
Source|ByConity open source community
Hello fellow community friends, ByConity version 0.3.0 was officially released on December 18. This version provides many new features such as inverted index, master selection method based on shared storage, and has conducted cold reading performance tests. With further optimization, ELT capabilities have been further iterated, and several known issues have been fixed, further improving the performance and stability of the system. Everyone is welcome to download and experience it.
GitHub address: https://github.com/ByConity/ByConity Download experience: https://github.com/ByConity/ByConity/releases/tag/0.3.0
01 inverted index
|Background
During the use of ByConity, many businesses have put forward very high demands for text retrieval related capabilities (such as StringLike). It is hoped that the community can optimize related query performance and be compatible with the inverted index capability that ClickHouse will support this year. In order to meet business demands, maintain ecological compatibility, and improve ByConity's text retrieval capabilities, ByConity added support for text retrieval in version 0.3.0 to provide high-performance queries for log data analysis and other scenarios.
ByConity's planning of text retrieval is divided into two stages -
In the first phase, ByConity will enhance its functionality based on the ClickHouse community version;
In the second phase, ByConity plans to support more text retrieval capabilities, including phrase query/fuzzy query and other capabilities, making ByConity also a text analysis tool.
Currently in the 0.3.0 version released on December 18, the first phase goal has been completed. On the basis of supporting ClickHouse inverted indexing capabilities, ByConity additionally supports Chinese word segmentation and has performed IO-related optimizations.
|Implementation
The inverted index is a mapping from values to row numbers, so the engine can quickly locate qualified data based on the inverted index, avoiding the scanning overhead of large amounts of data, and reducing the calculation overhead of some filter conditions.
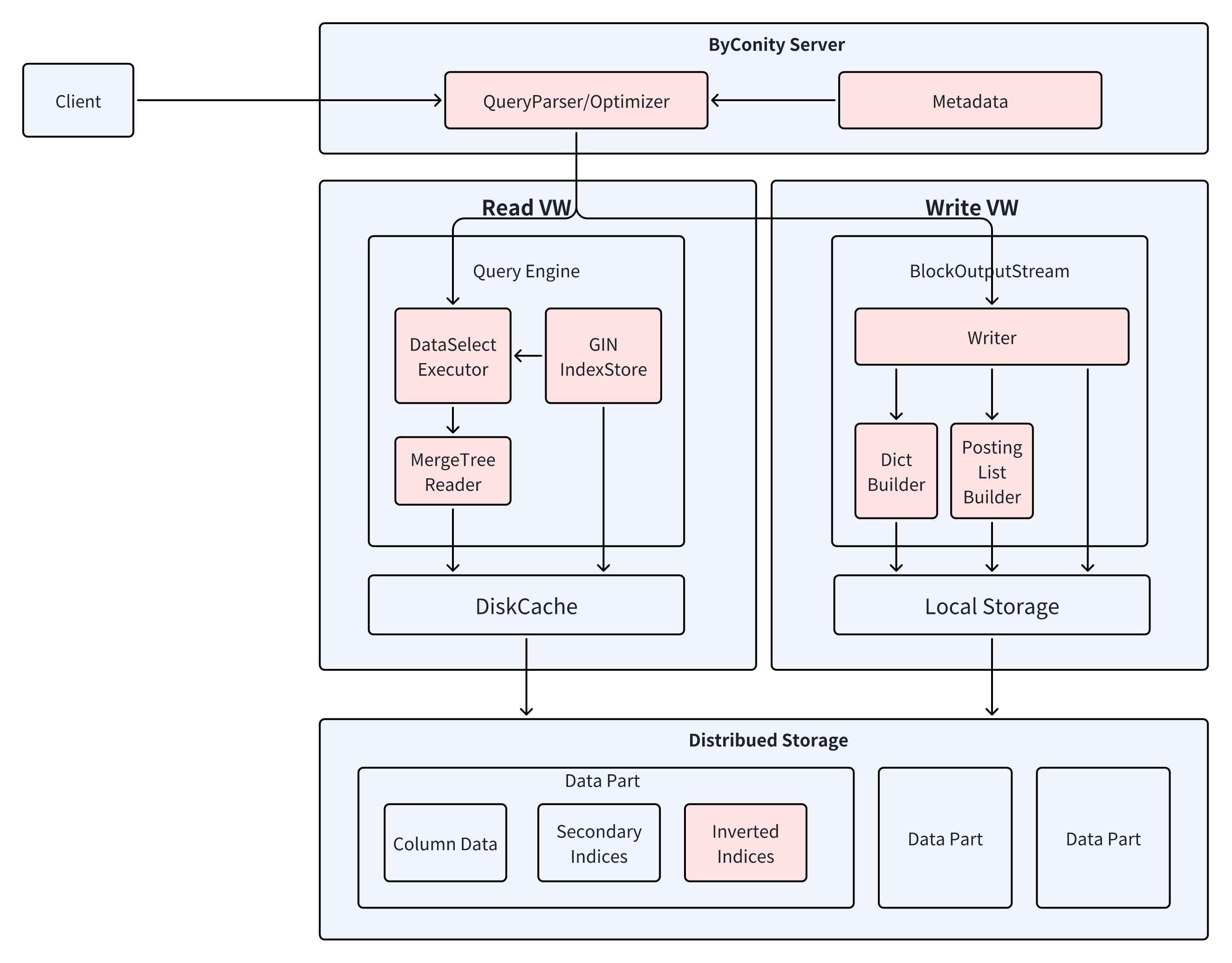
Adding support for inverted index to ByConity mainly includes modification of write/read links——
The modification of the write link mainly includes generating an inverted index based on the column data during writing, and writing it to the remote storage;
The modification of the read link mainly includes constructing an expression based on the filtering conditions during query to filter the query data range.
