
*Author: He Jiahuan, Alibaba Cloud MSE R&D Engineer
Why microservice governance?

In the modern microservice architecture, we decompose the system into a series of services and connect them together through remote procedure calls, which brings some advantages but also brings us some challenges.
As shown in the figure above, you can see that what is displayed in the word cloud are the challenges encountered by the current microservice architecture in production. For example, the most common scenario of traffic surge is that AIGC suddenly became popular in the past year. Related websites/services have experienced service unavailability due to the surge in traffic, which may cause us to miss an optimal growth window.
Another example is the lack of a fault-tolerant mechanism. A certain service exception on a certain video website spreads along the call chain, causing the entire site entrance to be unavailable, affecting tens of millions of users and causing substantial economic losses. The frequent occurrence of these production failures also reminds us that stability is one of the major challenges in using microservices well.
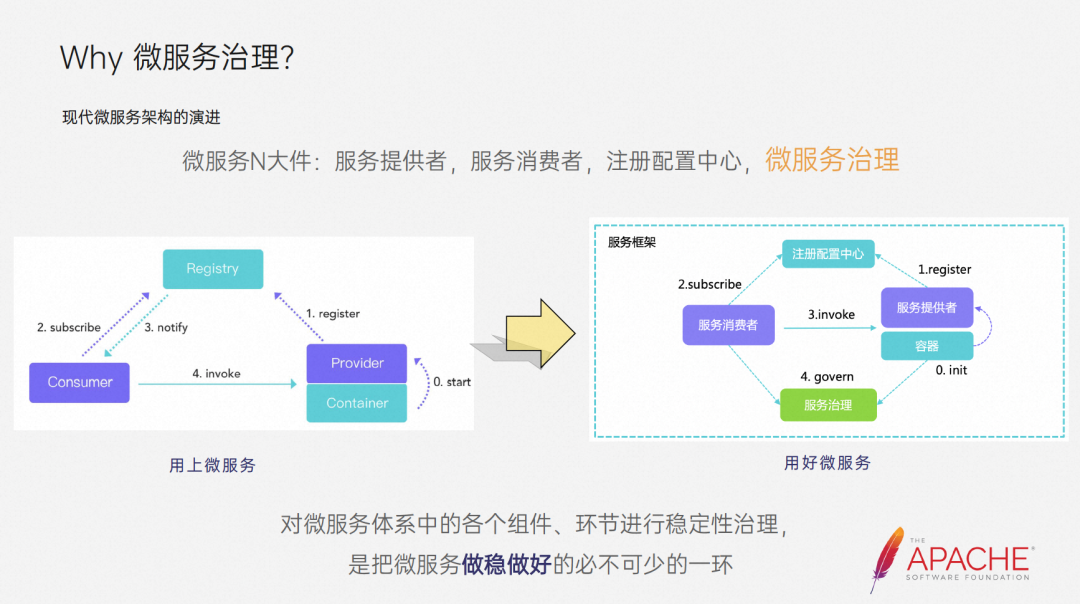
In order to ensure the stability of microservices, we need to make some architectural evolutions.
Let’s first take a look at the three major components of microservices on the left, which everyone is already familiar with. Through the cooperation of these three, our application can be used normally, but there is still a long way to go before it can be used in production. Various enterprises There have been some explorations and practices with the community to bridge the gap. For example, the Dubbo community has introduced a series of capabilities such as traffic management and high availability into Dubbo3 to ensure the stability of microservices. These measures can be collectively referred to as microservice governance.
So it can actually be seen that everyone has realized that microservice governance is an indispensable part from running microservices to actually being available for production. But what microservice governance should do and how to do it are actually still relatively vague.

From the perspective of the software life cycle, we can divide microservice governance into three domains, Development state, test state, change state, and running state.
We are facing many challenges in these three domains, and we have also done some exploration and practice on these challenges. For example, for the problem of lossy release, we can solve it through lossless online and offline, and the impact of the change is controlled through grayscale. For uncertain traffic, use flow control and hotspot protection, and for unstable calls, use fusing and isolation.
It can be seen that there are some mature solutions and very effective practices in various fields. However, whether it is Alibaba or other companies, they will encounter many problems when implementing microservice governance in a systematic manner.
OpenSergo: Service governance control surface and standards specifications

First of all, we involve many components. In the microservice architecture, we will need a calling framework like Dubbo, a registration center like Nacos, stability middleware like Sentinel and Hystrix, etc. These components cannot be managed and controlled in a unified way. The cost will become very high.
Secondly, the concepts are not unified. For example, isolation in Envoy and isolation in Sentinel have completely different meanings. Envoy's isolation is to remove unhealthy instances, while Sentinel's isolation is concurrency control, which makes the understanding cost of developers very high.
At the same time, each enterprise community has its own best practices, which leads to misalignment in everyone's capabilities and no unified standards.
There is also the problem of inconsistent configurations, which I believe everyone is familiar with. For example, Sentinel, Hystrix, and Istio all have circuit breaker capabilities, but their configurations are different. Developers need to learn separately, and they must also be careful not to confuse each other, which is not conducive to understanding. It is not conducive to unified management and control.
It can be found that due to these problems, we will have great resistance when implementing systematic microservice governance.What we need is a unified management interface to make us better We want to do microservice governance, so we proposed the OpenSergo project.
