

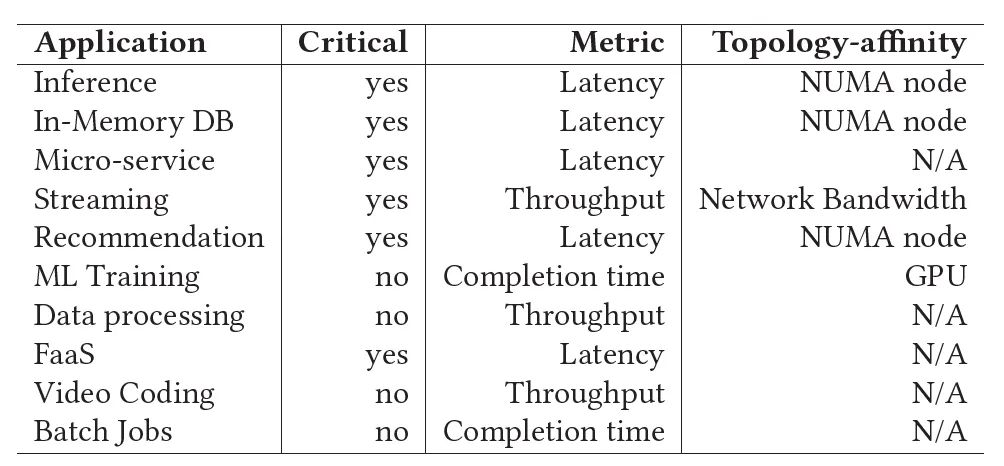
QoS management capabilities can uniformly schedule online and offline applications, greatly improving resource utilization.
Source | ByteDance Infrastructure Team
Open Source | github.com/kubewharf/godel-scheduler
This article interprets the paper " Gödel: Unified Large-Scale Resource Managment and Scheduling at Bytedance " published by the Bytedance infrastructure orchestration and scheduling team at SoCC 2023, the top international cloud computing conference .

Paper link: dl.acm.org/doi/proceedings/10.1145/3620678
The paper introduces a high-throughput task scheduling system based on Kubernetes proposed by ByteDance that supports the mixing of online tasks and offline tasks. It aims to effectively solve the resource allocation problem of different types of tasks in large-scale data centers and improve the resources of the data center. Utilization, resiliency, and scheduling throughput.
Currently, the scheduling system supports the management of ultra-large-scale clusters with tens of thousands of nodes, and provides resource pooling capabilities for multiple types of tasks including microservices, batch, streaming tasks, and AI. Since 2022, it has been deployed in batches in ByteDance's internal data centers. The Gödel scheduler has been verified to provide >60% CPU utilization and >95% GPU utilization during peak periods , with a peak scheduling throughput of nearly 5,000 pods/ sec .
introduction
In the past few years, with the rapid development of ByteDance's business lines, the company's internal business types have become more and more diverse, including microservices, promoted search (recommendation/advertisement/search), big data, machine learning, The scale of storage and other businesses is expanding rapidly, and the amount of computing resources required for them is also expanding rapidly. In the early days, Bytedance's online business and offline business had independent resource pools, and separate pool management was adopted between the businesses. In order to cope with the explosive growth of online business requests during important festivals and major events, infrastructure teams often need to make plans in advance and lend some offline business resources to the online business resource pool. Although this method can meet temporary needs, the resource lending process between different resource pools is long, complex, and inefficient. At the same time, independent resource pools lead to high costs of co-location between offline businesses, and the ceiling for improving resource utilization is also very limited. In order to deal with this problem, the paper proposes the unified offline scheduler Gödel, which aims to use the same set of schedulers to uniformly schedule and manage offline services and realize resource pooling, thereby improving resource utilization and resource elasticity. Optimize business costs and experience, and reduce operation and maintenance pressure. The Gödel scheduler is based on the Kubernetes platform and can seamlessly replace the Kubernetes native scheduler. It is superior to the Kubernetes native scheduler and other schedulers in the community in terms of performance and functionality.
