
Author: Bruce
background
The case shared today comes from the best practices in the application of MSE-ZooKeeper by the Dewu technical team. The original Dewu ZooKeeper SLA can also be 99.99% | Dewu Technology .
ZooKeeper (ZK) is a distributed application coordination service born in 2007. Although for some special historical reasons, many business scenarios still have to rely on it. For example, Kafka, task scheduling, etc. Especially when Flink mixed deployment and ETCD decoupling, the business side required absolute stability and strongly recommended not to use self-built ZooKeeper. For stability considerations, Alibaba's MSE-ZK is used. Since its use in September 2022, the Dewu technical team has not encountered any stability problems, and the SLA reliability has indeed reached 99.99%.
In 2023, some businesses used self-built ZooKeeper (ZK) clusters, and then ZK experienced several fluctuations during use. Then Dewu SRE began to take over some self-built clusters and made several rounds of stability reinforcement attempts. During the takeover process, it was discovered that after ZooKeeper has been running for a period of time, the memory usage will continue to increase, which can easily lead to out-of-memory (OOM) problems. The Dewu technical team was very curious about this phenomenon and therefore participated in the exploration process to solve this problem.
Explore and analyze
determine direction
When troubleshooting the problem, I was very lucky to find a fault site in a test environment. Two nodes in the cluster happened to be in an edge state of OOM.

With the fault scene, usually only 50% is left before the successful end point. The memory is on the high side. According to past experience, it is either non-heap or there is a problem in the heap. It can be confirmed from the flame graph and jstat that it is a problem in the heap.

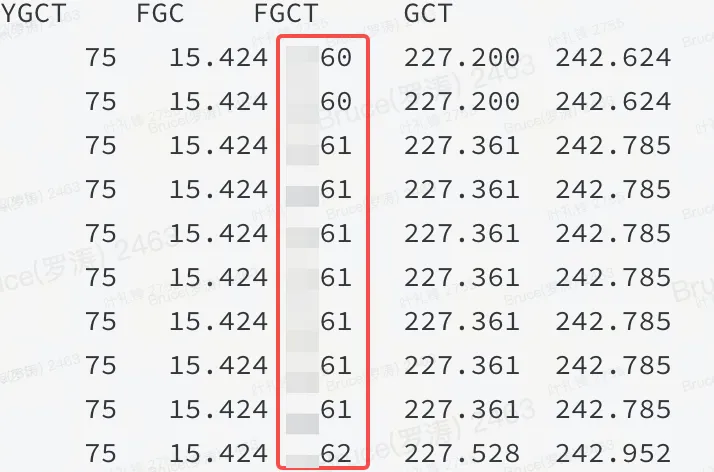
As shown in the figure: It means that a certain resource in the JVM heap occupies a large amount of memory, and FGC cannot release it.
Memory analysis
In order to explore the distribution of memory usage in the JVM heap, the Dewu technical team immediately made a JVM heap dump. Analysis found that JVM memory is heavily occupied by childWatches and dataWatches.
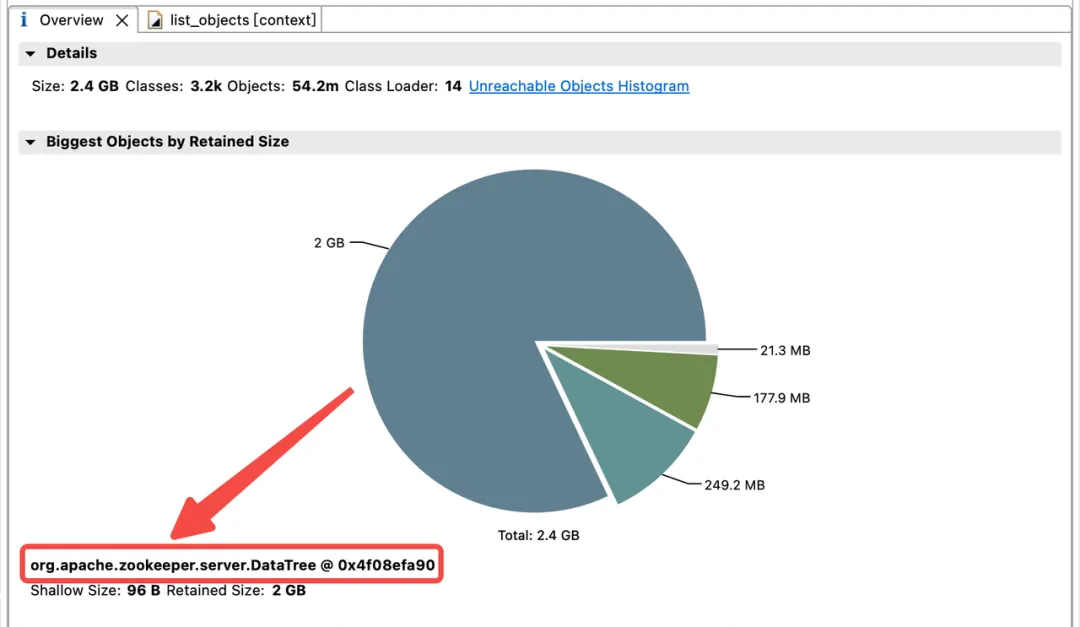
dataWatches: Track changes in znode node data.
childWatches: Track changes in the znode node structure (tree).
childWatches and dataWatches originate from WatcherManager.
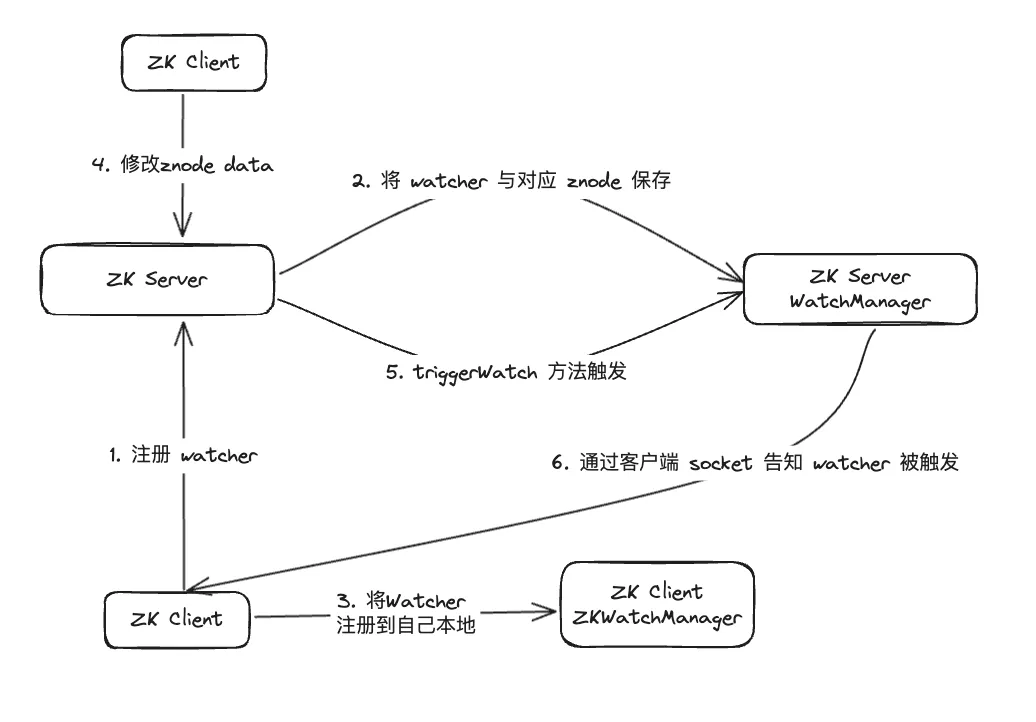
After data investigation, it was found that WatcherManager is mainly responsible for managing Watchers. The ZooKeeper (ZK) client first registers Watchers to the ZooKeeper server, and then the ZooKeeper server uses WatcherManager to manage all Watchers. When the data of a Znode changes, WatchManager will trigger the corresponding Watcher and communicate with the socket of the ZooKeeper client subscribed to the Znode. Subsequently, the client's Watch manager will trigger the relevant Watcher callback to execute the corresponding processing logic, thereby completing the entire data publishing/subscribing process.