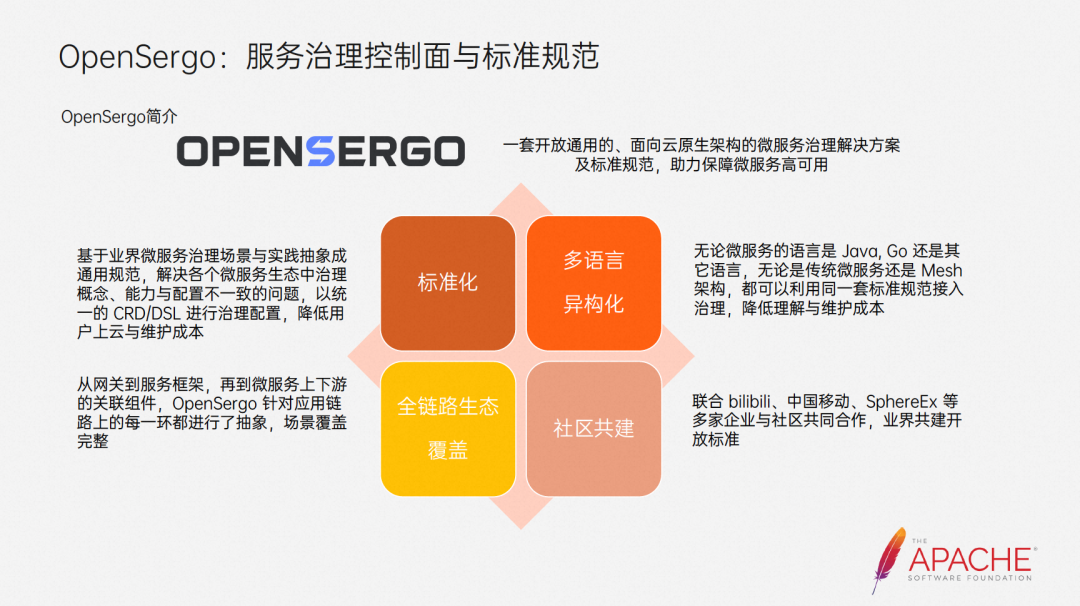
OpenSergo hopes to propose a set of open and universal microservice governance solutions and standards for cloud-native architecture to help ensure high availability of microservices. The four parts of the picture above are the vision of the OpenSergo community.
The OpenSergo community will abstract it into specifications based on industry microservice governance scenarios and practices. In this way, it will solve the previously mentioned problems of inconsistent concepts, configurations, and capabilities, and use a unified management and control plane to carry them, reducing usage and maintenance costs.
At the same time, vertically, we abstract each link on the link to cover complete scenarios. Horizontally, whether it is the Java ecosystem, Go ecosystem or other languages, whether it is traditional microservices or Mesh architecture, they will be included in this unified system.
But OpenSergo is an open standard, and Alibaba alone is not enough. Therefore, we have joined forces with many companies and communities such as bilibili and China Mobile to jointly build this set of open standards, hoping to truly solve the risk of microservice stability.

The following is a brief introduction to the architecture of OpenSergo. As mentioned earlier, the OpenSergo community will abstract OpenSergo's Spec based on scenarios, but this is only the first step. In order to carry these standards To regulate, we need a control plane. In the initial evolution, the community chose to develop a control plane from scratch to control, monitor and issue governance rules.
However, as the community evolves, we find that scaling based on Istio is cheaper and can reuse more capabilities. Therefore, in the subsequent evolution, we will choose to combine the Istio expansion control plane and the decision center to achieve unified management and control of governance rules. Governance policy precomputation.
After we have the control plane, we also need the data plane to implement specific governance capabilities. It can be middleware like Sentinel or the framework itself. The communication between the control plane and the data plane was based on links built on gRPC in the initial architecture. However, after determining that the subsequent evolution direction would be based on Istio extensions, the community chose to embrace XDS and serve its links as much as possible. For some If it cannot be carried, we will use our own gRPC link.

As mentioned earlier, the subsequent evolution of the community control plane is based on Istio extensions. Istio itself also has some traffic management capabilities and has a certain degree of popularity. However, Istio mainly focuses on traffic management and letting the traffic go where it should go rather than microservice governance. Therefore, in the scenario of microservice stability, the capabilities provided by Istio are not enough to meet our needs.
Therefore, on the basis of Istio, we have abstracted some scenarios based on microservice stability, such as the previously mentioned change state stability and runtime stability, and formulated standards to meet the needs, hoping to be more suitable for microservice scenarios. . So overall we will be a superset of Istio in the field of microservice governance, rather than a mutually exclusive relationship.
Next, let’s take a look at how the OpenSergo standard specification solves the scenarios mentioned above.