Start the engine
ByteDance operates dozens of ultra-large-scale multi-cluster data centers. Tens of millions of containerized tasks are created and deleted every day. The average task throughput of a single cluster during the evening peak is >1000 pods/sec. The business priorities, operating modes and resource requirements of these tasks are different. How to schedule these tasks efficiently and reasonably to maintain high resource utilization and elasticity while ensuring high-quality task SLA and different task resource requirements is a challenge. Very challenging job.
Through research, we found that none of the cluster schedulers commonly used in the community can meet ByteDance’s requirements well:
- Although the Kubernetes native scheduler is very suitable for microservice scheduling and provides a variety of flexible scheduling semantics, its support for offline services is not satisfactory. At the same time, because the Kubernetes native scheduler has a low scheduling throughput (< 200 pods/sec), The supported cluster size is also limited (usually <= 5000 nodes), and it cannot meet the huge online business scheduling needs within ByteDance.
- Volcano from the CNCF community is a scheduler mainly aimed at offline services, which can meet the scheduling needs of offline services (eg batch, offline training, etc.) (eg Gang scheduling). However, its scheduling throughput rate is also relatively low, and it cannot support online services at the same time.
- YARN is another popular cluster resource management tool and has been the first choice for offline business scheduling for a long time in the past. It not only has good support for the scheduling semantics required for offline services such as batch and offline training, but also has a high scheduling throughput rate and can support large-scale clusters. However, its main drawback is that it does not support online businesses such as microservices well, and it cannot meet the scheduling needs of online and offline businesses at the same time.

Therefore, ByteDance hopes to develop a scheduler that combines the advantages of Kubernetes and YARN to open up resource pools and uniformly manage all types of businesses. Based on the above discussion, the scheduler is expected to have the following characteristics:
- Unified Resource Pool
All computing resources in the cluster are visible and assignable to various tasks both online and offline. Reduce resource fragmentation rate and cluster operation and maintenance costs.
- Improved Resource Utilization
Mix tasks of different types and priorities in the cluster and node dimensions to improve the utilization of cluster resources.
- High Resource Elasticiy
In the cluster and node dimensions, computing resources can be flexibly and quickly transferred between services of different priorities. While improving resource utilization, the resource priority allocation rights and SLA of high-quality services are guaranteed at all times.
- High Scheduling Throughput
Compared with the Kubernetes native scheduler and the community's Volcano scheduler, both online and offline services must greatly improve scheduling throughput. Meet business requirements > 1000 pods/sec.
- Topology-aware Scheduling
The resource microtopology of candidate nodes is identified when making scheduling decisions rather than when kubelet admits, and appropriate nodes are selected for scheduling based on business needs.
Introduction to Gödel
Gödel Scheduler is a distributed scheduler used in Kubernetes cluster environments that can uniformly schedule online and offline services. It can provide good scalability and scheduling quality while meeting offline business function and performance requirements. As shown in the figure below, Gödel Scheduler has a similar structure to the Kubernetes native scheduler and consists of three components: Dispatcher, Scheduler and Binder. The difference is that in order to support larger clusters and provide higher scheduling throughput, its Scheduler component can be multi-instance and adopt optimistic concurrent scheduling, while Dispatcher and Binder run in a single instance.