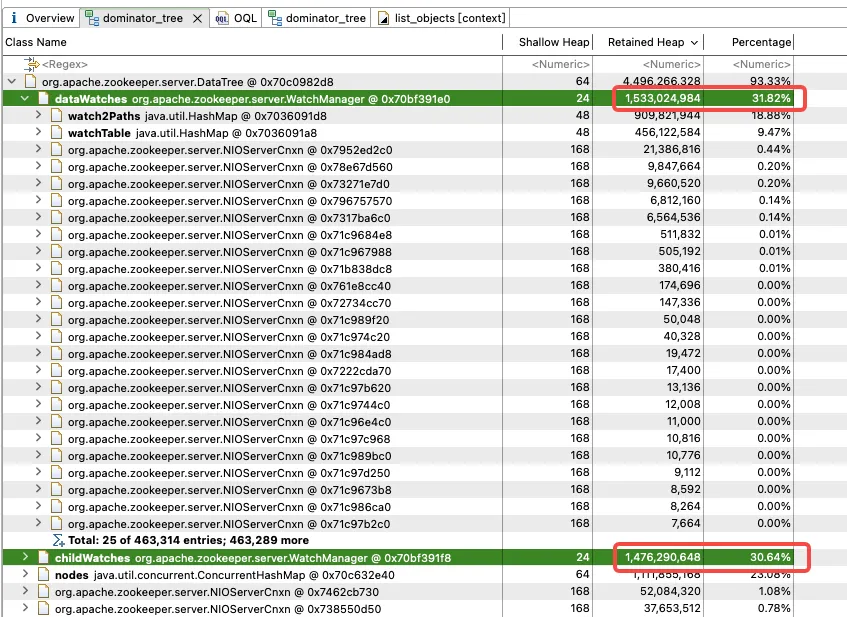
Further analysis of WatchManager shows that the memory ratio of member variables Watch2Path and WatchTables is as high as (18.88+9.47)/31.82 = 90%.
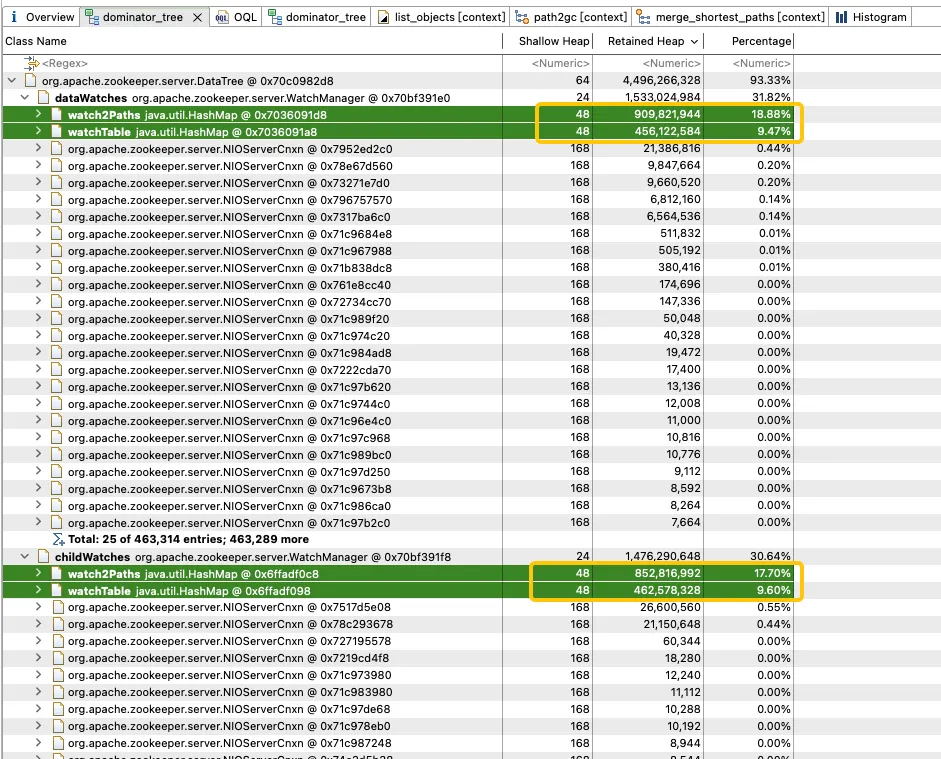
WatchTables and Watch2Path store the exact mapping relationship between ZNode and Watcher, as shown in the storage structure diagram:
WatchTables [forward lookup table]
HashMap<ZNode, HashSet<Watcher>>
Scenario: When a ZNode changes, the Watcher subscribed to the ZNode will receive a notification.
Logic: Use this ZNode to find all corresponding Watcher lists through WatchTables, and then send notifications one by one.
Watch2Paths [reverse lookup table]
HashMap<Watcher, HashSet>
Scenario: Count which ZNodes a certain Watcher has subscribed to.
Logic: Use this Watcher to find all corresponding ZNode lists through Watch2Paths.
Watcher is essentially NIOServerCnxn, which can be understood as a connection session.
If there are a large number of ZNodes and Watchers, and the client subscribes to a large number of ZNodes, it can even be fully subscribed. The relationship recorded in these two Hash tables will grow exponentially, and will eventually reach a sky-high volume!
