Table of contents
2. Apply data separation architecture
3. Application service cluster architecture
4. Read and write separation/master-slave separation architecture
5. Introducing cache - hot and cold separation architecture
7. Business splitting-microservices
8. Introduction of containerization - container orchestration architecture
1. Stand-alone architecture
In the early stage, we need to use our capable technical team to quickly put the business system into the market for testing and respond quickly to changing requirements. But fortunately, the number of user visits in the early stage was very small, and there were no high requirements for our performance, security, etc., and the system architecture is simple and does not require a professional operation and maintenance team, so it is appropriate to choose a stand-alone architecture.

The user enters www.baidu.com in the browser. First, the domain name is resolved into the IP address 10.102.41.1 through the DNS service, and then the browser accesses the application service corresponding to the IP.
Advantages: simple deployment, low cost
Disadvantages: There is a serious performance bottleneck, the database and the application compete with each other for resources
2. Apply data separation architecture
As the system went online, we achieved success as expected. A group of loyal users appeared on the market, which gradually increased the number of visits to the system, gradually approaching the limit of hardware resources. At the same time, the team also accumulated a lot of experience in business processes during this period. Facing the current performance pressure, we need to take precautions to carry out system reconstruction and architectural challenges to improve the system's carrying capacity. However, since the budget is still very tight, we chose to separate applications and data, which can increase the system's carrying capacity at the minimum cost.
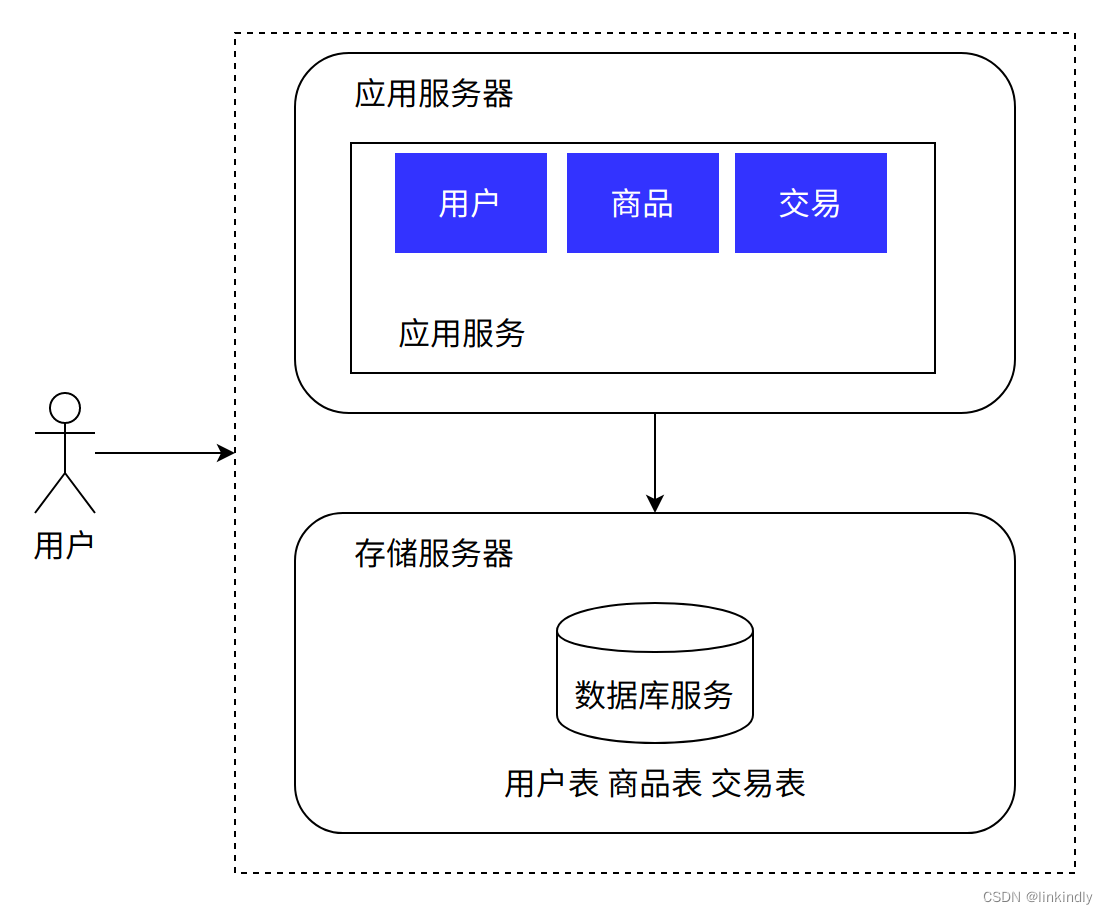
The main difference from the previous architecture is that the database service is independently deployed on other servers in the same data center, and the application service accesses the data through the network.
