Distributed locks, as the name suggests, are locks in distributed scenarios. For example, processes on multiple different machines competing for the same resource are distributed locks.
Distributed lock features
Mutual exclusivity: The purpose of the lock is to obtain the right to use the resource, so only one competitor can hold the lock, and this should be guaranteed as much as possible;
Safety: Avoid locks that are never released due to exceptions. When a competitor fails to actively unlock due to an unexpected crash during the period of holding the lock, the lock held by it can also be fully released, and it is guaranteed that other competitors can also lock it subsequently;
Symmetry: For the same lock, locking and unlocking must be the same competitor. Locks held by other competitors cannot be released.
Reliability: A certain degree of exception handling and disaster recovery capabilities are required.
Implementation of distributed lock
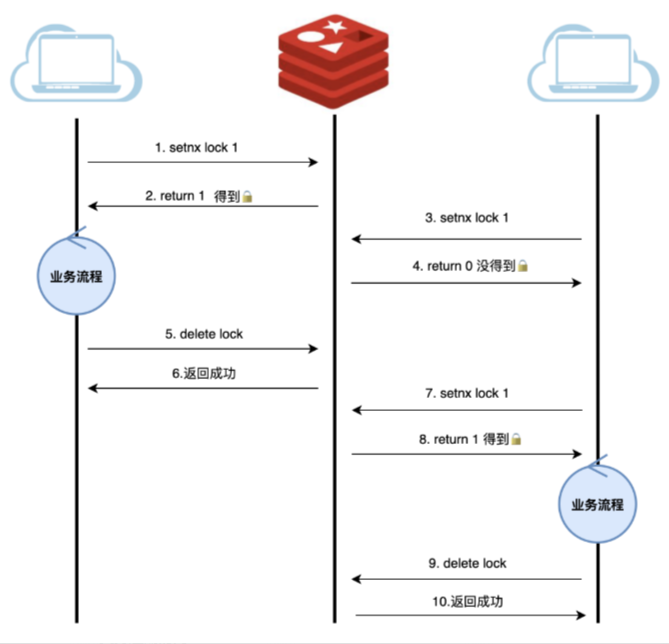
1. Directly use the setnx command of Redis
First of all, of course, build the simplest implementation. Directly use the setnx command of Redis. The syntax of this command is: setnx key value. If the key does not exist, the key will be set to value and 1 will be returned; if the key exists, no There will be task impact, return 0.
Based on this feature, we can use setnx to achieve the purpose of locking: lock through setnx. After locking, other services cannot lock. After use, unlock through delete.
The process of acquiring a lock is the process of setnx. If there is a lock, it will return 0. If there is no lock, it will set the key to value and then release the lock and delete it.
2.Support expiration time
There is a problem with the most simplified version: if the service that obtains the lock hangs up, the lock will never be released, just like nothing is heard from it. So, we need a timeout to find out.
There is an expire command in Redis, which is used to set the timeout period of a key. However, setnx and expire are not atomic. If the service hangs up after setnx acquires the lock (before the setting time comes), it will still be a mess.
Naturally, we will think about whether there are atomic operations for set and expire.
Of course, Redis has already considered this scenario and introduced the following execution statement: set key value nx ex seconds nx means setnx specific, ex means increased Expiration time, the last parameter is the value of the expiration time.
He combined set and expire into an atomic operation
The expiration and lock release are parallel. That is, actively releasing the lock and expiration will delete it.
3.Add Owner
Let's imagine the following scenario: Service A acquires the lock. Due to a long business process, network delay, GC jam, etc., the lock expires, but the business will continue. At this time, business B has obtained the lock and is ready to execute it. When service A recovers and completes the business, it will release the lock, but B is still executing.
In a real distributed scenario, there may be dozens of competitors, so the probability of the above situation occurring is very high, causing the same resource to be frequently accessed by different competitors at the same time, and distributed locks lose their meaning .
Based on this scenario, we can find that the key to the problem is that competitors can release other people's locks . (That is to say, the lock holder can only release the lock himself. This delete process can only be deleted by himself and not by other threads.) Then in abnormal circumstances, problems will occur, so we can further provide solutions. Solution: Distributed locks need to meet the principle of whoever applies for them, and they cannot release other people's locks. In other words, distributed locks must be owned.
Isn't there a delete process to release the lock before we acquire the lock? We make it impossible for other threads to perform this delete operation. Only my lock holder can delete.
Specific steps: Before releasing, first check whether the holder wants to delete, then return the check result, and then operate based on the result.
4.Introduce LUA
Before releasing, first check whether the holder wants to delete, then return the check result, and then operate based on the result.
These three steps are not atomic
Let's look at the gap between detection and returned results
This simultaneous lock has expired
Detect that the lock has expired, release the lock, and another client has acquired the lock, then return the result and delete the lock.
At this time, after judging that it is his own lock, he will delete the lock.
This causes the lock to be accidentally deleted
Then LUA synthesizes atomic operations for these three operations.
(Actually owner)
What guarantees the reliability of distributed locks?
Master-slave disaster recovery
emmm, it was sent from the main library. Use the slave library to send it first.
However, master-slave switching requires manual participation, which will increase labor costs. However, Redis already has a mature solution, which is the sentry mode, which can flexibly and automatically switch and no longer requires manual intervention.
