★Deep learning; pattern recognition; image processing; artificial intelligence modeling; artificial intelligence; deep learning algorithm; reinforcement learning; neural network; convolutional neural network; artificial neural network; VIBE algorithm; control system simulation; machine learning; high performance computing ;Data mining; Supercomputing; ACL; Computing power; Computer vision; PSU; Transformer; PLM; SLM; NLM; LLM; Galactica; OPT; OPT-IML; BLOOM; BLOOMZ; GLM; Reddit; H100; H800; A100; A800 ; MI200; MI250; LaMA; OpenAI; GQA; RMSNorm; SFT; RTX 4090; A6000; AIGC; CHATGLM; LLVM; LLMs; GLM; AGI; HPC; GPU; CPU; CPU+GPU; Nvidia; Nvidia; Intel; AMD; High-performance server; blue ocean brain; diverse heterogeneous computing power; large model training; general artificial intelligence; GPU server; GPU cluster; large model training GPU cluster; large language model; generative AI; ML; DLC; image segmentation; pre-training Language model; AI server; GH200; L40S; HBM3e; Grace Hopper; gracehopper; heterogeneous computing; cluster; cluster management; resource management system
With the large-scale application of artificial intelligence in industry and academia, the need for deep learning training is increasingly urgent. Various organizations invest a lot of money to purchase and build heterogeneous computing clusters equipped with GPUs and InfiniBand network cards. The cluster management system (also called the platform) supports model training, provides job, data and model management, and provides resource isolation. The resource management system is the foundation of the deep learning system. In enterprise-level scenarios, upper-layer frameworks and applications usually run on the resources provided by the resource management system.
The main driving force for heterogeneous computing comes from the development trend of dark silicon and heterogeneous hardware. Data center hardware is increasingly diversified, and users use the hardware in a multi-tenant and shared manner. Therefore, the need for unified management gradually emerged. In order to manage heterogeneous computing and storage hardware, it is usually necessary to abstract and manage them in a unified space, ultimately enabling users to use the hardware transparently. The heterogeneous computing cluster scheduling and resource management system is similar to a traditional operating system in an artificial intelligence system. It abstracts the underlying heterogeneous resources (such as GPU, CPU, etc.), schedules deep learning jobs and allocates resources. After starting a job, resource isolation, environment isolation and job life cycle management need to be performed.
Introduction to heterogeneous computing cluster management system
The heterogeneous computing cluster management system is a system software that is responsible for managing the hardware (such as GPU, CPU, memory, disk, etc.) and software resources (such as frameworks, jobs, mirrors, etc.) of multiple nodes in the computer cluster, and provides computer Programs (usually deep learning training jobs) provide common services (such as job submission, debugging, monitoring, cloning, etc.). In short, the heterogeneous computing cluster management system is a system software that manages and optimizes hardware and software resources within a computer cluster, aiming to provide universal services for deep learning training.
1. Training operations running in multi-tenant environment
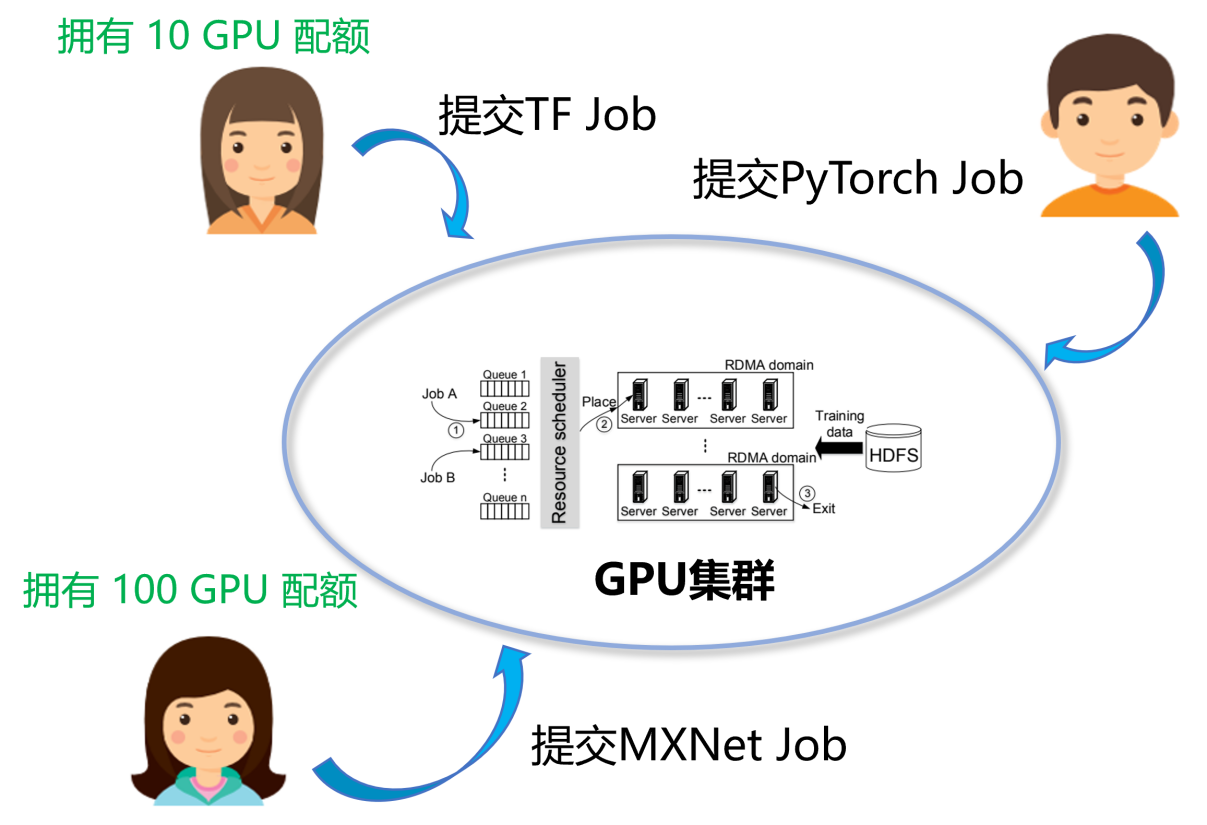
Submit running jobs in multi-tenant environment
In enterprise-level deep learning scenarios, large enterprises usually have many machine learning scientists and engineers and have a large number of GPU servers. In order to improve efficiency and resource sharing, multi-tenant platform systems designed for deep learning scenarios are highly favored. As shown in the figure above, in an enterprise environment, different users will submit deep learning jobs of different frameworks (such as PyTorch, TensorFlow, etc.), with different resource requirements (such as single GPU card, multiple GPU cards), and share a physical cluster to reduce Waste of hardware resources.
In the current deep learning scenario, the resources managed by the platform system are heterogeneous (such as CPU, GPU, etc.). Compared with deep learning developers using exclusive servers for model training, there is a big difference between multi-user sharing of multi-GPU servers. This also brings corresponding requirements for the design of heterogeneous computing cluster management systems (referred to as platforms or deep learning platforms), which are mainly reflected in the following aspects:
1. Multiple jobs (Jobs) and multiple users
1) Each user submits a large number of jobs to the platform for continuous model improvement, hyperparameter tuning, debugging and optimization jobs.
2) Different artificial intelligence teams (such as computer vision, natural language processing, speech recognition, etc.) use the platform. Many engineers from each team will apply for resources from the platform to perform tasks within the same time period.
2. Diverse working environment needs
The current deep learning technology stack is not unified enough, and different users may use different frameworks and libraries, such as TensorFlow, PyTorch, Hugging Face, etc. Users may use open source projects, some of which are older and some of which use the latest frameworks. Users do not want to perform version adaptation frequently. In addition, the versions of open source frameworks may also be inconsistent, resulting in different versions of underlying dependencies such as NVIDIA CUDA. In the case of shared machines, you need to ensure that the environments are independent of each other and not affected by versions of Python, PyTorch, etc. installed by other users.
3. Diverse operational resource requirements
Deep learning jobs submitted by users include distributed training jobs, single-machine training or debugging tasks, and large-scale distributed training tasks. These jobs vary in the amount of resources they require, with some requiring more resources and others requiring fewer resources. Even if the number of GPUs requested is the same, different jobs and models will lead to differences in resource utilization. The platform needs to allocate resources on demand to reduce resource fragmentation. Users expect jobs to run as if they were using exclusive resources, without being interfered by resource and namespace conflicts from other jobs, so that model training can be completed as quickly as possible. The platform needs to implement resource isolation during job running to ensure service quality.
4. Single server software environment
When purchasing and deploying resources, it is difficult for the platform to predict and plan users' future software and version needs. This is mainly because users use a variety of frameworks and libraries, and the versions are also different. In order to simplify operation and maintenance, the platform usually unifies the operating system and driver and keeps the versions consistent to reduce compatibility issues. But this is in conflict with the diverse environmental needs of users. Even if different systems and environments are deployed, it is difficult to accurately adapt to the changing needs of users.
5. Diverse server idle resource combinations
Although the platform purchases machines of the same model in batches, due to different resource application and job life cycles by users, the platform's idle resource combinations after resource release are very diverse. Scheduling strategies need to be designed to improve resource utilization.
It can be seen from the above problems that a unified platform system is needed to support scheduling and resource management. It abstracts and manages computing resources at the bottom layer, and provides an isolated and easy-to-use job running environment for applications at the upper layer. In short, it is an operating system that supports deep learning applications and manages distributed GPU server clusters.
2. Job life cycle
Before expanding on the platform components and functions, let’s first understand how deep learning jobs (the job life cycle) are submitted and executed on the platform.
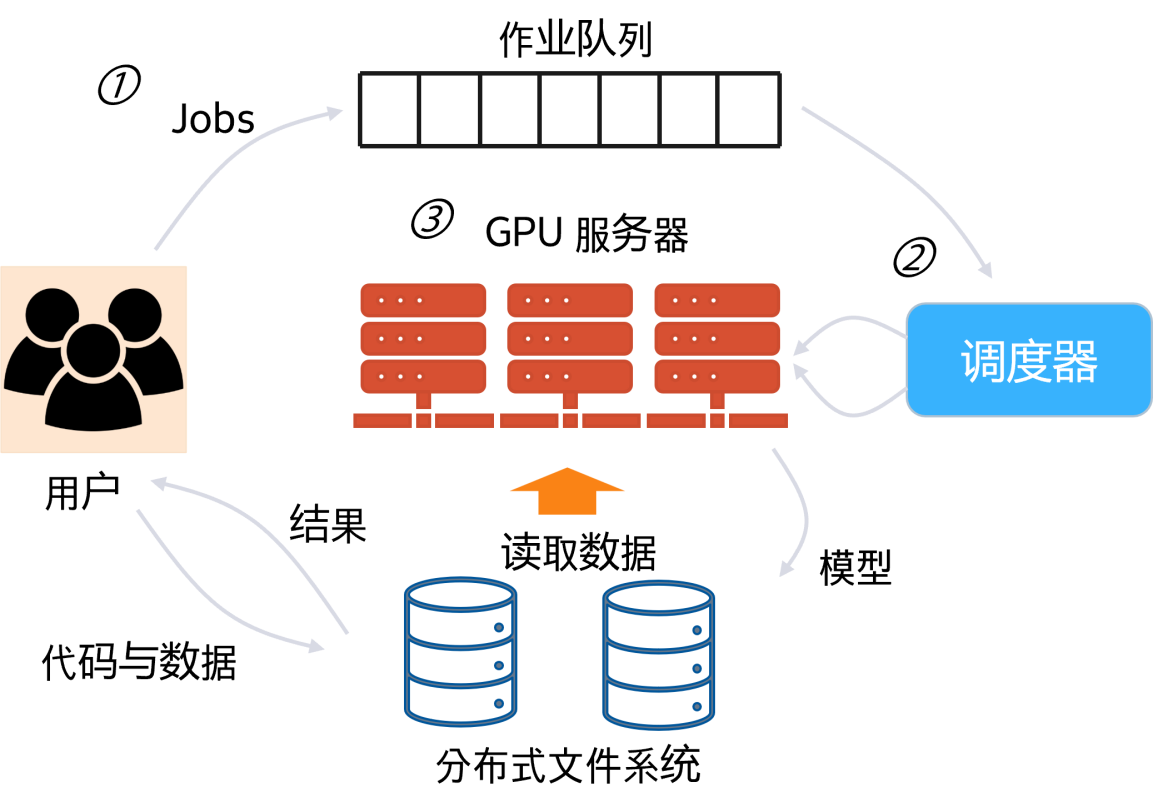
GPU cluster
1. Job life cycle on the platform
1) Job submission and queuing
Users first test the job-dependent environment locally, package it as an image, and then upload it to the public image center. Next, upload the code and data to the file system of the platform. Afterwards, fill in information such as resource application, startup command, deployment method, image, code and data path through submission tools (such as Web, command line, API) (resource requirements and queuing time need to be weighed when submitting).
2) Job resource allocation and scheduling
After receiving the resource request, the platform will queue it up and wait for polling by the scheduler. When the scheduler polls for the job, it will decide to start the job on the nodes with idle resources based on the idle resource status of the cluster and the scheduling algorithm. If the job's resource requirements cannot be met, the job will continue to be queued. If the job submission fails or times out, the user needs to adjust the job information and resubmit.
3) Job execution completion and release
After the job is scheduled, the platform will start the job on a node with idle resources, download the image, mount code and data, limit and isolate resources, and then start execution. The platform collects operational metrics and logs during execution for debugging. After the job is completed, the platform releases the resources and continues to allocate them to other jobs.