Advantages: The cost is relatively controllable, the performance is improved compared to a single machine, the database is isolated separately, the database will not be damaged due to applications, and it has certain disaster recovery capabilities
Disadvantages: Hardware costs become higher, performance has bottlenecks, and cannot handle massive concurrency
3. Application service cluster architecture
Our system has been welcomed by users and has become popular. A single application server can no longer meet the demand. Our stand-alone application server first encountered a bottleneck. There were two options before our technical team. Everyone had a heated discussion on the pros and cons of the solutions:
• Vertical expansion / vertical expansion Scale Up. Deal with more traffic by purchasing application servers with better performance and higher prices. The advantage of this solution is that it does not require any adjustments to the system software; but the disadvantage is also obvious: the relationship between hardware performance and price growth is non-linear, which means that choosing hardware with 2 times the performance may cost more than 4 times the price. , Secondly, there is a clear upper limit to hardware performance improvement.
• Scale Out/Scale Out. By adjusting the software architecture, adding application layer hardware, and allocating user traffic to different application layer servers, the system's carrying capacity can be improved. The advantage of this solution is that the cost is relatively low and the upper limit of improvement is also large. But the disadvantage is that it brings more complexity to the system and requires more experience from the technical team. After the team's study, research and discussion, we finally chose the horizontal expansion solution to solve this problem, but this required the introduction of a new component - load balancing: In order to solve the problem of which application server the user traffic is distributed to, a Specialized system components do traffic distribution. In practice, load balancing not only refers to working in the application layer, but may even be in other network layers. At the same time, there are many kinds of traffic scheduling algorithms. Here are a few common ones:
• Round-Robin polling algorithm. That is, the requests are distributed to different application servers very fairly.
• Weight-Round-Robin round robin algorithm. Give different weights to different servers (for example, with different performance)
, and those who can do more work.
