Common collection expansion mechanisms and source code analysis in Java
collective framework system
There are many collection classes in Java, which are mainly divided into two categories, namely Collection and Map.
As shown below (recite it, memorize it):
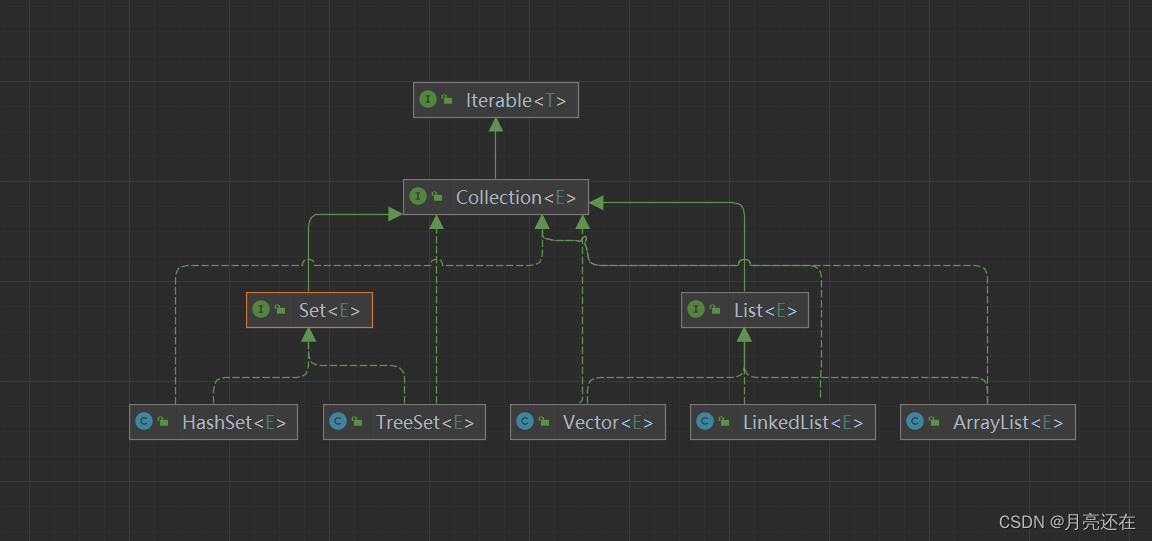
- There are mainly two sets of sets (single-column sets, double-column sets)
- The Collection interface has two important sub-interfaces, List Set, and their implementation subclasses are all single-column collections.
- **The implementation subclass of the Map interface is a double-column collection, which stores KV **
Note: This article is aimed at collection expansion and will avoid collection method demonstrations as much as possible.
ArrayList underlying implementation and source code analysis
Note:
- ArrayList can add null, and can add multiple
- ArrayList implements data storage through arrays
- ArrayLIst is basically the same as Vector, except that ArrayList is thread-unsafe, but the execution efficiency of ArrayLIst is higher than that of Vector.
ArrayList underlying implementation
ArrayList maintains an array elementData of type Object.