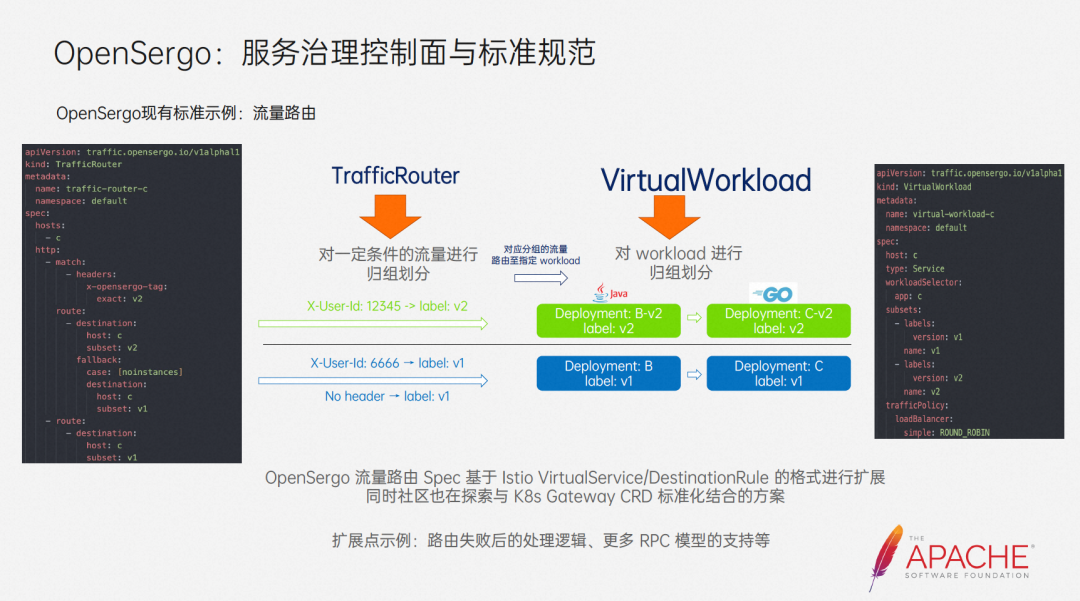
First, let’s talk about traffic routing. Its main function is to route traffic that meets certain characteristics to a specified workload. Generally, people will use this capability to implement grayscale, same-AZ routing and other solutions.
The format community based on Istio VirtualService/DestinationRule defines traffic routing spec, but during our research and practice, we found that it cannot meet the needs of microservice scenarios very well. Therefore, we expanded it to be closer to the microservice scenario. For example, we added processing logic after routing failure, which is a very common requirement in microservice architecture.
And since Istio mainly focuses on HTTP requests, its CRD cannot carry RPC calls like Dubbo well, so we have added support for more RPC models. In the future, we will also explore options to integrate with community standards to make our Spec more universal and standard.
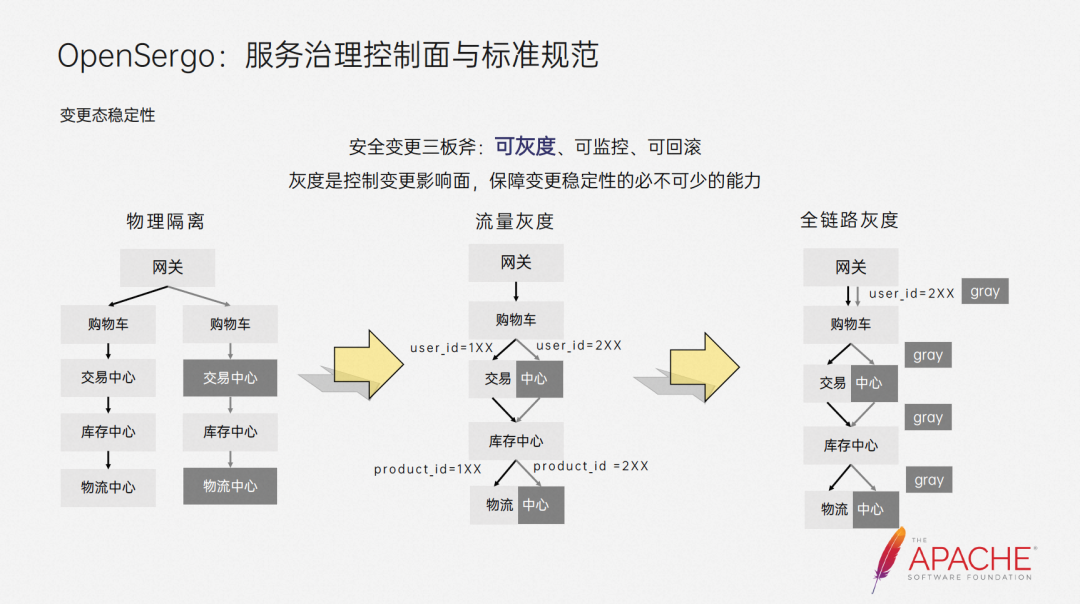
The grayscale mentioned earlier has been defined as the three pillars of safe change along with monitorability and rollback in several years of safe production practice within the Alibaba Group. Grayscale is to control the impact of the change and ensure the stability of the change. essential abilities.
In order to achieve grayscale, we usually have several solutions. The first is physical isolation. We implement grayscale by deploying two sets of the same environment. However, the deployment and maintenance costs of this solution are high.
In order to improve resource utilization, the second solution was produced, traffic grayscale. We do not deploy an independent environment, but match the characteristics of the traffic at each hop of the traffic, and decide whether to go to the grayscale instance or the base instance. Compared with the former, this solution More flexibility and efficiency can be achieved through the traffic routing capabilities mentioned earlier. However, we need to configure routing rules on each hop, which is relatively cumbersome.
And because some information cannot be obtained in subsequent links, such as uid, there are certain difficulties in the implementation of this solution. So the third solution was born, full-link grayscale. We match the traffic at the traffic entrance and label it, and the label will automatically be along the When link transparent transmission is called, subsequent links are routed based on labels. In this way, we can define grayscale more concisely. Opensergo abstracts the corresponding CRD for this scenario.