2. The status of the job on the platform can be abstracted into the following state machine
1) Job preparation and submission: trigger job submission action
●Submission successful
●Submission failed: restart submission
2) Job queuing: trigger job scheduling action
●Scheduling successful
●Scheduling failure: restart submission
3)Job deployment and running: trigger job execution action
●Execution successful
●Job failed, retry count <=N: Restart submission
●Job failed, retry count > N: Job failed and exited
The user's operation is actually to continuously switch between these states, eventually reaching the successful execution or failure of the job. If the execution is successful, the user can obtain the results and model upon completion.
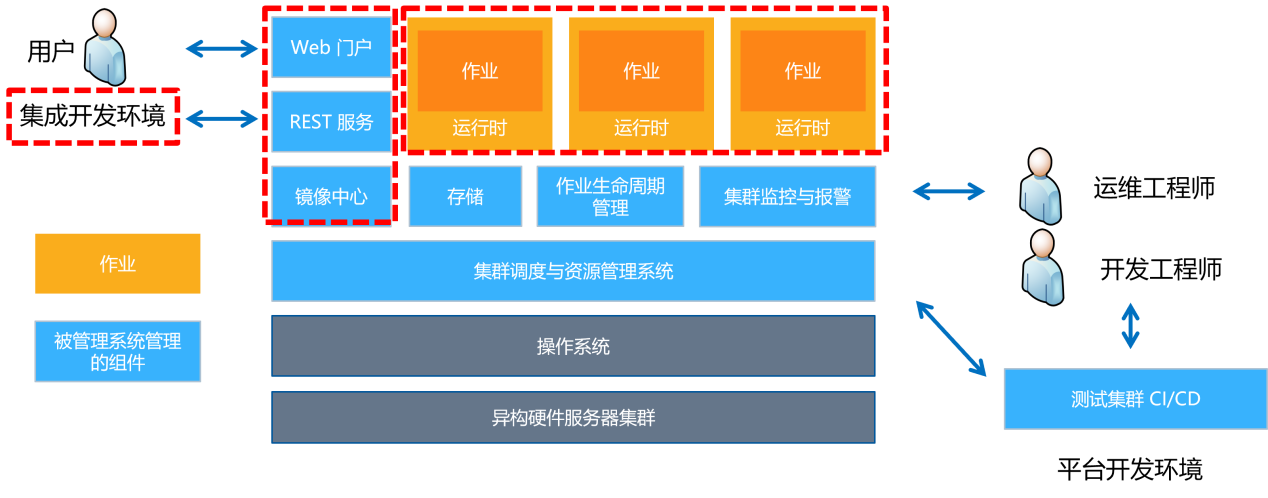
3. Cluster management system architecture
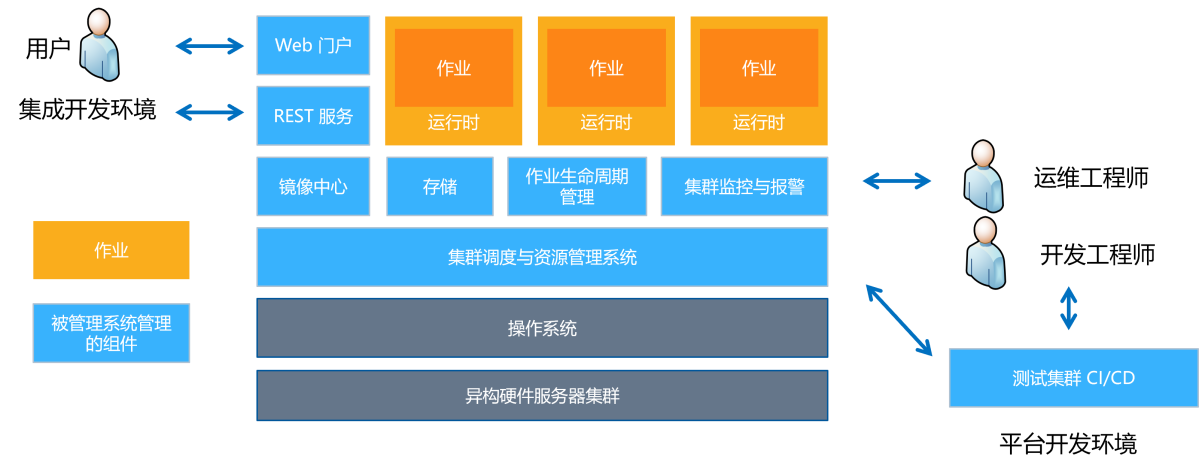
Heterogeneous cluster management system architecture
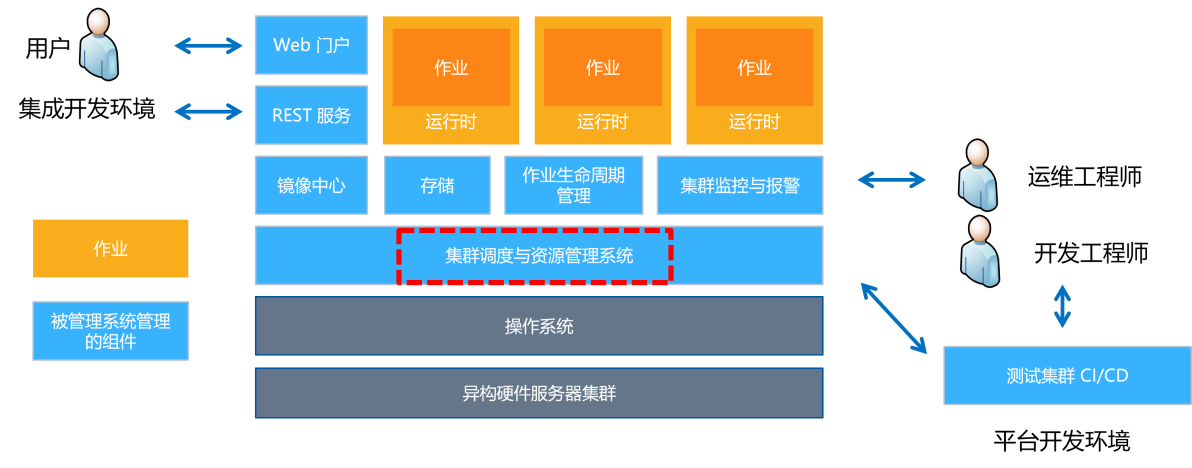
Heterogeneous cluster management systems often contain multiple components. Among them, the scheduler is responsible for the management of resources and jobs, the monitoring system is responsible for monitoring the health status of the system and issuing alarms, the web interface provides a user interaction interface, and the storage system is used to store data, models and codes.
1. The main components of the platform include
1) Cluster scheduling and resource management module
Manage cluster resources in a unified manner, schedule jobs to idle resources, and recycle resources for completed jobs. The control plane can choose Kubernetes, Mesos and other systems, or use a customized scheduler for deep learning jobs.
2) Mirror center
Store Docker images for users to submit and share images, and jobs to download images. You can use public centers such as Docker Hub, or you can build a private center or use a cloud mirror center.
3) Storage module
Plays the role of data plane, storing data, models and code. User upload and job download data.
4) Job life cycle manager
Deployment, monitoring, retrying jobs, and diagnosing errors are tasks involved in the control plane of a single job. On this plane, automatic machine learning systems can be built without the need to consider other tasks. Based on the platform interface, you can choose to use tools such as K8S Operator, Framework Controller or YARN AppMaster to implement these functions.
5) Cluster monitoring and alarming
Monitoring hardware, service and job status and issuing alarms is an important task of the monitoring system. In this process, you can choose to use open source systems such as Prometheus, Grafana, and AlertManager to implement monitoring and alarm functions. Additionally, custom monitoring metrics can be developed to meet specific needs.
6) Integrated development environment
Provide users with web portals, REST APIs, IDEs (such as VS Code, Jupyter Notebook), etc. for job submission, management, monitoring and debugging.
7) Test cluster
To isolate the production environment, a small-scale test cluster can be deployed for development and testing.
2. Platform deployment mode
1) Local deployment
Due to data compliance and other requirements, some companies choose to use open source platforms or self-developed platforms for local deployment to ensure that data and mirrors are in their own data centers, which places higher requirements on operation and maintenance and development engineers. You need to build your own data center or deploy it on existing infrastructure. The initial investment is large and resource planning is required. A full-time operation and maintenance team is required to maintain software, monitoring, etc., and custom development capabilities for platform service software are required. Hardware iterates quickly and is easily obsolete after a period of time, and updates require high costs.
2) Public cloud deployment
Some companies purchase cloud IaaS or PaaS services to build platforms, reduce operation and maintenance pressure, and use the latest technology of cloud platforms to achieve elastic expansion and contraction. However, data and code need to be uploaded to the cloud, which has high long-term costs. The initial investment is small, you pay based on usage, and most operations and maintenance are completed by the cloud provider, making it suitable for initial use. However, some companies cannot fully migrate to the cloud due to data compliance. Costs may become unaffordable as scale increases.
3) Hybrid cloud
Some companies adopt a solution where sensitive data is stored locally and non-sensitive data and elastic resources are stored in the cloud.
4) Cloudy
Some companies will adopt multi-cloud solutions and tools to prevent cloud provider lock-in or comprehensive selection of cost-effectiveness.
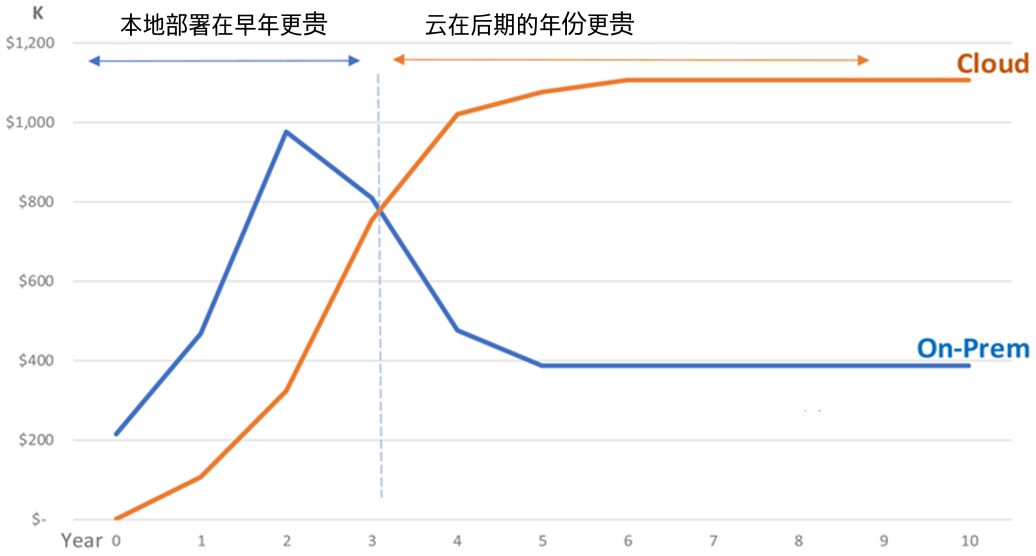
On-premises vs. cloud deployment cost trends
Training jobs, images and containers
Platform work and development experience
The cluster management system needs to share server resources among the jobs of multiple users. To solve the problems of environmental dependence and resource isolation, mechanisms such as mirroring and runtime resource isolation need to be adopted. The following will introduce the dependency isolation of jobs on the cluster management system, runtime resource isolation, and artificial intelligence job development experience.
1. Deep learning assignments
When developing a training model on a local machine or dedicated server, environmental issues are fewer and more challenges are not exposed. The situation of exclusive environment is as follows:
●No need to consider dependency environment and resource isolation issues
●The Python environment dependency path is local and isolated through the package manager or environment variables
●GPU environment dependency path is fixed locally and switched through environment variables
●Data is uploaded directly to the local disk with high bandwidth
●Execute the startup script directly on the disk, making modification and debugging easy
If the environment is ready, training can be started through the following script:
python train.py --batch_size=256 --model_name=resnet50
{
//Job name
"jobName": "resnet",
//Image name
"image": "example.tensorflow:stable",
//Input data storage path
"dataDir": "/tmp/data",
//Data result storage path
"outputDir": "/tmp/output",
...
//Task specifications: resource requirements, startup scripts, etc.
"taskRoles": [
{ ... "taskNumber": 1, "cpuNumber": 8, "memoryMB": 32768, "gpuNumber": 1, "command": "python train.py --batch_size=256 --model_name=resnet50" }
]
}
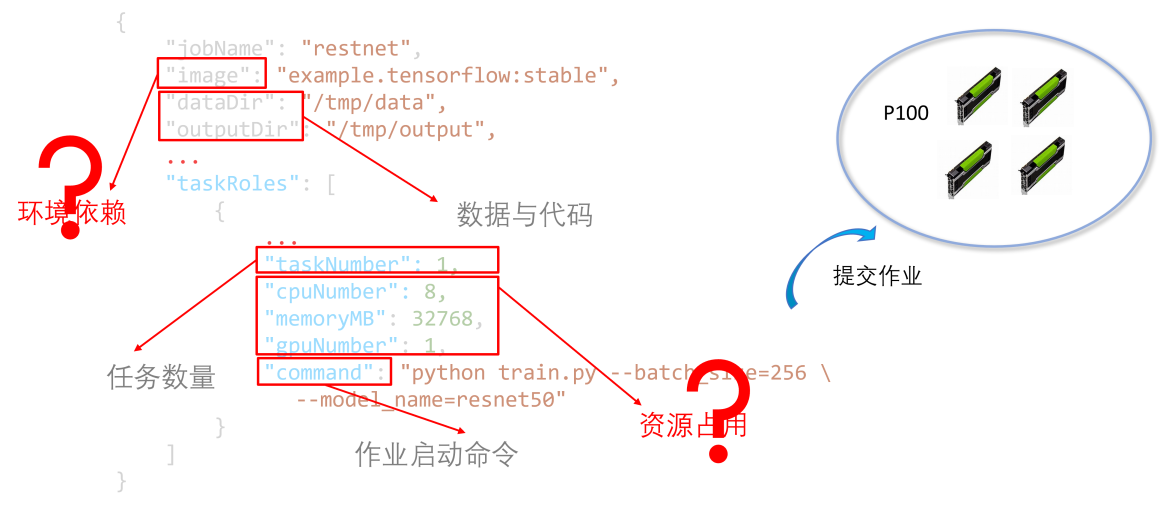
As can be seen from the job submission specification example, when a user submits a job to a server with 4 GPUs, the platform needs to provide the following support:
1. Environmental dependence
1) Question
The machine systems and environments in the platform cluster are all the same. How to support users to use different deep learning frameworks (such as TensorFlow and PyTorch), libraries and versions?
