in a cluster of 100 machines, the system will automatically adjust to 99 machines to continue training without manual intervention. In addition, it is compatible with Kubeflow and PyTorchJob, and strengthens node health monitoring capabilities to ensure that any faults are quickly identified and responded to within 10 minutes, maintaining the continuity and stability of training operations.
DLRover elastic fault tolerance training
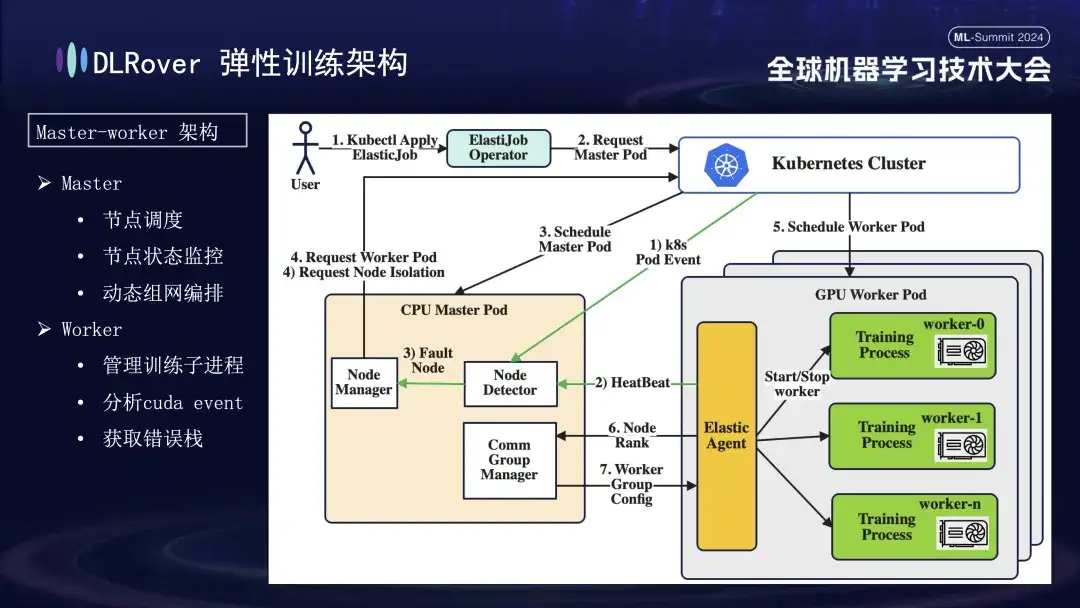
DLRover adopts a master-worker architecture, which was not common in the early days of machine learning. In this design, the master serves as the control center and is responsible for key tasks such as node scheduling, status monitoring, network configuration management, and fault log analysis, without running the training code. Usually deployed on CPU nodes. Workers bear the actual training load, and each node will run multiple sub-processes to utilize the node's multiple GPUs to accelerate computing tasks. In addition, in order to enhance the robustness of the system, we have customized and enhanced the Elastic Agent on the worker to enable more effective fault detection and location, ensuring stability and efficiency during the training process.
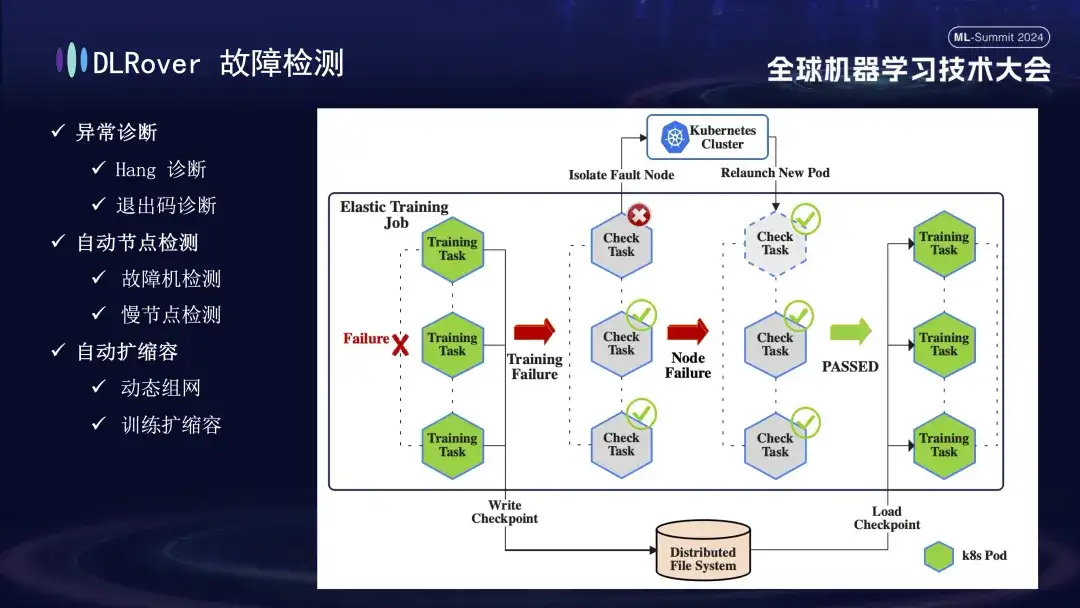
Next is the fault detection process. When a fault occurs during the training process and the task is interrupted, the intuitive performance is that the training is suspended, but the specific cause and source of the fault are not directly apparent, because once a fault occurs, all related machines will stop simultaneously. To solve this problem, we immediately executed the detection script on all machines after the failure occurred. Once it is detected that a node fails the inspection, the Kubernetes cluster will be notified immediately to remove the failed node and redeploy a new replacement node. The new node completes further health checks with the existing nodes. After everything is correct, the training task is automatically restarted. It is worth noting that if a faulty node is isolated and causes insufficient resources, we will implement a reduction strategy (will be introduced in detail later). When the original faulty machine returns to normal, the system will automatically perform capacity expansion operations to ensure efficient and continuous training.