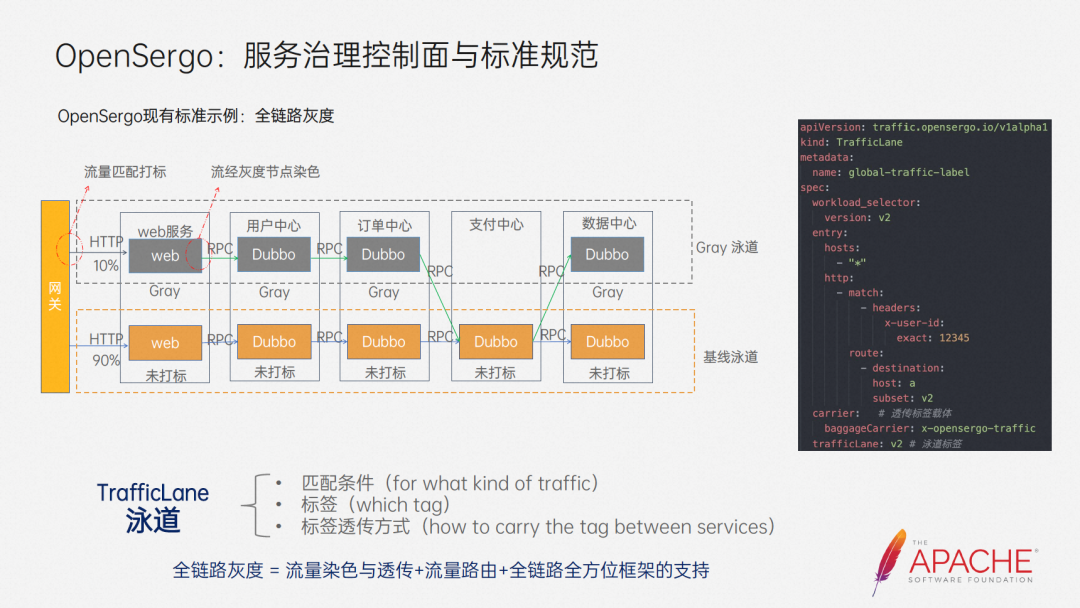
We call this CRD TrafficLane, which is also a swimming lane. I think it is quite vivid. Take a look at the picture above. The orange one is the normal traffic direction, and the gray one is the grayscale traffic direction. It is like dividing a pool into Multiple swimming lanes.
The CRD of a swim lane consists of three parts and is relatively easy to understand. First, we need to match grayscale traffic, so we need to define the matching conditions, then define what labels to label these traffic, and finally define how to use this label. Penetrate.
Through such CRD we define a grayscale swim lane. But if definition alone is not enough to achieve full grayscale, we also need the support of the OpenSergo system's full-link and all-round framework to allow tags to be automatically transparently transmitted in these frameworks. These frameworks can also be routed through tags. . Traffic coloring and label transparent transmission will be implemented using the standard Trcae system, such as OpenTelemetry.
The right side of the picture above is an example of a CRD. You can take a brief look at it.
Next, let’s take a look at the scenario of running state stability.
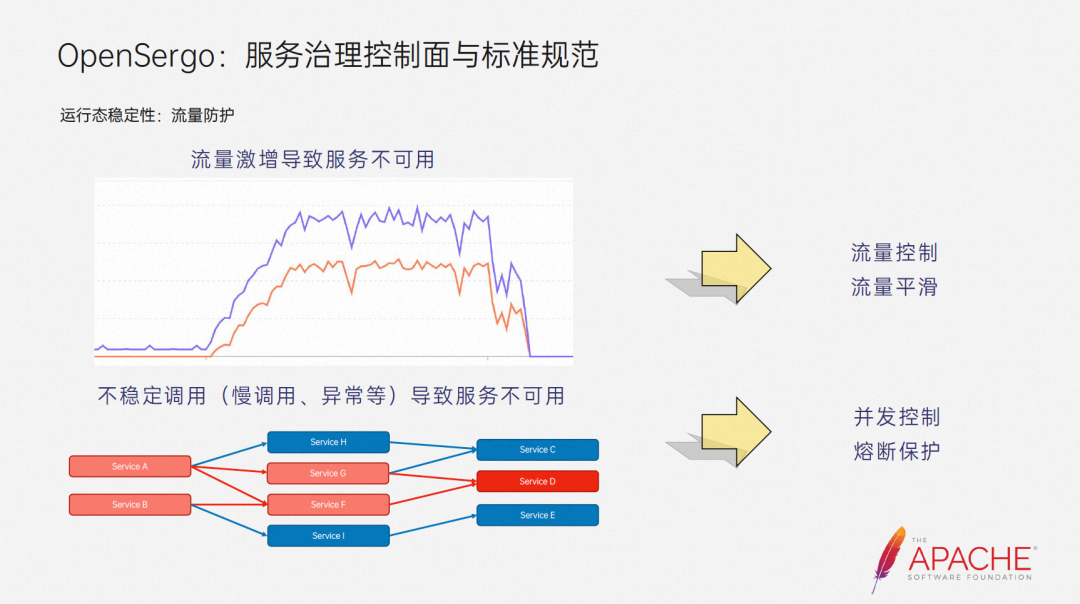
We mainly mention two scenarios.The first one is the scenario where traffic surges. For example, during the Double Eleven flash sale event, the traffic will increase at the beginning. When it is stable, the system is also in a steady state. But when traffic surges, the system will begin to develop in an unstable direction, abnormal calls will surge, and eventually it will become unavailable. For this kind of scenario, we can use the traffic control capability to reject requests that exceed capacity, or use the traffic smoothing capability to cut peaks and fill valleys, so that the traffic is in a relatively stable state and avoid service unavailability.