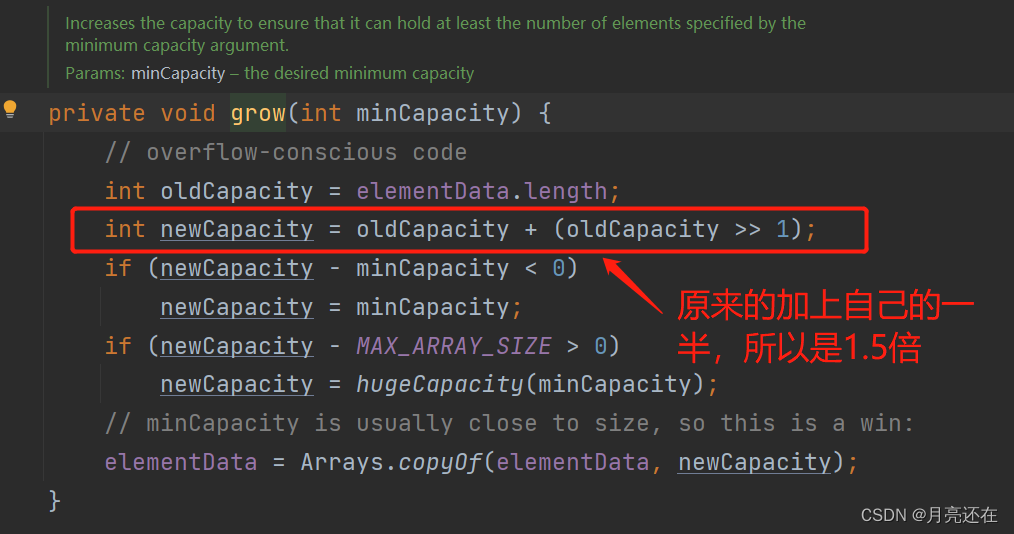
When creating an ArrayList object, if a no-parameter construct is used, the initial elementData is 0. If it is added for the first time and it is found to be insufficient during inspection, the elementData will be expanded to 10. If it needs to be expanded again, then The capacity is expanded to 1.5 times that of elementData.

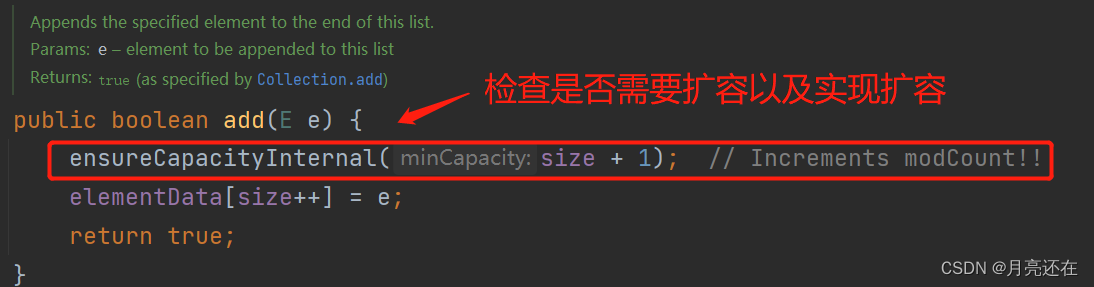
ArrayList expansion checks whether expansion is needed every time data is added (add method)
If a constructor with a specified size is used, the initial elementData capacity is the specified size. If expansion is required, directly expand the capacity to 1.5 times that of elementData.
Vector underlying implementation and source code analysis
The bottom layer of Vector is also an object array protected Object[] elementData;

Vector is thread synchronized (thread safe), and Vector's methods are synchronized, which can be considered in multi-threaded development.
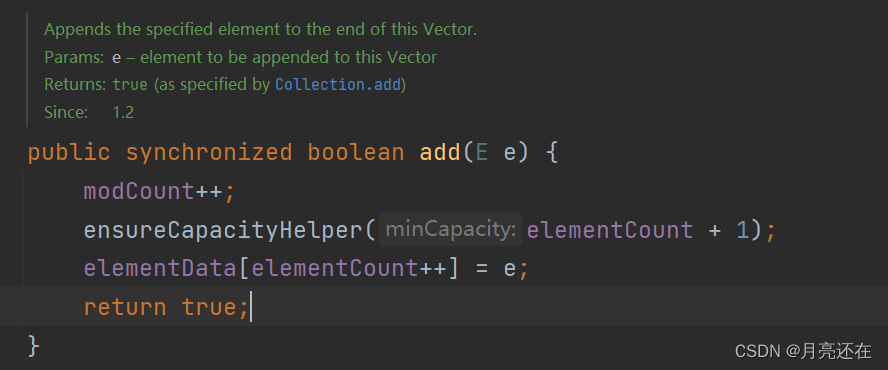
When using no-parameter construction, the capacity defaults to 10
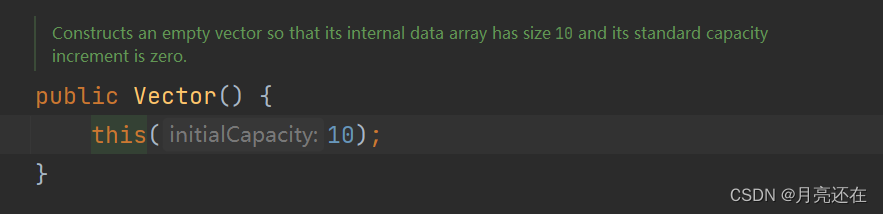
If there is a parameter, the capacity is...