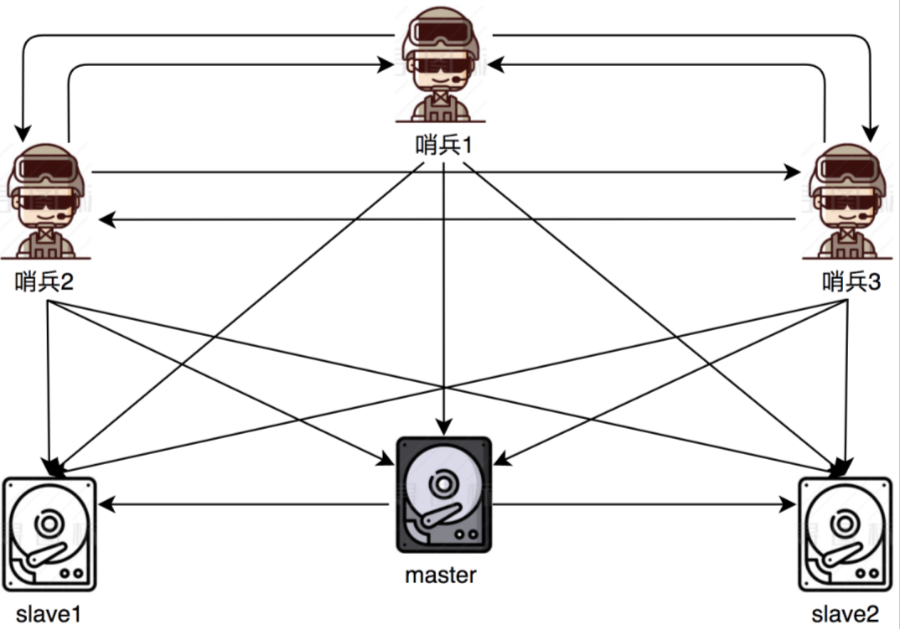
A bunch of arrows are in a mess. Describe it. Each sentinel will monitor the other two sentinels. It will also monitor the master database and two slave databases.
By adding slave nodes, although the single-point disaster recovery problem is solved to a certain extent, it is not perfect. Due to the delay in synchronization, the slave may lose some data, and the distributed lock may fail, which will cause a short-term failure. Multiple machines have obtained execution permissions.
A better way
Multi-machine deployment
If the consistency requirements are higher, you can try multi-machine deployment, such as RedLock of Redis. The general idea is that multiple machines, usually an odd number, will be considered successful when more than half of them agree to lock. In this way, the reliability will be Get closer to ETCD.
Now assuming that there are 5 Redis master nodes, it is basically guaranteed that they will not go down at the same time. During the process of acquiring and releasing the lock, the client will perform the following operations:
1. Apply for locks from 5 Redis;
2. As long as more than half of them are used, That is, if 3 Redis returns successfully, the lock is obtained. If more than half fail, an unlock command needs to be sent to each Redis;
3. Since sending requests to 5 Redis will take a certain amount of time, the remaining lock holding time needs to be subtracted from the request time. This can be used as a basis for judgment. If the remaining time is 0, then it also fails to acquire the lock:
4. After the use is completed, send unlocking requests to 5 Redis.
The advantage of this mode is that if two Redis are down, the entire cluster is still available, giving operation and maintenance more time to repair.
(This method is too heavy and rarely used in business)
Three major dilemmas of distributed systems
NPC for short
The advantage of this mode is that if two Redis are down, the entire cluster is still available, giving operation and maintenance more time to repair.
In addition, one more thing, all the means of single-point Redis, this multi-machine mode can be used, such as configuring sentinel mode for each node. Since the locking is
successful if more than half of them agree, then if a single node performs master-slave Switching, the loss of data on a single node will not invalidate the lock. This enhances
reliability.
N: Network Delay (Network Delay) When the distributed lock takes too long to obtain the return packet, although the lock may be successful, time has passed and the lock may expire soon. RedLock has done some calculations, that is, the remaining lock holding time mentioned earlier needs to be subtracted from the request time. In this way, the problem of network delay can be solved to a certain extent.
P: Process Pause (Process Pause) For example, if GC occurs, GC occurs after acquiring the lock, it is in GC execution, and then the lock times out. Other locks are acquired, and there is almost no solution to this situation. At this time, the GC comes back, and the two processes obtain the same distributed lock.
Maybe you will say that after the GC comes back, you can check it again?
There are two questions here. First, how do you know that the GC is back? This can be roughly judged through time before doing business, but it is also very difficult. Scenario experience; secondly, what if it is ok when you judge, but after judging the GC? RedLock cannot solve this.
C: Clock Drift (Clock Drift)
If competitor A obtains RedLock, locks are added to 5 distributed machines. For the convenience of analysis, we directly assume that clock drift occurs on all five machines and the lock expires instantly. At this time competitor B gets the lock, and A and B get the same execution permissions.
Based on the above analysis, it can be seen that RedLock cannot withstand the challenge of NPC. Therefore, it is impossible to be completely reliable based solely on the distributed lock itself. To implement a relatively reliable distributed lock mechanism, you still need to cooperate with the business. The business itself must be idempotent and reentrant. This design can save a lot of trouble.