The second is a scenario where unstable calls lead to service unavailability. For example, when we call some third-party services, instability often occurs. The instability here mainly refers to exceptions. Or slow call. Taking Dubbo as an example, when the service provider makes slow calls, it will cause the threads of the service consumer to accumulate, affecting other normal calls and even the stability of the entire service, and this risk will be passed in the reverse direction along the call chain. , diffusion ultimately affects the stability of the entire system. At this time, we can use concurrency control or circuit breaker protection to limit the resource usage of slow calls and ensure the overall stability of the system.

OpenSergo has also developed relevant CRDs for the scenarios mentioned above. In industry practice, Sentinel is a mature traffic protection solution. A large number of traffic protection-related scenarios and practices have been accumulated within Alibaba. After being open sourced in 2018, these accumulations have been further enriched in the industry. From these accumulations, we have abstracted a Specification standards for flow protection.
So you can briefly think about what a traffic protection rule should contain.
First of all, we need to determine what kind of traffic we want to target. We can divide it by interface or by characteristics in the request. After determining the goals, we need to define what governance strategy to adopt. The strategies here include the strategies just mentioned, as well as higher-level strategies such as self-overload protection.
Finally, since the current limit itself is lossy, but we don't want this loss to be passed to the user side, so we need to configure different behaviors for different rules, so that the performance on the user side is relatively friendly, such as the most basic For the current limit in the rush buying scene, we can return to a queue, please give us a reminder later.
The right side of the figure above is an example of a CRD. The traffic target is a request with the interface name /foo, the policy is global traffic restriction with a threshold of 10, and the fallback is a specific return body.
Through such CRD configuration, whether it is the Dubbo framework or other frameworks, we can easily use the traffic protection capability.
OpenSergo&Dubbo best practices
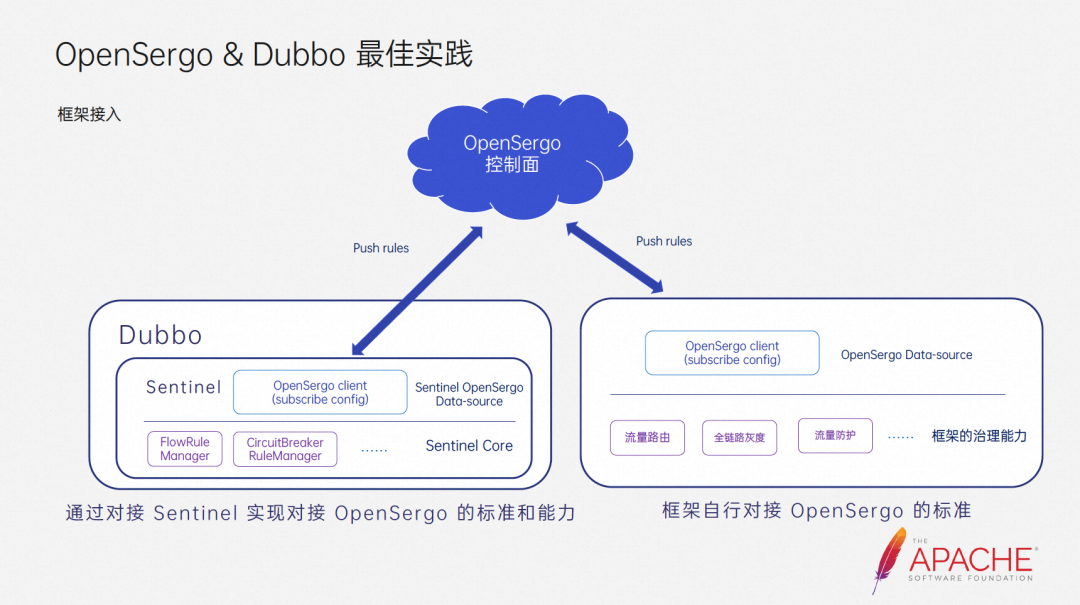
For framework developers, there are actually two ways to connect to the OpenSergo system:
One is to connect to the data plane of the OpenSergo system. Framework developers only need to implement the adaptation module to connect to Sentinel to complete the docking work. For frameworks with special requirements or that are closer to specific scenarios, you can also connect to the OpenSergo system by connecting to OpenSergo standards.
For users, no matter which method is used, they only need to simply introduce some dependencies, and they can seamlessly obtain the microservice governance capabilities defined by OpenSergo, and can control the microservice governance capabilities of these frameworks on a unified control plane. , greatly improving the experience and efficiency of using microservice governance. After talking about the access method, let’s take a look at the implementation effect.