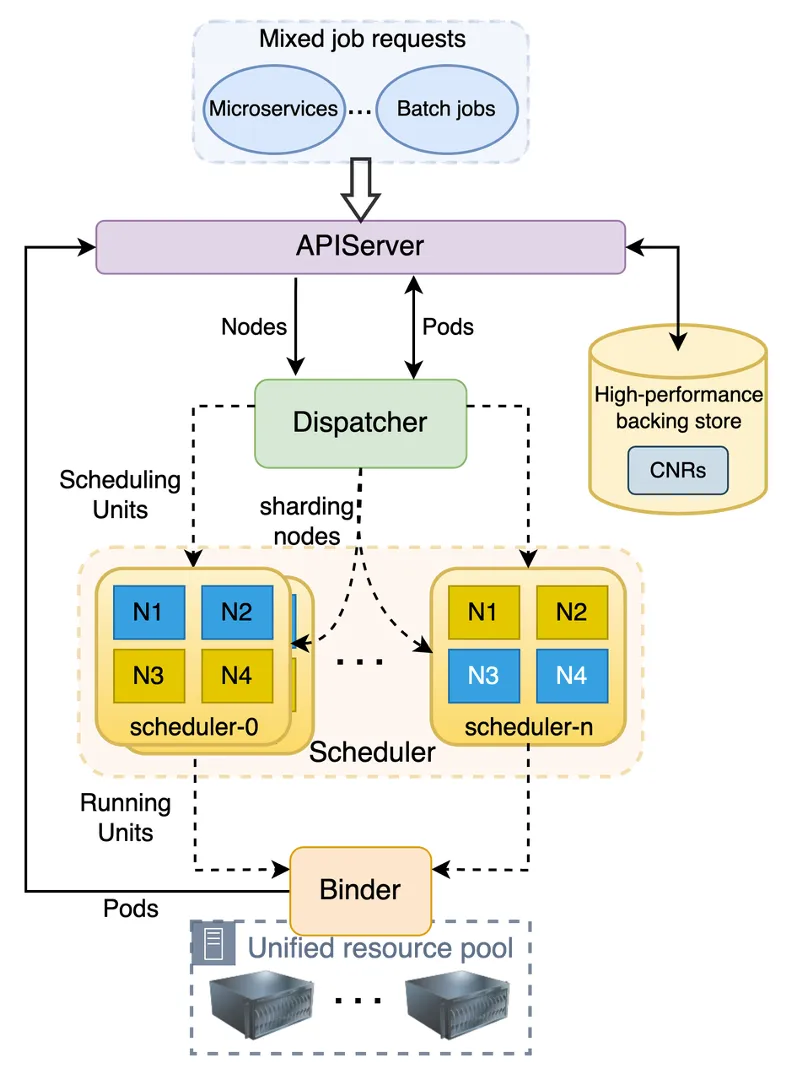
core components
Dispatcher is the entrance to the entire scheduling process and is mainly responsible for task queuing, task distribution, node partitioning, etc. It mainly consists of several parts: Sorting Policy Manager, Dispatching Policy Manager, Node Shuffler, and Scheduler Maintainer.
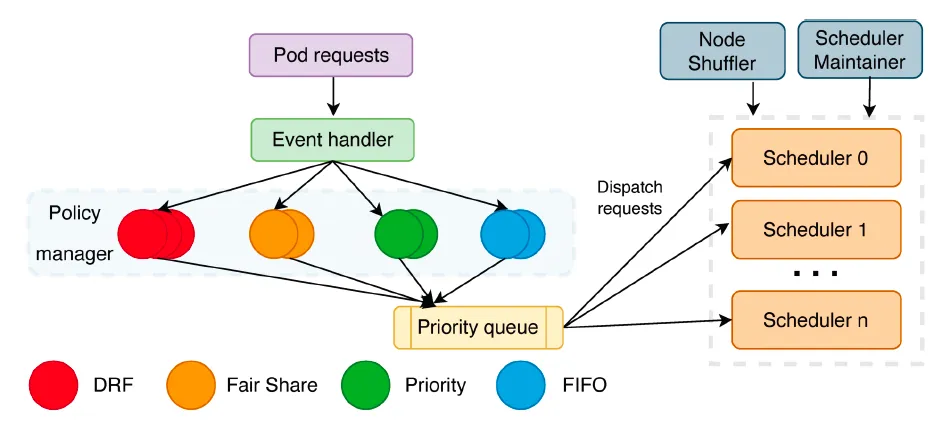
- Sort Policy Manager : Mainly responsible for queuing tasks. It currently implements queuing strategies such as FIFO, DRF, and FairShare. More queuing strategies will be added in the future, such as priority value based, etc.
- Dispatching Policy Manager : Mainly responsible for distributing tasks to different Scheduler instances and supporting different distribution strategies through plug-in configuration. The current default strategy is based on LoadBalance.
