
1. Background introduction
Parameterized queries refer to a type of query that has the same template and only differs in predicate binding parameter values. They are widely used in modern database applications. They perform actions repeatedly, which provides opportunities for performance optimization.
However, the current method of handling parameterized queries in many commercial databases only optimizes the first query instance (or user-specified instance) in the query, caches its best plan and reuses it for subsequent query instances. Although this method optimizes the time to minimize, due to different optimal plans for different query instances, the execution of the cached plan may be arbitrarily sub-optimal, which is not applicable in actual application scenarios.
Most traditional optimization methods require many assumptions about the query optimizer, but these assumptions often do not match actual application scenarios. Fortunately, with the rise of machine learning, the above problems can be effectively solved. This issue will introduce in detail two papers published in VLDB2022 and SIGMOD2023:
论文 1:《Leveraging Query Logs and Machine Learning for Parametric Query Optimization》
论文 2:《Kepler: Robust Learning for Faster Parametric Query Optimization》
2. Essence of Paper 1
"Leveraging Query Logs and Machine Learning for Parametric Query Optimization" This paper decouples parameterized query optimization into two problems:
(1) PopulateCache: caches K plans for a query template;
(2) getPlan: for each query Instance, selects the best plan from the cached plans.
The algorithm architecture of this paper is shown in the figure below. It is mainly divided into two modules: PopulateCache and getPlan module.
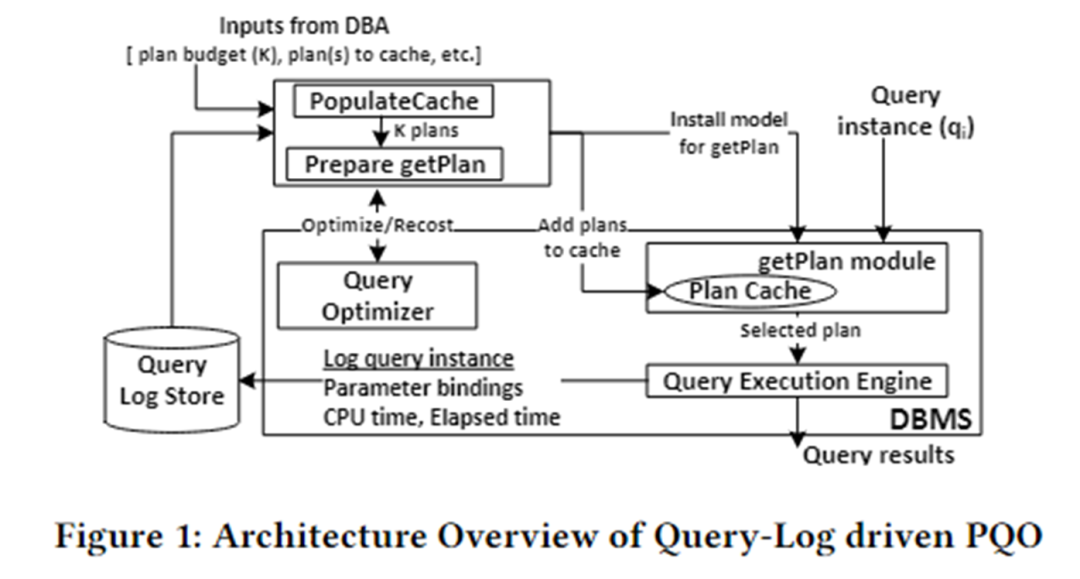
PopulateCache uses the information in the query log to cache K plans for all query instances. The getPlan module first collects cost information between K plans and query instances by interacting with the optimizer, and uses this information to train the machine learning model. Deploy the trained model in the DBMS. When a query instance arrives, the best plan for that instance can be quickly predicted.
PopulateCache
The PolulateCache module is responsible for identifying a set of cache plans for a given parameterized query. The search phase utilizes two optimizer APIs:
- Optimizer call: Returns the plan selected by the optimizer for a query instance;
- Recost call: Returns the cost estimated by the optimizer for a query instance and corresponding plan;
The algorithm flow is as follows:
- Plan-collection phase: Call optimizer call to collect candidate plans for n query instances in the query log;
- Plan-recost phase: For each query instance and each candidate plan, call recost call to form a plan-recost matrix;
- K-set identification phase: adopts a greedy algorithm and uses the plan-recost matrix to cache K plans to minimize suboptimality.
getPlan
The getPlan module is responsible for selecting one of the K cached plans for execution for a given query instance. The getPlan algorithm can consider two goals: minimizing the cost estimated by the optimizer or minimizing the actual execution cost among K cache plans.