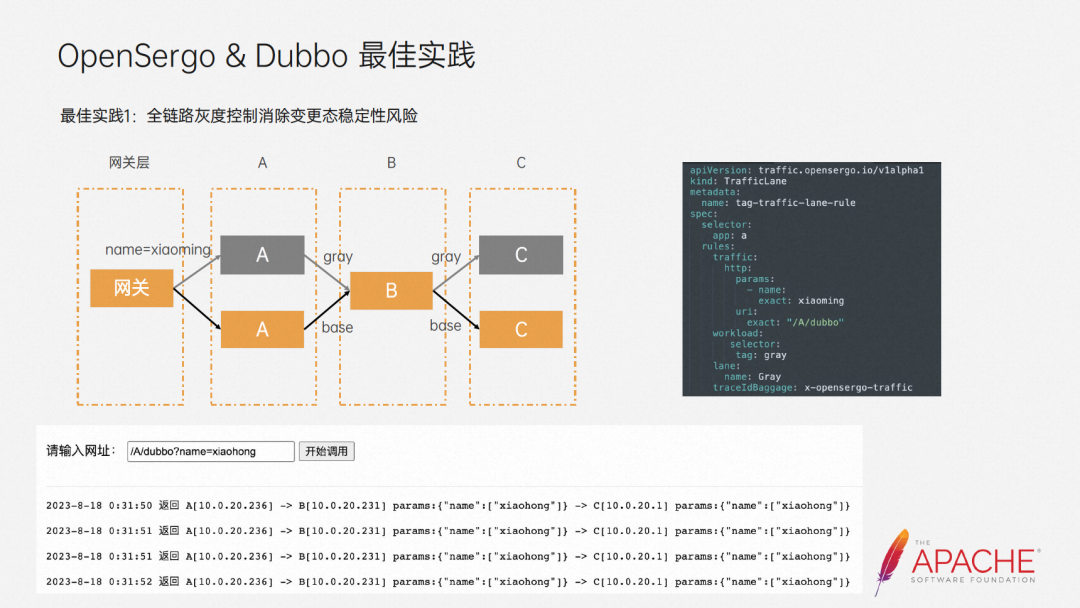
The first practice is full-link grayscale control to eliminate the risk of changing state stability. This is a simple demo. We only need to deploy such a CRD and define the request for /A/dubbo. When name=xiaoming appears in its parameters, we will direct it In the grayscale environment, for traffic that does not meet the requirements, we still use the baseline environment. We can see that the current request trend is in line with our expectations.
But our production environment will be much more complicated than the demo, and will involve various frameworks, such as RokcetMQ and spring cloud alibabab. But as long as these frameworks are connected to the Opensergo system, this CRD can be used to achieve full-link, full-frame grayscale.
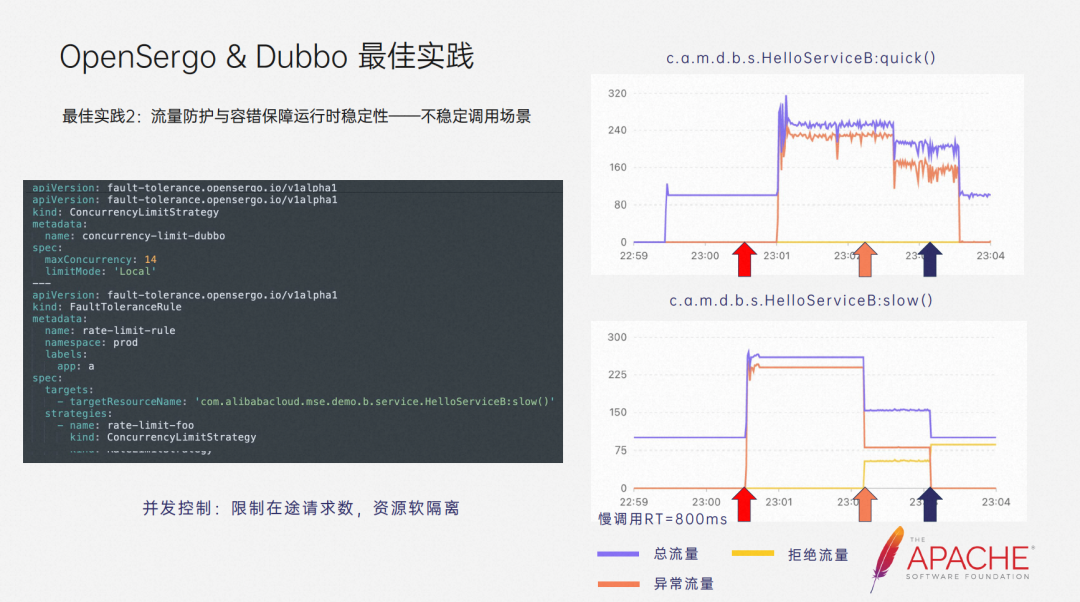
The second practice is traffic protection and fault tolerance to ensure runtime stability - unstable calling scenarios. A simple Demo is used here. Application A calls application B through Dubbo. On the right is a traffic diagram of a normal interface and a slow-calling interface. The purple one is the total traffic, the yellow one is the rejected traffic, and the orange one is the abnormal traffic.
At the beginning, slow calls have not occurred yet, the system is in a steady state, and there is no abnormal traffic. At the first point in time, I manually adjusted the RT of the slow call interface. Slow calls occurred and abnormal traffic occurred. At the same time, because the slow calls occupied a large amount of Dubbo's thread resources, normal calling resources were occupied, and a large number of Abnormal traffic and thread pool depletion exceptions also occurred on the Dubbo side.
You can think about what rules we should configure to solve this problem in this scenario. In fact, many people will want flow control to limit the current at this time, hoping to solve this problem. Let's take a look at one of its effects.
At the second time, I configured a current limiting rule. It can be seen that although the situation has been alleviated, there are still a large number of errors. This is because in the slow call scenario, requests have accumulated, and only QPS current limiting will still cause The influx of requests piled further.
