Common problems and solutions when building PySpark environment
This article mainly collects some common problems and solutions when building the PySpark development environment, and collects some related resources.
1. winutils.exe problem
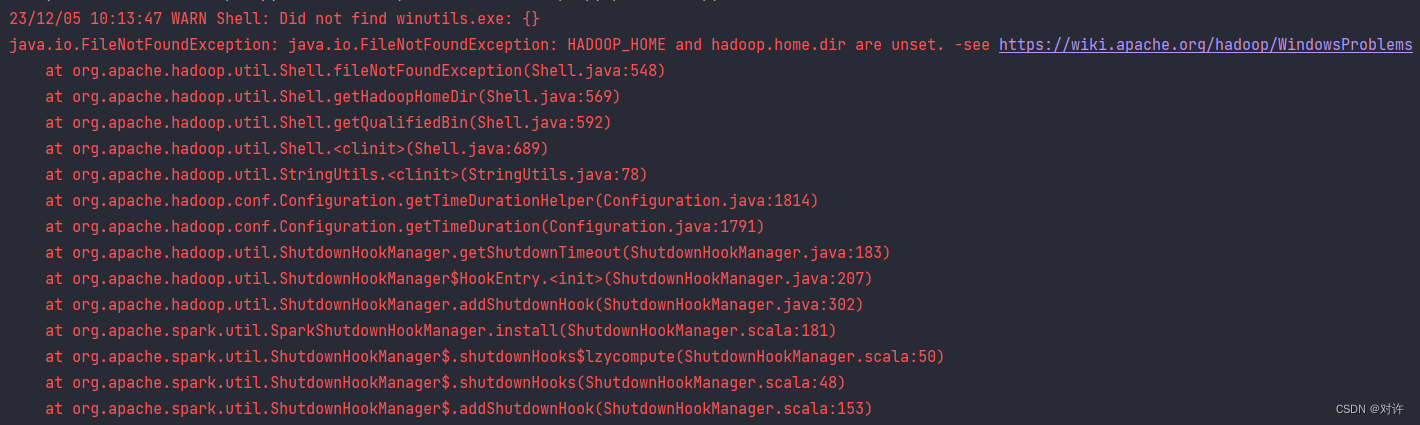
Error summary:
WARN Shell: Did not find winutils.exe: {
}
java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset.
......
Reason 1: Lack of Windows support environment for Hadoop: hadoop.dll and winutils.exe
See the official website for details:https://cwiki.apache.org/confluence/display/hadoop/WindowsProblems
Cause 2: hadoop.dll and winutils.exe have been downloaded, and environment variables have been configured, but and have been downloaded. a> directory (restart the computer to take effect) is optional) copy the file to the hadoop.dll (winutils.exeC:\Windows\System32
Solution: Download the Windows support environment for Hadoop: hadoop.dll and winutils.exe, configure the environment variables, and set < /span> directory and restart the computerhadoop.dllCopy the file to theC:\Windows\System32
PS: The download links for each version of hadoop.dll and winutils.exe are in the appendix at the end of the article
2. SparkURL problem
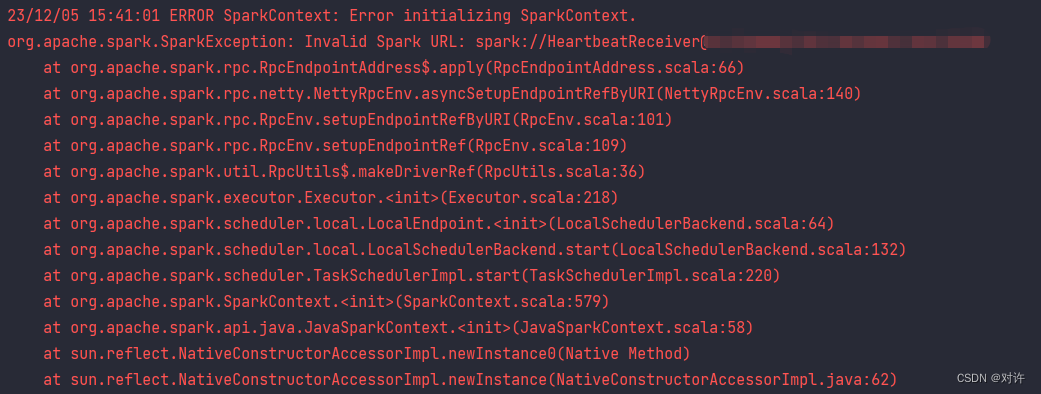
Error summary:
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
23/12/05 14:50:09 ERROR SparkContext: Error initializing SparkContext.
org.apache.spark.SparkException: Invalid Spark URL: spark://HeartbeatReceiver@***
......