Consider goal 1: Use the plan-recost matrix to train a supervised ML model, and consider classification and regression.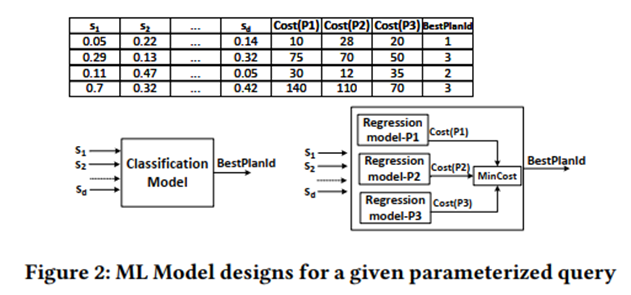
Consider goal 2: Use reinforcement learning training model based on Multi-Armed Bandit.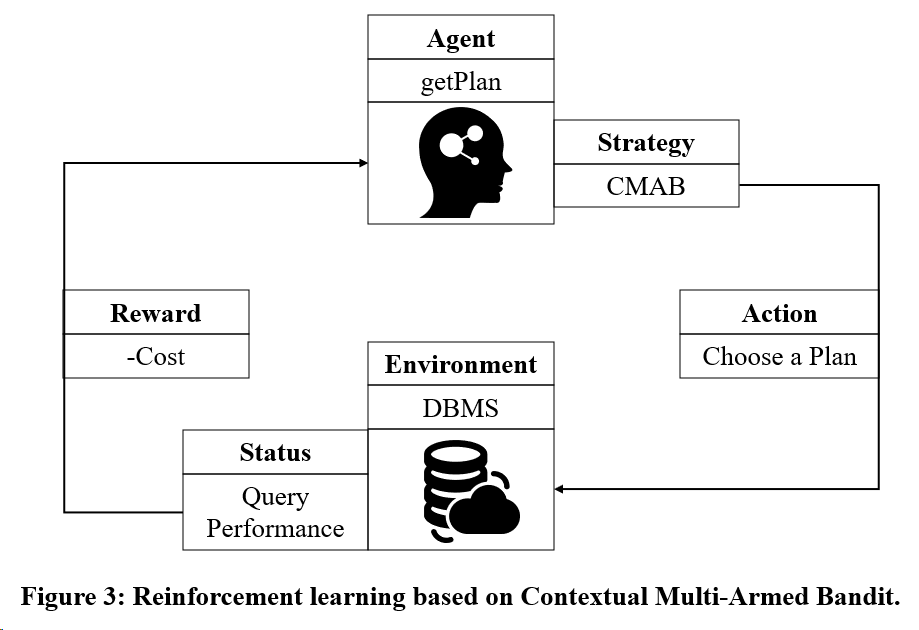
3. Essence of Paper 2
"Kepler: Robust Learning for Faster Parametric Query Optimization" This paper proposes an end-to-end, learning-based parametric query optimization method, which aims to reduce query optimization time and improve query execution performance.
The algorithm architecture is as follows. Kepler also decouples the problem into two parts: plan generation and learning-based plan prediction. It is mainly divided into three stages: plan generation strategy, training query execution phase and robust neural network model.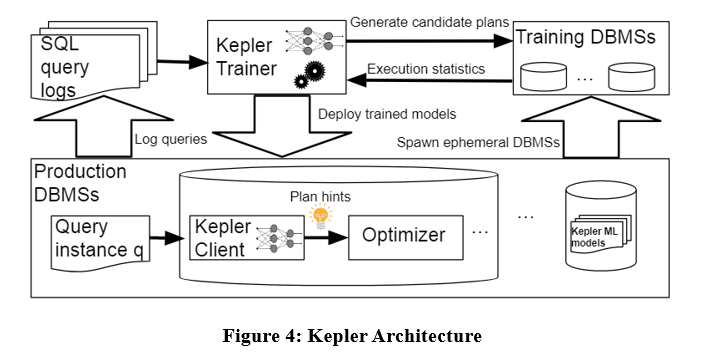
As shown in the figure above, input the query instance in the query log to Kepler Trainer. Kepler Trainer first generates a candidate plan, and then collects execution information related to the candidate plan as training data to train the machine learning model. After training, the model is deployed in the DBMS. . When a query instance arrives, Kepler Client is used to predict the best plan and execute it.