After adding the inverted index, the specific writing process and reading process of the engine are shown in the figure below.
|How to use
ByConity supports token word segmentation, Ngram word segmentation, and Chinese word segmentation. The following is an example of using Chinese word segmentation.
CREATE TABLE chinese_token_split
(
`key` UInt64,
`doc` String,
-- token_chinese_default 代表使用token_chinese_default分词器
-- default 代表使用default配置
INDEX inv_idx doc TYPE inverted('token_chinese_default', 'default',1.0) GRANULARITY 1
)
ENGINE = MergeTree
ORDER BY key
Using Chinese word segmentation requires additional configuration of dictionaries and models in the configuration file.
|Next step plan
The main goal of the next phase is to support more text retrieval capabilities and optimize performance. In terms of functionality, it will add support for phrase query, fuzzy matching, and text relevance judgment capabilities, and add support for the JSON type to the inverted index.
At the same time, some performance optimizations will also be carried out. For example, currently the inverted index is only used for Granule filtering. We still need to read the entire Granule and then filter it, but in fact we can directly obtain the row number of the data from the inverted index. , to directly read the corresponding row; and now during the Merge process, we still rebuild the inverted index, but in fact we can reuse the previous word segmentation results to improve the efficiency of Merge.
02 Master selection scheme based on shared storage
| Background
There are a variety of control nodes in the ByConity architecture, and they each need to provide high-availability service capabilities through multiple copies + master election, such as Resource Manager, TSO, etc. In practice, multiple computing servers also need to select a single node to perform specific read and write tasks. Previously, ByConity used the clickhouse-keeper component for master selection. This component is implemented based on Raft and provides a master selection interface compatible with zookeeper. However, many operation and maintenance problems have been encountered in actual use. For example, more than 3 nodes need to be deployed to provide disaster recovery, which increases the operation and maintenance burden; the node addition and deletion and service discovery processes are complicated; after the container is restarted, if the service changes IP and service port, the keeper Components are difficult to recover quickly, etc.