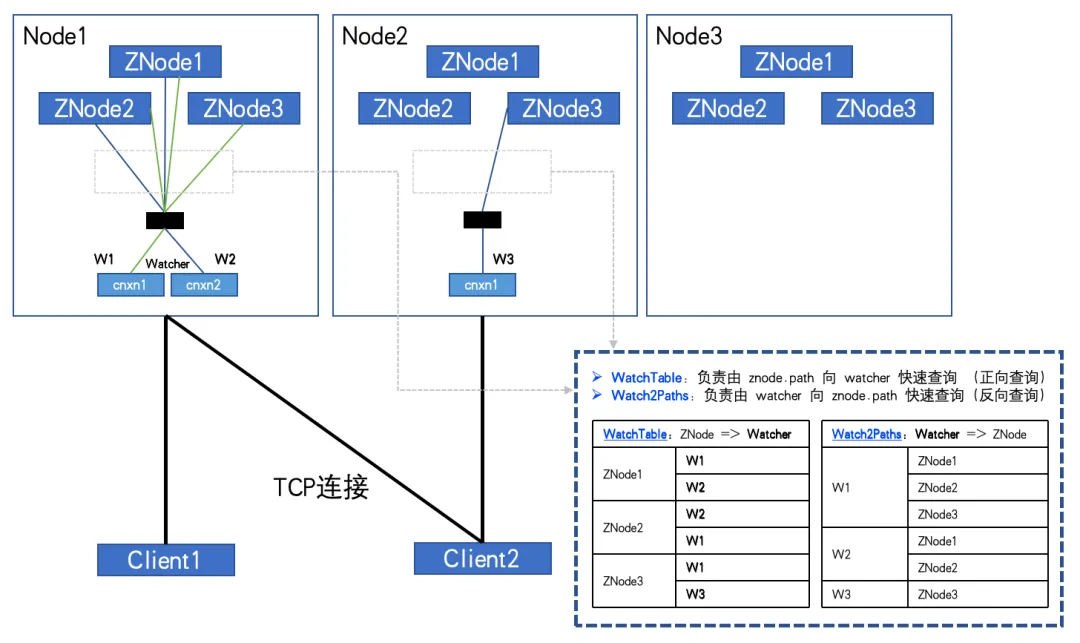
When fully subscribed, as shown in the figure:
When the number of ZNodes: 3, the number of Watchers: 2, WatchTables and Watch2Paths will each have 6 relationships.
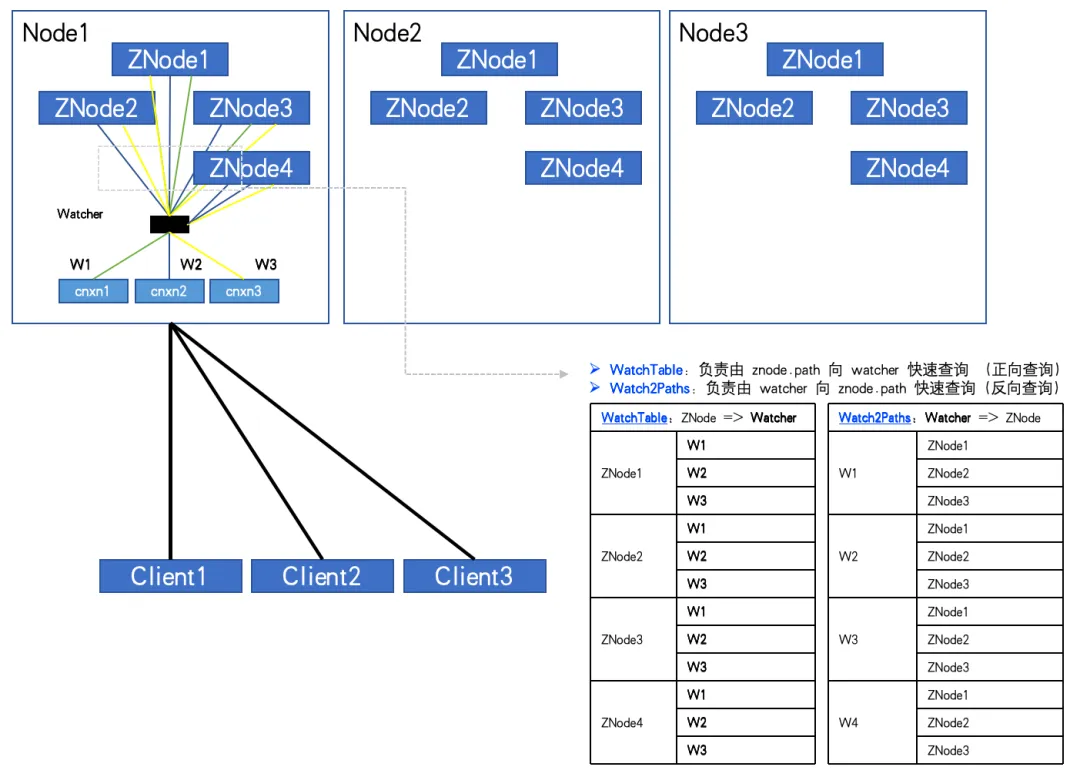
When the number of ZNodes: 4, the number of Watchers: 3, WatchTables and Watch2Paths will each have 12 relationships.
An abnormal ZK-Node was discovered through monitoring. The number of ZNodes is about 20W, and the number of Watchers is 5,000. The number of relationships between Watcher and ZNode has reached 100 million.
If one HashMap&Node (32Byte) is needed to store each relationship, since there are two relationship tables, double it. Then don't calculate anything else. This "shell" alone requires 2 10000^2 32/1024^3 = 5.9GB of invalid memory overhead.
unexpected discovery
From the above analysis, we can know that it is necessary to avoid the client from fully subscribing to all ZNodes. However, the reality is that many business codes do have such logic to traverse all ZNodes starting from the root node of the ZTree and fully subscribe to them.
It may be possible to persuade some business parties to make improvements, but it cannot be forced to restrict the use of all business parties. Therefore, the solution to this problem lies in monitoring and prevention. However, unfortunately, ZK itself does not support such a function, which requires modification of the ZK source code.
Through tracking and analysis of the source code, it was found that the root of the problem pointed to WatchManager, and the logical details of this class were carefully studied. After an in-depth understanding, I found that the quality of this code seemed to be written by a recent graduate, and there were a lot of inappropriate use of threads and locks. By looking at the Git records, we found that this issue dates back to 2007. However, what is exciting is that during this period of time, WatchManagerOptimized (2018) appeared. By searching the ZK community’s information, [ZOOKEEPER-1177] was discovered. That is, in 2011, the ZK community had realized that a large number of Watches caused memory footprint issue and finally provided a solution in 2018. It is precisely because of this WatchManagerOptimized that it seems that the ZK community has already optimized it.
Interestingly, ZK does not enable this class by default, even in the latest 3.9.X version, WatchManager is still used by default. Perhaps because ZK is so old, people gradually pay less attention to it. By asking colleagues at Alibaba, it was confirmed that MSE-ZK also enabled WatchManagerOptimized, which further confirmed that the focus of the Dewu technical team was in the right direction.