2) Solution
Solve the environment dependency problem by specifying the "image" mirror name. Users need to package and build dependencies into Docker images in advance and submit them to the designated image center for job downloading.
2. Data and code
1) Question
Deep learning training jobs are run on the platform, and each job requires input data and code. Data and code cannot be reused if uploading directly to the server would cause excessive load.
2) Solution
Process the input data and output results of the job by specifying the "dataDir" and "outputDir" paths. Users upload data and code in advance to the file system path specified by the platform. In the future, the platform will mount the data and code in the network file system to the machine running the job.
3. Resource application volume
1) Question
Users submit single-GPU, multi-GPU or distributed jobs, and the platform cannot statically analyze job resource requirements. Failure to explicitly configure them will lead to resource waste or shortage.
2) Solution
Users clearly declare the required GPU, CPU and memory resources, and the platform allocates matching idle resources according to policies.
4. Resource isolation
1) Question
When running multiple jobs on the same server, how to avoid interference between jobs?
2) Solution
The platform can limit resources and isolate processes through technologies such as container cgroups.
5. Task deployment mode
1) Question
For distributed jobs, if the user does not specify it, the platform cannot know the number of tasks that need to be started.
2) Solution
The user clearly informs the number of tasks that need to be started, and the platform starts multiple task copies for training.
6. Job start command
1) Question
The platform needs to know the job's launch command to launch and execute the code.
2) Solution
The user clearly describes the startup entry command in the job to start and execute the code.
2. Environmental dependencies: Image (Image)
When users execute jobs on the platform, the first issue is the difference between the local environment and the cluster environment:
●The server does not have the required personalized environment pre-installed
●Different jobs require different frameworks, dependencies and versions, making installation cumbersome and repetitive.
●There are a large number of repeatedly installed libraries on the server, taking up space.
●Special issues with deep learning: CUDA, frameworks, etc. need to be installed
The platform needs to adopt the following technical solutions to solve:
Use mirrors to isolate the overall environment and create new environments on top of it, and reuse each level in a hierarchical way. This method not only ensures a personalized environment, but also ensures minimal performance and resource consumption. This method mainly relies on mainstream platforms to implement Docker images, and Docker images achieve efficient storage through mechanisms such as the Union file system.
The Union file system jointly mounts multiple directories to form a merged view, and Docker takes advantage of this mechanism to store files and packages more efficiently. Docker supports multiple Unionfs, such as the lower-level AUFS and the upper-level OverlayFS.
The following will use an example to understand, build and use the image. The Dockerfile written by the user can build and package the image through the commands in it. After the build is successful, it can be uploaded to the image center. When starting a job, the platform downloads the image to the server and uses it to configure the job environment.
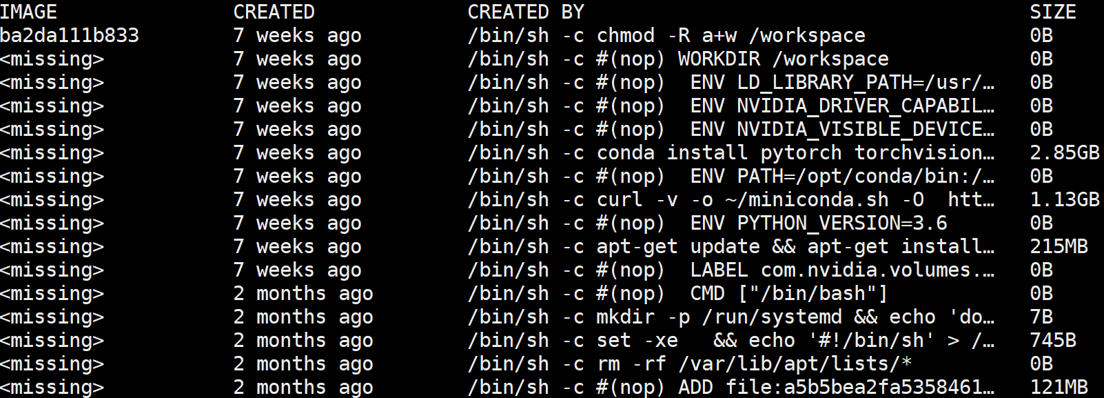
Dependencies included in the PyTorch image file
3. Runtime resource isolation: containers
When users execute jobs on the platform, how to avoid resource contention interference between jobs and achieve resource isolation:
●Cluster resources are shared. How to ensure that job processes do not interfere with each other and seize resources?
●How to let different jobs run on the same machine in independent namespaces to avoid conflicts?
●How to start jobs as quickly as possible while ensuring isolation?
●Special problem of deep learning: How to isolate the core and memory of GPU?
●Platforms usually use container technology to solve runtime resource isolation. Containers mainly achieve resource isolation through two mechanisms:
Control group Cgroups: can control, count and isolate the resources of a group of processes (such as CPU, memory, etc.).
Namespaces: Wrap system resources in abstractions so that processes in each namespace have independent resources to achieve namespace isolation.
Since deep learning currently relies on GPUs for training, in order for containers to support mounting GPUs, GPU manufacturers usually provide special support for Docker. For example, NVIDIA provides nvidia-docker. Users can refer to its documentation for environment configuration.
However, because the virtualization support of accelerators such as GPUs is not as mature as that of CPUs, the current mainstream method is to mount and isolate accelerators at the granularity of accelerators, which cannot perform fine-grained time division multiplexing, memory isolation and dynamic migration like CPUs.
After the environment configuration is completed, users can run containers with a specific number of GPUs mounted. For example, mount 2 GPUs in the container through the following NVIDIA Docker command:
nvidia-docker run --gpus 2 --rm nvidia/cuda nvidia-smi This command will start a container and mount 2 GPUs into the container. These 2 GPUs can be seen in the container.
4. Looking at the GPU technology stack from an operating system perspective
The operating system is usually responsible for resource management and multi-task scheduling of processes. In computers, the GPU is abstracted as a device, and the operating system controls the device through ioctl system calls. There are two main ideas trying to incorporate GPU technology into the management of the operating system and provide support for multi-tenancy, virtualization and other functions:
1. Modify the kernel
Integrate GPU device drivers and scheduling logic into the kernel, and implement GPU virtualization and scheduling by extending the kernel. However, this method requires modifying the kernel, which is costly.
2. Implement resource management components in user space
Provides scheduling and virtualization support through encapsulated kernel interfaces. This method is more compatible and easier to iterate. There have been some related works that have implemented user-level GPU virtualization management.
The purpose of incorporating the GPU into the unified resource management of the operating system is to enable the GPU to be multi-task scheduled like the CPU, which is the basis for realizing GPU multi-tenancy and automated management.
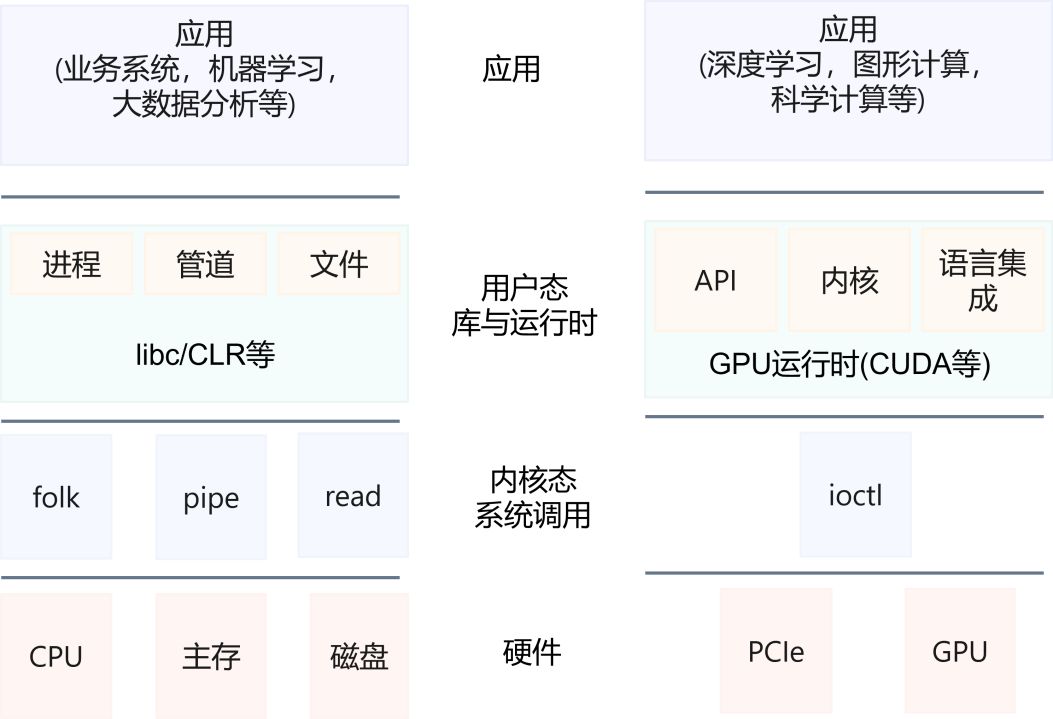
CPU and GPU technology stacks and operating system abstractions
As can be seen from the figure, the operating system can provide a large number of system call support for CPU programs, and can also abstractly manage various hardware and support users' multi-process and multi-tenancy. However, in the case of GPU programs, the current model is more like an abstraction between the client and the server. The GPU is regarded as a device, and the CPU program submits jobs to the GPU and obtains response results from it. However, the operating system's operation of the GPU itself can usually only be achieved through limited interaction and control. The commonly used interaction method is ioctl.
5. Artificial Intelligence Job Development Experience (Development Experience)
When using a cluster management system, artificial intelligence algorithm engineers usually use the following tools to develop artificial intelligence jobs and Python scripts:
1. Client integrated development environment (IDE)
This tool provides a complete development environment for Python development, debugging, syntax highlighting and other functions, such as Visual Studio Code. In artificial intelligence scenarios, algorithm engineers mainly use VS Code for Python program development, debugging, syntax highlighting, intelligent code completion, pre-installed code snippets and version management Git support. Users can change themes, keyboard shortcuts, preferences and install extensions that add additional functionality to suit their needs.
2. One-stop artificial intelligence development plug-in
Tools for AI is currently renamed the Visual Studio Code Azure Machine Learning Extension. This tool provides support for deployment to the cloud or edge, support for commonly used deep learning libraries, local experiments re-deployment to large-scale clusters, integration of automated machine learning, and tracking of experiments and management models through CI/CD tools.
3. Code completion tools
Kite for VS Code is suitable for various languages of VS Code. It trains artificial intelligence models through massive code libraries and provides intelligent code completion services, including intelligent perception, code snippets, and cursor-following document AI code completion. Kite supports Python and other file types, and code completion will greatly improve development productivity, which is also an advantage of an integrated development environment. At the same time, OpenAI has also open sourced Copilot for intelligent code prompts and program synthesis (Program Synthesis) of common languages and general programs. Development using VS Code and other similar client IDEs is characterized by powerful functions and complete functions such as debugging and completion.
Submit jobs to the cluster through the web interface
Developers typically go through three stages of development before submitting jobs to the cluster. First, you will program and test in your own development environment to ensure that the program has no errors before submitting it to the cluster platform.
Writing Python artificial intelligence programs can be done locally using tools such as VS Code. VS Code facilitates local debugging, code static detection and code completion through plug-ins, which can significantly improve development efficiency without waiting for platform resources to be queued. This method is very convenient for quickly developing initial programs. If the local device does not have a GPU, you can consider installing the CPU version of the deep learning framework for development and testing.
If there is an available test server with a GPU mounted, the developer can submit the job to the test server for testing in the second stage. For small-scale operations, a certain level of training can also be completed on the server. However, GPU cannot meet the needs of large-scale multi-card and distributed training, or hyperparameter search with huge search space. Therefore, the debugged program can build a Docker image or upload data on the test server, etc. At this stage, it is more suitable to use VS Code with the Remote SSH plug-in for remote development.
When the user ensures that the program development is completed, the job can be submitted to the platform for batch job execution (the user can choose to use the command line tool, Web or REST API for job submission). Since GPU is a scarce resource, it may experience a certain queuing process (for example, several hours). In this case, users can use their free time to continue developing new jobs or reading papers, looking for new optimization points or debugging other jobs and models. After submitting the job, you can refer to the process in the figure below for complete execution of the job. This process is more suitable for accessing the job monitoring interface through the Web, logging in to the job through SSH for debugging, or starting Jupyter through job container deployment for interactive development.
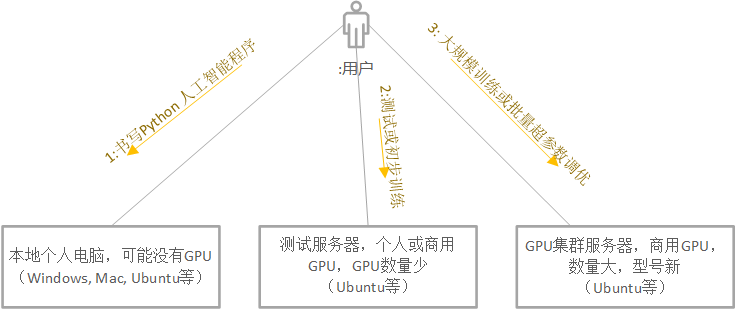
Different development environments for artificial intelligence jobs
As shown in the figure, developers usually go through the following three stages: local development, test server development, and packaged program submission to the platform for execution. At each stage, corresponding operations are performed. First, during the local development phase, developers write and test programs on their own computers. Then, during the test server development phase, the program is tested more rigorously to ensure it will function properly in a production environment. Finally, when the packaged program is submitted to the platform for execution, the developer will package the program and submit it to the cluster management system for batch processing. During the execution of the job, developers need to monitor the job status and debug to ensure that the program can execute smoothly and return correct results. Based on the training results, developers can adjust and optimize the program before starting the next job submission.