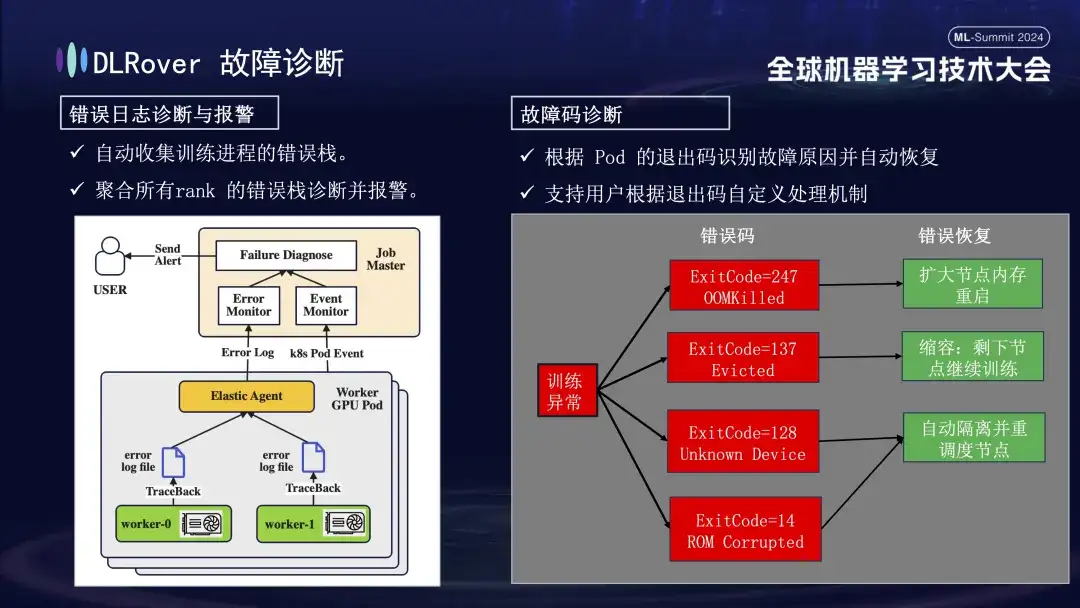
Next is the fault diagnosis process, which uses the following comprehensive methods to achieve rapid and accurate fault location and processing:
- First, the Agent collects error information from each training process and summarizes these error stacks to the master node. The master node then analyzes the aggregated error data to pinpoint the machine with the problem. For example, if a machine log shows an ECC error, the machine fault is directly determined and eliminated.
- In addition, the exit code of Kubernetes can also be used to assist diagnosis. For example, exit code 137 usually indicates that the underlying computing platform terminates the machine due to a problem detected; exit code 128 means that the device is not recognized, and the GPU driver may be faulty. There are also a large number of faults that cannot be detected through exit codes. Common ones include network jitter timeouts.
- There are also many failures, such as timeouts caused by network fluctuations, that cannot be identified by exit codes alone. We will adopt a more general strategy: regardless of the specific nature of the fault, the primary goal is to quickly identify and remove the faulty node, and then notify the master to specifically detect where the problem lies.