• Consistent Hash hashing algorithm. The hash value is obtained by calculating the user's characteristic value (such as IP address) and distributed based on the hash result. The advantage is to ensure that requests from the same user are always assigned to the designated server. That is the special account manager service we usually encounter.
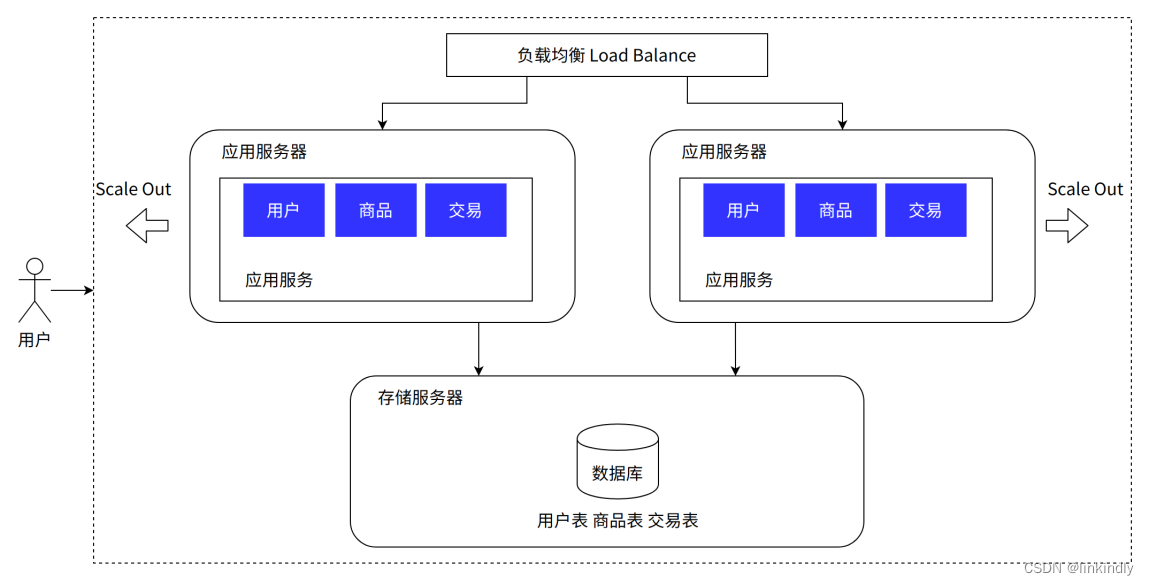
Advantages: High availability of application services: Applications meet high availability, and the whole site will not hang up if there is a problem with one service; Application services have certain high performance: If the database is not accessed, application-related processing can support rapid response to massive requests through expansion; Application services have Certain scalability: supports horizontal expansion
Disadvantages: The database has become a performance bottleneck and cannot cope with the massive queries of the database; the database is a single point and does not have high availability; the operation and maintenance work increases, and the deployment and operation and maintenance work increases after expansion, and corresponding tools need to be developed to cope with rapid deployment; the hardware cost is high
4. Read and write separation/master-slave separation architecture
As mentioned earlier, after we distribute user requests to different application servers through load balancing, they can be processed in parallel, and as the business grows, the number of servers can be dynamically expanded to relieve pressure. But in the current architecture, no matter how many servers are expanded, these requests will eventually read and write data from the database. After a certain level, the pressure on the data becomes the bottleneck of the system's carrying capacity. Can we scale the database server the same way we scale the application server? The answer is no, because database services have their own particularities: if the data is distributed to various servers, the consistency of the data cannot be guaranteed. The so-called data consistency here refers to: for the same system, no matter when and where, we should see a consistent data. Imagine the account amount managed by a bank. If after receiving a transfer, the data in one database is modified, but the other database is not modified, the deposit amount received by the user will be wrong. The solution we adopted was to keep one primary database as the write database and the other databases as slave databases. All data in the slave database comes from the data in the master database. After synchronization, the slave database can maintain data consistent