Artificial Intelligence Job Development Experience Sequence Diagram
As shown in the figure below, when the job has been debugged, the user will go through the following steps to interact with the platform to complete the training process:
●User first uploads data to storage
●Upload the image to the image center
●Submit job specifications. Fill in the data, image path, resource requirements and startup command line
●Cluster scheduler schedules jobs
●Idle GPU node pulls (Pull) image
●Idle GPU node starts job
●Mount file system
●Job operation starts
●Job monitoring continuously reports performance indicators and logs for observation and debugging
●Save results after training is completed
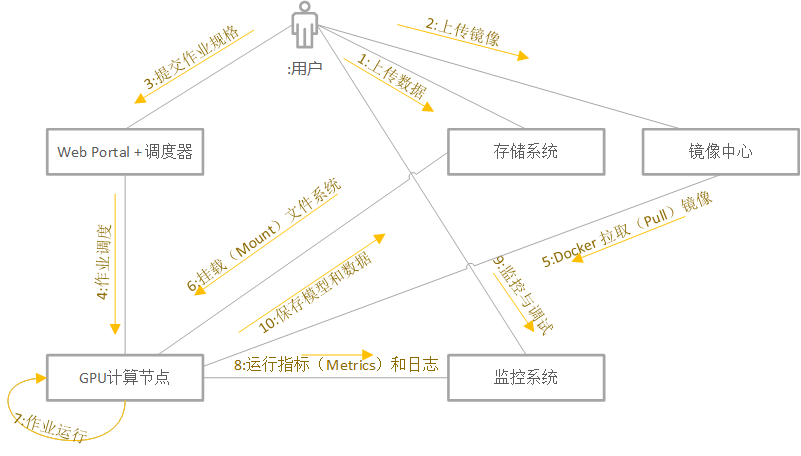
Job lifecycle submitted to the cluster
Scheduling
Platform scheduler
Before the job process is started, the platform needs to make decisions to determine which servers and GPUs the current job should run on, and which job can be executed first, and then make scheduling decisions. The following will focus on the abstraction and optimization goals of the scheduling problem, as well as the traditional scheduling algorithms that can be used for deep learning job scheduling, to understand the classic problems and solutions of job scheduling.
1. Optimization objectives of scheduling problems
Scheduling is the process of allocating resources to perform tasks. In the deep learning platform, resources include processors, GPUs, memory, etc., while tasks are jobs submitted by users. Scheduling activities are performed by a process called the scheduler. The scheduler's algorithm is typically designed to keep all computer resources busy, allowing multiple users to efficiently share system resources to achieve a target quality of service.
On the cluster server running deep learning jobs, an operating system will be deployed for job management and scheduling, that is, the heterogeneous resource management system is also called a deep learning platform. This system is different from traditional operating systems in that the "processes" it runs are generally deep learning jobs.
Each server is equipped with multiple commercial GPUs, InfiniBand network cards and other heterogeneous hardware. The deep learning platform must also provide multiplexing for jobs as a whole at a "certain abstraction level" of the hardware it manages. At the same time, because not only one user in the entire system submits multiple jobs, the entire resource pool is shared by multiple internal company groups and users. This is a multi-tenancy system.
1. Job delay and throughput related indicators
1) Queuing delay
Describes the time a job spent waiting in the scheduler queue for resource allocation. The lower the queuing delay, the shorter the waiting time for user jobs and the more efficient they are. It is mainly affected by two factors:
●Fairness
Whether user jobs are fairly allocated the required resources
●Locality and resource fragmentation issues
May cause resources to be unallocated and waiting
2) Average response time
The average amount of time from submitting a request until the first response is generated.
3) Average job completion time
The average completion time of a batch of jobs (this metric can represent system performance). For example, considering the locality of distributed jobs, it affects the communication time and thus the average job completion time.
4) Completion time
In a batch of jobs, the overall completion time from the first job to the last job (the smaller the time, the better). Some scheduling algorithms also consider the overall completion time of all jobs as the optimization goal, because minimizing the completion time is equivalent to maximizing resource efficiency.
5) Throughput
The number of jobs that can be completed per unit time (the larger the throughput, the better).
2. Indicators related to platform resource utilization
1) Resource utilization
Describes the percentage of resources used for the job as a percentage of total resources (higher utilization is better).
2) Resource fragmentation
After job allocation, individual node resources cannot be reallocated, causing fragmentation problems. The fewer fragments, the less wasted resources. It is also an indicator related to resource utilization.
3. Indicators related to fairness and service level
1) Fairness
Resource usage is distributed equally among platform users or groups or in proportion to specified quotas.
2) Service Level Agreement
A service level agreement is a commitment between the platform and its users. For example, the fairness, quality, availability, responsibility, etc. of platform services are agreed upon and agreed upon between the platform and users.
As shown in the figure below, the platform contains the following hierarchical relationships between clusters and jobs. Different levels contain different scheduling problems. The deep learning-oriented scheduling algorithms involved later can also be mapped to the solutions to the hierarchical problems.
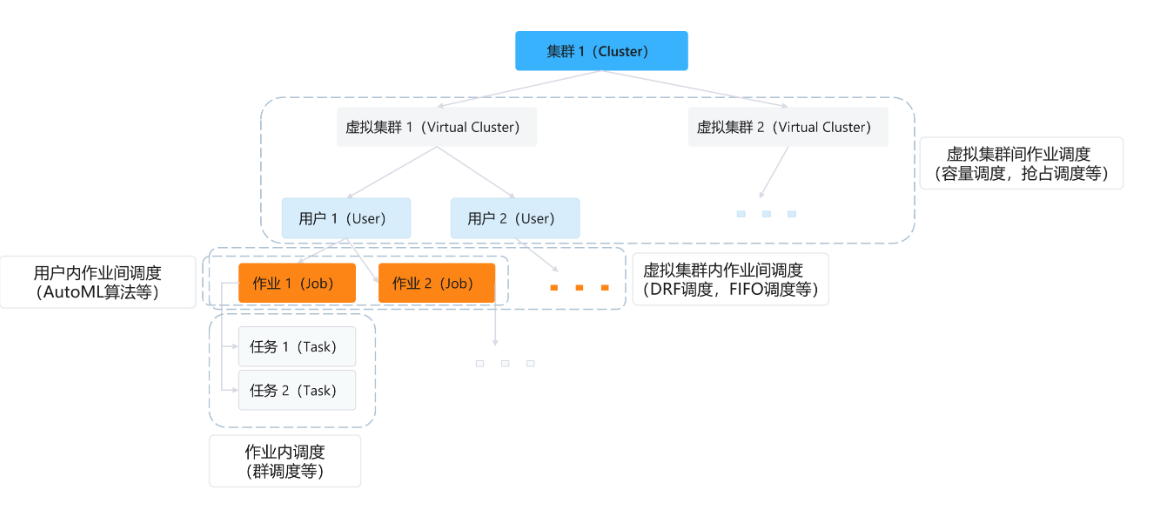
Overview of job scheduling issues in the platform
2. Single job scheduling-group scheduling
Group scheduling is a scheduling algorithm used in parallel systems to schedule related threads or processes to start and run at the same time on different processors. Deep learning jobs often require group scheduling to ensure that all necessary acceleration devices are ready before starting the training process. Failure to use group scheduling may cause problems. Because deep learning jobs usually need to execute multiple tasks at the same time, if any dependent tasks are not started, the started tasks may be waiting for synchronization points or frequently switch contexts and cannot continue to run, resulting in the failure of the training task.
At the same time, if resources are not released for started tasks, resources may be wasted and deadlock may occur. As shown in the figure below, both jobs have applied for some resources, but they also need other resources to start, which results in a deadlock.
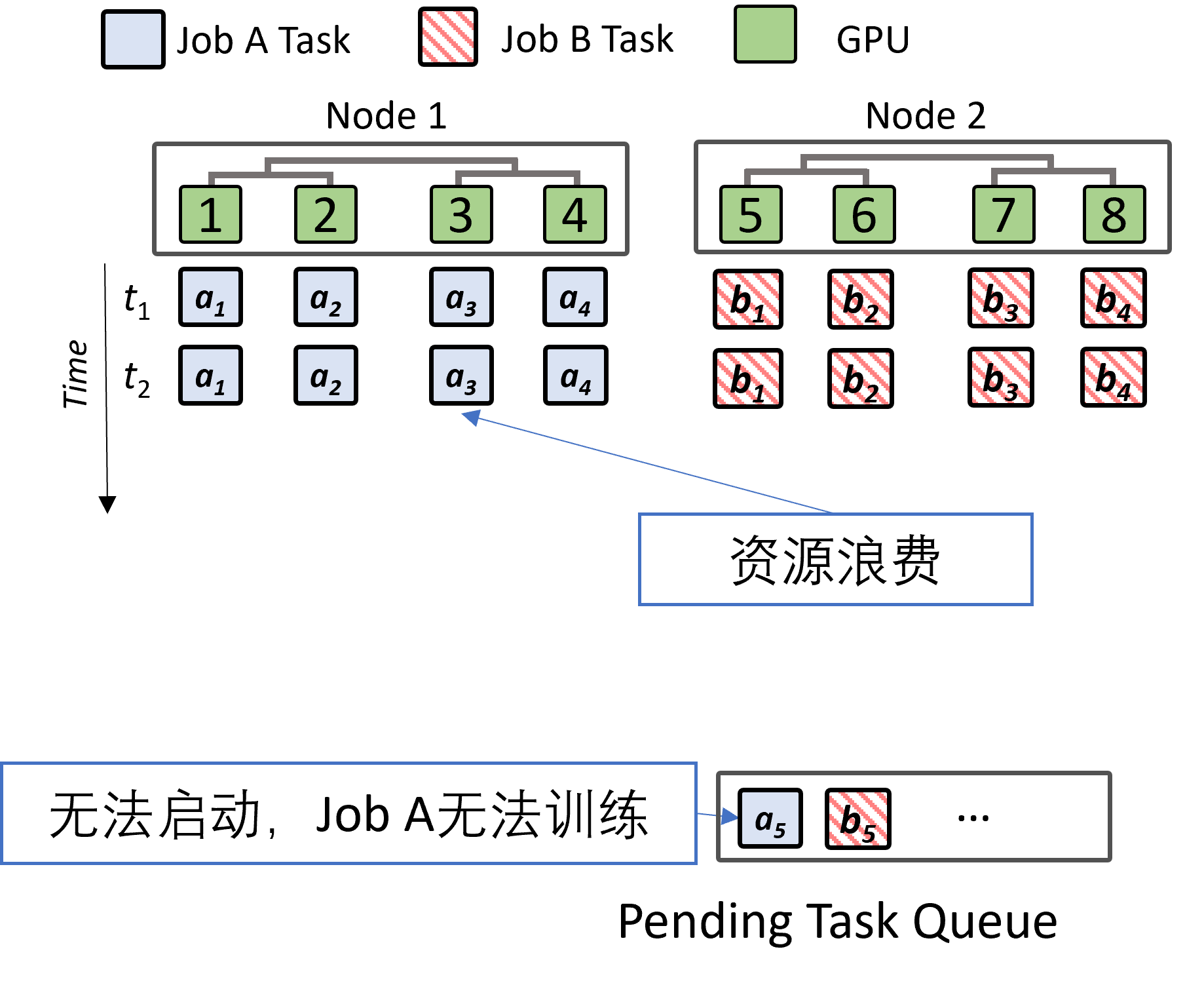
Problems that may arise when starting execution jobs in parallel
By leveraging group scheduling technology, deep learning task processes can be started simultaneously to solve the problem in the previously mentioned example. As shown in the figure below, jobs A, B, and C can be executed alternately to ensure that all tasks can be completed smoothly. This method allows started tasks to continue running without interrupting training or wasting resources due to waiting for other unstarted tasks.