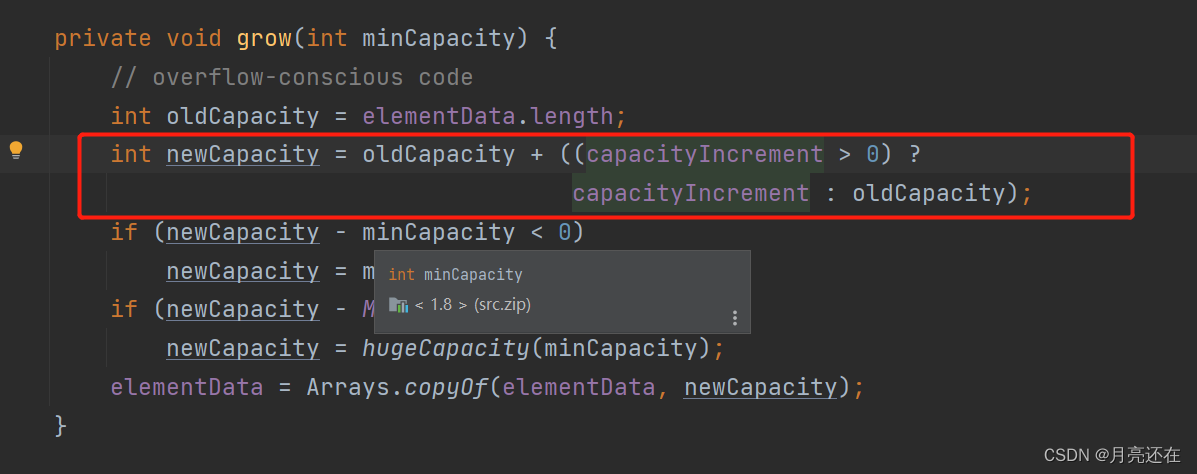
The expansion mechanism also checks whether expansion is needed when adding data, but the expansion of Vector is twice that of elementData.
LinkedList
The underlying layer of LinkedList implements a doubly linked list and a double-ended queue.
Any element can be added and can be repeated, including null
Thread safety is not implemented
LinkedList underlying implementation
LinkedList maintains a doubly linked list at the bottom
LinkedList maintains two attributes first and last pointing to the first node and the last node respectively.
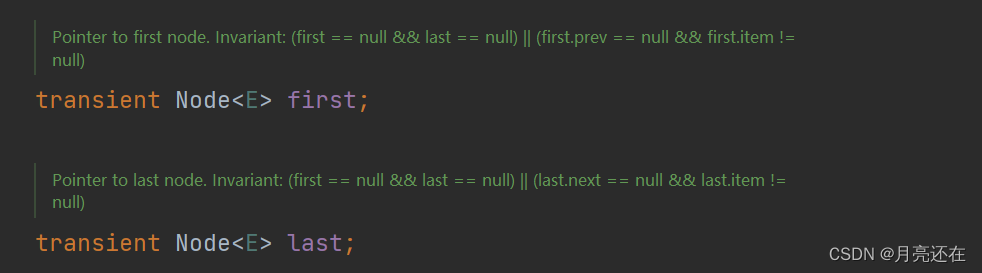
Each node (Node object) maintains three attributes: prev, next, and item. Perv points to the previous node, and next points to the next node to implement a doubly linked list.