- Node Shuffler : Mainly responsible for partitioning cluster nodes based on the number of Scheduler instances. Each node can only be in one Partition. Each Scheduler instance corresponds to a Partition. When a Scheduler instance works, it will give priority to the nodes in its own Partition. If no node that meets the requirements is found, it will look for nodes in other Partitions. If the cluster status changes, such as adding or deleting nodes, or the number of Schedulers changes, node shuffle will re-divide the nodes based on the actual situation.
- Scheduler Maintainer : Mainly responsible for maintaining the status of each Scheduler instance, including Scheduler instance health status, load status, number of Partition nodes, etc.
Scheduler receives task requests from Dispatcher and is responsible for making specific scheduling and preemption decisions for tasks, but does not actually execute them. Like the Kubernetes native scheduler, Gödel's Scheduler also determines a scheduling decision through a series of plugins at different links. For example, the following two plugins are used to find nodes that meet the requirements.
- Filtering plugins: task-based resource requests, filtering out nodes that do not meet the requirements;
- Scoring plugins: Score the nodes filtered above and select the most suitable node.
Unlike the Kubernetes native scheduler, Gödel's Scheduler allows multiple instances to run in a distributed manner . For very large-scale clusters and scenarios that require high throughput, we can configure multiple scheduler instances to meet the needs. At this time, each scheduler instance is scheduled independently and in parallel. When selecting a node, it is first selected from the partition to which the instance belongs. This has better performance, but it can only guarantee local optimality; when there is no suitable node in the local partition, it will be selected from the partition to which the instance belongs. Nodes are selected in the partitions of other instances, but this may cause a conflict, that is, multiple scheduler instances select the same node at the same time. The more scheduler instances, the greater the chance of a conflict. Therefore, the number of instances should be set appropriately. More is not always better.
In addition, in order to support both online and offline tasks, Gödel Scheduler adopts two-level scheduling semantics , that is, it supports two-level scheduling of Scheduling Unit and Pod's Running Unit representing business deployments such as Pod Group or ReplicaSet. The specific usage will be introduced later.
Binder is mainly responsible for optimistic conflict checking, performing specific preemption operations, preparing tasks before binding, such as dynamically creating storage volumes, and finally performing binding operations. In general, it is similar to the Kubernetes Binder workflow, but in Gödel, Binder has to deal with more conflicts caused by multiple Scheduler instances. Once a conflict is discovered, call it back immediately and reschedule. For preemption operations, Binder checks to see if there are multiple Schduler instances trying to preempt the same instance (ie Victim Pod). If such a problem exists, Binder only handles the first preemption and rejects preemption requests issued by the remaining Schduler instances. For Gang/Co-scheduling, the Binder must handle conflicts (if any) for all Pods in the Pod Group. Either all Pod conflicts are resolved and each Pod is bound separately; or scheduling of the entire Pod Group is rejected.
CNR stands for Custom Node Resource, which is a CRD created by ByteDance to supplement node real-time information. Although it is not part of Gödel Scheduler itself, it can enhance Gödel's scheduling semantics. This CRD not only defines the resource amount and status of a node, but also defines the micro-topology of the resources, such as the CPU/Memory consumption and resource remaining amount on each socket on the dual-socket node. This allows the scheduler to select appropriate nodes based on the node status described by CNR when scheduling tasks with microtopology affinity requirements.
Compared with native Kubernetes that only uses topology-manager, using CNR can avoid the scheduling failure that kubelet encounters when pods are scheduled to nodes that do not meet topology restrictions. If a Pod is successfully created on the node, the CNR will be updated by the node agent belonging to Katalyst .
Related reading: " Katalyst: Bytedance Cloud Native Cost Optimization Practice "
two-tier scheduling
When Bytedance was designing Gödel, one of its main goals was to meet the scheduling needs of both online and offline services. To achieve this goal, Gödel introduces two levels of scheduling semantics, namely Scheduling Unit and Running Unit.
