Insert data
insert
We need to insert multiple records into the database table at one time, which can be optimized from the following three aspects.
- Insert data in batches
One insert statement inserts multiple data, but it should be noted that each insert statement is best to insert 500-1000 rows of data, and you have to rewrite another insert statement.
Insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');- Manually control transactions
We can manually control transactions and close open and submit transactions between multiple insert statements to prevent wasting performance by submitting transactions after one insert.
start transaction;
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
insert into tb_test values(4,'Tom'),(5,'Cat'),(6,'Jerry');
insert into tb_test values(7,'Tom'),(8,'Cat'),(9,'Jerry');
commit;- The performance of primary key sequential insertion is higher than that of out-of-order insertion.
主键乱序插入 : 8 1 9 21 88 2 4 15 89 5 7 3
主键顺序插入 : 1 2 3 4 5 7 8 9 15 21 88 89Insert data in bulk
If you need to insert a large amount of data (for example, millions of records) at one time, the insertion performance of using the insert statement is low. In this case, you can use the load command provided by the MySQL database to insert. The operation is as follows

You can execute the following instructions to load the data in the data script file into the table structure:
-- 客户端连接服务端时,加上参数 -–local-infile
mysql –-local-infile -u root -p
-- 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile = 1;
-- 执行load指令将准备好的数据,加载到表结构中
load data local infile '/root/sql1.log' into table tb_user fields
terminated by ',' lines terminated by '\n' ;
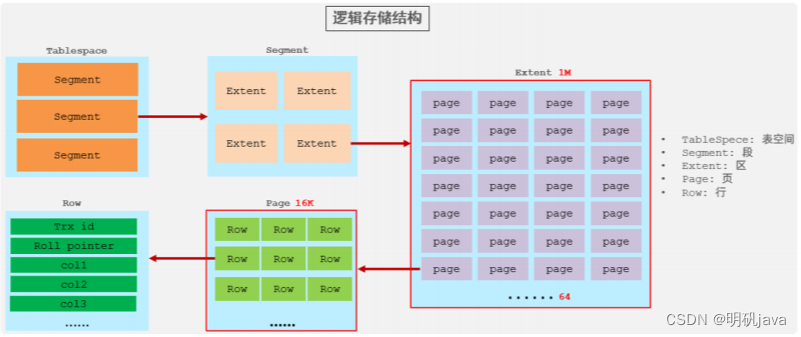
Primary key optimization
Data organization
In the InnoDB storage engine, table data are organized and stored in order according to the primary key. Tables in this storage method are called index organized tables (index organized table IOT).
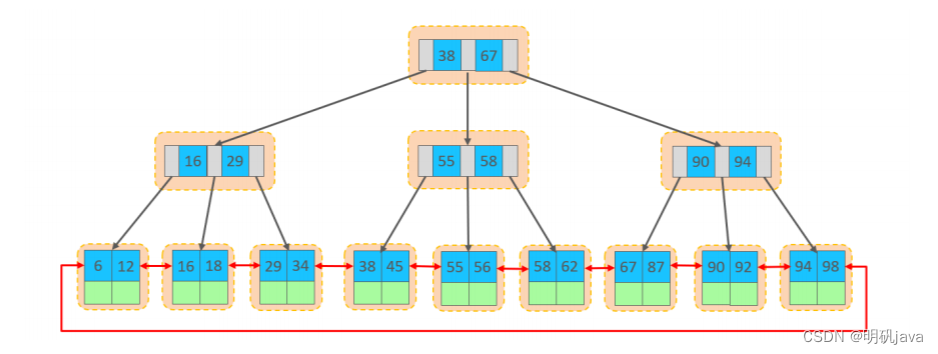
Rows of data are stored on the leaf nodes of the clustered index. In the InnoDB engine, data rows are recorded in logical structure page pages, and the size of each page is fixed, defaulting to 16K. That means that the rows stored in a page are also limited. If the inserted data row is not small in the page, it will be stored in the next page, and the pages will be connected through pointers.
Primary key sequence insertion effect
- Apply for pages from disk and insert them in primary key order

2. The first page is not full, continue inserting to the first page

3. When the first page is also full, write the second page, and the pages will be connected through pointers.

4. When the second page is full, write to the third page

Primary key out-of-order insertion effect
page split
If pages 1# and 2# are already full, the data as shown in the figure is stored.
 At this time, insert the record with ID 50. Because to maintain the order of the primary key in the memory, it should be inserted after 47. The remaining memory of the page where 47 is located is not enough to hold the record 50. At this time, a new page will be opened.
At this time, insert the record with ID 50. Because to maintain the order of the primary key in the memory, it should be inserted after 47. The remaining memory of the page where 47 is located is not enough to hold the record 50. At this time, a new page will be opened.
 However, 50 will not be directly stored in page 3#, but the last half of the data on page 1# will be moved to page 3#, and then 50 will be inserted on page 3#.
However, 50 will not be directly stored in page 3#, but the last half of the data on page 1# will be moved to page 3#, and then 50 will be inserted on page 3#.