with the master database. Then in order to share the pressure on the database, we can hand over all write data requests to the main library for processing, but spread the read requests to various slave libraries. Since in most systems, read and write requests are disproportionate, for example, 100 reads and 1 write, so as long as the read requests are shared among the slave libraries, the pressure on the database will not be so great. Of course, this process is not cost-free. Data synchronization from the master database to the slave database actually has a time cost, but we will not discuss this issue further for the time being.
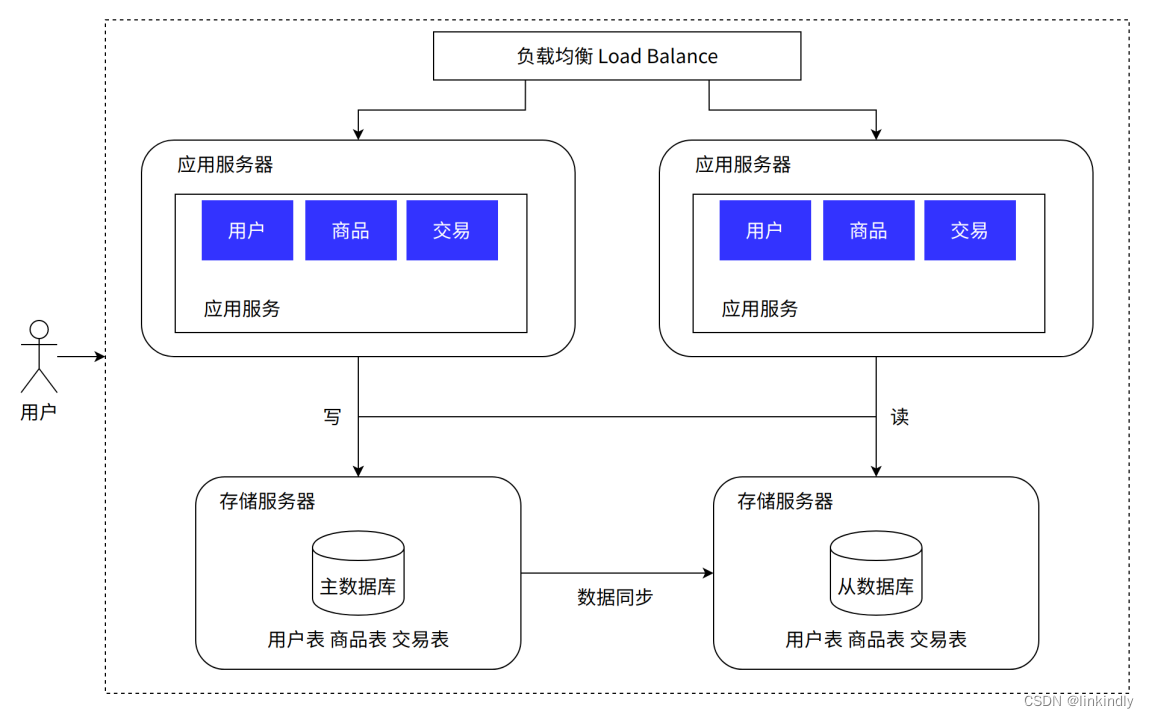
Advantages: The reading performance of the database is improved; reading is shared by other servers, and the writing performance is indirectly improved; the database has slave libraries, and the availability of the database is improved
Disadvantages: Frequent reading of hotspot data results in high database load; when synchronization fails or the synchronization delay is relatively large, the data written to the database and the read database are inconsistent; server costs need to be further increased
5. Introducing cache - hot and cold separation architecture
As the number of visits continues to increase, it is found that the reading frequency of some data in the business is much greater than that of other data. We call this part of data hot data, which corresponds to cold data. For hot data, in order to improve the response time of reading, you can add local cache and add external distributed cache to cache popular product information or html pages of popular products, etc. Through caching, most requests can be intercepted before reading and writing to the database, greatly reducing database pressure. The technologies involved include: using memcached as a local cache and using Redis as a distributed cache. It also involves issues such as cache consistency, cache penetration/breakdown, cache avalanche, and hotspot data centralized failure.
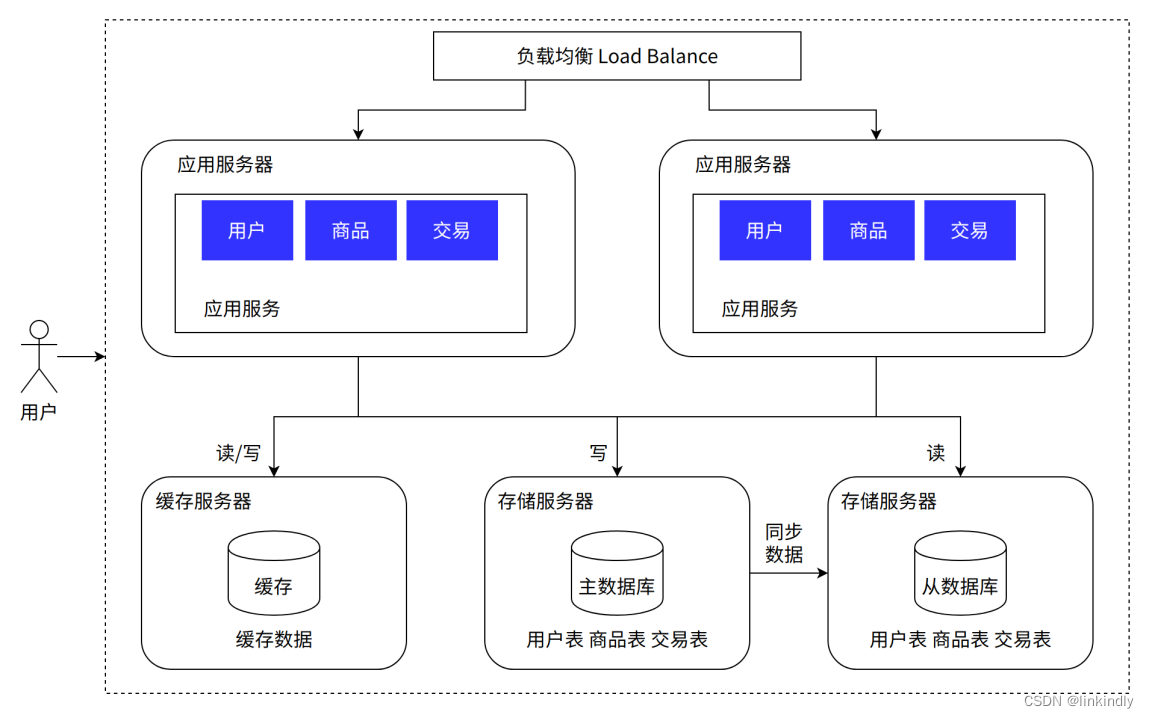
Advantages: Greatly reduce access requests to the database, and the performance improvement is very obvious;
Disadvantages: It brings about cache consistency, cache breakdown, cache failure, cache avalanche and other problems; server costs need to be further increased; as the business volume increases, data continues to increase, the single database is too large, and the size of a single table is also large. If it is too large, data query will be very slow, causing the database to become the system bottleneck again.