The former corresponds to a deployed job and consists of one or more Running Units. For example, when a user deploys a job through Kubernetes Deployment, the job is mapped to a Scheduling Unit, and each Pod running the task corresponds to a Running Unit. Unlike native Kubernetes' direct Pod-oriented scheduling, Gödel's two-level scheduling framework will always use the overall status of the Scheduling Unit as the admission principle. When a Scheduling Unit is considered schedulable, the Running Units (ie Pods) it contains will be scheduled in sequence.
The rule for judging whether a Scheduling Unit is schedulable is that there are >= Min_Member Running Units that meet the scheduling conditions, that is, when the scheduler can find nodes that meet resource requirements for enough Pods in a job, the job is considered to be schedulable. . At this time, each Pod will be scheduled to the designated node by the scheduler in turn. Otherwise, all Pods will not be scheduled and the entire job deployment will be rejected.
It can be seen that Min_Member of Scheduling Unit is a very important parameter. Setting different Min_Member can meet the needs of different scenarios. The value range of Min_Member is [1, Number of Running Units].
For example, when oriented to microservice business, Min_Member is set to 1. As long as the resource request of one Running Unit/Pod in each Scheduling Unit can be satisfied, scheduling can be performed. At this point, the Gödel scheduler runs basically the same as the native Kubernetes scheduler.
When facing offline services such as Batch and offline training that require Gang semantics, the value of Min_Member is equal to the number of Running Units/Pods (some services can also be adjusted to a value between 1 and Number of Running Units according to actual needs) , that is, scheduling starts only when all Pods can meet resource requests. The value of Min_Member is automatically set based on the business type and parameters in the business deployment template.
Performance optimization
Because of ByteDance’s own business needs, it has high requirements for scheduling throughput. One of Gödel's design goals is to provide high throughput. To this end, the Gödel scheduler places the most time-consuming part of the filtering node in a multi-instance Scheduler that can run concurrently. On the one hand, because multiple instances will encounter conflicts, the number of Schduler instances is not always better; on the other hand, the performance improvement brought by multiple instances alone is not enough to cope with the evening peak of 1000-2000 pods/s in a single cluster. Throughput requirements. In order to further improve scheduling efficiency, Gödel has made further optimizations in the following aspects.
- Cache candidate nodes
In the process of filtering nodes, Filter and Prioritize are the two most time-consuming parts. The former filters available nodes based on resource requests, and the latter scores candidate nodes to find the most suitable node. If the running speed of these two parts can be increased, the entire scheduling cycle will be greatly compressed.
The ByteDance development team observed that although computing resources are used by different applications from different business units, all or most Pods of an application from a certain business user usually have the same resource requirements.
Example: A social APP applies to create 20,000 HTTP servers. Each server requires 4 CPU cores and 8GB of memory. A Big Data team needs to run a data analysis program with 10,000 subtasks, each requiring 1 CPU core and 4GB of memory.
Most Pods in these mass-created tasks have the same resource application, same network segment, device affinity and other requirements. Then the candidate nodes selected by the Filter Plugin meet the needs of the first Pod and are likely to meet the needs of other Pods for this task.
Therefore, the Gödel scheduler caches candidate nodes after scheduling the first Pod, and preferentially searches for available nodes from the cache in the next round of scheduling. Unless the cluster status changes (nodes are added or deleted) or Pods with different resource requirements are encountered, there is no need to rescan the nodes in the cluster every round. Nodes that have no resources to allocate during the scheduling process will be removed from the cache and the sorting will be adjusted based on the cluster status. This optimization can significantly optimize the node screening process. When scheduling a group of Pods for the same business user, ideally it can reduce the time complexity from O(n) to O(1) .
- Reduce the proportion of scanned nodes
Although the above optimization can reduce the construction process of candidate nodes, if the cluster status or resource application changes, all nodes in the cluster still need to be rescanned.