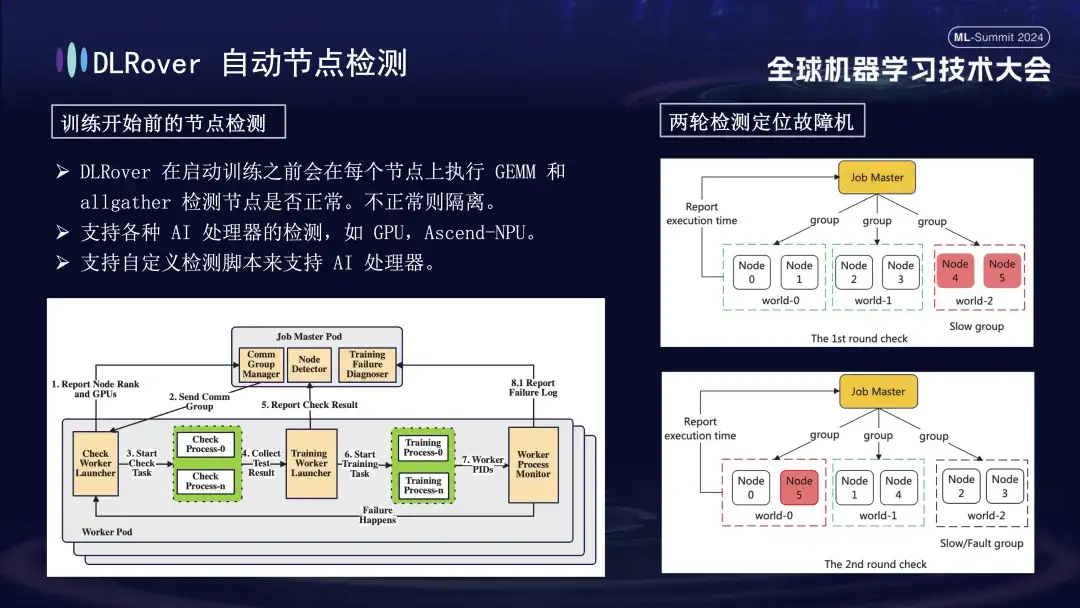
First, matrix multiplication is performed on all nodes. Subsequently, the nodes are paired and grouped. For example, in a Pod with 6 nodes, the nodes are divided into three groups (0,1), (2,3), and (4,5), and AllGather communication detection is performed. If there is a communication failure between 4 and 5, but the communication in other groups is normal, it can be concluded that the failure exists in node 4 or 5. Next, the suspected faulty node is re-paired with the known normal node for further testing, for example, combining 0 and 5 for detection. By comparing the results, the faulty node is accurately identified. This automated inspection process accurately diagnoses a faulty machine within ten minutes.
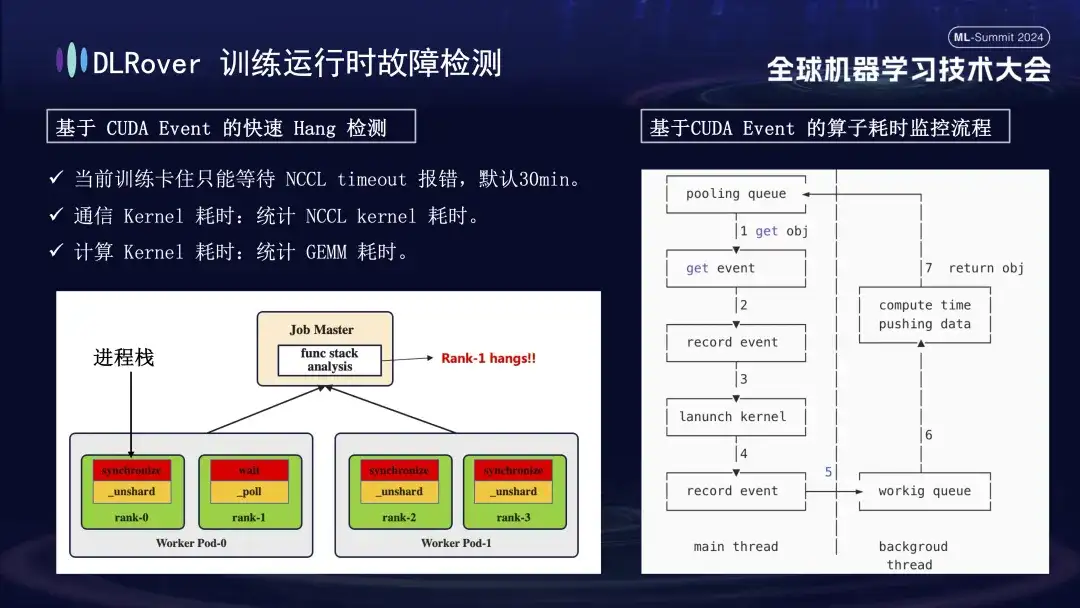
The situation of system interruption and fault detection has been discussed before, but the problem of identifying machine stuck needs to be solved. The default timeout set by NCCL is 30 minutes, which allows data to be retransmitted to reduce false positives. However, this may cause each card to wait for 30 minutes in vain when the card is actually stuck, resulting in huge cumulative losses. In order to accurately diagnose stuck, it is recommended to use a refined profiling tool. When it is detected that the program is paused, for example, there is no change in the program stack within one minute, the stack information of each card is recorded, and the differences are compared and analyzed. For example, if it is found that 3 out of 4 ranks perform the Sync operation and 1 performs the wait operation, you can locate a problem with the device. Furthermore, we hijacked the key CUDA communication kernel and computing kernel, inserted event monitoring before and after their execution, and judged whether the operation was running normally by calculating the event interval. For example, if a certain operation is not completed within the expected 30 seconds, it can be regarded as stuck, and the relevant logs and call stacks will be automatically output and submitted to the master for comparison to quickly locate the faulty machine.