Cause: The host name is underlined_ or dot.caused
solve:
Method 1: Add configuration:spark.driver.host=localhost
Method 2: Modify the local hosts file: add host name and IP mapping:
主机名 127.0.0.1
Then add configuration:spark.driver.bindAddress=127.0.0.1
Spark attribute configuration official document:https://spark.apache.org/docs/3.1.2/configuration.html
3. set_ugi() problem
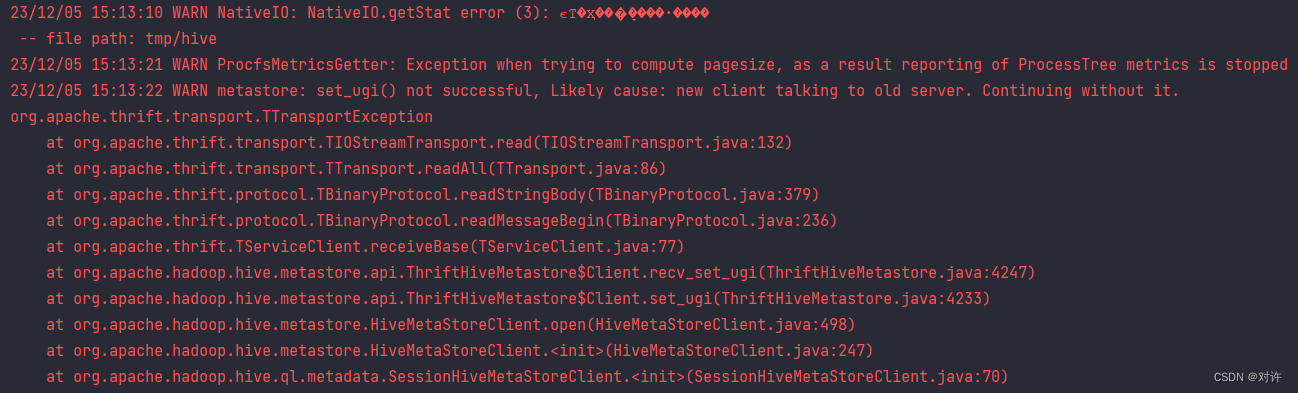
Error summary:
23/12/05 15:13:10 WARN NativeIO: NativeIO.getStat error (3): ϵͳ�Ҳ���ָ����·����
-- file path: tmp/hive
23/12/05 15:13:21 WARN ProcfsMetricsGetter: Exception when trying to compute pagesize, as a result reporting of ProcessTree metrics is stopped
23/12/05 15:13:22 WARN metastore: set_ugi() not successful, Likely cause: new client talking to old server. Continuing without it.
org.apache.thrift.transport.TTransportException
......
Possible reasons: Permission issues, version issues
Solution: First configure blocking:spark.executor.processTreeMetrics.enabled=false, then try the following:
Method 1: Modifyhdfs-site.xml
# 在集群服务器的hdfs-site.xml文件中添加跳过权限验证
# 注意修改配置前先停止集群,配置结束之后,重启集群即可。经测试只需要修改NameNode上的配置文件即可
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
Method 2: Modifyhive-site.xml
# 新客户端与旧服务器通信,hive-site.xml与服务器不同步
# 在hive-site.xml中添加以下内容:
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
For reference on version issues:https://cloud.tencent.com/developer/ask/sof/1059191
Reference for other related questions:https://forum.mirrorship.cn/t/topic/4921
================== Appendix Resources ==================
Download versions of hadoop.dll and winutils.exe:https://github.com/cdarlint/winutils/tree/master/ hadoop-3.1.2
Hadoop各版本下载:https://archive.apache.org/dist/hadoop/common/
Spark各版本下载:http://archive.apache.org/dist/spark/