Optimize exploration
Lock optimization
In the default version, the HashSet used is thread-unsafe. In this version, related operation methods such as addWatch, removeWatcher and triggerWatch are all implemented by adding synchronized heavy locks to the methods. In the optimized version, a combination of ConcurrentHashMap and ReadWriteLock is used to use the lock mechanism in a more refined manner. In this way, more efficient operations can be achieved during the process of adding Watch and triggering Watch.
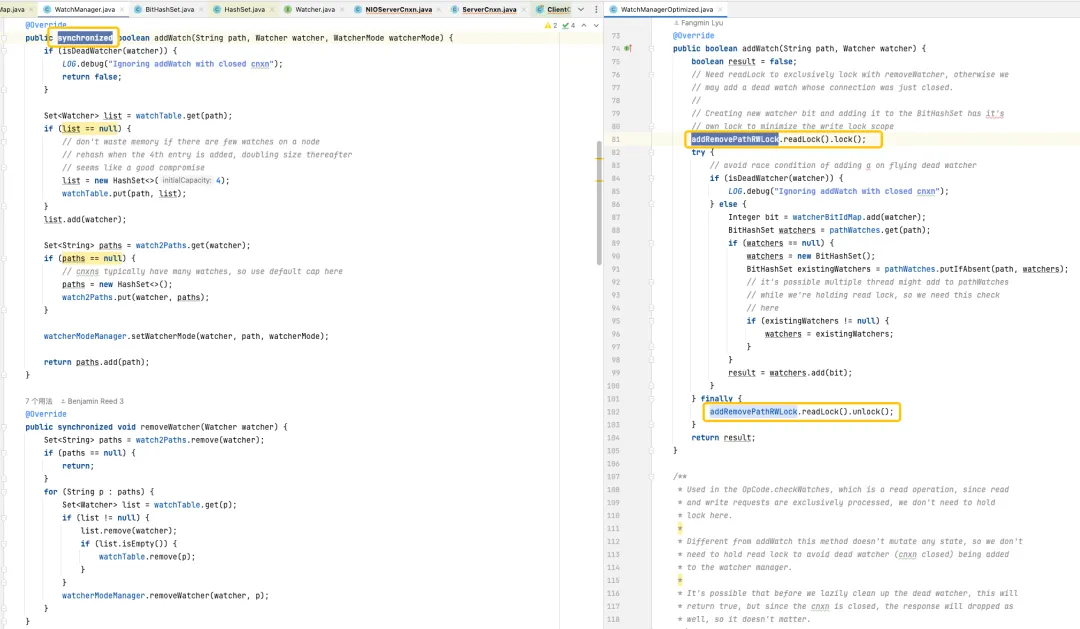
Storage optimization
This is the focus. From the analysis of WatchManager, we can see that the storage efficiency of using WatchTables and Watch2Paths is not high. If ZNode has many subscription relationships, a large amount of additional invalid memory will be consumed.
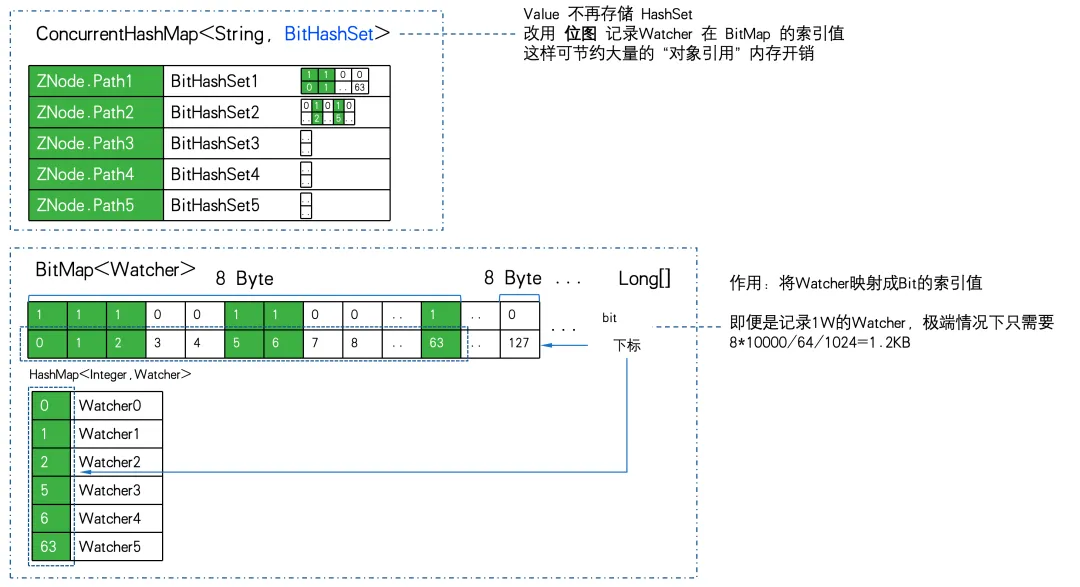
Surprisingly, WatchManagerOptimized uses "black technology" -> bitmap here.
The relational storage is heavily compressed using bitmaps to achieve dimensionality reduction optimization.
Main features of Java BitSet:
- Space efficient: BitSet uses bit arrays to store data, requiring less space than standard Boolean arrays.
- Processing is fast: Bit operations such as AND, OR, XOR, flipping are often faster than the corresponding Boolean logic operations.
- Dynamic expansion: The size of a BitSet can dynamically grow as needed to accommodate more bits.
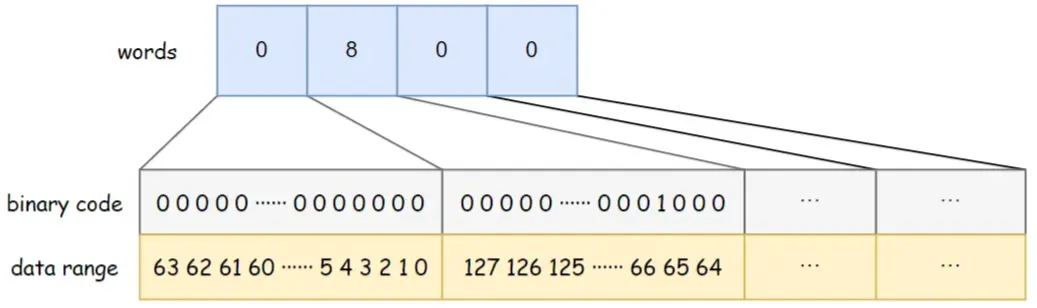
BitSet uses a long[] words to store data. The long type occupies 8 bytes and is 64 bits . Each element in the array can store 64 pieces of data. The storage order of data in the array is from left to right, from low to high.
For example, the word capacity of the BitSet in the figure below is 4. Words[0] from low to high indicates whether data 0 ~ 63 exists, words[1] from low to high indicates whether data 64 ~ 127 exists, and so on. Among them, words[1] = 8, and the corresponding binary bit 8 is 1, indicating that there is a data {67} stored in the BitSet at this time.