So what we really need is concurrency control. At the third point in time, I configure concurrency control rules to limit the concurrency number of the slow call interface, which is the number of requests being processed. It can be seen that through this restriction, even if the slow call still exists, the thread resources it can occupy are limited, and the normal interface can be called normally, thereby avoiding the expansion of stability risks and ensuring the stability of the application.
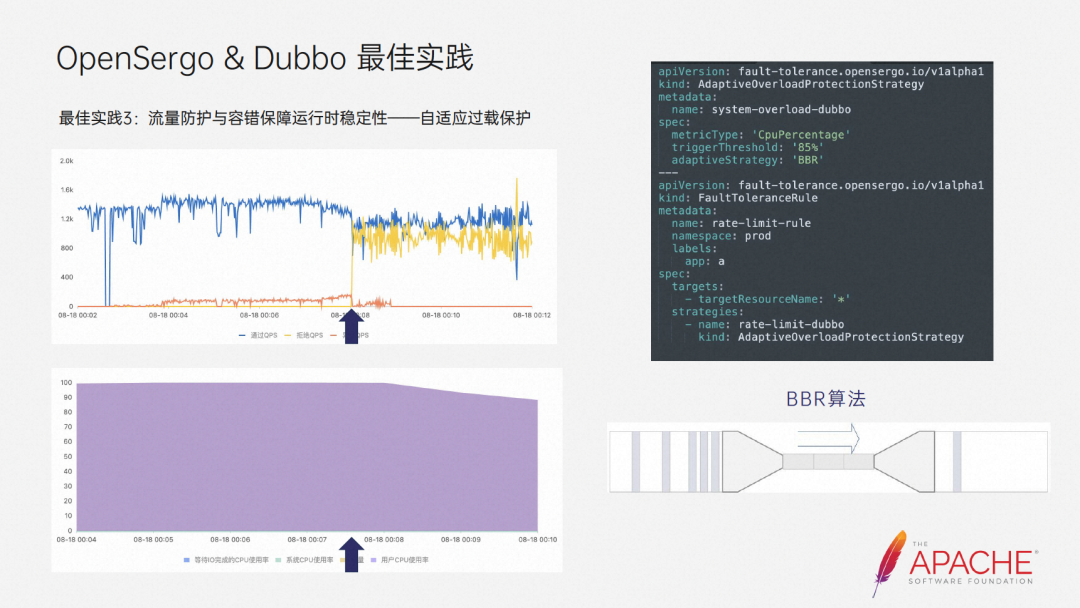
The third practice is traffic protection and fault tolerance to ensure runtime stability - adaptive overload protection. We can see that under continuous high load in our demo, abnormal traffic began to gradually increase, and the stability of the system was destroyed. At this time, we can configure adaptive overload protection rules to adaptively Adjust the current limiting behavior to eliminate abnormal requests and help the system return to a steady state.
The current strategy is that we already support BBR in open source, and we also use PID in internal practice. I will not introduce these strategies in detail here. If you are interested, you can go to our open source community to participate in the discussion.
From these three examples, we can see that after Dubbo connects to the OpenSergo system through docking with Sentinel, it seamlessly possesses the general governance capabilities defined by OpenSergo, and can be managed and controlled through a unified control plane.
The same is true for other frameworks. You can imagine that if all the frameworks involved in our production are connected to the OpenSergo system, then we can control all services on one control plane, and the microservice governance capabilities of all frameworks can be better guaranteed. System stability.
The future of OpenSergo
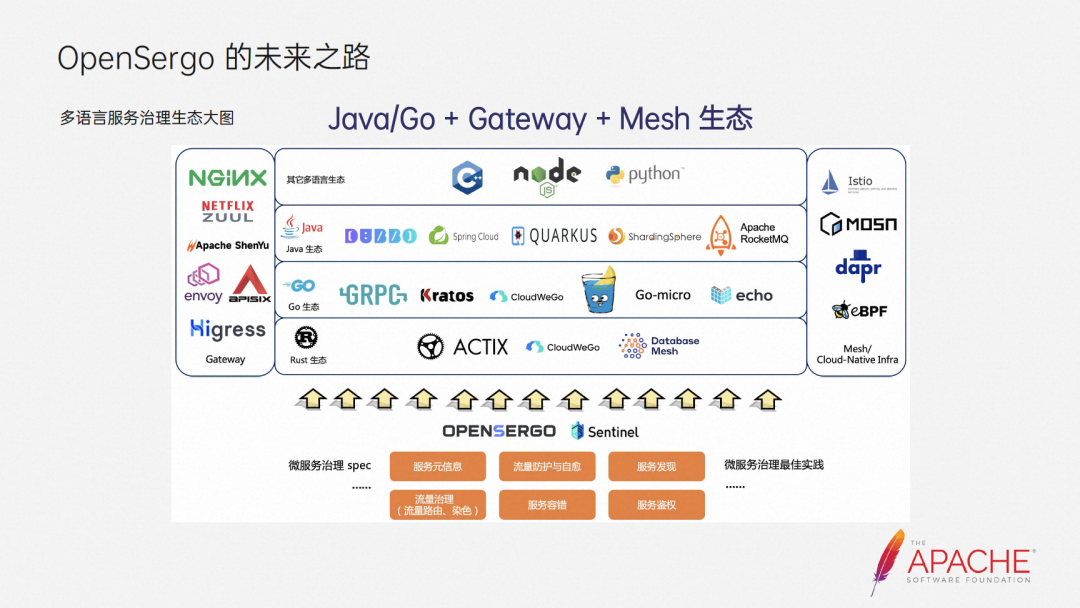
This is the ecological picture of multi-language service governance. In terms of ecology, we hope that OpenSergo will be full-link multi-language isomerization. We will mainly focus on the Java/Go + Gateway + Mesh ecology and continue to cover more frameworks in terms of ecology.