Row Count Evolution
This paper proposes a candidate plan generation algorithm called Row Count Evolution (RCE), which generates candidate plans by perturbing the optimizer cardinality estimate.
The idea of this algorithm comes from: incorrect estimation of cardinality is the main cause of optimizer suboptimality, and the candidate plan generation stage only needs to contain the optimal plan of one instance, rather than selecting a single optimal plan.
The RCE algorithm first generates the optimal plan for the query instance, then perturbs the join cardinality of its subplans within the exponential interval range, repeats it multiple times and performs multiple iterations, and finally uses all generated plans as candidate plans. Specific examples are as follows: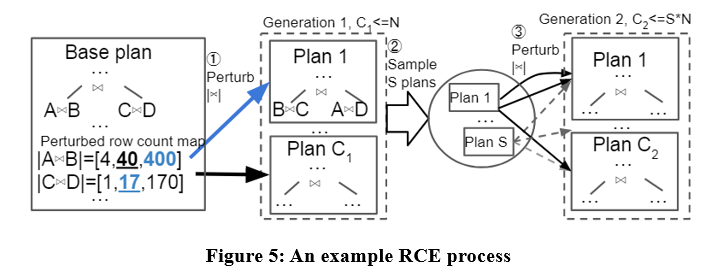
With the RCE algorithm, the candidate plans generated may be better than the plan produced by the optimizer. Because the optimizer may have cardinality estimation errors, and RCE can produce the optimal plan corresponding to the correct cardinality by continuously perturbing the cardinality estimate.
Training Data Collection
After obtaining the candidate plan set, each plan is executed on the workload for each query instance, and the real execution time is collected for training of the supervised optimal plan prediction model. The above process is relatively cumbersome. This article proposes some mechanisms to speed up the collection of training data, such as parallel execution, adaptive timeout mechanism, etc.
Robust Best-Plan Prediction
The resulting actual execution data is used to train a neural network to predict the optimal plan for each query instance. The neural network used is a spectral normalized Gaussian neural process. This model ensures the stability of the network and the convergence of training, and can provide uncertainty estimates for predictions. When the uncertainty estimate is greater than a certain threshold, it is left to the optimizer to select an execution plan. Performance regression is avoided to a certain extent.
4. Summary
Both of the above two papers decouple parameterized queries into populateCache and getPlan. The comparison between the two is shown in the table below.
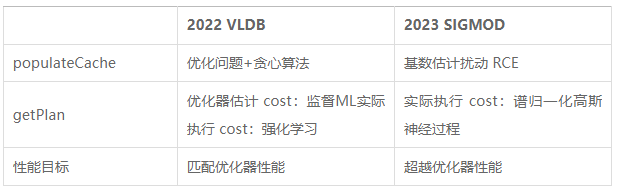
Although algorithms based on machine learning models perform well in plan prediction, their training data collection process is expensive, and the models are not easy to generalize and update. Therefore, existing parameterized query optimization methods still have room for improvement.
本文图示来源: 1)Kapil Vaidya & Anshuman Dutt, 《Leveraging Query Logs and Machine Learning for Parametric Query Optimization》, 2022 VLDB,https://dl.acm.org/doi/pdf/10.14778/3494124.3494126 2)LYRIC DOSHI & VINCENT ZHUANG, 《Kepler: Robust Learning for Faster Parametric Query Optimization》, 2023 SIGMOD,https://dl.acm.org/doi/pdf/10.1145/3588963
I decided to give up on open source industrial software. Major events - OGG 1.0 was released, Huawei contributed all source code. Ubuntu 24.04 LTS was officially released. Google Python Foundation team was laid off. Google Reader was killed by the "code shit mountain". Fedora Linux 40 was officially released. A well-known game company released New regulations: Employees’ wedding gifts must not exceed 100,000 yuan. China Unicom releases the world’s first Llama3 8B Chinese version of the open source model. Pinduoduo is sentenced to compensate 5 million yuan for unfair competition. Domestic cloud input method - only Huawei has no cloud data upload security issues