WatchManagerOptimized uses BitMap to store all Watchers. In this way, even if there is a 1W Watcher. The memory consumption of bitmap is only 8Byte 1W/64/1024= 1.2KB . If replaced by HashSet, at least 32Byte 10000/1024=305KB is required, and the storage efficiency is nearly 300 times different.
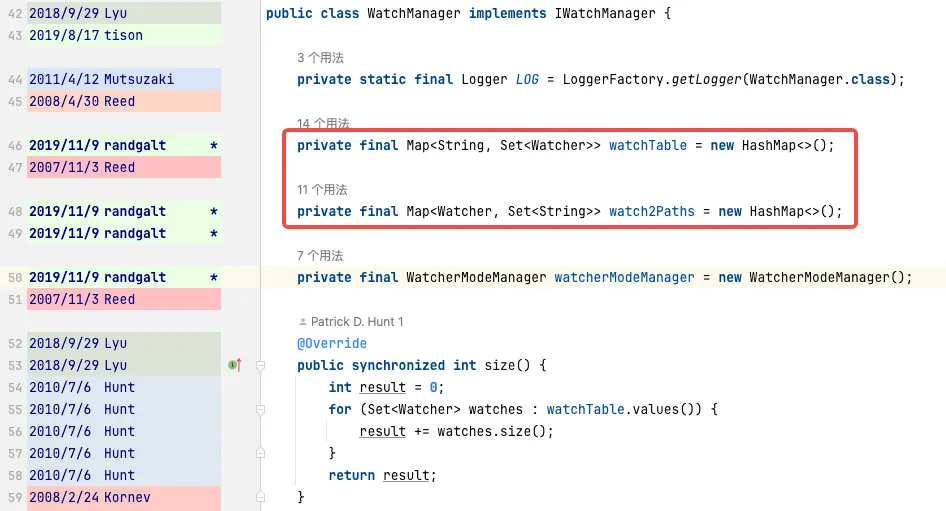
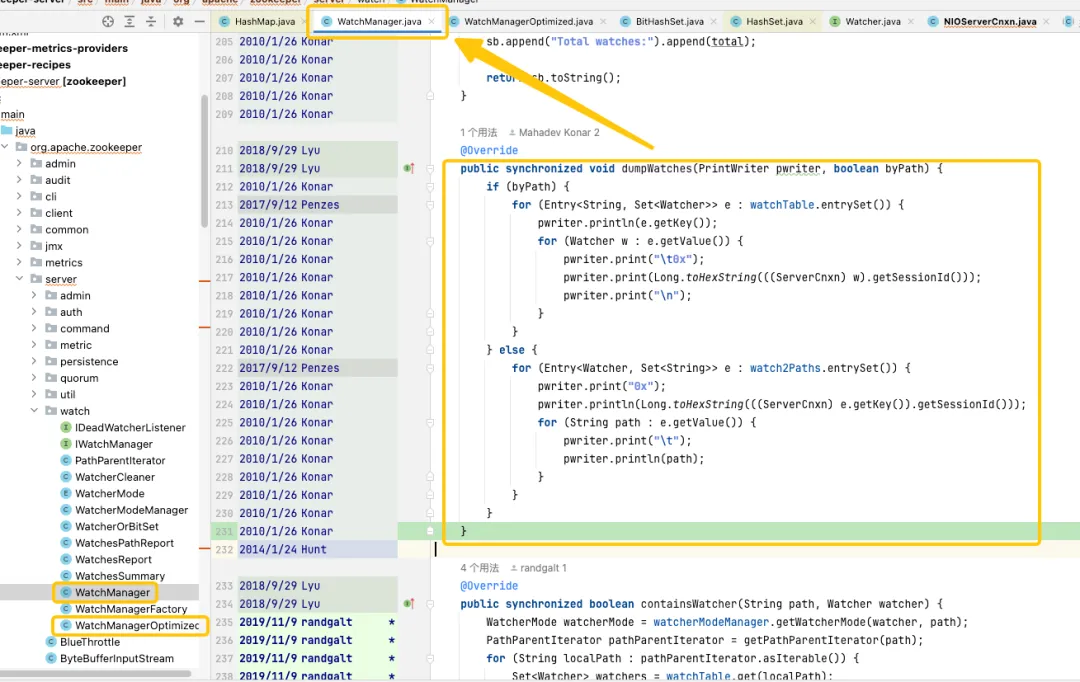
WatchManager.java:
private final Map<String, Set<Watcher>> watchTable = new HashMap<>();
private final Map<Watcher, Set<String>> watch2Paths = new HashMap<>();
WatchManagerOptimized.java:
private final ConcurrentHashMap<String, BitHashSet> pathWatches = new ConcurrentHashMap<String, BitHashSet>();
private final BitMap<Watcher> watcherBitIdMap = new BitMap<Watcher>();
The mapping storage from ZNode to Watcher is changed from Map<string, set> to ConcurrentHashMap<string, BitHashSet >. That is to say, the Set is no longer stored, but the bitmap is used to store the bitmap index value.
Use 1W ZNode, 1W Watcher, and go to the extreme point of full subscription (all Watchers subscribe to all ZNodes) to do storage efficiency PK:

You can see that 11.7MB PK 5.9GB , the memory storage efficiency difference is: 516 times .
Logic optimization
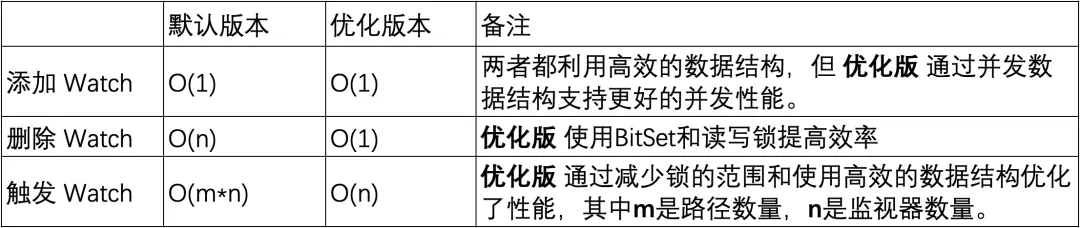
Adding a monitor: Both versions are able to complete operations in constant time, but the optimized version provides better concurrency performance by using ConcurrentHashMap .