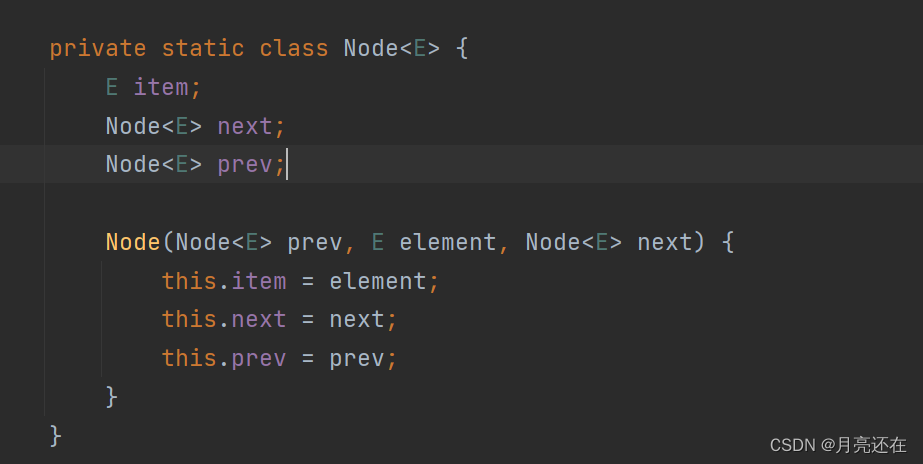
It can be seen that the addition and deletion of elements in LinkedList are not completed through arrays, and are relatively efficient.
At this point, the List introduced in this article is over. Next, let us take a look at the implementation of Set.
Set interface
introduce:
- Unordered (the order of adding is inconsistent with the order of taking out), there is no index, you can use iterators or enhanced for traversal.
- Duplicate elements are not allowed, NUll can be stored
HashSet
HashSet is actually the key of HashMap

The bottom layer of HashSet is HashMap, and the bottom layer of HashMap is array + linked list + red-black tree
The addition of HashSet, in principle, uses the value to be stored as K of HashMap, while V is replaced by an empty Object.
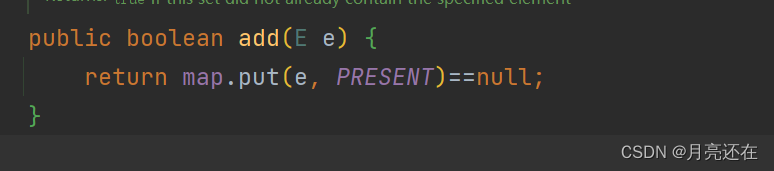
The expansion mechanism and hash are consistent with HashMap. The loading factor is 0.75. If the expansion is satisfied, the capacity will be expanded to 2 times the original. When the elements of a linked list reach 8 or more, and the table size reaches 64 or more, treeing will be performed.
LinkedHashSet
LinkedHashSet is a subset of HashSet. The bottom layer is a LinkedHashMap, which maintains an array + doubly linked list.

LinkedHashSet determines the storage location of elements based on their hashCode values, and uses a linked list to maintain the order of elements (picture), which makes the elements appear to be saved in insertion order.
LinkedHashSet does not allow duplicate elements
At this point, we have ended the introduction of Collection.