In order to further reduce time overhead, Gödel adjusted the scanning ratio of the candidate list and used the local optimal solution as an approximate replacement for the global optimal solution. Because it is necessary to find enough candidate nodes for all Running Units/Pods during the scheduling process, Gödel will scan at least # of Running Units nodes. Based on the analysis of historical data, Gödel scans # of Running Units + 50 nodes by default to find candidates. node. If no suitable one is found, the same number will be scanned again. This method, combined with candidate node caching, will greatly reduce the scheduler's time overhead in finding suitable nodes for Pods.
- Optimize data structures and algorithms
In addition to the above two optimizations, the Gödel scheduler also continuously optimizes data structures and algorithms:
In order to maintain the candidate node list at low cost and avoid the overhead caused by frequent reconstruction of the node list. Gödel reconstructed the NodeList maintenance mechanism of the native Kubernetes scheduler , solved the performance problems of ultra-large-scale production clusters by discretizing the node list, and achieved better node discretization effects with lower overhead;
In order to improve overall resource utilization, ByteDance mixes and deploys high-quality online tasks and low-quality offline tasks. Due to the tidal characteristics of business, a large number of online businesses return during the evening peak, which often requires high-frequency preemption of low-quality offline businesses. The preemption process involves a large amount of search calculations, and frequent preemption seriously affects the overall work efficiency of the scheduler. In order to solve this problem, the Gödel scheduler introduces a multi-dimensional pruning strategy based on Pods and Nodes , which enables the preemption throughput to quickly recover and the preemption delay to be significantly reduced.
Experimental results
The paper evaluates the performance of the Gödel scheduler in terms of scheduling throughput, cluster size, etc.
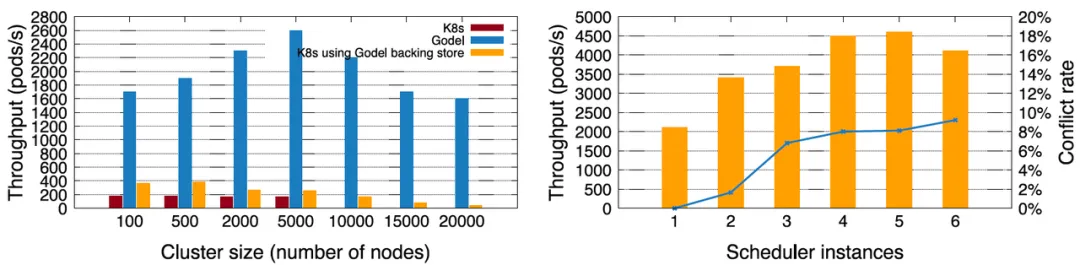
First, for the microservice business, ByteDance compared Gödel (single instance) with the Kubernetes native scheduler. In terms of cluster scale, native Kubernetes can only support a maximum cluster of 5,000 nodes by default, and the maximum scheduling throughput is less than 200 Pods/s. After using KubeBrain , a high-performance key-value store open source by Byte , native Kubernetes can support larger clusters and the scheduling throughput is also significantly improved. But the performance of the combination of Kubernetes + KubeBrain is still much smaller than Gödel. Gödel can achieve a performance of 2,600 Pods/s on a 5,000-node cluster. Even at 20,000 nodes, there are still about 2,000 Pods/s, which is more than 10 times the performance of the native Kubernetes scheduler .
In order to achieve higher scheduling throughput, Gödel can enable multiple instances. The figure on the right below depicts 1-6 scheduler instances being opened in sequence in a cluster of 10,000 nodes. The throughput gradually increases in the initial stage, and the peak value can reach approximately 4,600 Pods/s. But when the number of instances exceeds 5, the performance decreases. The reason is that the more instances, the more conflicts between instances, which affects the scheduling efficiency. Therefore, it is not that the more scheduling instances the better.
For offline tasks with Gang semantic requirements, the paper compares Gödel with YARN and K8s-volcano commonly used in the open source community. It can be clearly seen that the performance of Gödel is not only much higher than K8s-volcano, but also nearly twice that of YARN. Gödel supports simultaneous scheduling of online and offline tasks. The paper simulates the scenario when different businesses are mixed by changing the proportion of offline tasks submitted in the system. It can be seen that regardless of the proportion of offline services, Gödel's performance is relatively stable, with throughput maintained at around 2,000 Pods/s .