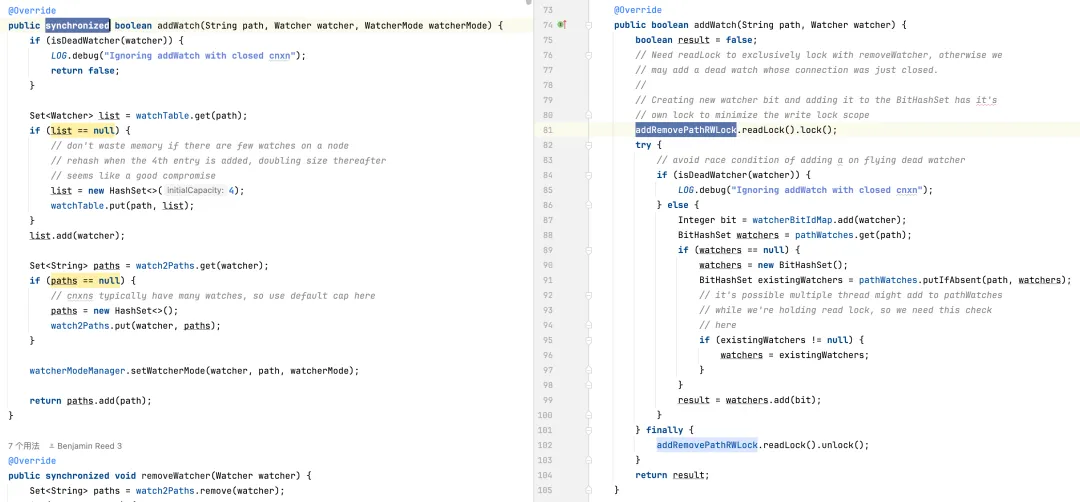
Deleting a monitor: The default version may need to traverse the entire monitor collection to find and delete the monitor, resulting in a time complexity of O(n). The optimized version uses BitSet and ConcurrentHashMap to quickly locate and delete monitors in O(1) in most cases.
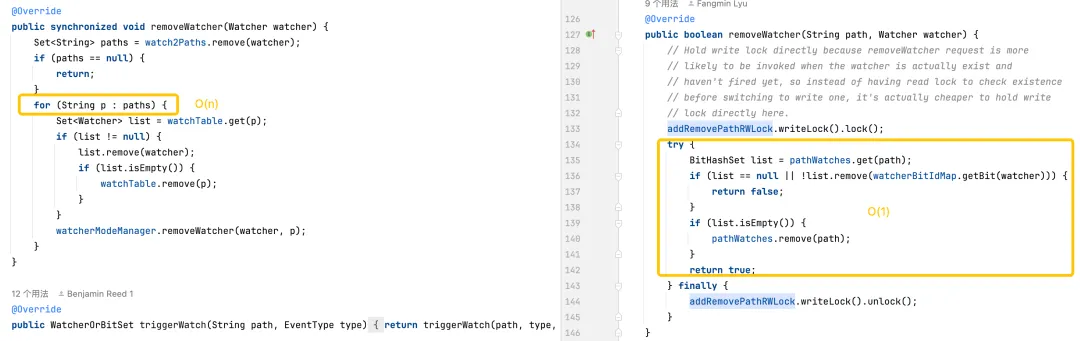
Triggering monitors: The default version is more complex because it requires operations on every monitor on every path. The optimized version optimizes the performance of trigger monitors through more efficient data structures and reduced lock usage.
Performance stress test
JMH microbenchmark
ZooKeeper 3.6.4 source code compilation, JMH micor stress test WatchBench.
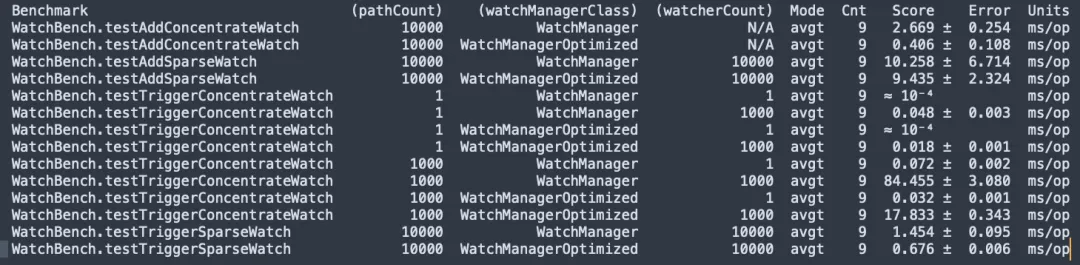
pathCount: Indicates the number of ZNode paths used in the test.
watchManagerClass: Represents the WatchManager implementation class used in the test.
watcherCount: Indicates the number of observers (Watchers) used in the test.
Mode: Indicates the test mode, here is avgt, which indicates the average running time.
Cnt: Indicates the number of test runs.
Score: Indicates the score of the test, that is, the average running time.
Error: Indicates the error range of the score.
Units: The unit representing the score, here is milliseconds/operation (ms/op).
- There are 1 million subscriptions between ZNode and Watcher. The default version uses 50MB, and the optimized version only requires 0.2MB, and it will not increase linearly.
- Adding Watch, the optimized version (0.406 ms/op) is 6.5 times faster than the default version (2.669 ms/op).
- A large number of Watches are triggered, and the optimized version (17.833 ms/op) is 5 times faster than the default version (84.455 ms/op).
Performance stress test
Next, a set of 3-node ZooKeeper 3.6.4 was built on a machine (32C 60G) and the optimized version and the default version were used for capacity stress test comparison.
Scenario 1: 20W znode short path
Znode short path: /demo/znode1

Scenario 2: 20W znode long path
Znode long path: /sentinel-cluster/dev/xx-admin-interfaces/lock/_c_bb0832d5-67a5-48ab-8fe0-040b9ddea-lock/12

- Watch memory usage is related to the Path length of ZNode.
- The number of Watches increases linearly in the default version and performs very well in the optimized version, which is a very obvious improvement for memory usage optimization.
Grayscale test
Based on the previous benchmark test and capacity test, the optimized version has obvious memory optimization in a large number of Watch scenarios. Next, we started to conduct grayscale upgrade test observations on the ZK cluster in the test environment.