6. Vertical sub-library
As the amount of business data increases, storing a large amount of data in the same database has become a bit overwhelming, so the data can be stored separately according to the business. For example, for comment data, it can be hashed according to the product ID and routed to the corresponding table for storage; for payment records, a table can be created by hour, and each hourly table can be split into small tables, and the user ID or record number can be used to route the data. . As long as the amount of table data being operated in real time is small enough and requests can be evenly distributed to small tables on multiple servers, the database can improve performance through horizontal expansion. The Mycat mentioned earlier also supports access control when a large table is split into small tables. This approach significantly increases the difficulty of database operation and maintenance, and places higher demands on DBAs. When the database is designed with this structure, it can already be called a distributed database, but this is just a logical database as a whole. Different components in the database are implemented separately by different components, such as the management and request of sub-databases and sub-tables. Distribution is implemented by Mycat, SQL parsing is implemented by a stand-alone database, read-write separation may be implemented by gateways and message queues, summary of query results may be implemented by the database interface layer, etc. This architecture is actually MPP (large-scale A class of implementations of parallel processing) architecture.
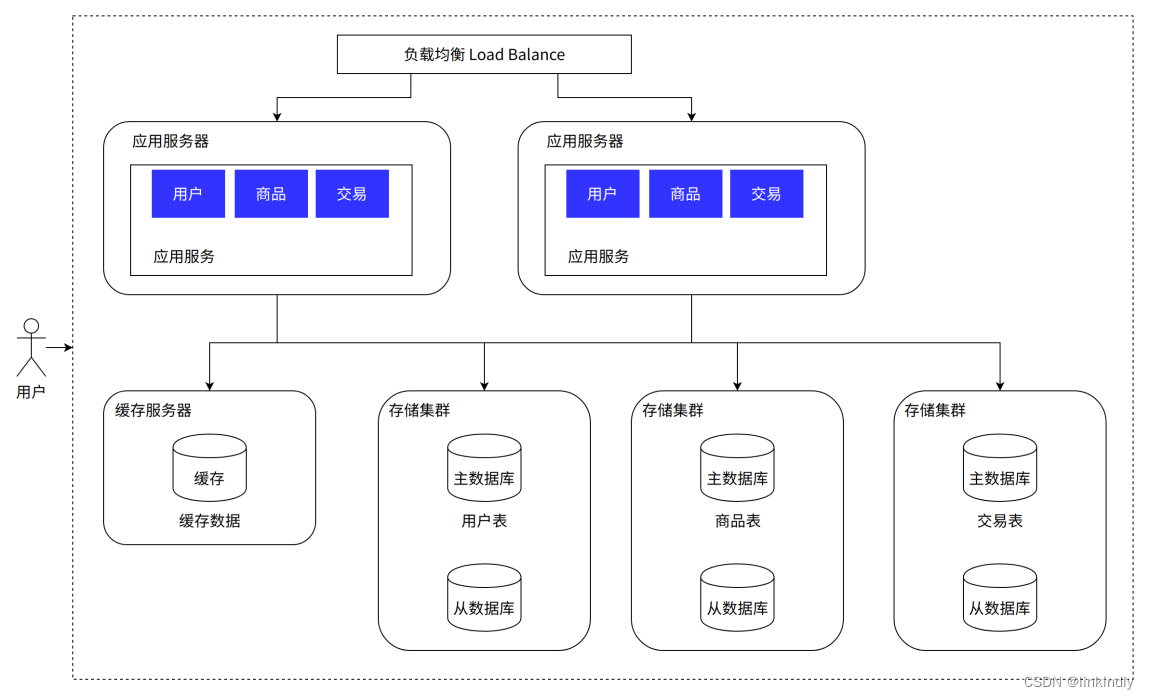
Advantages: Database throughput is greatly improved and is no longer a bottleneck;
Disadvantages: Issues such as cross-database joins and distributed transactions need to be solved accordingly. The current mpp has corresponding solutions; the combination of database and cache can currently withstand massive requests, but the overall application code is coupled together. , modifying one line of code requires re-publishing the entire code
7. Business splitting-microservices
As the number of people increases and the business develops, we divide the business into different development teams for maintenance. Each team independently implements its own microservices, and then isolates direct access to data from each other. Technologies such as Gateway and message bus can be used. , to achieve mutual call association. You can even turn some services such as user management into public services.