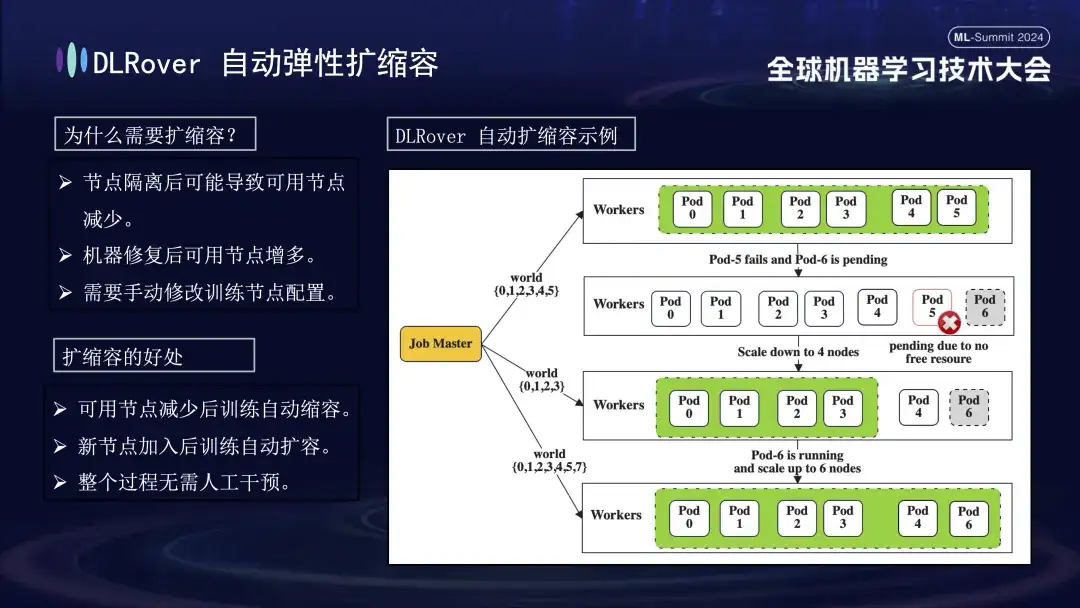
After the faulty machine is identified, considering cost and efficiency, although there was a backup mechanism in previous training, the number was limited. At this time, it is particularly important to introduce an elastic expansion and contraction strategy. Assume that the original cluster has 100 nodes. Once a node fails, the remaining 99 nodes can continue the training task; after the failed node is repaired, the system can automatically resume operation to 100 nodes, and this process does not require manual intervention, ensuring an efficient and stable training environment.
DLRover Flash Checkpoint
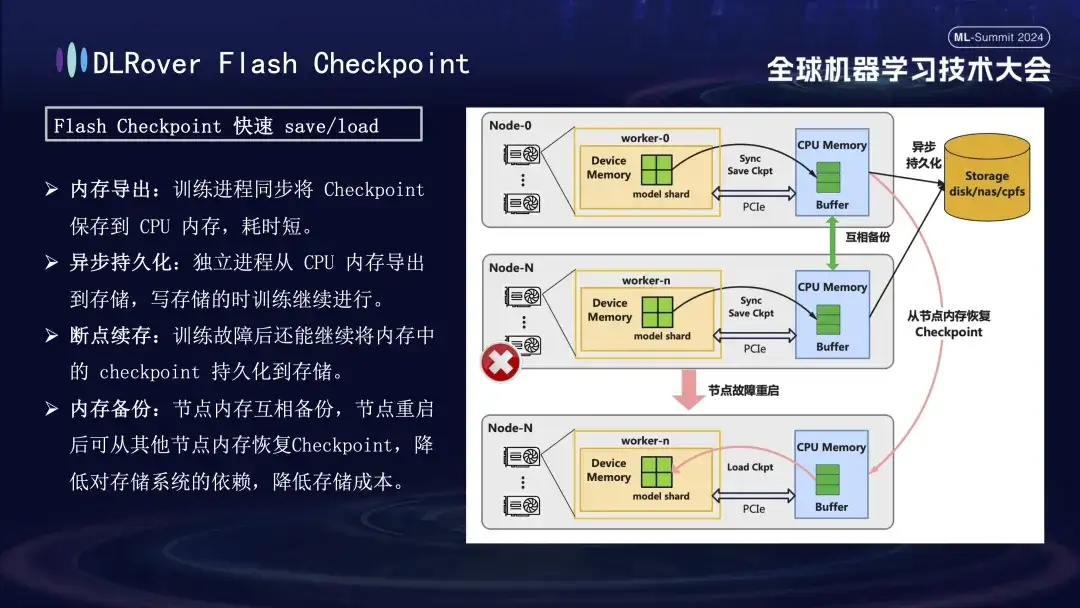
In the process of training failure recovery, the key is to save and restore the model state. The traditional Checkpoint method often leads to low training efficiency due to the long time saving. To solve this problem, DLRover innovatively proposed the Flash Checkpoint solution, which can export the model status from GPU memory to memory in near real-time during the training process. It is also supplemented by an inter-memory backup mechanism to ensure that even if a node fails, it can Quickly restore the training status from the backup node memory, greatly shortening the fault recovery time. For the commonly used Megatron-LM, the Checkpoint export process requires a centralized process to coordinate and complete, which not only introduces additional communication burden and memory consumption, but also results in higher time costs. DLRover has adopted an innovative approach after optimization, using a distributed export strategy so that each computing node (rank) can independently save and load its own Checkpoint, thus effectively avoiding additional communication and memory requirements and greatly improving efficiency.