After moving the data and inserting the data with ID 50, there is a problem with the data order between these three pages. The next page of 1# should be 3#, and the next page of 3# is 2#. Therefore, at this time, the linked list pointer needs to be reset.

Page merge
The index structure (leaf nodes) of the existing data in the table is currently as follows:

When we delete existing data, the specific effect is as follows: When a row of records is deleted, the record is not actually deleted physically, but the record is marked for deletion and its space becomes allowed to be claimed by other records. use. It is similar to deleting disk space by the operating system, except that it is logically deleted, allowing other programs to overwrite the data in the space.
After we delete records and reach MERGE_THRESHOLD (the default is 50% of the page, you can set it yourself), InnoDB will start to look for the closest page (before or after) to see if the two pages can be merged to optimize space usage.



After deleting the data and merging the pages, insert new data 21 again, then directly insert page 3#

Primary key design principles
- When meeting business needs, try to reduce the length of the primary key as much as possible.
- When inserting data, try to insert sequentially and use AUTO_INCREMENT to auto-increment the primary key.
- Try not to use UUID as the primary key or other natural primary keys, such as ID number.
- During business operations, avoid modification of primary keys.
order by optimization
There are two ways to sort MySQL:
Using filesort: Through table index or full table scan, read the data rows that meet the conditions, and then sort the buffer in the sort buffer Complete the sorting operation in All sorting that does not directly return the sorting results through the index is called FileSort sorting.
Using index: Ordered data is directly returned through ordered index sequential scanning. This situation is called using index. No additional sorting is required, and the operation efficiency is high.
For the above two sorting methods, Using index has high performance, while Using filesort has low performance.When optimizing the sorting operation, we try to optimize it to Using index a>.
When executing the sorting SQL, since there are no indexes for age and phone, when sorting again at this time, Using filesort appears, and the sorting performance is low.
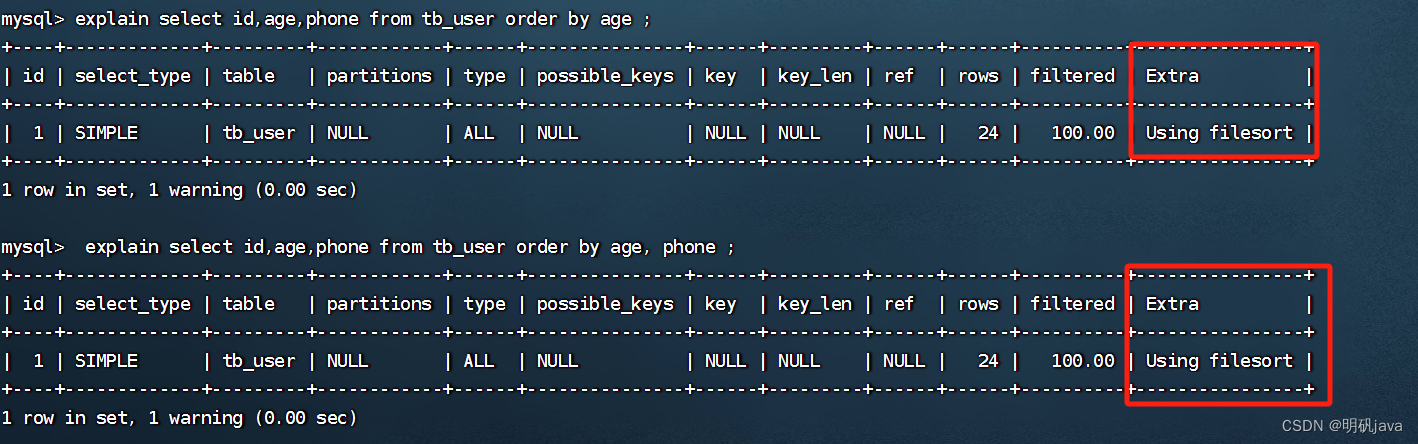
Then we can according to our business, if we always need to order by based on these two fields, then we can completely create a joint index for phone and age.
create index idx_user_age_phone_aa on tb_user(age,phone);After the index is created, it is optimized toUsing index

At this time, if you search in reverse order, Using index also appears, but at this time Backward index scan appears in Extra, This represents the reverse scan index, because in the index we create in MySQL, the leaf nodes of the default index are sorted from small to large, and when we query the sorting, it is from large to small, so when scanning, it is a reverse scan, and it will Backward index scan appears. In the MySQL8 version, descending indexes are supported, and we can also create descending indexes.