In terms of capabilities, we will continue to abstract and implement more general microservice governance capabilities. Including traffic protection, self-healing, service fault tolerance, service authentication, etc.
At present, we have established contacts and cooperation with many communities, such as Dubbo, ShenYu, APISIX, Higress, RocketMQ, MOSN, etc., and many of them have made some substantial progress.

Next, let’s share our recent plans.
- In terms of control plane, we will gradually promote the production availability of the control plane and release the GA version in March next year, so that everyone can verify the microservice governance system in production.
- In terms of Spec, we will support microservice security governance, outlier instance removal, and continue to integrate with community standards.
- In terms of the evolution of governance capabilities, we will focus on completing the upgrade of Sentinel 2.0 traffic governance and explore in the direction of security and adaptability.
- In terms of community cooperation, we will continue to promote communication and cooperation with the community, promote the ecological implementation of various microservice governance areas, and unify the control plane and co-build Spec.
Although Alibaba has accumulated a lot of experience and scenarios in the group and the cloud, the issue of stability is complex and the scenarios are diverse. One party alone is not enough to cover all stability scenarios, nor is it enough to become a standard, so microservices The evolution of governance technology, ecology and standardization also requires the joint participation of various enterprises and communities.
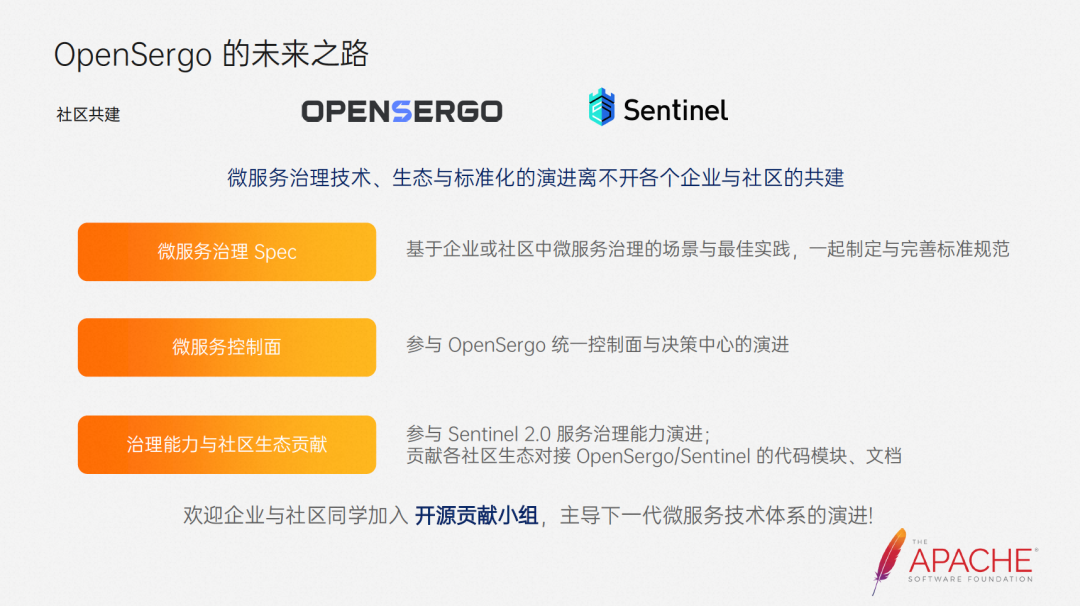
You can start from the following three aspects to participate in the community.
- Regarding the spec of microservice governance, each community and enterprise is a leader in their respective fields. Everyone can work together to formulate and improve standards based on their own scenarios and best practices.
- The evolution of the unified control plane of microservices actually has many possibilities. As a control plane, it is actually in the position of a decision-maker. It has a God's perspective of the entire system to a certain extent. It has a lot to do now that AI technology is booming.
- As for the contribution of governance capabilities and community ecology, everyone can participate in the evolution of service governance capabilities, and can also contribute to the connection between various communities and the OpenSergo system.
Finally, I would like to say that microservice governance is actually a very broad platform. By participating in it, you can be exposed to technologies and scenarios in various fields, instead of being limited to a single point of technology. Enterprise and community students are welcome to join the open source contribution group and lead the evolution of the next generation microservice technology system together!
Tang Xiaoou, founder of SenseTime, passed away at the age of 55 In 2023, PHP stagnated Wi-Fi 7 will be fully available in early 2024 Debut, 5 times faster than Wi-Fi 6 Hongmeng system is about to become independent, and many universities have set up “Hongmeng classes” Zhihui Jun’s startup company refinances , the amount exceeds 600 million yuan, and the pre-money valuation is 3.5 billion yuan Quark Browser PC version starts internal testing AI code assistant is popular, and programming language rankings are all There's nothing you can do Mate 60 Pro's 5G modem and radio frequency technology are far ahead MariaDB splits SkySQL and is established as an independent company Xiaomi responds to Yu Chengdong’s “keel pivot” plagiarism statement from Huawei