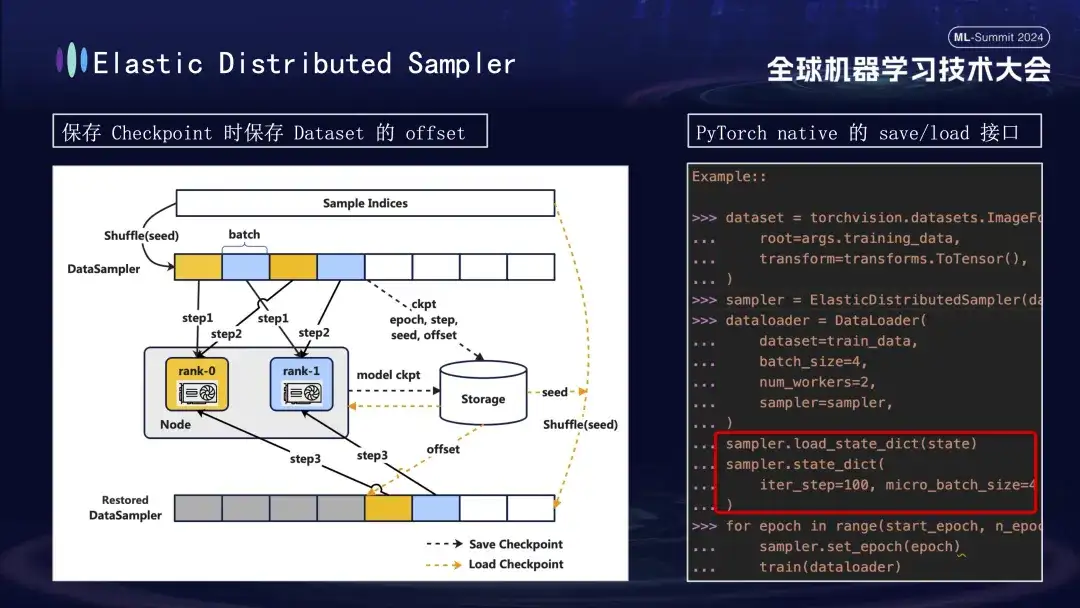
When creating the model Checkpoint, there is another detail worth paying attention to. The training of the model is based on data, assuming that we save the Checkpoint at step 1000 of the training process. If training is restarted later without considering data progress, re-consuming data directly from scratch will lead to two problems: subsequent new data may be missed, and previous data may be reused. To solve this problem, we introduced the Distributed Sampler strategy. When saving the Checkpoint, this strategy not only records the model status, but also saves the offset position of the data reading. In this way, when loading the Checkpoint to resume training, the data set will continue to be loaded from the previously saved offset point and then advance the training, thereby ensuring the continuity and consistency of the model training data and avoiding data errors or repeated processing.
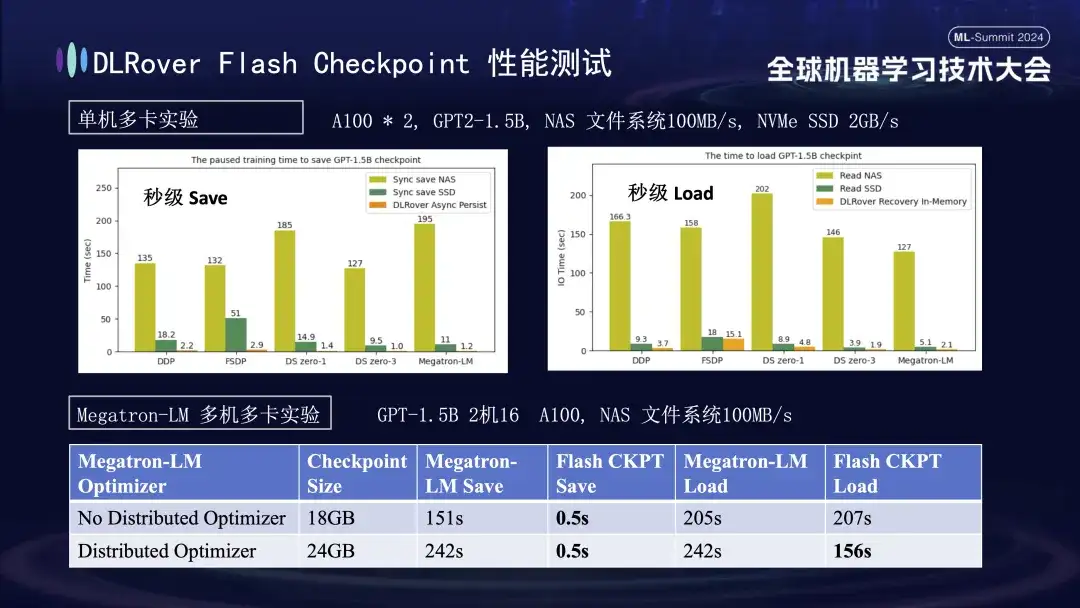
在上述图表中,我们展示了一项单机多 GPU(A100)环境下的实验结果,旨在比较不同存储方案对训练过程中 Checkpoint 保存所造成阻塞时间的影响。实验表明,存储系统的性能直接影响效率:采用较低效的存储方式直接将 Checkpoint 写入磁盘时,训练会被显著阻塞,时间延长。具体而言,针对约 20GB 大小的 1.5B 模型 Checkpoint,若使用 NAS 存储,写入时间大约在 2-3 分钟;而采取一种优化策略,即异步先将数据暂存于内存中,能大幅缩短该过程,平均只需约 1 秒钟,显著提升了训练的连续性和效率。