At this time, we need to create a reverse index, which can be optimized into a Using index. As long as our sort order has a corresponding index order, it can be optimized into a Using index.
Optimization principles
A. Establish an appropriate index based on the sorting field. When sorting on multiple fields, the leftmost prefix rule is also followed.
B. Try to use covering indexes.
C. Multi-field sorting, one in ascending order and one in descending order. At this time, you need to pay attention to the rules when creating the joint index (ASC/DESC).
D. If filesort is unavoidable, you can appropriately increase the sort buffer size sort_buffer_size (default 256k) when sorting large amounts of data.
group by optimization
If there is no index, grouping is performed. You can see that temporary tables are used and the performance is poor.

We are creating a joint index on profession, age, status.

Execute the same SQL as before to view the execution plan. It has been optimized to using index.If grouping is based solely on age, the temporary table will still be used in the end. Group by also complies with the leftmost prefix rule

In grouping operations, we need to optimize through the following two points to improve performance:
A. During grouping operations, indexes can be used to improve efficiency.
B. During grouping operations, the use of indexes also satisfies the leftmost prefix rule.
limitexcellence

Through testing, we will see that the further back, the lower the efficiency of paging query. This is the problem of paging query.Because, when performing a paging query, if you execute limit 2000000,10 , at this time Requires MySQL before sorting 2000010 records, only returns 2000000 - 2000010 The records of a> . The cost of query sorting is very high. are discarded
Generally, when performing paging queries, performance can be better improved by creating a covering index, or by adding subqueries through the covering index.query form is optimized. We can also query id through limit. Since id is a primary key index, it is more efficient. is used as a temporary table in the form of a subquery to return the sorted id table for multi-table joint query. , the overall query also uses the id index, and the performance is higher
count优化
Overview
MyISAM The engine stores the total number of rows of a table on disk, so execute count(*) will directly return thiscount, the efficiency is very high; but if it is conditional count, MyISAM is also slow.The InnoDB engine is in trouble. When it executes count(*) , it needs to /span>Data is read from the engine line by linecome, then accumulate the count. This is inefficient
Main optimization ideas:
Count by yourself,You can use a database such asredis,Redis itself has self-increasing keys, which can satisfy this business,but if it is a conditional countIt’s more troublesome again. It can be said that this problem is still quite troublesome
count用法
If sorted by efficiency, count( field ) < count(< a i=4>Primary key id) < count(1) ≈ count(*), so Exhausted a>Use count(*) for quantities.
|
count
用
法
|
meaning
|
|---|---|
|
count(
main key)
|
InnoDB
The engine will traverse the entire table and take out the primary key
id
value of each row , returned to the service layer. After the service layer obtains the primary key, directly accumulates it row by row(
The primary key cannot be
null)
|
|
count(
字 段)
|
There is no not null constraint
: InnoDB
The engine will traverse the entire table, take out the field values of each row, and return it to the service layer. The service layer determines whether it is null
, if not
null
, the count is accumulated.
There is not null constraint
:
InnoDB
The engine will traverse the entire table and compare the field values of each row Take them out and return them to the service layer, directly accumulate them row by row.
|
|
count(
数
character
)
|
InnoDB
The engine traverses the entire table but does not retrieve values. For each row returned, the service layer puts a number
"1" in it and directly accumulates it by row.
|
|
count(*)
|
InnoDB
The engine
will not take out all the fields
, but has specially optimized it. If no value is taken, the service layer directly accumulates rows .
|
updateimprovement
When we execute this update statement, this row of data is locked.
update course set name = 'javaEE' where id = 1 ;
update course set name = 'SpringBoot' where name = 'PHP' ;
Because
InnoDB's row lock is a lock added to the index, not a lock added to the record, and the index cannot be invalidated, otherwise it will be lost. Row locks are upgraded to table locks. When we perform DML operations, we try to use the index as the search condition to avoid upgrading to table locks and affecting concurrency