Considering that ByConity, as a new cloud native service, does not need to be compatible with ClickHouse's access to zookeeper, we chose a cloud native architecture based on the separation of storage and computing to implement a new master selection method to optimize the above problems.
| Design and implementation
The competition for selecting the leader and the release of the results can be regarded as a multi-thread synchronization problem. Inspired by the Linux mutex lock implementation, if we regard ByConity's multiple nodes trying to elect the master as different threads, and the metadata KV storage that supports transaction submission and visibility order equal to the transaction submission order as supporting CAS writing and guaranteeing Visibility-ordered local memory uses periodic Get polling of nodes to simulate the thread wake-up notification mechanism of the Linux kernel. We can use the high-availability KV storage used by ByConity to synchronize the "Who" between multiple nodes by simulating CAS operations. Competition for the answer to the question: Whoever succeeds in CAS will be the leader .
To solve the synchronization between competing writers, we also need to publish the results of the writer competition to readers. The Linux lock data structure will record who is the mutex owner. Here you can also write the leader's listening address as the result of the competition: the value written in the CAS key needs to include its own listening address . Therefore, readers can complete service discovery by accessing this key (readers do not need to know the address of the non-leader).
The implementation of leader election includes formulating basic election rules, implementing processes such as selection, election, winning, taking office, renewal, voluntary resignation, passive resignation, etc., while also solving issues such as time consensus between the old and new leaders and the judgment of term expiration.
The figure below introduces how the generation of a new leader competes among followers to generate a distributed consensus, and agrees with the old leader and new leaders that may appear in the future on the security of the validity period of this consensus, and then allows the client to perceive the whole process of this consensus.