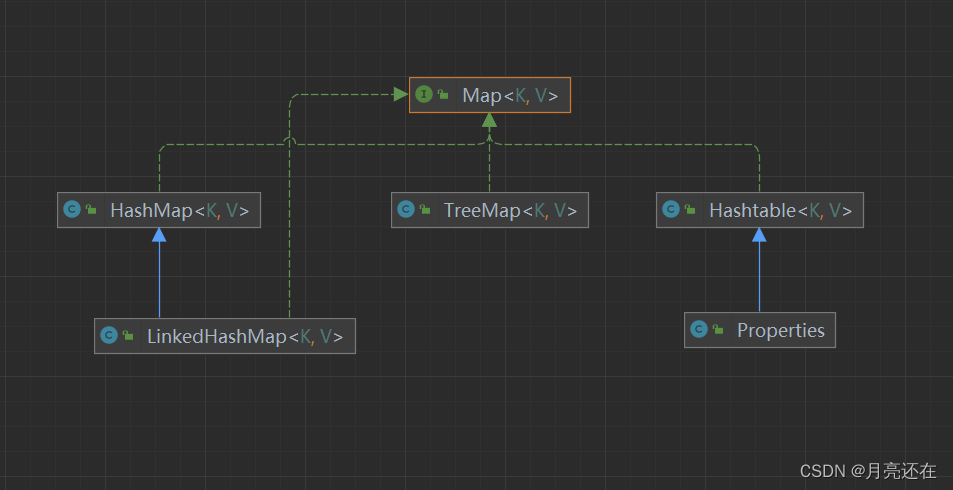
Map interface
- Map and Collection exist side by side. Because KV with mapping relationship is saved.
- The key and value in the Map can be any reference type data and will be encapsulated into the HashMap$Node object.
- Keys in Map are not allowed to be repeated for the same reason as HashSet, values in Map can be repeated.
- The key of Map can be null, and the value can also be null. Note that key is null and there can only be one. value is null and can be multiple. The String class is commonly used as the key of Map.
- There is a one-way one-to-one relationship between key and value, that is, the corresponding value can always be found through the specified key.
HashMap
- The key cannot be repeated, but the value can be repeated, and null keys and null values are allowed.
- If you add the same key, it will overwrite the original key-val, which is equivalent to modification (k will not be replaced, but v will be replaced)
- The order of mapping is not guaranteed, because the bottom layer is stored in the form of a hash table (jdk8's hashMap bottom array + linked list + red-black tree)
- HashMap does not implement synchronization, so it is thread-unsafe. The method does not perform synchronization and mutual exclusion operations, and is not synchronized.
Underlying implementation and expansion mechanism:
- The bottom layer of HashMap maintains an array table of Node type, which defaults to null.
- When creating the object, initialize the loadfactor to 0.75.
- When adding key-val, the index in tablel is obtained by the hash value of key. Then determine whether there is an element at the index, and if there is no element, add it directly. If there is an element at the index, continue to determine whether the key of the element and the key to be added are equal. If they are equal, replace v directly; if they are not equal, you need to determine whether it is a tree structure or a linked list structure, and handle it accordingly. If the capacity is found to be insufficient when adding, it needs to be expanded.
- For the first addition, the table capacity needs to be expanded to 16, and the threshold is 12 (16*0.75). For subsequent expansions, the table capacity needs to be expanded to 2 times the original (32), and the threshold is 2 times the original. , that is, 24, and so on.
- In Java8, if the number of elements in a linked list exceeds TREEIFY THRESHOLD (default is 8), and the size of tablel >= MIN TREEIFY CAPACITY (default 64), it will be treed (red-black tree)
Hashtable
- The stored elements are key-value pairs: KV
- The keys and values of the hashtable cannot be null, otherwise NullPointerException will be thrown
- The usage of hashTable is basically the same as HashMap
- hashTable is thread-safe (synchronized), hashMap is thread-unsafe
Properties
- The Properties class inherits from the Hashtable class and implements the Map interface, which also uses a key-value pair to save data. Its usage characteristics are similar to Hashtable
.
- The usage of hashTable is basically the same as HashMap
- hashTable is thread-safe (synchronized), hashMap is thread-unsafe
Properties
- The Properties class inherits from the Hashtable class and implements the Map interface, which also uses a key-value pair to save data. Its usage characteristics are similar to Hashtable
- Properties can also be used to load data from the xxx.properties file into the Properties class object, and read and modify it.