DLRover's Flash Checkpoint feature is widely compatible with major mainstream large model training frameworks, including DDP, FSDP, DeepSpeed, Megatron-LM, transformers.Trainer and Ascend-DDP. It has customized APIs for each framework to ensure extremely easy use. Flexibility - Users rarely need to adjust existing training code, it works out of the box. Specifically, users of the DeepSpeed framework only need to call the save interface of DLRover when executing Checkpoint, while the integration of Megatron-LM is even simpler. They only need to replace the native Checkpoint import statement with the import method provided by DLRover. Can.
DLRover distributed training practice
We conducted a series of experiments for each failure scenario to evaluate the system's fault tolerance, ability to handle slow nodes, and flexibility in scaling up and down. The specific experiments are as follows:
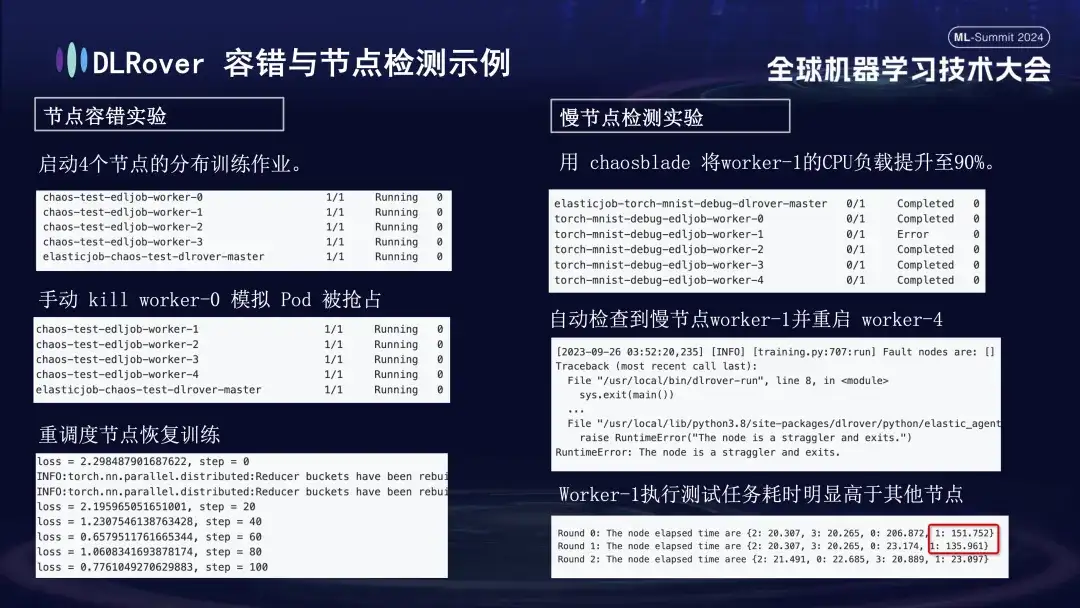
- Node fault tolerance experiment: manually shut down some nodes to test whether the cluster can recover quickly;
- Slow node experiment: Use the chaosblade tool to increase the CPU load of the node to 90% to simulate a time-consuming slow node situation;
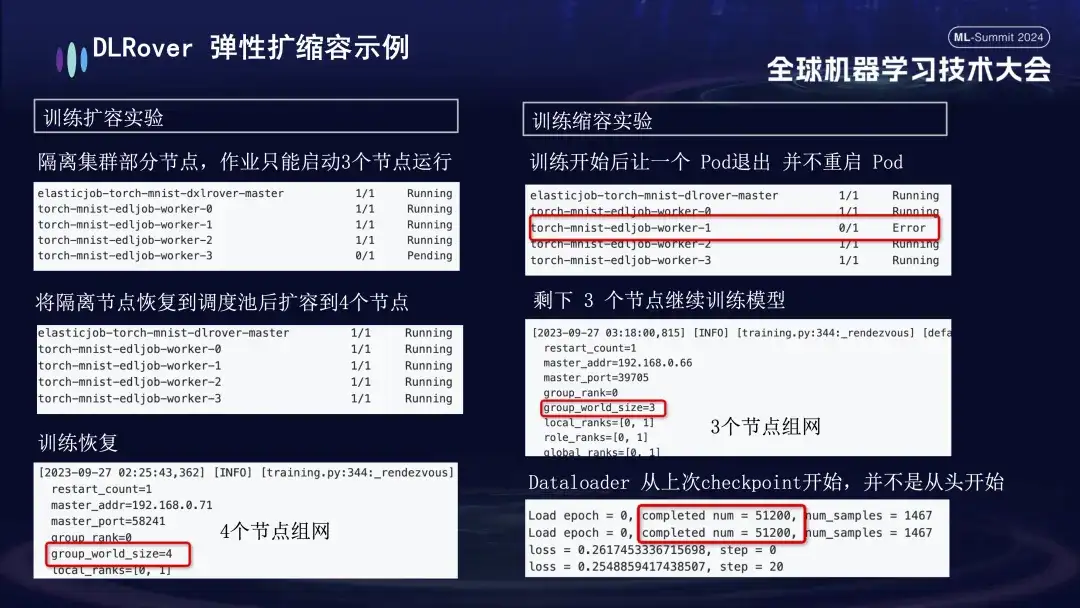
- Expansion and contraction experiment: simulates a scenario where machine resources are tight. For example, if a job is configured with 4 nodes, but only 3 are actually started, these 3 nodes can still be trained normally. After a period of time, we simulated isolating a node, and the number of Pods available for training was reduced to 3. When this machine returns to the scheduling queue, the number of available Pods can be increased to 4. At this time, the Dataloader will continue training from the last Checkpoint instead of starting over.