The first ZooKeeper cluster & benefits
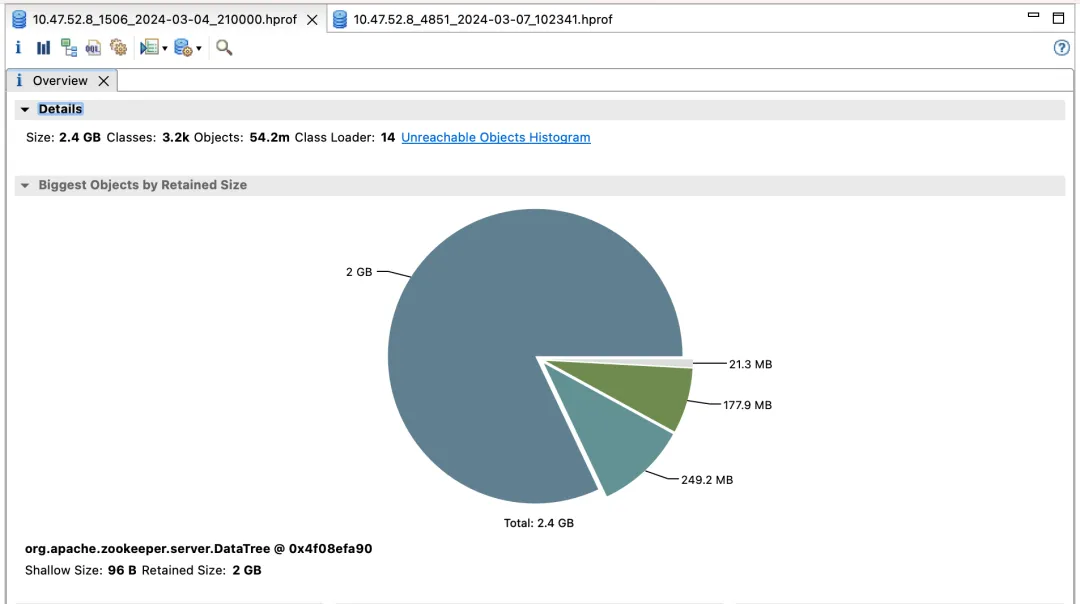
Default version
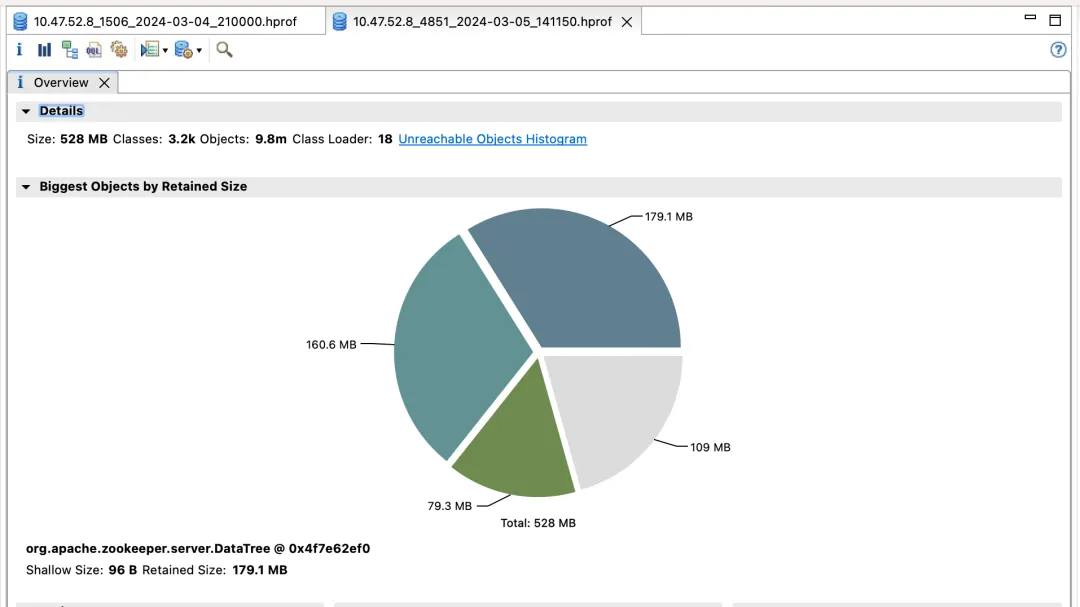
Optimized version


Effect income:
- election_time (election time): reduced by 60%
- fsync_time (transaction synchronization time): reduced by 75%
- Memory usage: reduced by 91%
Second ZooKeeper cluster & benefits
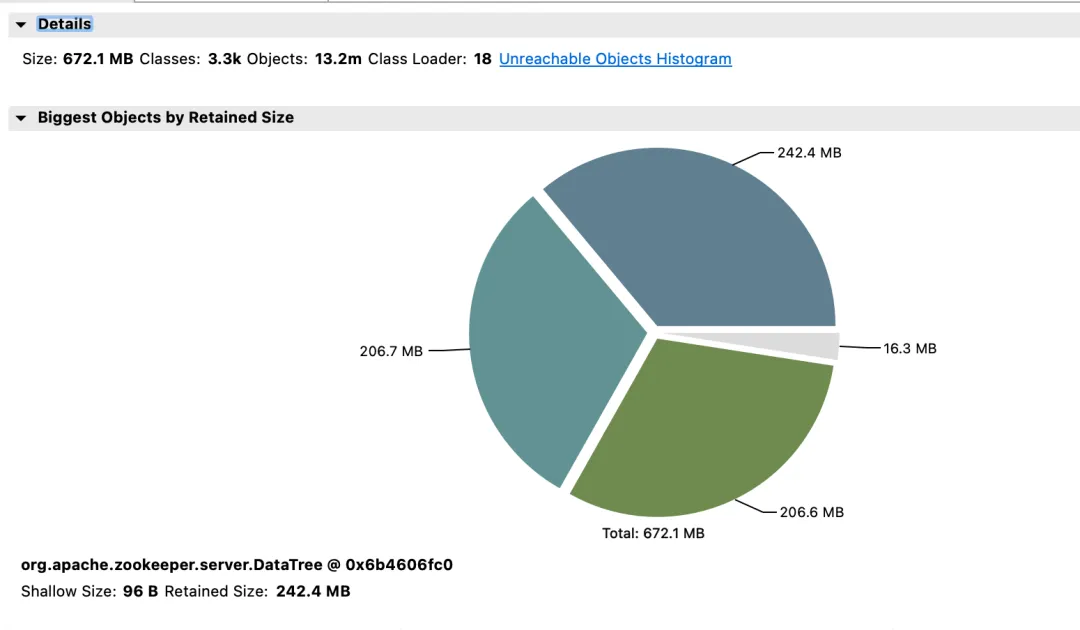



Effect income:
- Memory: Before the change, the JVM Attach response failed to respond and data collection failed.
- election_time (election time): reduced by 64%.
- max_latency (read latency): reduced by 53%.
- proposal_latency (election processing proposal delay): 1400000 ms --> 43 ms.
- propagation_latency (data propagation delay): 1400000 ms --> 43 ms.