Advantages: High flexibility: independent testing, deployment, upgrade and release of services; independent expansion: each service can be expanded independently; improved fault tolerance: one service problem will not paralyze the entire system; easy application of new technologies: supports multiple programming language
Disadvantages: High complexity of operation and maintenance: With the continuous development of business, the number of applications and services will continue to increase, and the deployment of applications and services will become complicated. Deployment of multiple services on the same server also requires solving the problem of running environment conflicts. In addition, for example, Scenarios such as big promotions that require dynamic expansion and contraction require horizontal expansion of service performance, which requires preparing the operating environment for new services, deploying services, etc. Operation and maintenance will become very difficult; resource usage will increase: all of these Microservices that run independently need to occupy memory and CPU; it is difficult to handle faults: a request spans multiple service calls, and you need to check the logs of different services to complete problem location
8. Introduction of containerization - container orchestration architecture
As the business grew, it was discovered that the resource utilization rate of the system was not high. Many resources were used to deal with short-term high concurrency and were idle at ordinary times. Dynamic expansion and contraction were required. There was no way to directly offline the server, and every day during development, testing, and production was In an environment where all sets of environments must be isolated, the workload of operation and maintenance becomes very large. The emergence of containerization technology has brought new ideas to solve these problems.
Currently, the most popular containerization technology is Docker, and the most popular container management service is Kubernetes (K8S). Applications/services can be packaged as Docker images, and the images can be dynamically distributed and deployed through K8S. A Docker image can be understood as a minimal operating system that can run your application/service. It contains the running code of the application/service. The operating environment is set according to actual needs. After the entire "operating system" is packaged into an image, it can be distributed to the machines where related services need to be deployed. The service can be started by directly starting the Docker image, making the deployment and operation and maintenance of the service simple. Services
usually have production and R&D k8s clusters, which are generally not shared publicly. R&D clusters use namespaces to complete application isolation. Some companies are divided into R&D and test clusters according to R&D purposes, and some companies complete inter-department resources through organizational structures. Reuse.