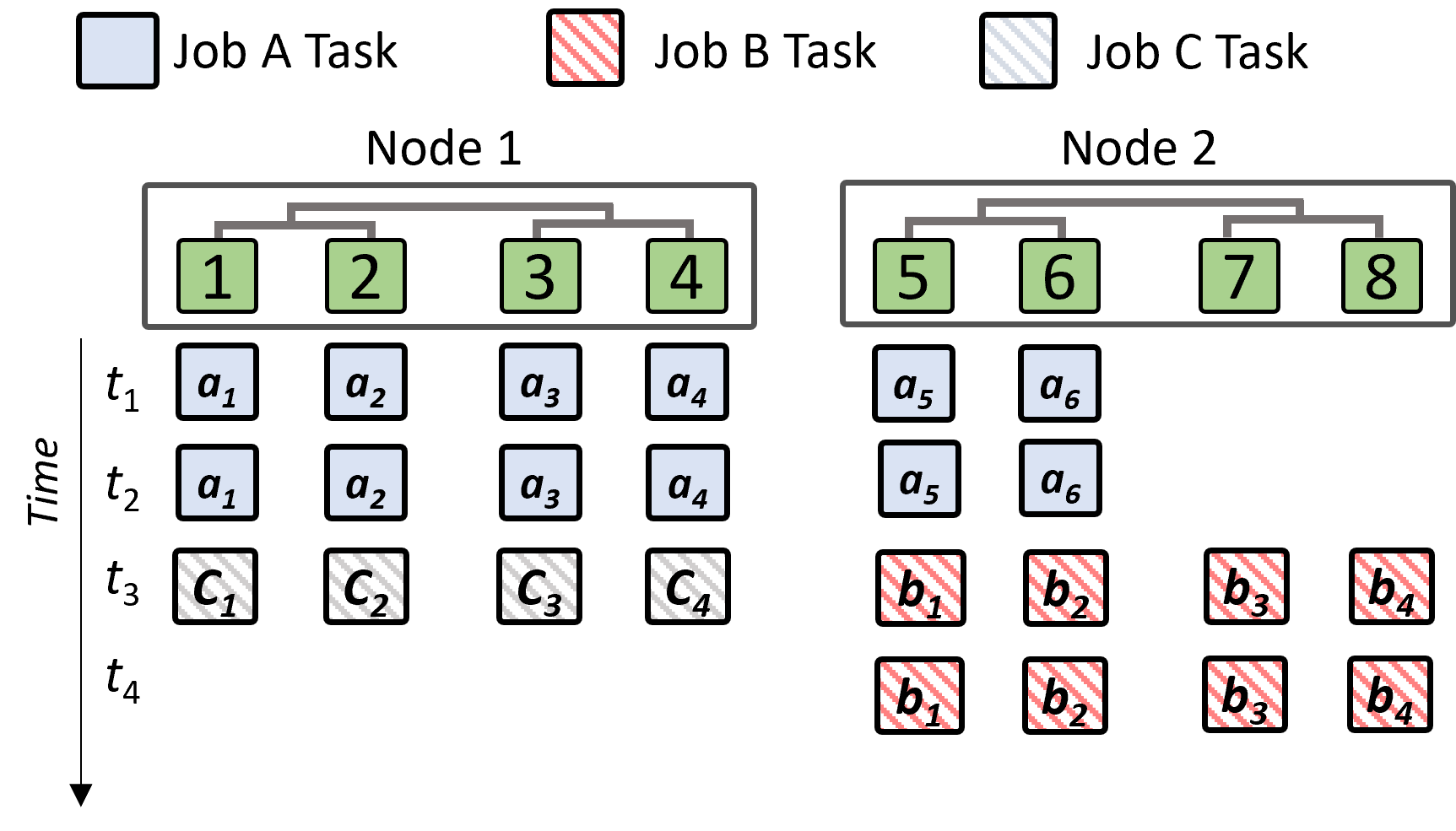
Problems that may arise when executing jobs in parallel
Of course, group scheduling also has certain limitations. For example, it may increase the risk of resource fragmentation and lower utilization in shared clusters. As shown in the figure during the t1 and t2 time periods, GPUs 7 and 8 are in idle state, resulting in a waste of resources.
3. Inter-job scheduling—Dominant Resource Fairness (DRF) scheduling
In systems containing multiple heterogeneous resources, achieving fair resource scheduling for multiple jobs is a challenge. Deep learning jobs require the use of multiple resources such as CPU, GPU, and memory, so a fair scheduling strategy that considers multiple resources is needed. DRF (Dominant Resource Fairness) is an algorithm for fair scheduling of multiple resources that compares the allocation of multiple resources by using the concept of dominant shares.
Unlike other strategies, DRF satisfies several desirable properties. First, users are encouraged to share resources to ensure fairness. Secondly, DRF is policy-proof, that is, users have no incentive to increase the allocation of job resources by lying about demand. Based on max-min fairness, users who lie about more resources will need more queuing time. At the same time, DRF is jealousy-free, that is, users do not envy other users’ allocations. Finally, DRF allocation is Pareto efficient, that is, it is impossible to benefit some people without harming the interests of others.
A brief summary of the DRF scheduling strategy is: determine the dominant resource based on the share of resources of the same type in the overall cluster resources. Scheduling algorithm for multiple resource types (such as GPU, CPU) based on max-min fairness.

DRF scheduling example for 2 jobs
In the following resource application requirements, the dominant resource is memory.

Among the following resource application requirements, the dominant resource is GPU.

4. Inter-group job scheduling—Capacity Scheduling
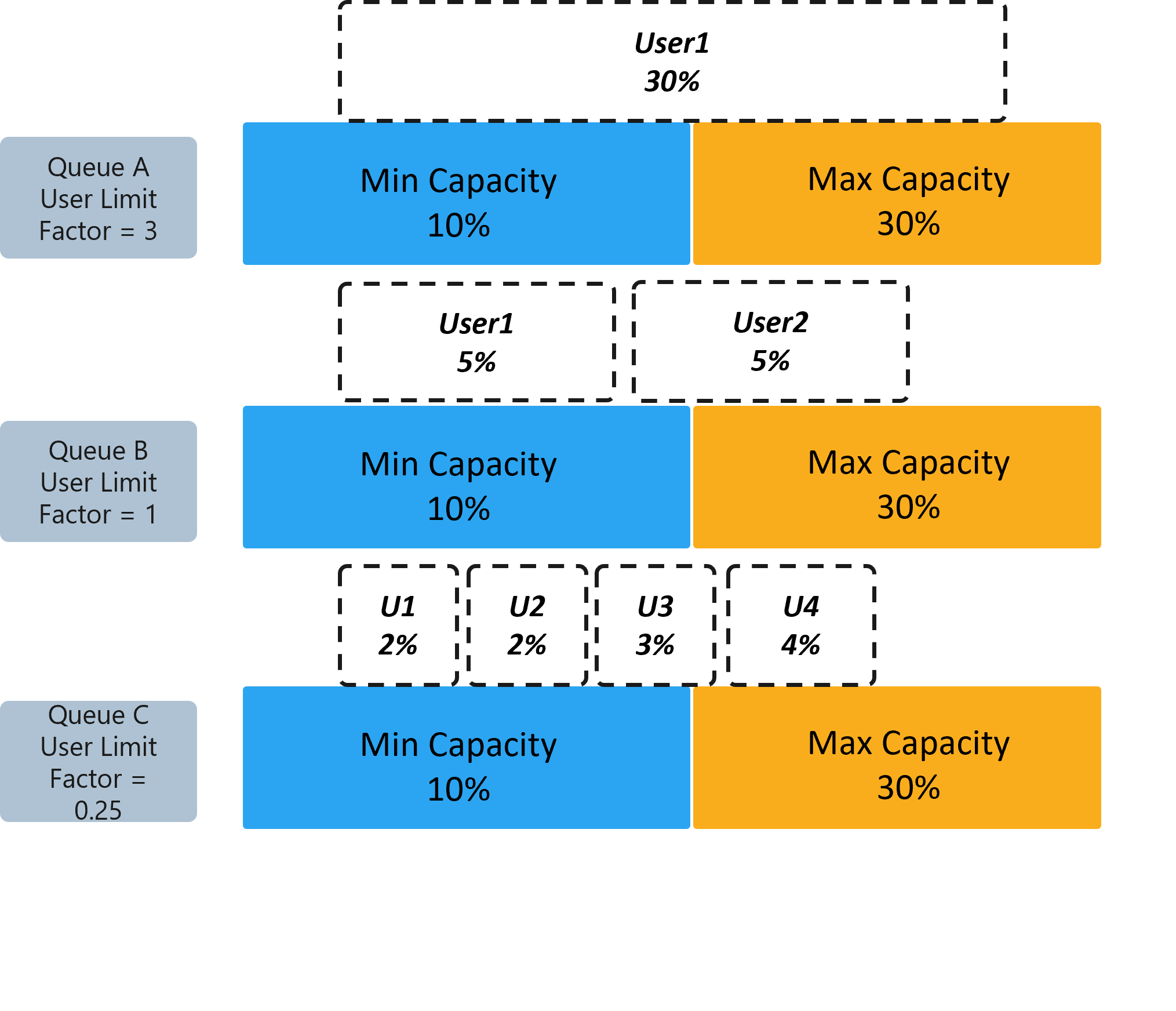
In addition to being able to distribute multiple jobs equitably, platform administrators also need to consider how clusters can be shared among multiple groups and how cluster resources can be shared across multiple organizations. While sharing cluster resources, you also need to provide minimum capacity guarantees for each organization to ensure that it can get the resources it needs. Idle resources should be able to be flexibly utilized by other organizations to improve resource utilization and reduce resource waste.
Compared with traditional capacity scheduling, deep learning jobs also need to consider scheduling GPU and GPU memory capacity. Capacity Scheduler is a commonly used mainstream scheduler in big data platforms. It can treat both deep learning training jobs and big data jobs as batch processing jobs. Allows multiple tenants to securely share a large cluster and allocate resources to applications in a timely manner within the constraints of allocated capacity.
Take the following figure as an example. Teams A, B, and C share the cluster. Each group has multiple users, and each user submits jobs to use cluster resources. If fairness between groups is not considered, even if Team A applies for another 45 resources, it will be wasted if they are not used up. It will also prevent Team C from applying for resources, causing starvation.
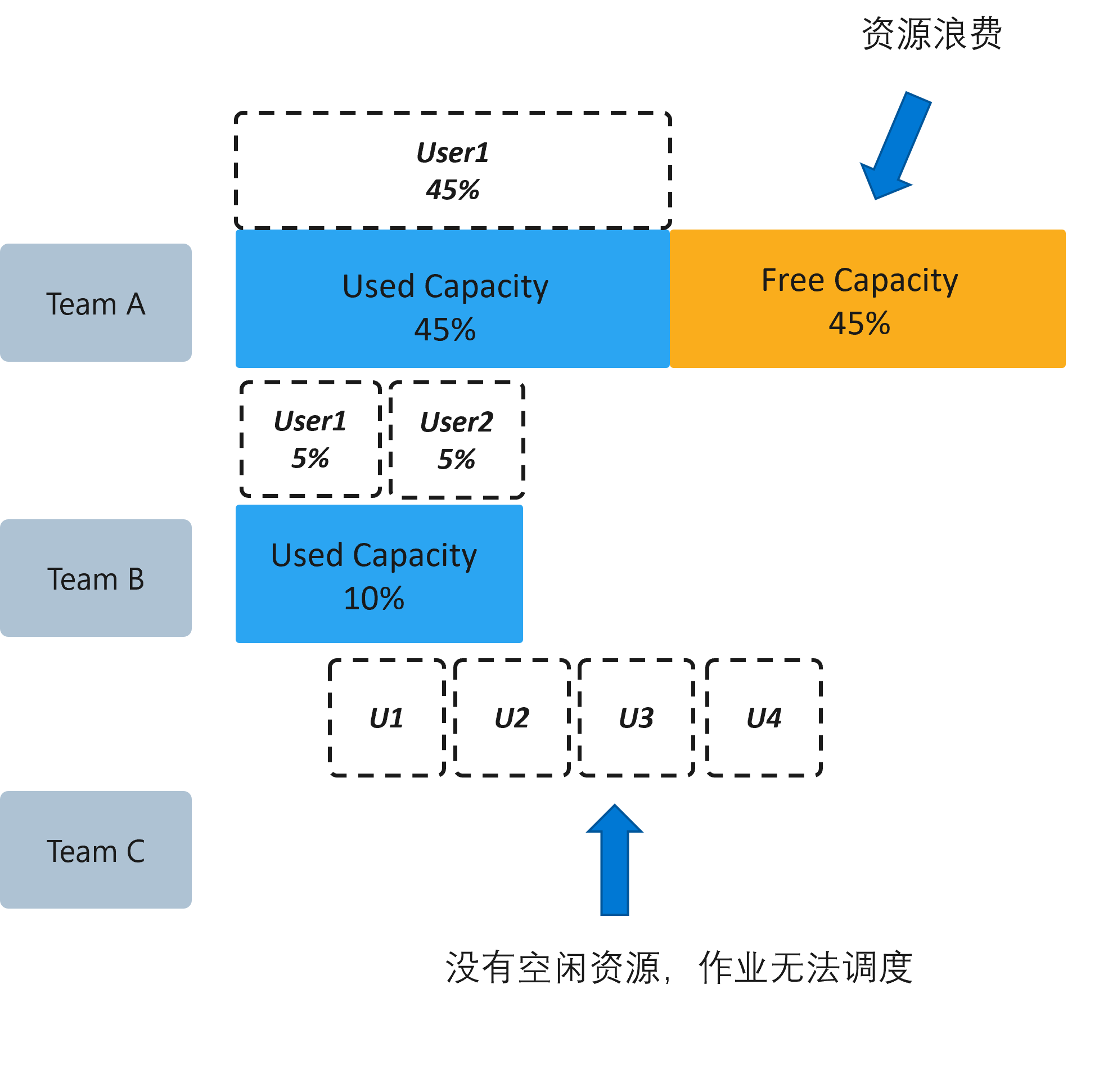
Excessive resource usage causes other groups to be unable to allocate resources.
Therefore, capacity scheduling has designed the following policy set to support multi-tenant resource sharing:
1. Improve utilization (Utilization)
1) What the Virtual Cluster group can see is a virtual resource view, which is not bound to a specific machine. The corresponding resources will be allocated after the job is started, which helps to improve resource utilization.
2) Hierarchical Queues support the hierarchical structure of queues to ensure that resources are shared among the organization's sub-queues before allowing other queues to use idle resources, thereby providing more control and predictability.
3) Other inter-job scheduling algorithms can be orthogonally combined in the queue, such as first-in-first-out (FIFO), DRF, etc. In heterogeneous computing scenarios, other custom schedulers suitable for multi-dimensional resource scheduling can still be used.
2. Multi-renting and improving fairness (Fairness)
1) In a sense, queues will be allocated a small fraction of the grid's capacity because they can use a certain capacity of resources. All applications submitted to the queue have access to the capacity allocated to the queue. Administrators can configure soft limits and optional hard limits on the capacity allocated to each queue.