DLRover’s practice in domestic cards
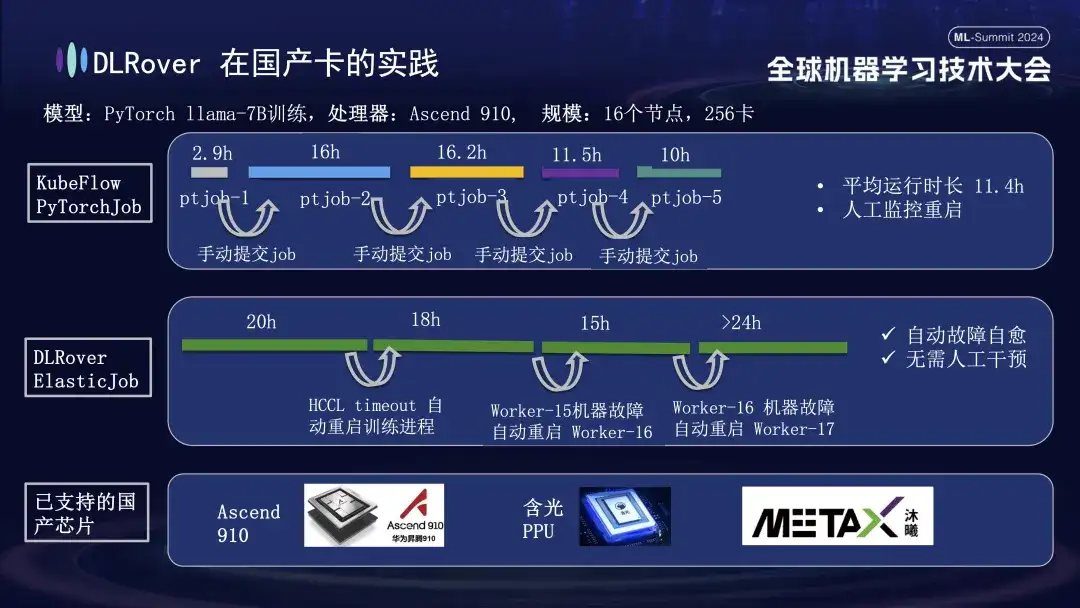
In addition to supporting GPUs, DLRover fault self-healing also supports distributed training of domestic accelerator cards. For example, when we ran the LLama-7B model on the Huawei Ascend 910 platform, we used 256 cards for large-scale training. At first, we used KubeFlow's PyTorchJob, but this tool did not have fault tolerance, causing the training process to automatically terminate after lasting about ten hours. Once this happened, the user had to manually resubmit the task; otherwise, the cluster resources will be idle. The second diagram depicts the entire training process with training fault self-healing enabled. When the training progressed for 20 hours, a communication timeout failure occurred. At this time, the system automatically restarted the training process and resumed training. About forty hours later, a machine hardware failure was encountered. The system quickly isolated the faulty machine and restarted a pod to continue training. In addition to supporting Huawei Ascend 910, we are also compatible with Alibaba's Hanguang PPU, and cooperate with Muxi Technology to use DLRover to train the LLAMA2-65B model on its independently developed Qianka GPU.