| Actual use
If you use K8s to deploy a ByConity cluster, you only need to adjust the replicas attribute to easily increase or decrease service Pod replicas.
If the ByConity cluster is physically deployed and configured manually, this solution does not require the configuration of service discovery between internal microservices and replicas. The added replicas can be discovered as long as they can be started, and automatically participate in the master selection competition, so that ByConity can Remove dependence on clickhouse-keeper component configuration in the cluster.
03 Further improvement of cold reading performance
In ByConity 0.2.0, we improved the performance of cold read queries by introducing IOScheduler and other methods, especially the cold read performance on S3. Version 0.3.0 further improves cold reading performance by introducing ReadBuffer's Preload and other optimizations.
There are mainly the following optimization strategies:
| Prefetch
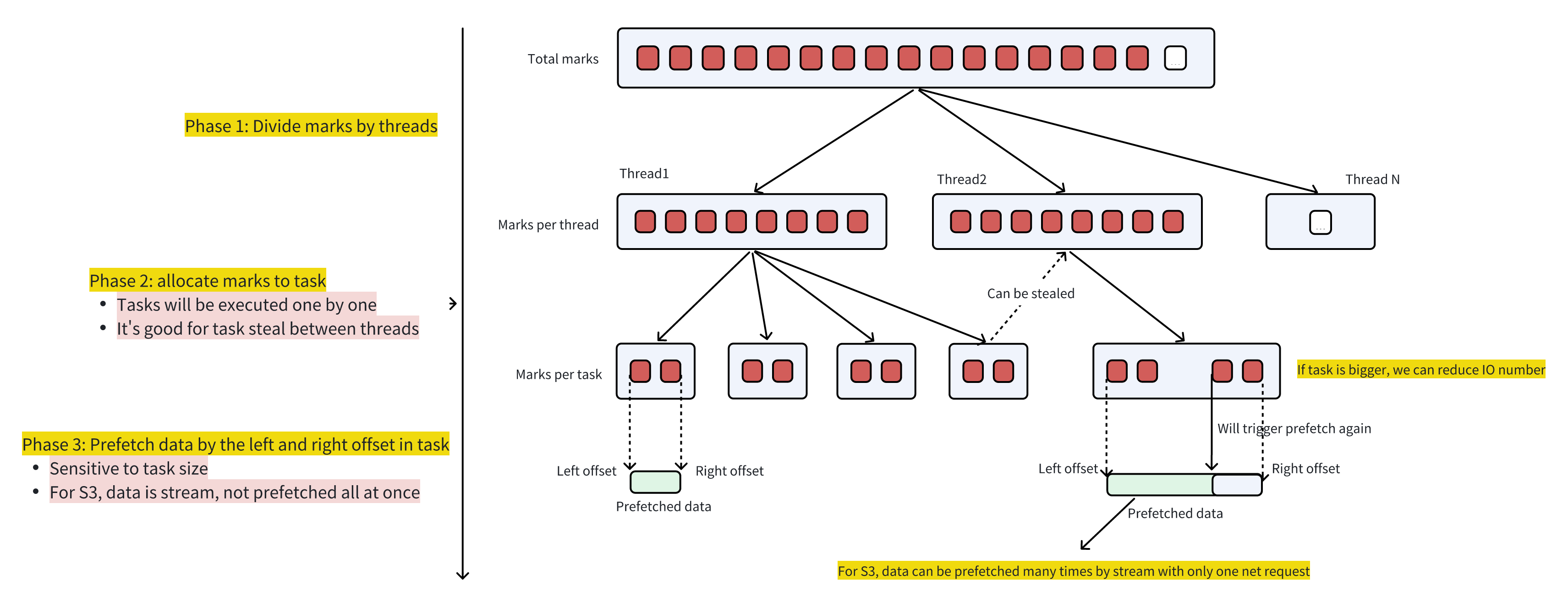
The call stack for Mark Ranges pushdown on the execution side has been optimized, and Prefetch has been introduced, as shown in the following figure:
in:
-
Stage 1: Divide all the marks that need to be queried evenly by Thread
-
Stage 2: All Marks of each Thread are further subdivided into multiple Tasks to facilitate Steal work between Threads
-
Stage 3: Prefetch in single Task units
-
The larger the Task, the fewer network requests are sent, but it may have an impact on work steal.
-
There is no need to worry about the time-consuming impact of a large Task on Prefetch, because the Stream returned by PocoHttpClient S3 is streaming. It is not necessary to read all the data from sending the request to returning. After the request returns, it can be read on demand.
| Adaptive mark per task
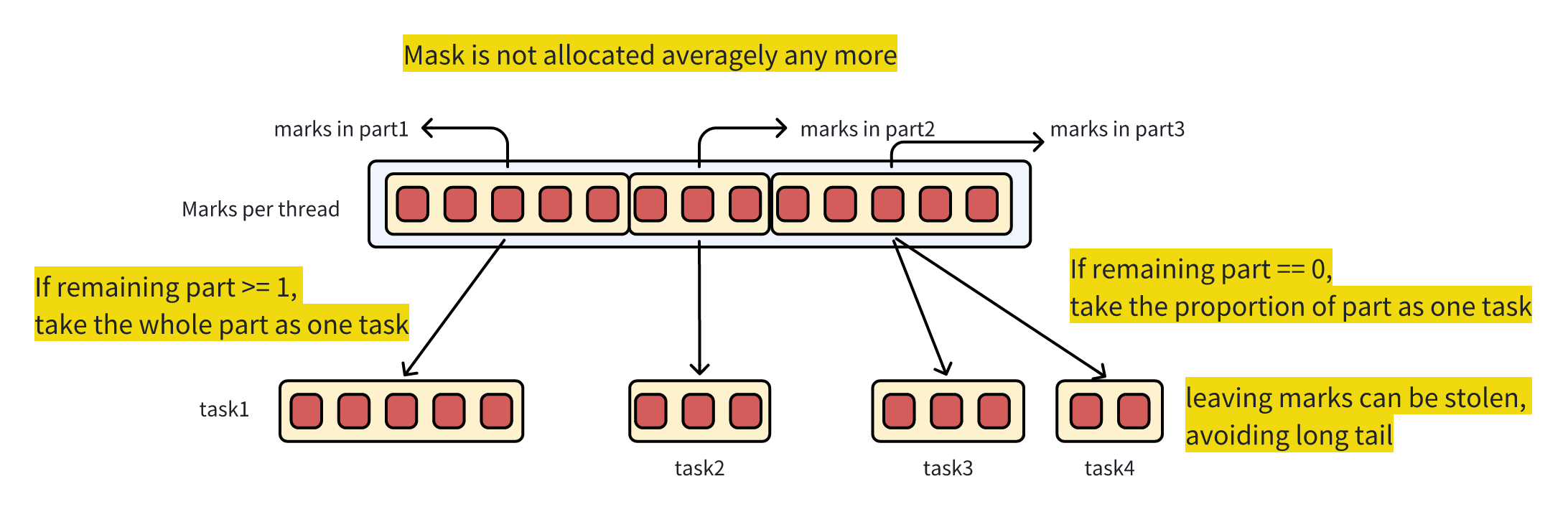
Since the optimization effect of Prefetch is significantly affected by the number of Marks contained in a single Task, especially the number of Marks adopted by the optimal solutions for large queries and small queries may be different, adaptive optimization is adopted for mark per task.