2) Allow multiple users to use the cluster in the form of multi-tenancy. Control the maximum resources that a single user can consume to prevent it from occupying too many resources and causing other processes to be unable to apply for resources.
3. Flexibility and SLA
1) Bonus Resource
Resources that are not used by other groups can be temporarily transferred to teams in need for free. However, when the resource holder needs it, the resource needs to be preempted and returned to the holder.
2) Preemption (Preemption) cooperates with the use of reward resources to ensure the service level agreement (SLA) provided to users
As shown in the figure below, when the administrator configures the minimum and maximum resource quotas for groups, this can ensure that there are available resources between groups.
capacity scheduling
5. Virtual Cluster mechanism
Within the cluster, the resource quotas seen by groups and users are generally not bound to specific physical machines. Instead, the physical machines for job deployment are determined after scheduling. This is achieved through Virtual Cluster mapping. The design of virtual clusters is similar to the control groups (Cgroups) introduced previously. Here you will see many problems caused by clusters, and similar design issues and principles can be found in traditional operating systems.
As shown in the figure below, the virtual cluster configures the quotas and views of the user group, and the physical cluster is bound at runtime after scheduling. This can greatly improve resource utilization and reduce resource fragmentation.
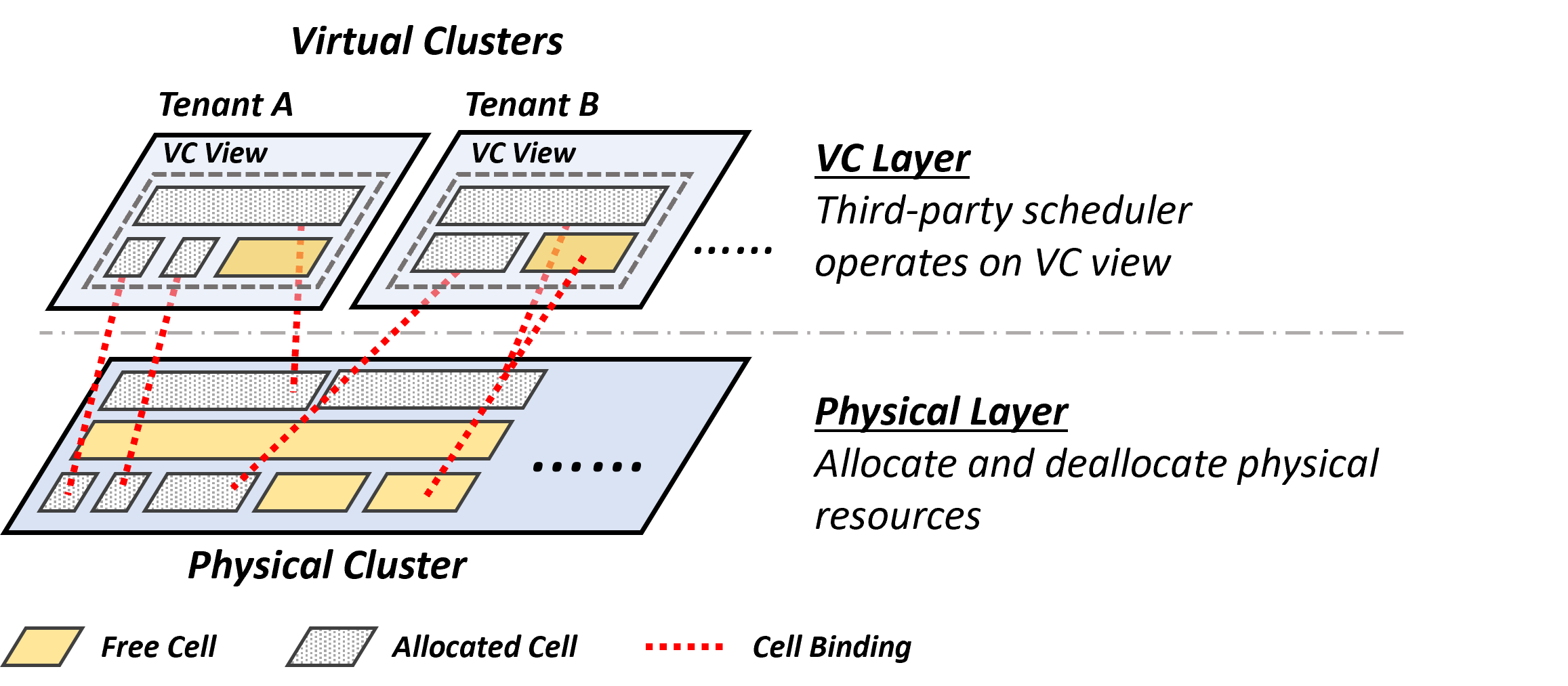
Virtual cluster and physical cluster mapping and binding
6. Preemptive scheduling
Some cluster administrators hope to share idle resources in the virtual cluster through policies to reduce the waste of resources within the group. However, simply transferring resources does not guarantee that the original users can reclaim the corresponding quota resources at any time, and thus cannot guarantee the SLA for the original users ( service level agreement). This problem can be solved through preemptive scheduling, that is, when the original user of the resource needs the resource, the job process using the reward resource is terminated and the resource is recycled to the original quota user. Preemptive scheduling is usually used in the following scenarios:
1. Let resource-hungry jobs or short jobs seize certain resources to reduce the average response time of jobs.
Since the resilience of deep learning jobs is not perfect, preemptive scheduling is generally not used for such needs. As shown in the figure below, APP2 cannot be executed if it cannot obtain resources for a long time, and its execution time is actually very short. This requires scheduling through the preemption mechanism to allow APP2 to obtain certain resources for execution to ensure that the average response time is reduced.
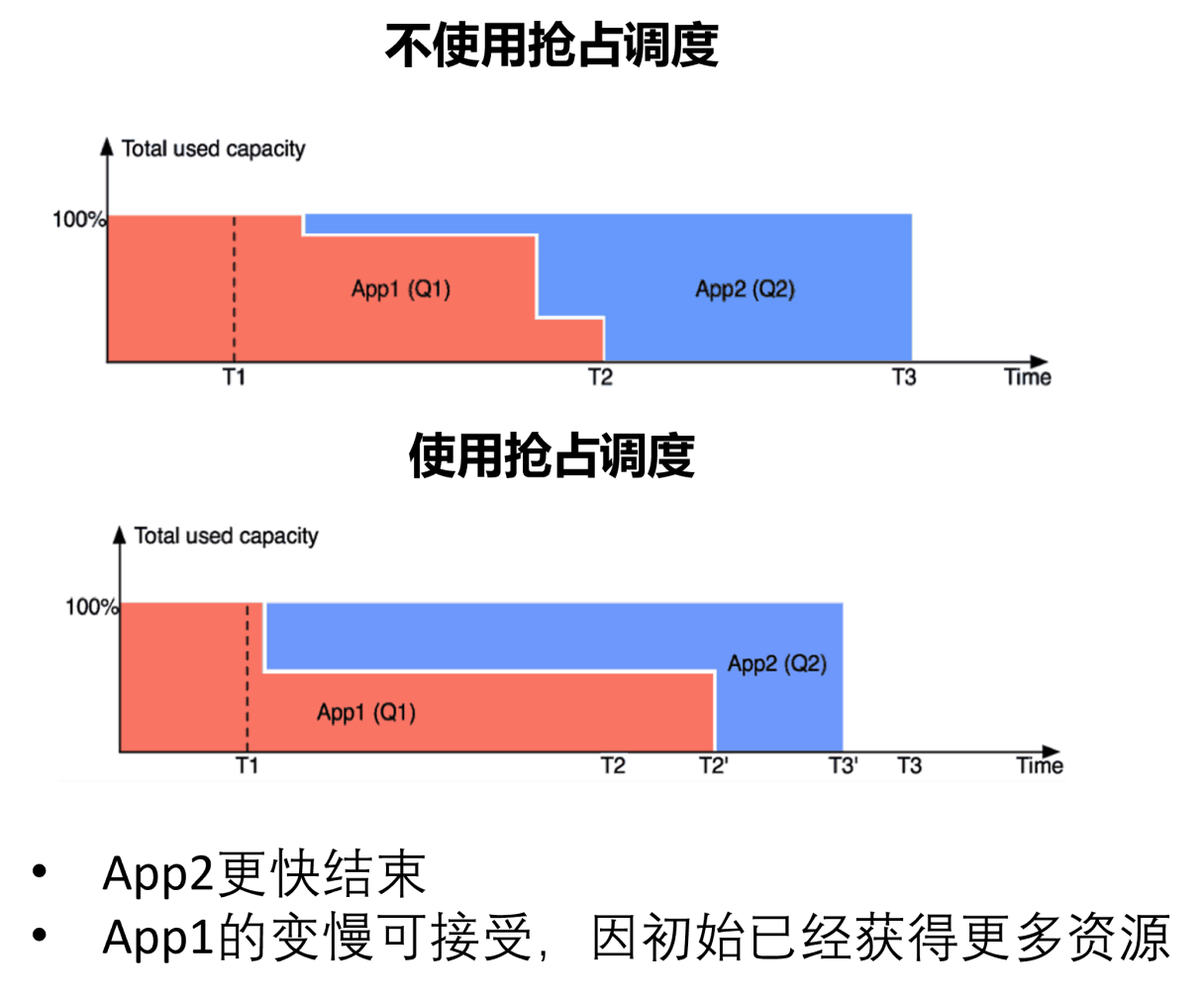
Job waiting time problem is too long
2. Transfer the idle resources of the virtual cluster to form reward resources for use by jobs in other virtual clusters, thereby improving overall resource utilization.
In deep learning, preemptive scheduling is often used for this reason. As shown in the figure below, 10 available resources are configured in queue A, but because the cluster has idle resources, 20 more reward resources are provided to C6 and C7. At this time, if queue C needs to use 20 resources, the cluster should ensure that preemption can be triggered. When the resources used by C6 and C7 of APP1 are marked as available for preemption, their resources can be preempted through the following steps:
1) Get the containers that need to be preempted from the overused queue (i.e. C6 and C7 of queue A).
2) Notify the job (i.e. queue A) controller that preemption is about to be triggered.
3) Wait until the preempted job is terminated.
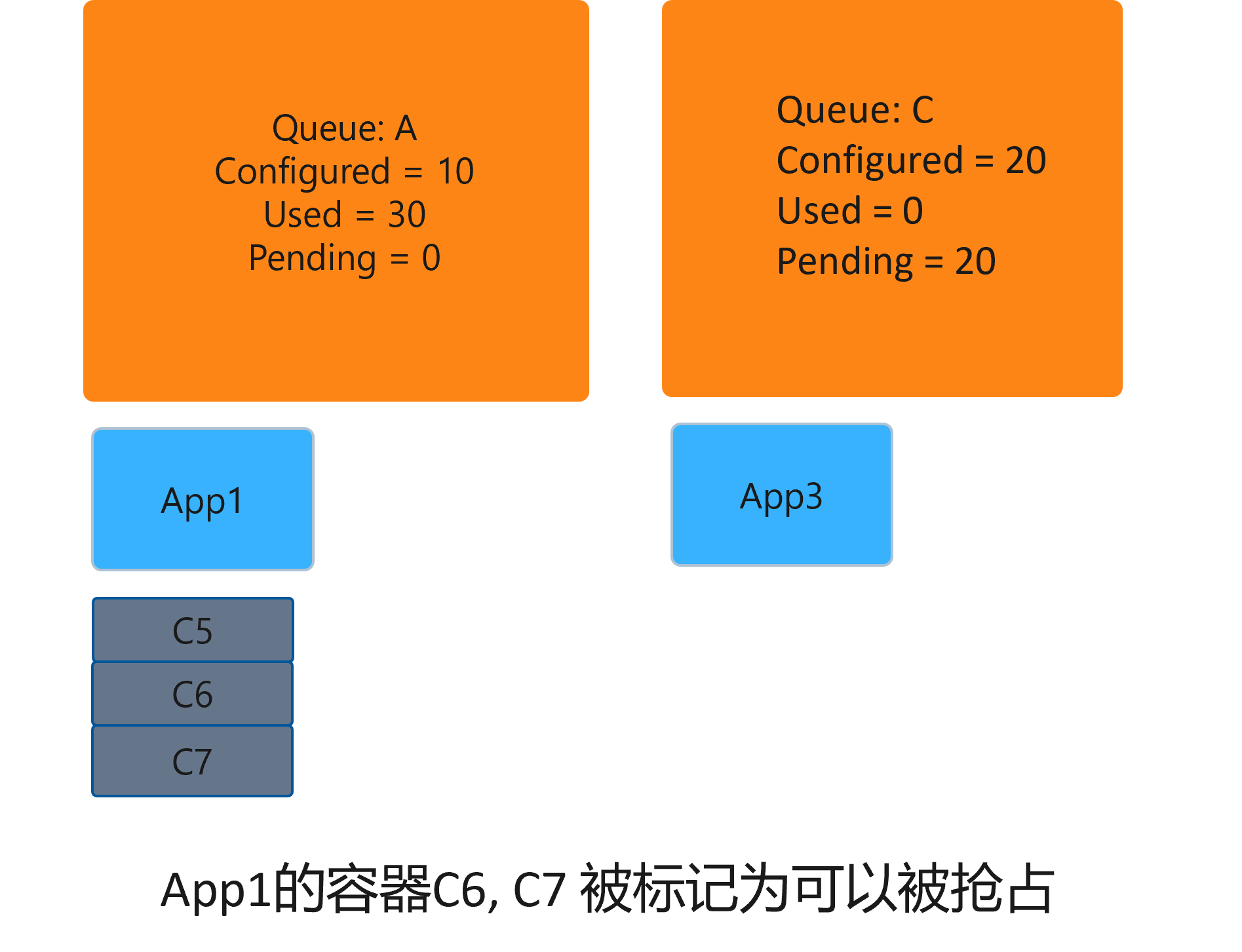
Preemption intensity
Preemptive scheduling poses challenges to deep learning jobs because deep learning jobs can only fail when they are preempted and cannot perform context switching by default like traditional operating systems. At present, some work provides a checkpoint mechanism at the framework or device driver library layer to cooperate with the scheduler to achieve preemption and recovery. However, since it is not natively supported, there is a certain overhead, and the supported frameworks and scenarios are limited, so it has not yet been widely used. In the future, better deep learning checkpoint and recovery technologies can be designed to reduce the problem of invalid use of preempted job resources caused by job failure after preemption.