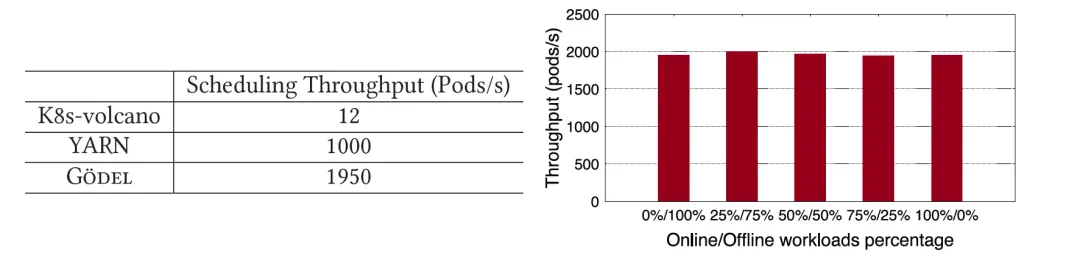
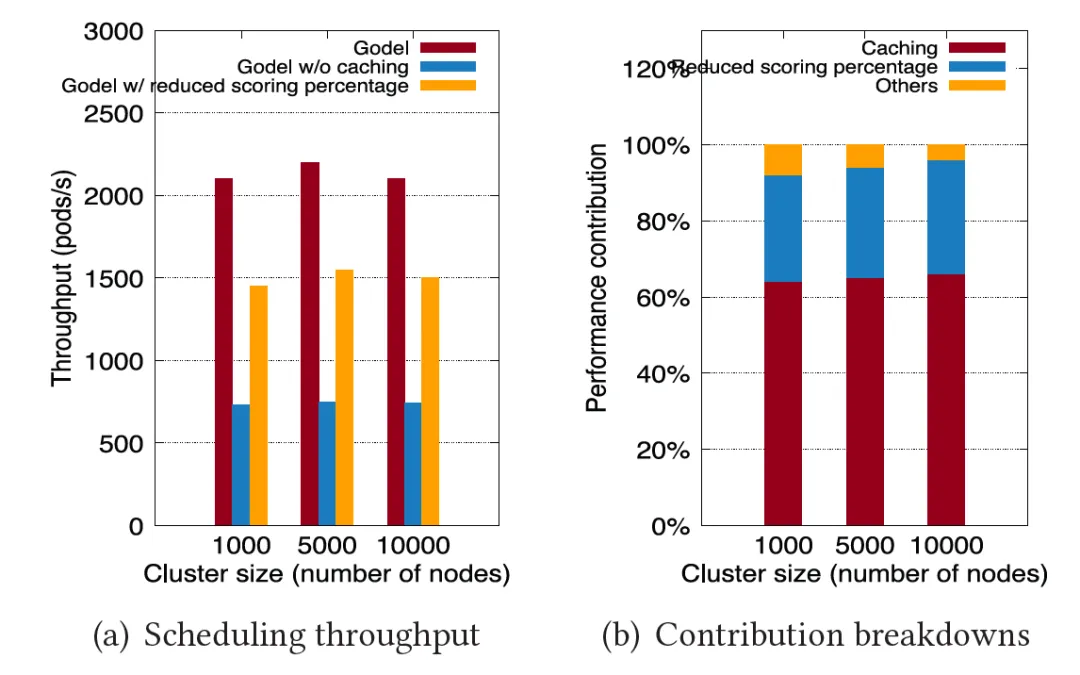
In order to demonstrate why Gödel has such a large performance improvement, the paper focuses on analyzing the contributions of two major optimizations: " caching candidate nodes " and " reducing the scan ratio ". As shown in the figure below, the previous experiment was repeated using the full version of Gödel, Gödel with only node cache optimization turned on, and Gödel with only reduced scan ratio turned on. The experimental results proved that these two main optimization items contributed about 60% and 60% respectively. 30% performance improvement.