The third set of ZooKeeper cluster & benefits
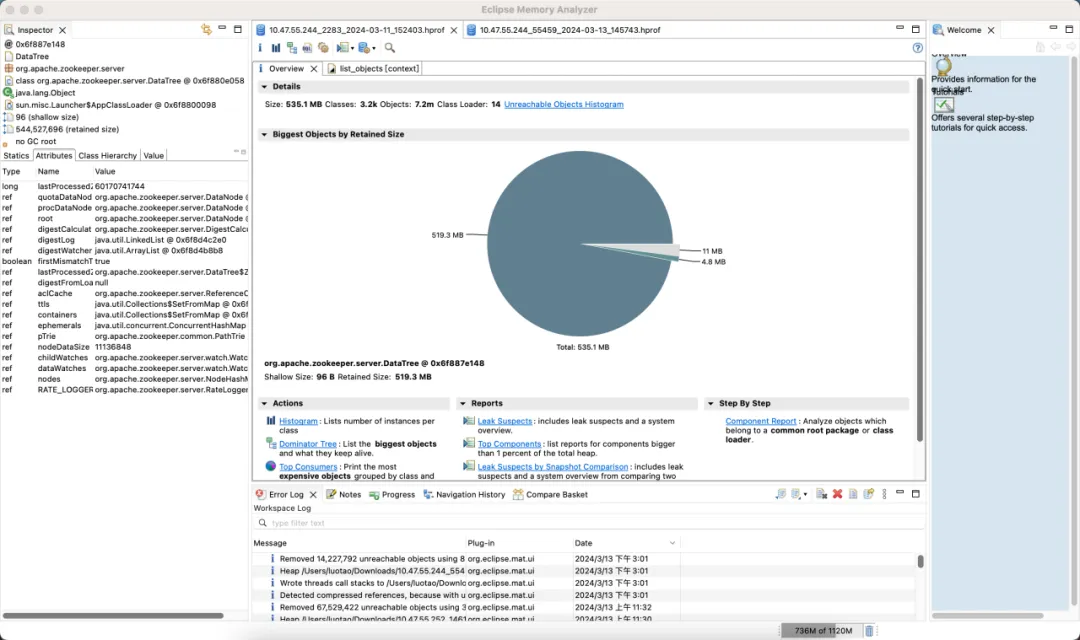
Default version
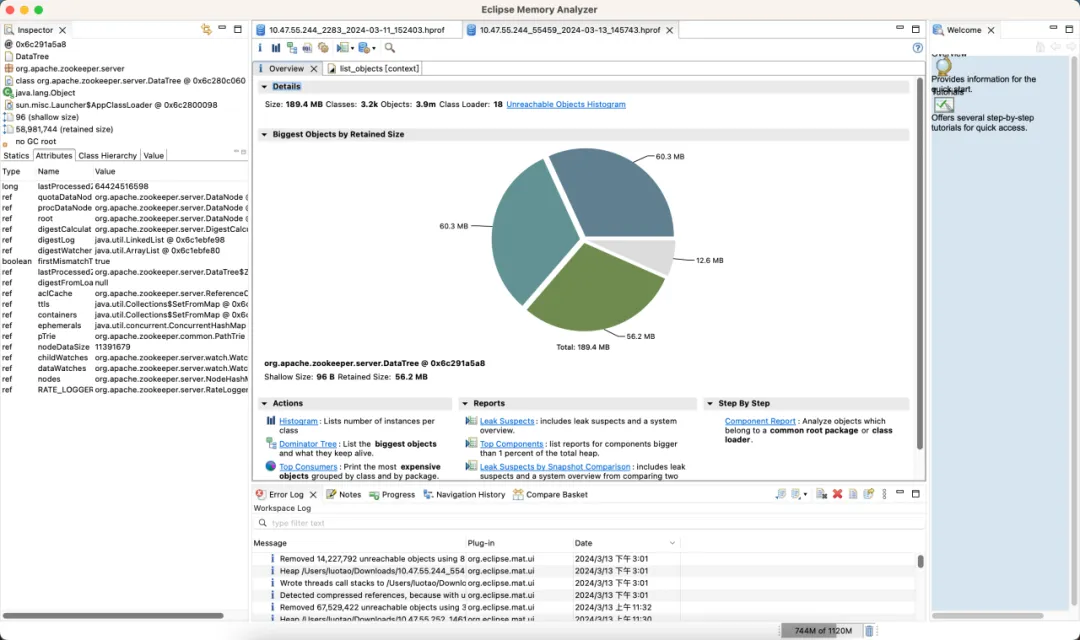
Optimized version
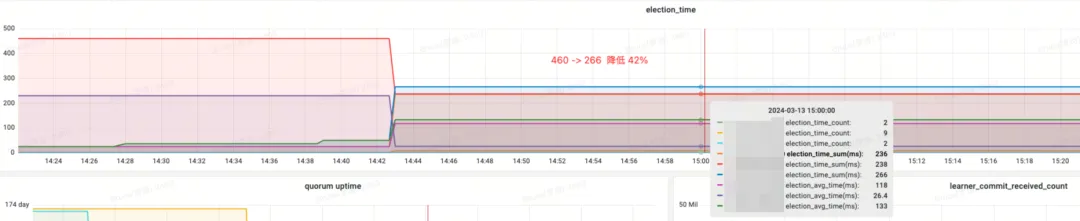

Effect income:
- Memory: Save 89%
- election_time (election time): reduced by 42%
- max_latency (read latency): reduced by 95%
- proposal_latency (election processing proposal delay): 679999 ms --> 0.3 ms
- propagation_latency (data propagation delay): 928000 ms--> 5 ms
Summarize
通过之前的基准测试、性能压测以及灰度测试,发现了 ZooKeeper 的 WatchManagerOptimized。这项优化不仅节省了内存,还通过锁的优化显著提高了节点之间的选举和数据同步等指标,从而增强了 ZooKeeper 的一致性。还与阿里 MSE 的同学进行了深度交流,各自在极端场景模拟压测,并达成了一致的看法:WatchManagerOptimized 对 ZooKeeper 的稳定性提升显著。总体而言,这项优化使得 ZooKeeper 的 SLA 提升了一个数量级。
ZooKeeper has many configuration options, but in most cases no tweaking is required. To improve system stability, it is recommended to perform the following configuration optimizations:
- Mount dataDir (data directory) and dataLogDir (transaction log directory) to different disks respectively, and use high-performance block storage.
- For ZooKeeper version 3.8, it is recommended to use JDK 17 and enable the ZGC garbage collector; for versions 3.5 and 3.6, it is recommended to use JDK 8 and enable the G1 garbage collector. For these versions, simply configure -Xms and -Xmx.
- 将 SnapshotCount 参数默认值 100,000 调整为 500,000,这样可以在高频率 ZNode 变动时显著降低磁盘压力。
- Use the optimized version of Watch Manager WatchManagerOptimized.
Ref:
https://issues.apache.org/jira/browse/ZOOKEEPER-1177
https://github.com/apache/zookeeper/pull/590
Linus took it upon himself to prevent kernel developers from replacing tabs with spaces. His father is one of the few leaders who can write code, his second son is the director of the open source technology department, and his youngest son is an open source core contributor. Robin Li: Natural language will become a new universal programming language. The open source model will fall further and further behind Huawei: It will take 1 year to fully migrate 5,000 commonly used mobile applications to Hongmeng. Java is the language most prone to third-party vulnerabilities. Rich text editor Quill 2.0 has been released with features, reliability and developers. The experience has been greatly improved. Ma Huateng and Zhou Hongyi shook hands to "eliminate grudges." Meta Llama 3 is officially released. Although the open source of Laoxiangji is not the code, the reasons behind it are very heart-warming. Google announced a large-scale restructuring