Run simulations on your data to see if you can improve your current goals and outperform the baseline algorithm. Finally, the results are analyzed and an analysis report or paper is formed.
Cluster management system for deep learning
The following will introduce the platform scheduling algorithm designed for the characteristics of deep learning workloads and GPU servers to better meet the needs of new workloads and hardware and improve resource utilization and other indicators.
1. Requirements for deep learning workloads
1. Deep learning training jobs vs. traditional data center batch processing jobs
1) Long execution time
Training lasts hours or even days
2) Iterative calculation
The backbone of the job is iterative calculations, and each iteration can be divided into tasks with small time windows.
3) Dynamic changes in the amount of memory data
Checkpoints at different time points during the training process have different amounts of memory data.
4) Performance predictability
Resource consumption predictability, which can be obtained through runtime monitoring
2. Characteristics of distributed deep learning training jobs
1) Sensitive to GPU topology
Data parallel strategy communication transfers gradients, and model parallel strategy communication transfers intermediate result tensors. The transmission bandwidth between GPUs can easily form a bottleneck. Therefore, a task placement strategy that considers GPU affinity is helpful to reduce the completion time of distributed training jobs.
2) Feedback-driven exploration
In automated machine learning scenarios, users will submit a large number of deep learning jobs at one time. These assignments are characterized by feedback-driven exploration. Users often try multiple job configurations (multiple jobs) and use early feedback from these jobs (accuracy, error, etc.) to decide whether to prioritize or terminate some of them.
According to the characteristics of deep learning jobs and hardware architecture, the support of software stack and hardware stack can collaboratively design job scheduling strategies for deep learning to improve resource utilization and other indicators.
2. Diversity of heterogeneous hardware
The main computing unit during deep learning job training is the GPU, and servers used for such calculations usually have multiple GPUs mounted on them. This hardware architecture differs in some ways from the servers used in traditional data center operations and therefore presents some challenges.
1. Communication cost
Due to the various interconnection methods between multiple GPUs, different placement methods may be affected by the GPU topology, which in turn affects the cost and performance of data communication. The GPU is mounted on the PCIe bus or switch according to a certain topology, so the communication between the GPU and the GPU may span PCIe and PCIe switches within the node, or span InfiniBand or Ethernet between nodes.
2. Resource contention
Since the job itself may share resources such as servers and data buses with other jobs, it will also be subject to contention and interference from other jobs. GPU topology and task placement will affect the training performance of multi-card and distributed jobs. Therefore, a heuristic optimization strategy can be considered, that is, scheduling tasks according to the affinity of the GPU topology of the cluster and server nodes.
3. Management and operation and maintenance requirements of deep learning platform
The deep learning platform needs to manage deep learning model training operations on the upper side and heterogeneous hardware represented by GPU and InfiniBand on the lower side. Platform management and operation and maintenance also face some challenges. Compared with machine learning engineers, data scientists and other platform users, deep learning platform administrators pay more attention to the following design goals:
1. Efficiency
GPU clusters are expensive and frequently updated. How to effectively plan the cluster, improve the input-output ratio, and how to reduce resource fragmentation and improve utilization in existing clusters are important challenges faced by platform administrators. The scheduling algorithm can optimize and improve the resource utilization of the cluster to a certain extent.
2. Fairness
Users of deep learning platforms have both engineering purposes and many scientific research purposes. While training the production model, there are also some needs for research submission and meeting paper deadlines. This allows users to have peak resource usage requirements similar to specific periods compared to traditional batch processing scheduling scenarios. The platform needs to ensure fairness in the use of resources among each group, and at the same time plan users' resource use in advance while taking into account peak utilization needs. Administrators need to design corresponding strategies.
3. Stability
1) Since the designers of the deep learning framework did not regard fault tolerance as the first priority like the big data community at the beginning, the framework provided a basic checkpoint mechanism, but it required user control and did not support automatic backup and recovery. In subsequent design versions Functions such as flexibility are supported only in community tools. This brings a relatively large operation and maintenance burden to the underlying platform.
2) Due to the heterogeneous hardware on the node, there is also a certain probability of hardware problems, such as GPU failure, causing platform stability challenges. How to discover and repair faults efficiently and quickly requires, in addition to tool support, systematic system design, development process design, and management strategy design.
4. Maintainability
The platform team is developing and operating the platform at the same time, and maintainability is also an important consideration to reduce the burden of operation and maintenance. Splitting functional modules as much as possible through microservices and other means can minimize fault location and repair. At the same time, good DevOps process establishment, agile development and project management also play a key role in improving the maintainability of the platform. .
5. User experience
Good user experience and unified job submission, job management and debugging tools can greatly improve users' development productivity and also reduce the burden of platform operation and maintenance engineers.
In addition to the above indicators, the platform will also focus on performance (throughput, completion time, etc.) indicators. The platform itself has many modules, involves a variety of external interactive software and hardware, and has many users who use and maintain it, so the problem scenarios it faces are relatively complex. As platform designers and users, we need to consider all aspects. Performance is only one part of it. We must also design and manage the entire heterogeneous resources from a systematic perspective to provide a more transparent and convenient user experience for upper-layer application loads and users.
4. Scheduling design under deep learning load and heterogeneous hardware
The following will start with the scheduling algorithm of the deep learning platform and introduce the design of scheduling algorithms that consider different design goals and priorities. Due to different design goals, these schedulers are based on different assumptions, and their implementation and intrusiveness to jobs are also different. Therefore, when selecting and designing a scheduler, you need to consider the advantages and disadvantages of different algorithms and make a decision based on the current situation of the platform.
1. Scheduler design based on collaborative design of framework and platform
1) Reactive Mode
Similar to the event-driven design of traditional schedulers, scheduling strategies are triggered based on different events and states (such as job arrival, departure, failure). Its overall strategy can be abstracted into a state machine.

Distributed job scheduling is affected by locality
As can be seen from the chart, scheduling jobs that also require two GPU cards on the same PCIe switch, across switches, and across nodes will result in a 40% to 5x slowdown. Therefore, for multi-card jobs, considering the locality of deployment, affinity scheduling can make job execution faster and save more resources to execute other jobs, which is beneficial to the overall completion time and improves resource utilization.
When scheduling is triggered, the scheduling policy gives priority to affinity. During the scheduling process, nodes are considered and sorted according to the following priorities for job allocation to reduce the data I/O overhead of deep learning jobs and improve performance. The priority of the nodes to be allocated is:
●Nodes with the same affinity.
●Nodes that have not yet been marked with affinity.
●Nodes with different affinities.
●Perform oversubscription and pause and resume other jobs on nodes with the same affinity.
●If the above conditions are not met, the job will be queued and waiting.
Taking the picture as an example, the scheduler places jobs that require 1 GPU together, but jobs that require 2 or 4 GPUs are placed on different servers. Additionally, an attempt is made to balance the oversubscription load on each server by selecting the least loaded server to prevent a server with 1 GPU demanding job from having 6 1 GPU demanding jobs each.
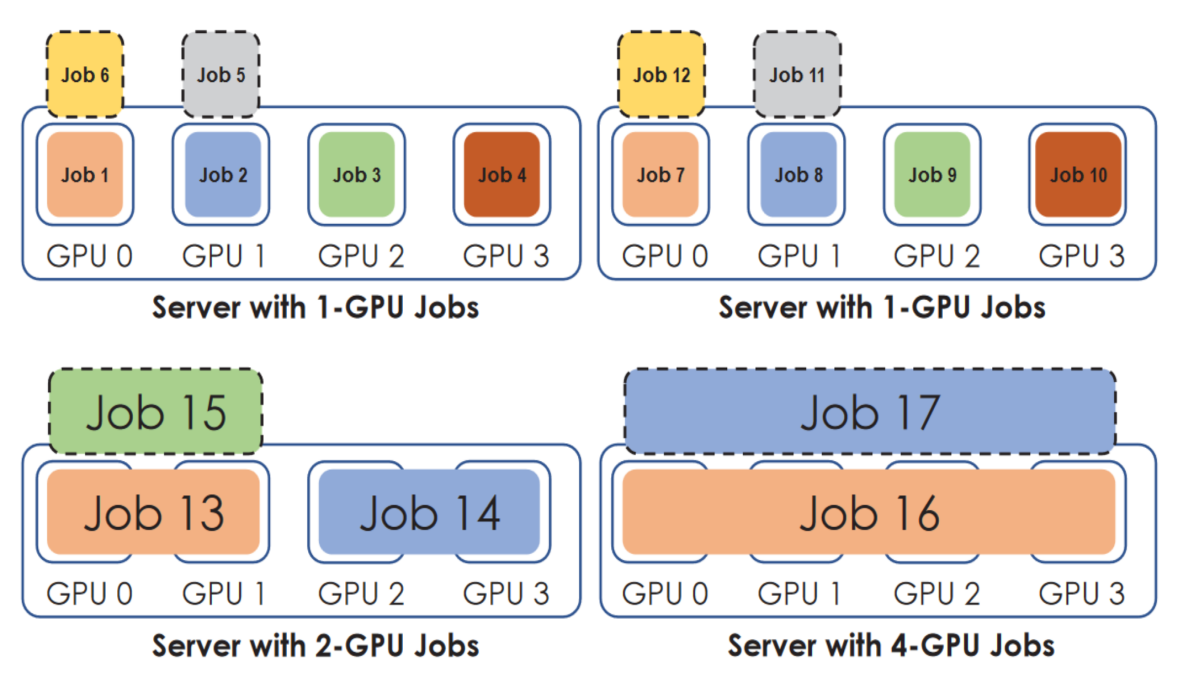
In a 16-GPU cluster, Gandiva schedules instances
2) Introspective Mode
After being applied to job execution, it continuously monitors and regularly optimizes the placement of the current job. At the same time, it supports fine-grained checkpoints and recovery functions through the extended framework, providing basic primitive support for subsequent backup and migration strategies. By continuously monitoring job utilization and node resource utilization, we perform bin packing, migration, grow-shrink, oversubscription and time slicing of jobs, thereby improving overall resource utilization. rate and reduce job completion time (Makespan).
Bin Packing refers to packing more jobs into the same GPU based on the amount of floating point operations while ensuring GPU memory constraints to improve resource utilization. Time Slicing uses the checkpoint and recovery mechanism implemented by the framework layer or the bottom layer. Multiple jobs can share a single GPU through time division multiplexing. This can be compared to a coarse-grained process context switching (Context Switching) mechanism.
Migration uses the checkpoint and recovery mechanism implemented by the framework layer or the bottom layer. When there are idle resources or reward resources, the dynamic migration job uses the reward resources to accelerate training. When a job needs to be preempted to return resources, the migration job ensures that the training before the job does not become invalid.
The figure above shows an example of a cluster experiment. In the multi-job scheduling scenario, there are 4 jobs that require 2 GPUs. These jobs have been scheduled, but 3 of the jobs do not have good affinity (J1, J2, and J3). Only the GPU of J0 is packaged and allocated. Reached the same node. Three minutes later, a job training using the DeepSpeed framework was completed and 8 GPUs were released, 3 of which are represented by green circles in the figure and distributed on different servers. These three GPUs have the potential to improve the training efficiency of multiple current jobs.
The scheduler starts the migration process and reallocates J1, J2, and J3 to GPUs placed together. To reduce fragmentation, choose to migrate jobs on the server with the most idle GPUs. Then start migrating the running jobs from the current server (with more idle GPUs) to another server (with less idle GPUs) so that the tasks of the same job can be executed on the GPUs of the same server.
Gandiva keeps repeating this process until the number of idle GPUs on the non-idle server is less than a certain threshold (3/4 is used as the threshold in the experiment), or until no jobs can benefit from job migration.