-
The first allocation of the global mark pool between threads still adopts an even distribution strategy to ensure that the initial task size of each thread is the same;
-
The tasks under each thread no longer adopt an even distribution strategy.
-
If in addition to the part being read, the number of remaining parts >= 1, then all masks in the part will be selected for execution this time, and the remaining parts can meet the needs of steal.
-
If the number of remaining parts = 0, split it according to the size of the part
In addition, we also have special optimization for the problem of long waiting time for the first Prefetch synchronization, that is, long start, which will not be detailed here.
| Effect
Prefetch and related optimizations can more than double S3 cold reading performance and improve HDFS cold reading performance by about 20%.
04 ELT capability enhancement
When ByConity 0.2.0 was released, we introduced ByConity's plan for ELT, as well as the capabilities provided in 0.2.0 such as asynchronous execution, queue and disk based shuffle.
In 0.3.0, we introduce a new BSP mode, which satisfies calculations under limited conditions and improves throughput through stage by stage execution and enhanced disk based shuffle. In ByConity, complex queries divide the stages of the query plan and perform stage by stage scheduling, but semantically it is still all at once scheduling. ELT needs to run the query in stages during execution, and needs to further achieve the effect of stage by stage execution.
| Design and implementation
The execution plan (physical/logical) is split into multiple stages based on shuffle from bottom to top, and is embodied in the form of plan segment or plan fragment, also called a phase. There are multiple tasks in the stage. The calculation logic of each task is the same, but the data sharding executed is different. There is data exchange between tasks in dependent stages.
The implementation of Stage execution includes the hierarchical reconstruction of the scheduler. The StagedSegmentScheduler (DAGScheduler) is introduced to be responsible for the state management and scheduling of the stage. The TaskScheduler is responsible for splitting the stage to form a task set. And select the scheduling node for each task and send it to the corresponding node; at the same time, we need to put the process of building io into asynchronous execution and introduce the scheduling process of BSP mode. The specific process is the same as that in the insert query we implemented in 0.2.0 The processing logic of asynchronous execution is similar, but since there may be some uncertainty in the processing of select and insert, the plan will be adjusted accordingly according to the situation. In subsequent versions, we will further enhance the implementation of asynchronous processing mode and scheduler.
For more 0.3.0 related features and optimization content, please view: https://github.com/ByConity/ByConity/releases/tag/0.3.0
The Zed editor written in Rust is officially open source. The former vice president of Meizu ridiculed Huawei for spending trillions to build the Hongmeng ecosystem. Oracle's 2024 Java work plan is incredible - 17-inch 64-core AMD EPYC workstation ioGame17 document may be forced to charge, netty java Game server NetEase Cloud Music third-party open source API was asked to delete ChatGPT due to infringement. Will the official Chinese page of FreeBSD also be "rusted"? The team said that considering using Rust AI tools in the basic system is leading to a decline in code quality. Jia Yangqing’s latest open source project - an AI search tool built with 500 lines of code