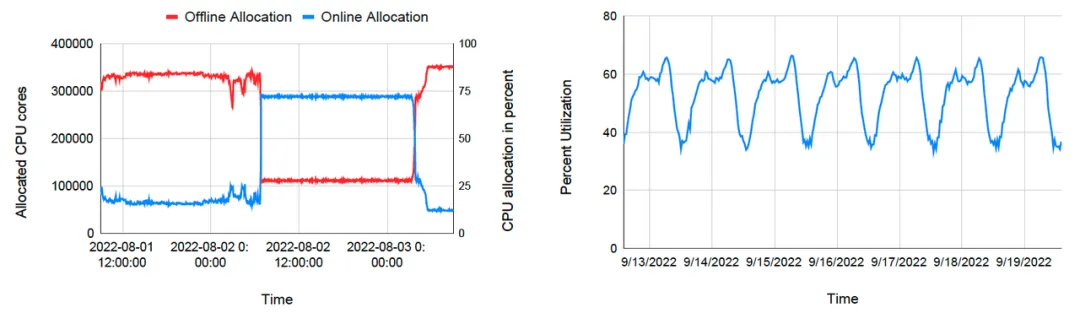
In addition to using benchmarks to evaluate Gödel's extreme performance, the paper also shows ByteDance's actual experience using the Gödel scheduler in a production environment, showing that Gödel has good capabilities in resource pooling, elasticity, and circulation.
The left figure below describes the resource allocation of online tasks and offline tasks in a certain cluster within a certain period of time. In the beginning, online tasks consume few resources, and a large amount of computing resources are allocated to offline tasks with lower priority. When online tasks have a surge in resource demand due to a special event (emergency, hot search, etc.), Gödel immediately allocates resources to online tasks, and the amount of resource allocation for offline tasks decreases rapidly. When the peak passes, online tasks begin to reduce resource requests, and the scheduler again shifts resources to offline tasks. Through offline pooling and dynamic resource transfer, ByteDance can always maintain high resource utilization. During the evening peak hours, the average resource rate of the cluster reaches more than 60% , and it can also be maintained at around 40% during the daytime trough stage.
Summary and future prospects
The paper introduces Gödel, a scheduling system designed and developed by the ByteDance orchestration and scheduling team to unify offline resource pools. The scheduling system supports simultaneous scheduling of online and offline tasks in ultra-large-scale clusters, supports resource pooling, elasticity and circulation, and has high scheduling throughput. Since Gödel was launched in batches in ByteDance's own data center in 2022, it has met the co-location needs of most infield businesses, achieving an average resource utilization of more than 60% during the evening peak and a scheduling throughput of approximately 5,000 Pods/s .
In the future, the orchestration and scheduling team will continue to promote the expansion and optimization of the Gödel scheduler, further enrich scheduling semantics, improve system responsiveness, and reduce the probability of conflicts in multi-instance situations. While optimizing the initial scheduling, they will also build and strengthen system re-routing. Scheduling capabilities, design and development Gödel Rescheduler. Through the collaborative work of Gödel Scheduler and Rescheduler, reasonable allocation of cluster resources throughout the entire cycle is achieved.
Gödel scheduler is currently open source . We sincerely welcome community developers and enterprises to join the community and participate in project co-construction with us. The project address is: github.com/kubewharf/godel-scheduler !

Scan the QR code to join the ByteDance open source community
Linus took it upon himself to prevent kernel developers from replacing tabs with spaces. His father is one of the few leaders who can write code, his second son is the director of the open source technology department, and his youngest son is an open source core contributor. Robin Li: Natural language will become a new universal programming language. The open source model will fall further and further behind Huawei: It will take 1 year to fully migrate 5,000 commonly used mobile applications to Hongmeng. Java is the language most prone to third-party vulnerabilities. Rich text editor Quill 2.0 has been released with features, reliability and developers. The experience has been greatly improved. Ma Huateng and Zhou Hongyi shook hands to "eliminate grudges." Meta Llama 3 is officially released. Although the open source of Laoxiangji is not the code, the reasons behind it are very heart-warming. Google announced a large-scale restructuring