DLRover 1,000-card, 100-billion model training practice
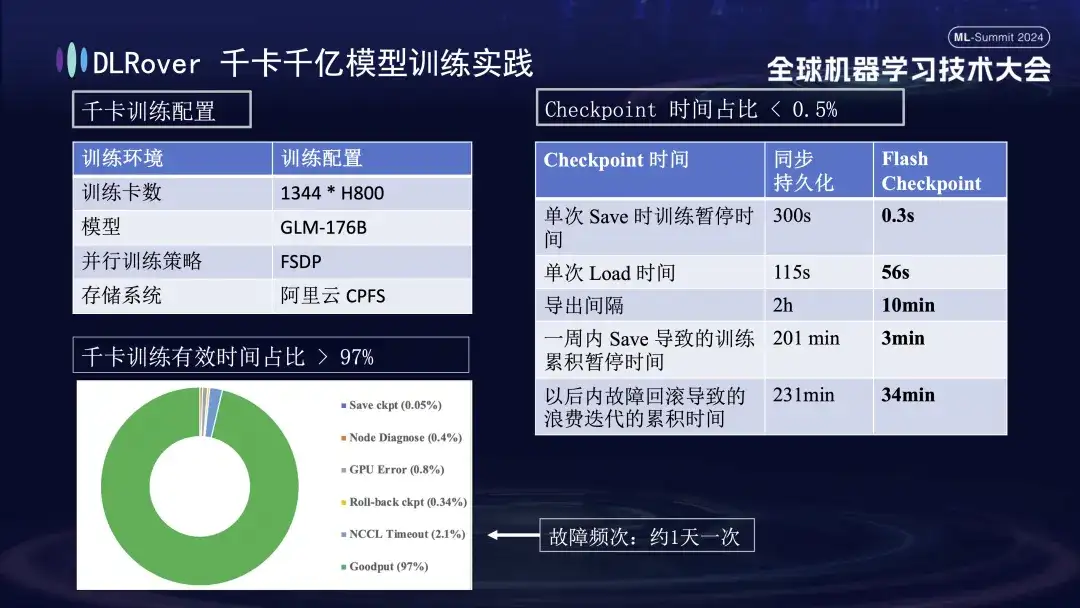
The above figure shows the practical effect of DLRover training fault self-healing on kilo-card training: more than 1,000 H800 cards are used to run large-scale model training. When the fault frequency is once a day, after the training fault self-healing function is introduced, the effective training time Accounting for more than 97%. The comparison table on the right shows that when using Alibaba Cloud's high-performance storage FSDP, a single save still takes about five minutes, while our Flash Checkpoint technology only takes 0.3 seconds to complete. In addition, through optimization, node efficiency has been improved by nearly one minute. In terms of export interval, the export operation was originally performed every 2 hours, but after the Flash Checkpoint function was launched, high-frequency export can be achieved every 10 minutes. The cumulative time spent on save operations within a week is almost negligible. At the same time, the rollback time is reduced by about 5 times compared with before.
DLRover plan & community building

DLRover has currently released three major versions. It is expected to release V0.4.0 in June, which will release runtime fault detection based on CUDA Event.
- V0.1.0(2023/07): Elastic fault tolerance and automatic expansion and contraction of TensorFlow PS on k8s/ray;
- V0.2.0(2023/09): Node detection and elastic fault tolerance for PyTorch synchronous training on k8s;
- V0.3.5(2024/03): Flash Checkpoint and domestic card fault detection;
In terms of future planning, DLRover will continue to optimize and improve the functions of DLRover in the aspects of node scheduling and management, compilation and optimization of lynx, training optimization framework AToch and domestic card training:
- **Node scheduling and management: **Communication topology-aware scheduling, reducing the communication traffic of top-level switches during Ring-based AllReduce communication; hardware Metric collection and fault prediction;
- **Compilation optimization lynx: **Computation graph scheduling optimization, achieving optimal communication and calculation overlap, hiding communication delay; SPMD automatic distributed training;
- **Training optimization framework ATorch: **RLHF training optimization; initialization acceleration of distributed training; automatic training acceleration configuration auto_accelerate;
- **Domestic card training: **Expand functions such as fault self-healing and training acceleration to domestic cards; provide best practices for domestic card training;

Technological progress begins with open collaboration. Everyone is welcome to follow and participate in our open source projects on GitHub.
DLRover:
https://github.com/intelligent-machine-learning/dlrover
GLAKE:
https://github.com/intelligent-machine-learning/glake
Our WeChat public account "AI Infra" will also regularly publish cutting-edge technical articles on AI infrastructure, aiming to share the latest research results and technical insights. At the same time, in order to promote further exchanges and discussions, we have also set up a DingTalk group. Everyone is welcome to join and ask questions and discuss related technical issues here. thank you all!
Article recommendations
