
With the rapid advancement of artificial intelligence technology, OpenAI has emerged as one of the leaders in the field. It performs well on a variety of language processing tasks, including machine translation, text classification, and text generation. With the rise of OpenAI, many other high-quality open source large language models have emerged, such as Llama, ChatGLM, Qwen, etc. These excellent open source models can also help teams quickly build an excellent LLM application.
But faced with so many choices, how can we use OpenAI interfaces uniformly while reducing development costs? How to efficiently and continuously monitor the running performance of LLM applications without adding additional development complexity? GreptimeAI and Xinference provide practical solutions to these problems.
What is GreptimeAI
GreptimeAI is built on the open source time series database GreptimeDB. It is a set of observability solutions for large language model (LLM) applications. It currently supports the LangChain and OpenAI ecosystems. GreptimeAI enables you to gain a comprehensive understanding of costs, performance, traffic, and security in real time, helping teams improve the reliability of LLM applications.
What is Xinference
Xinference is an open source model inference platform designed for large language models (LLM), speech recognition models and multi-modal models, and supports privatized deployment. Xinference provides a RESTful API compatible with the OpenAI API, and integrates third-party developer tools such as LangChain, LlamaIndex and Dify.AI to facilitate model integration and development. Xinference integrates multiple LLM inference engines (such as Transformers, vLLM and GGML), is suitable for different hardware environments, and supports distributed multi-machine deployment. It can efficiently allocate model inference tasks among multiple devices or machines to meet the needs of multi-model and high-speed computing. Available deployment needs.
GreptimeAI + Xinference deploy/monitor LLM applications
Next, we will take the Qwen-14B model as an example to introduce in detail how to use Xinference to deploy and run the model locally. An example will be shown here, which uses a method similar to OpenAI function calling (Function Calling) to perform weather queries, and demonstrates how to use GreptimeAI to monitor the usage of LLM applications.
Register and obtain GreptimeAI configuration information
Visit https://console.greptime.cloud to register the service and create the AI service. After jumping to the AI Dashboard, click the Setup page to obtain the OpenAI configuration information.
Start the Xinference model service
It is very simple to start the Xinference model service locally. You only need to enter the following command:
xinference-local -H 0.0.0.0
Xinference will start the service locally by default, and the default port is 9997. The process of installing Xinference locally is omitted here. You can refer to this article for installation.
Starting the model via Web UI
After Xinference is started, enter http://localhost:9997 in the browser to access the Web UI.

Start the model from the command line
We can also use Xinference's command line tool to start the model. The default Model UID is qwen-chat (the model will be accessed through this ID later).
xinference launch -n qwen-chat -s 14 -f pytorch
Get weather information through OpenAI style interface
Suppose we have the ability get_current_weatherto obtain weather information for a specified city by calling the function, with parameters locationand format.
Configure OpenAI and call interface
Access the Xinference local port through OpenAI's Python SDK, use GreptimeAI to collect data, use chat.completionsthe interface to create a conversation, and use to toolsspecify the function list we just defined.
from greptimeai import openai_patcher
from openai improt OpenAI
client = OpenAI(
base_url="http://127.0.0.1:9997/v1",
)
openai_patcher.setup(client=client)
messages = [
{"role": "system", "content": "你是一个有用的助手。不要对要函数调用的值做出假设。"},
{"role": "user", "content": "上海现在的天气怎么样?"}
]
chat_completion = client.chat.completions.create(
model="qwen-chat",
messages=messages,
tools=tools,
temperature=0.7
)
print('func_name', chat_completion.choices[0].message.tool_calls[0].function.name)
print('func_args', chat_completion.choices[0].message.tool_calls[0].function.arguments)
tools details
Function calling The function (tool) list is defined below, with required fields specified.