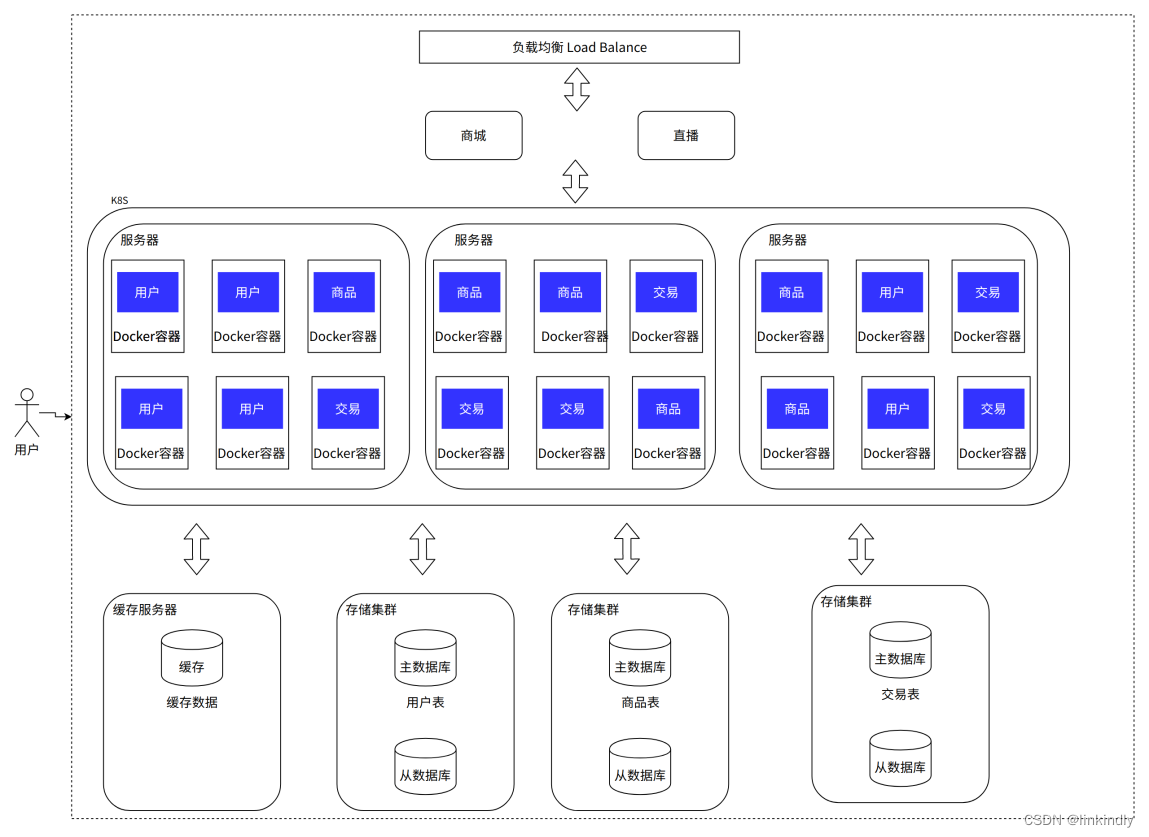
Advantages: deployment, operation and maintenance are simple and fast: one command can complete the deployment or expansion and contraction of hundreds of services; good isolation: the file system, network, etc. between containers are isolated from each other, and there will be no environmental conflicts; easy support Rolling update: switching between versions can be upgraded or rolled back with a single command
Disadvantages: The number of technology stacks increases and the requirements for the R&D team are high; the machines still need to be managed by the company itself. When there is no major promotion, a large amount of machine resources still need to be idle to cope with the major promotion. The cost of the machine itself and the operation and maintenance cost are extremely high. High and low resource utilization, which can be solved by purchasing servers from cloud vendors.
Summarize
At this point, the basic prototype of a reasonably high-availability, high-concurrency system has emerged. Note that the architecture evolution sequence mentioned above is only a separate improvement for a certain aspect. In actual scenarios, there may be several problems that need to be solved at the same time, or another aspect may reach the bottleneck first. At this time, it should Solve practical problems according to actual problems. For example, in government scenarios where the amount of concurrency may not be large, but the business may be very rich, high concurrency is not the key problem to be solved. At this time, the priority may be solutions that meet rich needs. For systems that are implemented once and have clear performance indicators, it is sufficient for the architecture to be designed to support the system's performance indicator requirements, but interfaces for extending the architecture should be left in case of emergencies. For continuously developing systems, such as e-commerce platforms, they should be designed to meet the user volume and performance index requirements of the next stage, and the architecture should be iteratively upgraded based on business growth to support higher concurrency and richer services. . The so-called "big data" is actually a collective term for scenario solutions such as massive data collection, cleaning and conversion, data storage, data analysis, and data services. Each scenario includes a variety of optional technologies, such as Flume, Sqoop, Kettle, etc.; data storage includes distributed file systems HDFS, FastDFS, NoSQL database HBase, MongoDB, etc.; data analysis includes Spark technology stack, machine learning algorithms, etc. In general, big data architecture is an architecture that integrates various big data components according to business needs. It generally provides distributed storage, distributed computing, multi-dimensional analysis, data warehouse, machine learning algorithms and other capabilities. The server-side architecture refers more to the architecture at the application organization level, and the underlying capabilities are often provided by big data architecture.