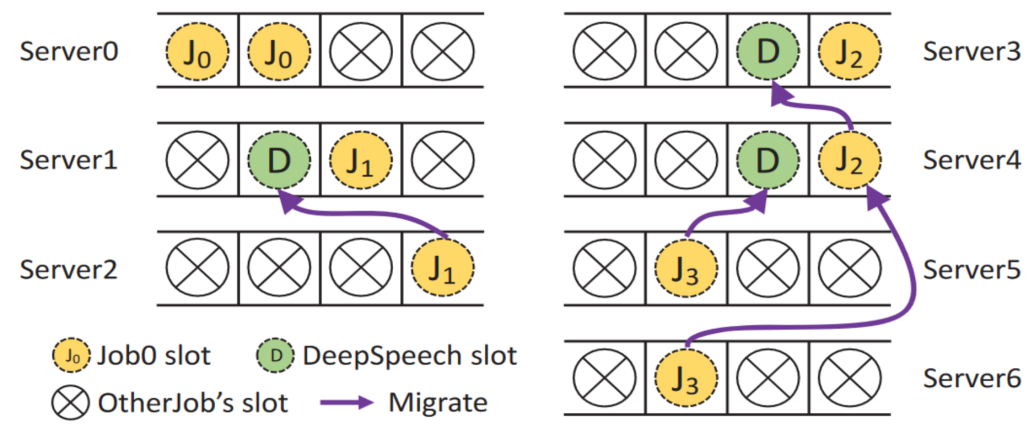
In a shared resource cluster, Gandiva performs job migration examples
2. Scheduler design for specific scenario problems (multi-tenancy)
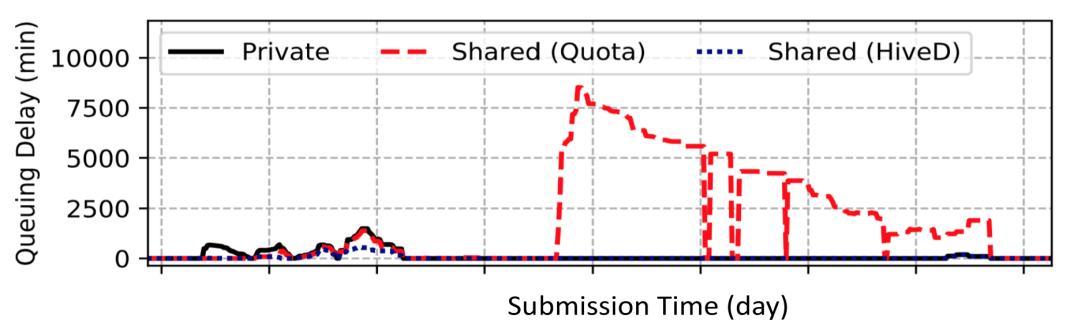
Queuing delay problem
The above figure shows log data within two months, involving a cluster with 2232 GPUs, 11 tenants, private clusters, shared multi-tenant clusters, and shared multi-tenant clusters optimized by HiveD. Among them, the red line shows that due to the requirements in the multi-tenant environment, the job needs to meet the hard node affinity constraints (schedule the job to nodes with a closer communication distance as much as possible), resulting in an average delay of 7 times. HiveD OSDI proposes that if both multi-tenancy environment and GPU affinity are taken into consideration when scheduling deep learning jobs, resources with high affinity will be allocated to the job as a whole as much as possible, which will lead to cluster scheduling being prone to exceptions with high queuing delays.
HiveD designs a multi-level cell (Cell) structure and adopts the Buddy Cell Allocation algorithm to ensure that resources can be allocated efficiently and reduce queuing time and resource fragmentation while satisfying the above constraints. At the same time, HiveD can be compatible and integrated with other schedulers.
The figure below shows the cell structure at four levels: GPU (Level-1), PCIe switch (Level-2), CPU socket (Socket) (Level-3) and node level (Level-4) . The current instance cluster has a rack consisting of four 8-GPU nodes, shared by three tenants A, B and C.
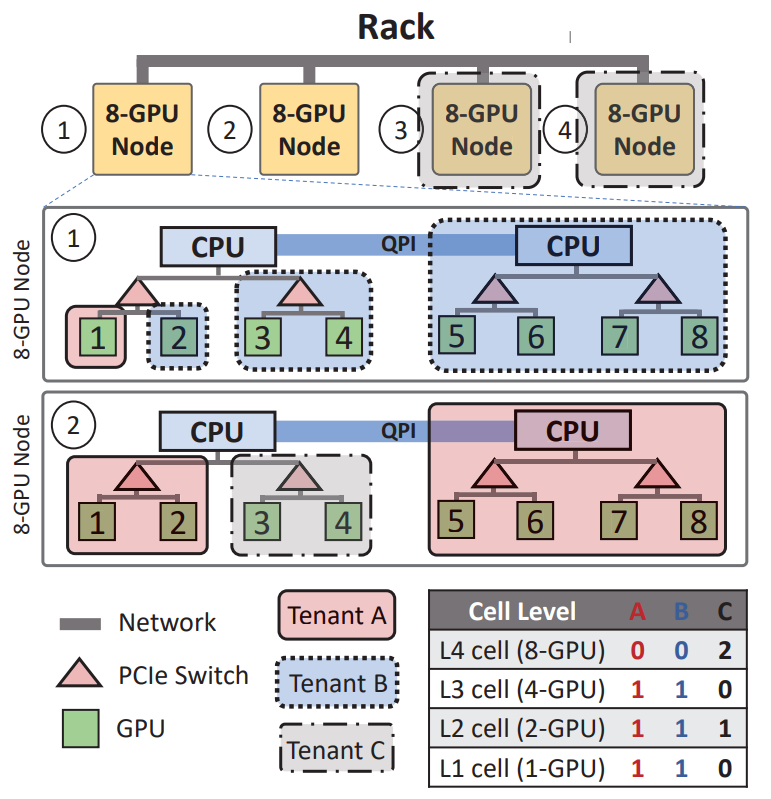
Example of multi-level cell allocation for HiveD rack
Blue Ocean Brain Heterogeneous Cluster Management Solution
As the scale of enterprises gradually expands, especially when there are often multiple hardware models and operating system versions in private cloud database architectures, batch replacement and upgrade of these hardware is a high-risk and high-cost task. Blue Ocean Brain's heterogeneous cluster management solution not only helps enterprises make full use of existing equipment, but also provides a smooth transition solution to support the grayscale replacement of new hardware and heterogeneous chips. At the same time, the solution also supports the hybrid deployment of encrypted copies of the national secret algorithm, providing a safe and stable solution for enterprises’ localization upgrades.
Blue Ocean Brain's heterogeneous cluster management solution adopts an active and standby cluster architecture. The standby cluster uses new hardware to complete the first phase of grayscale verification, without any impact on the main cluster business during this period. The AI heterogeneous computing platform includes four core suites: AI computing, AI storage, AI acceleration, and AI containers. It has the characteristics of high performance, high elasticity, high-speed interconnection, and high cost performance. In terms of AI computing, we provide high-performance instances based on the self-developed GPU hardware architecture X-MAN, which fully meets the performance requirements for computing, storage, and transmission such as AI stand-alone training, distributed cluster training, and AI inference deployment. In terms of AI storage, based on the AI storage architecture, it provides full-chain support for computing from data to the cloud, data storage, data processing and data acceleration. In terms of AI acceleration, through integrated acceleration of storage, training and push, AI tasks are further accelerated by accelerating storage access, model training and inference. In terms of AI containers, AI containers provide sharing and isolation of GPU memory and computing power, integrate with mainstream deep learning frameworks such as PaddlePaddle, TensorFlow, and Pytorch, and support AI task orchestration and management.
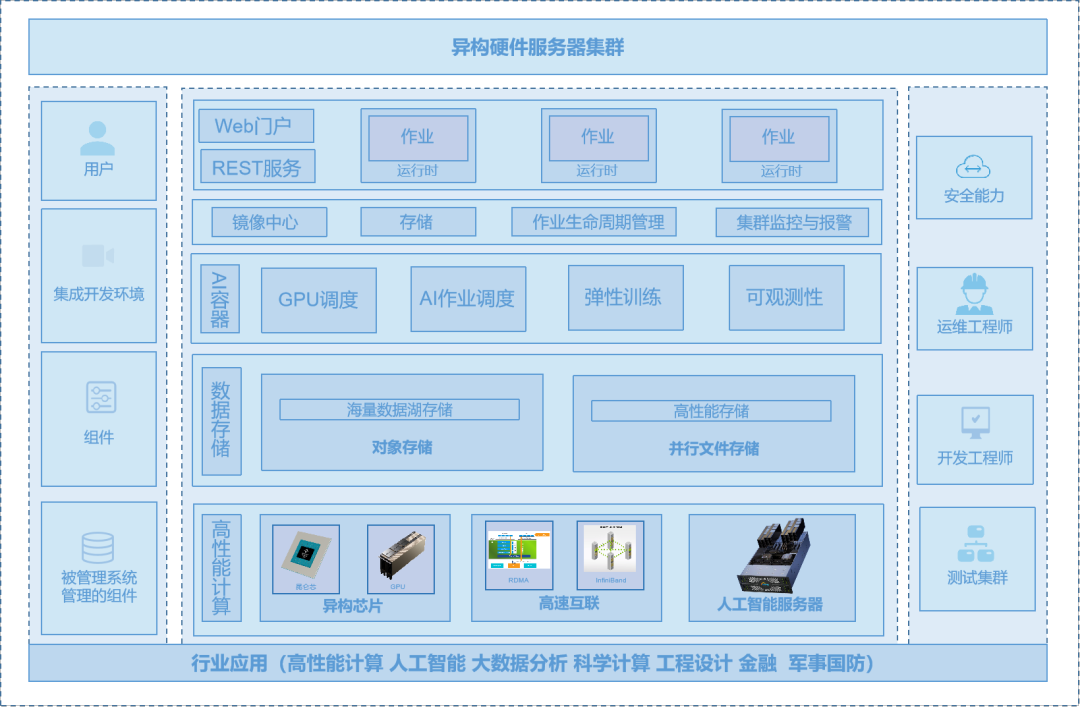
1. Business challenges
1. High risk
Batch replacement of traditional database hardware is risky because of the lack of effective grayscale solutions to gradually introduce changes, and it is difficult for heterogeneous replication solutions to ensure data consistency. If there are uniform problems in the same batch of hardware or operating systems, they will often break out in a concentrated manner, which may cause irreparable losses to the business in severe cases.
2. High cost
Traditional replacement solutions often require the deployment of dedicated environments for long-term verification, which incurs high resource parallel costs. These costs include, but are not limited to, purchasing and maintaining additional hardware, energy consumption, and managing human resources to monitor and maintain these parallel systems.
3. Difficult to maintain
Building a heterogeneous verification environment not only consumes hardware resources, but also makes the entire database infrastructure more complex and more difficult to maintain. This complexity can lead to potential errors and failures, increasing the cost and difficulty of maintenance.
2. Program advantages
1. Compatible and open to support Haiguang, Kunpeng, Intel and other chips and their ecosystems to meet the needs of different users and scenarios
It is compatible with multiple types of chips, including Haiguang, Kunpeng and Intel, and can support the ecosystem of these chips.
2. The database automatically adapts with consistent functions. Users do not need to distinguish the underlying chip form, which is transparent and senseless.
It automatically adapts to different underlying chip forms without caring about the underlying hardware details. It feels like using a unified database with consistent functions.
3. Data consistency, supporting heterogeneous chips, copy data consistency verification, ensuring data consistency and correctness, and having disaster recovery switching capabilities
Ensure the consistency of copy data on heterogeneous chips, and ensure the accuracy and consistency of data through data consistency verification. At the same time, this system also has the capability of disaster recovery switching, which can quickly switch to a backup system in the event of a failure.
4. Hybrid deployment, supporting multiple forms of mixed deployment, mixed deployment of active and backup clusters, mixed deployment in computer rooms, etc., and supporting long-term mixed deployment
Supports a variety of deployment forms, such as multi-copy co-location, active and backup cluster co-deployment, and computer room co-deployment. Different deployment forms can meet different business needs, and the system also supports long-term co-location operation, which greatly improves the availability and stability of the system.
5. Grayscale switching supports switching by available zone (Zone), the finest granularity supports grayscale switching by table partition, and supports smooth grayscale migration and replacement.
It supports grayscale switching. Users can choose to switch by availability zone. The most granular level can be grayscale switching by table partition.
6. Grayscale encryption supports the mixing of encrypted copies of the national secret algorithm, providing a smooth transition solution for globally enabling encrypted storage.
It supports the use of national encryption algorithms for encryption, and can encrypt data during the co-location process, providing a smooth transition solution for enabling encrypted storage globally.
7. Unified management of heterogeneous resources provides a unified view of computing, storage, network and other resources of multiple clusters, and enables multi-cluster network connection and unified mirror management.
Provides a unified view of computing, storage, network and other resources of multiple clusters, enabling multi-cluster network connection and unified management of mirrors.
8. Build an automatic scaling strategy based on multiple indicators and use it with a load balancer to achieve business elasticity
The automatic scaling strategy based on multiple indicators, combined with the load balancer, can achieve elastic expansion and contraction of the business and maintain high availability and performance of the business.
9. Supports the management of multi-architecture bare metal servers such as x86/ARM/localized, helping users achieve automatic discovery on power-on, one-click deployment and unified network management.
It supports the management of multi-architecture bare metal servers such as x86, ARM and localized servers, and can help users realize functions such as automatic discovery on power-on, one-click deployment and activation, and unified network management.
10. Achieve business network connection with virtual machines and containers
Help users connect business networks with different environments such as virtual machines and containers, making communication between different environments smoother and more efficient.
3. Application scenarios
1. High performance computing (HPC)
The HPC field uses heterogeneous clusters to perform scientific calculations such as weather forecasting, seismic analysis, and oil exploration. A typical configuration is to use multi-core CPU servers to form the main cluster, and add GPU servers for parallel acceleration. Different network topologies and interconnections will also be used to optimize throughput and latency.
2. Artificial Intelligence (AI)
AI training tasks will use hundreds or thousands of GPUs to build large-scale heterogeneous clusters, such as NVIDIA's DGX SuperPOD. For different training stages, different types of GPU servers can be flexibly used. AI inference tasks will use specialized AI accelerator cards, which can be flexibly deployed on demand.
3. Big data analysis
Big data platforms such as Apache Hadoop and Spark will build large-scale clusters centered on standard X86 servers, and add GPU servers for parallel acceleration of machine learning algorithms. Different types of analysis tasks can be loaded onto servers of different specifications.
4. Scientific computing
Use heterogeneous clusters to perform astronomical statistical analysis, particle physics simulations, quantum chemical calculations, etc. In addition to GPU servers, specialized hardware accelerators such as FPGA and ASIC will also be used for optimization.
5. Engineering design
The design of automobiles and aerospace requires complex physical simulation, and parallel simulation through heterogeneous clusters can greatly improve efficiency. In addition, GPU rendering and image processing are required.
6. Finance
Financial quantitative trading uses heterogeneous clusters to improve backtesting and trading performance. Adding FPGA can achieve ultra-low latency high-frequency trading. Blockchain also requires large-scale mining clusters to provide computing power.
7. Military and national defense
Heterogeneous clusters can be applied to military simulation, command and control, image recognition and other tasks. For security reasons, sensitive applications use customized chips.