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "获取当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市,例如北京",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "使用的温度单位。从所在的城市进行推断。",
},
},
"required": ["location", "format"],
},
},
}
]
The output is as follows, you can see that we chat_completiongot the function call generated by the Qwen model through:
func_name: get_current_weather
func_args: {"location": "上海", "format": "celsius"}
Get the function call result and call the interface again
It is assumed here that we have called the function with the given parameters get_current_weatherand have obtained the result, and resend the result and context to the Qwen model:
messages.append(chat_completion.choices[0].message.model_dump())
messages.append({
"role": "tool",
"tool_call_id": messages[-1]["tool_calls"][0]["id"],
"name": messages[-1]["tool_calls"][0]["function"]["name"],
"content": str({"temperature": "10", "temperature_unit": "celsius"})
})
chat_completion = client.chat.completions.create(
model="qwen-chat",
messages=messages,
tools=tools,
temperature=0.7
)
print(chat_completion.choices[0].message.content)
Final Results
The Qwen model will eventually output a response like this:
上海现在的温度是 10 摄氏度。
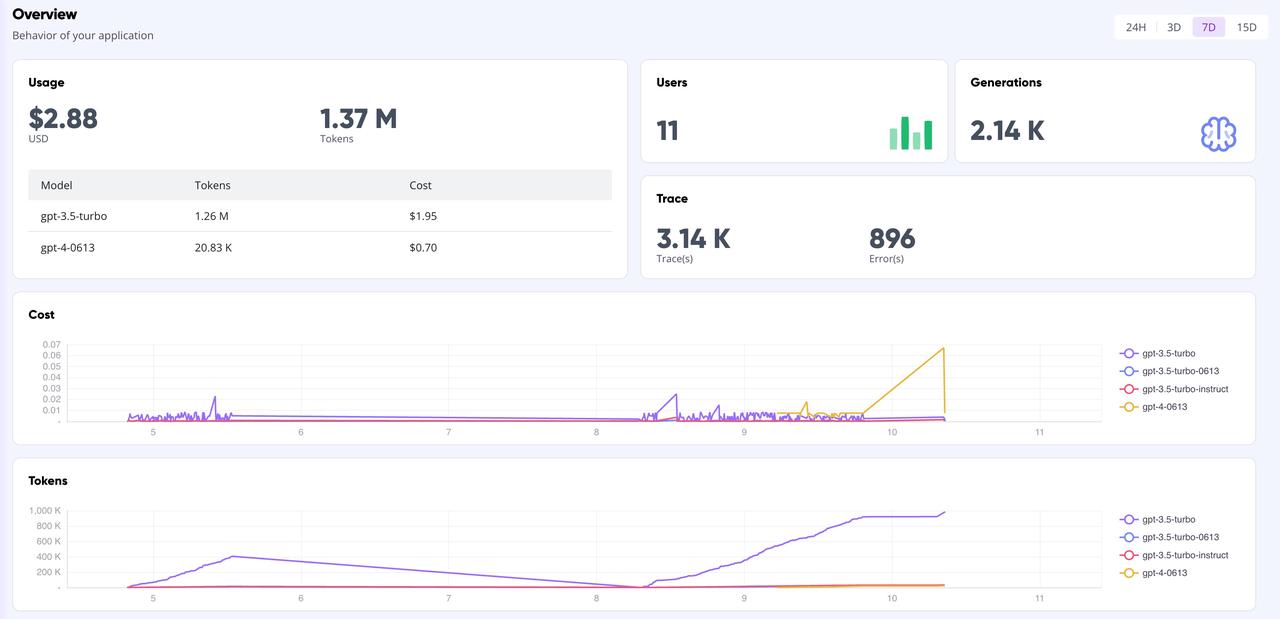
GreptimeAI billboard
On the GreptimeAI Dashboard page, you can comprehensively and real-time monitor all call data based on the OpenAI interface, including key indicators such as token, cost, latency, trace, etc. Shown below is the overview page of the dashboard.
Summarize
If you are using open source models to build LLM applications and want to use OpenAI style to make API calls, then using Xinference to manage the inference model and using GreptimeAI to monitor the model operation is a good choice. Whether you are conducting complex data analysis or simple daily queries, Xinference can provide powerful and flexible model management capabilities. At the same time, combined with the monitoring function of GreptimeAI, you can more efficiently understand and optimize the performance and resource consumption of the model.
We look forward to your attempts and welcome sharing of experiences and insights using GreptimeAI and Xinference. Let’s explore the infinite possibilities of artificial intelligence together!
Little knowledge about Greptime:
Greptime Greptime Technology was founded in 2022 and is currently improving and building three products: time series database GreptimeDB, GreptimeCloud and observability tool GreptimeAI.
GreptimeDB is a time series database written in Rust language. It is distributed, open source, cloud native and highly compatible. It helps enterprises read, write, process and analyze time series data in real time while reducing long-term storage costs; GreptimeCloud can provide users with A fully managed DBaaS service that can be highly integrated with observability, Internet of Things and other fields; GreptimeAI is tailor-made for LLM, providing full-link monitoring of cost, performance and generation processes.
GreptimeCloud and GreptimeAI have been officially tested. Welcome to follow the official account or official website for the latest developments!

Official website: https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
Documentation: https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime/
A programmer born in the 1990s developed a video porting software and made over 7 million in less than a year. The ending was very punishing! High school students create their own open source programming language as a coming-of-age ceremony - sharp comments from netizens: Relying on RustDesk due to rampant fraud, domestic service Taobao (taobao.com) suspended domestic services and restarted web version optimization work Java 17 is the most commonly used Java LTS version Windows 10 market share Reaching 70%, Windows 11 continues to decline Open Source Daily | Google supports Hongmeng to take over; open source Rabbit R1; Android phones supported by Docker; Microsoft's anxiety and ambition; Haier Electric shuts down the open platform Apple releases M4 chip Google deletes Android universal kernel (ACK ) Support for RISC-V architecture Yunfeng resigned from Alibaba and plans to produce independent games for Windows platforms in the future