Understanding function references, anonymous functions, lambda expressions, and inline functions
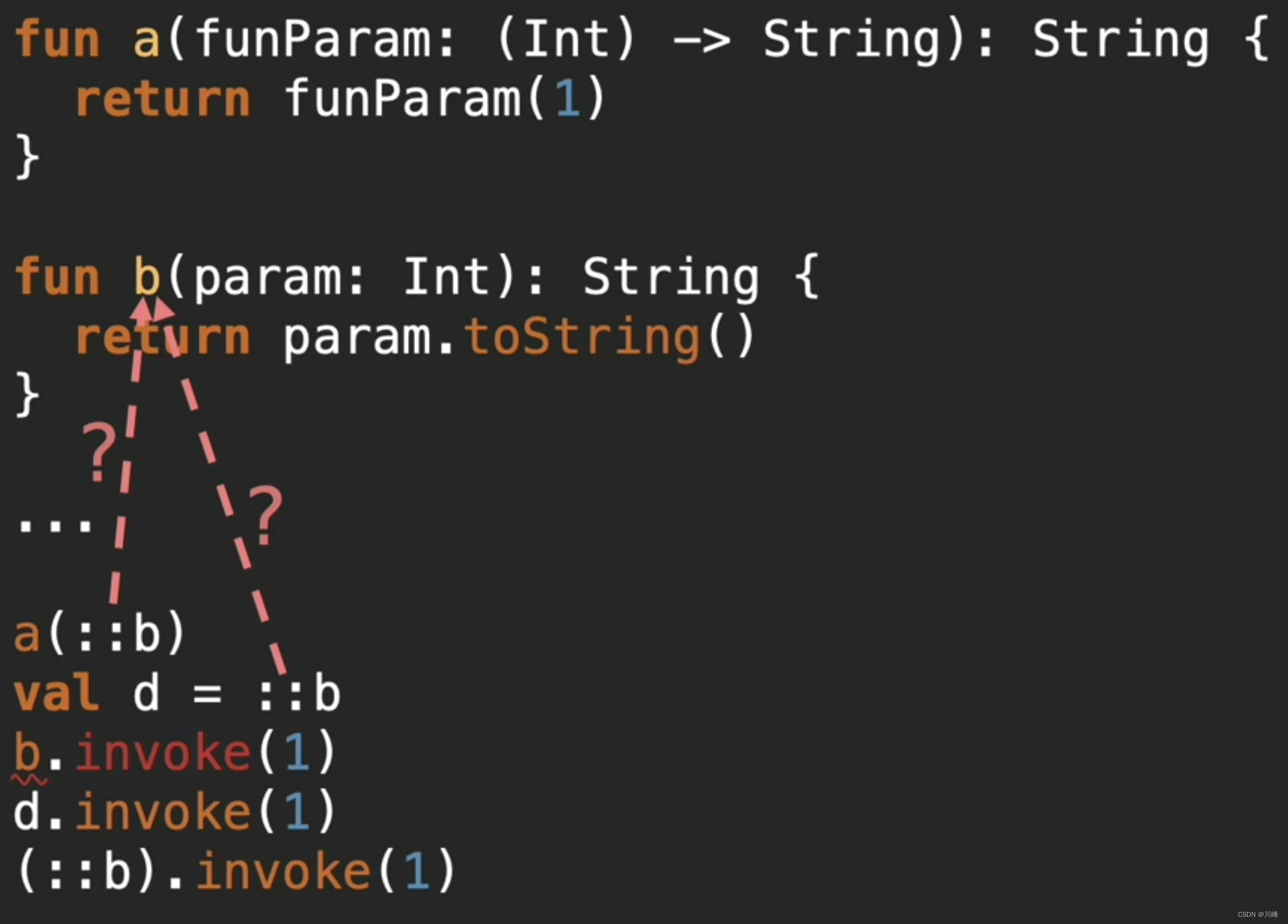
- The essence of a double colon referencing a function is to generate a function object
- Only function objects have
invoke()methods, but functions do not have this method - Function in kotlin has its own type, butthe function itself is not an object, so to reference the function type, you must use double colons The function is converted into an object so that the object can be assigned later
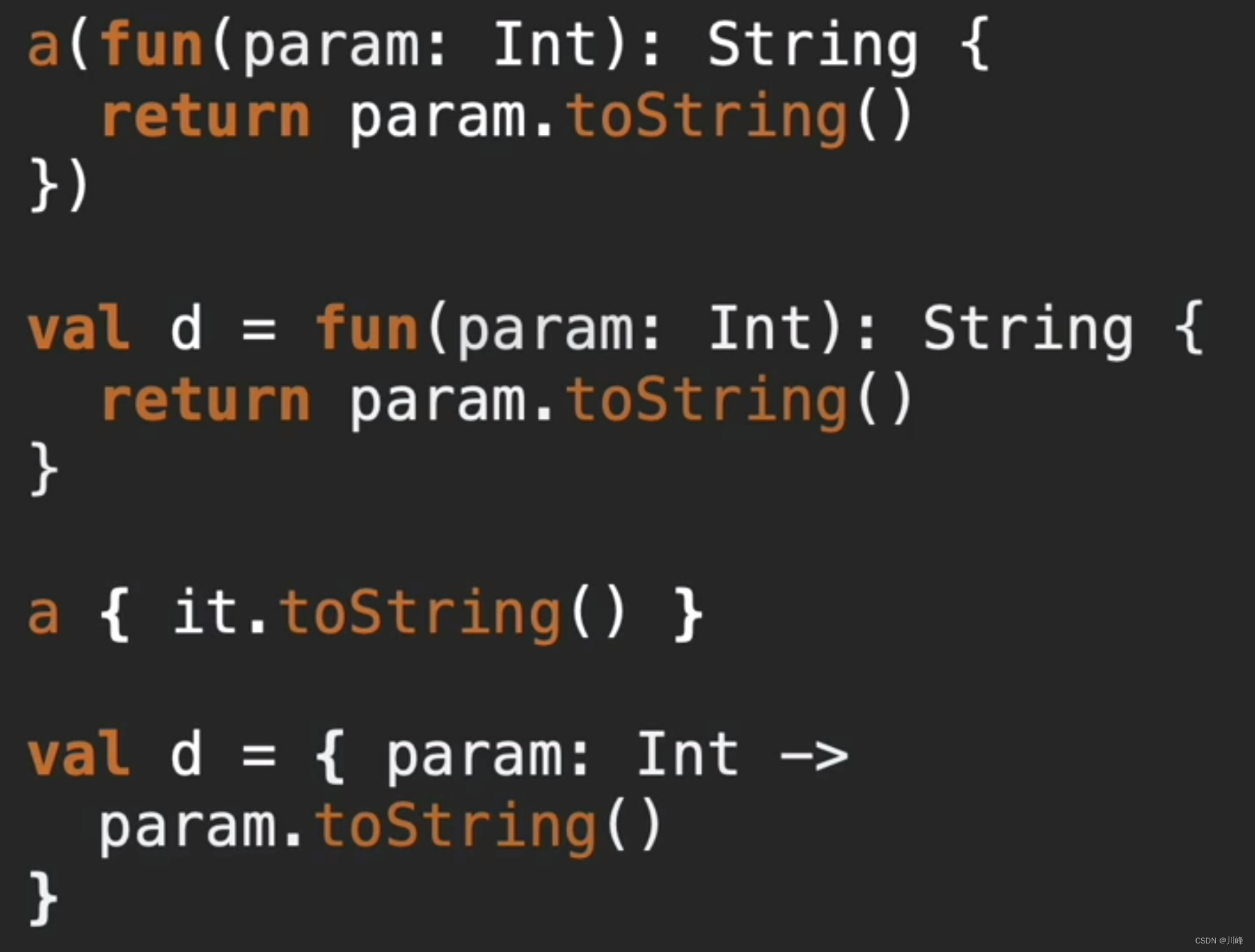
- An anonymous function is an object, it is not a function
- Anonymous functions and double colon reference functions are the same thing
- The lambda expression is a special anonymous function object, which can omit parameters and caller parentheses, etc., which is more convenient.
- Because an anonymous function is an object, it (including lambda expressions) can be passed as a parameter
- Double-colon function reference, anonymous function object, and lambda are essentially function type objects.
- Although Java8 also supports lambda writing (SAM conversion), there are essential differences between lambda in Java8 and lambda in kotlin. One is the simplified writing method of the compiler, and the other is the transfer of function objects. Even if it can be written as lambda in Java, it is an anonymous object generated by an interface class.

-
constin Kotlin is used to declare compile-time constants. Its function is the same asstatic finalin Java. It will directly replace the variable at the call site with a literal. But it can only be written in top-level scope.
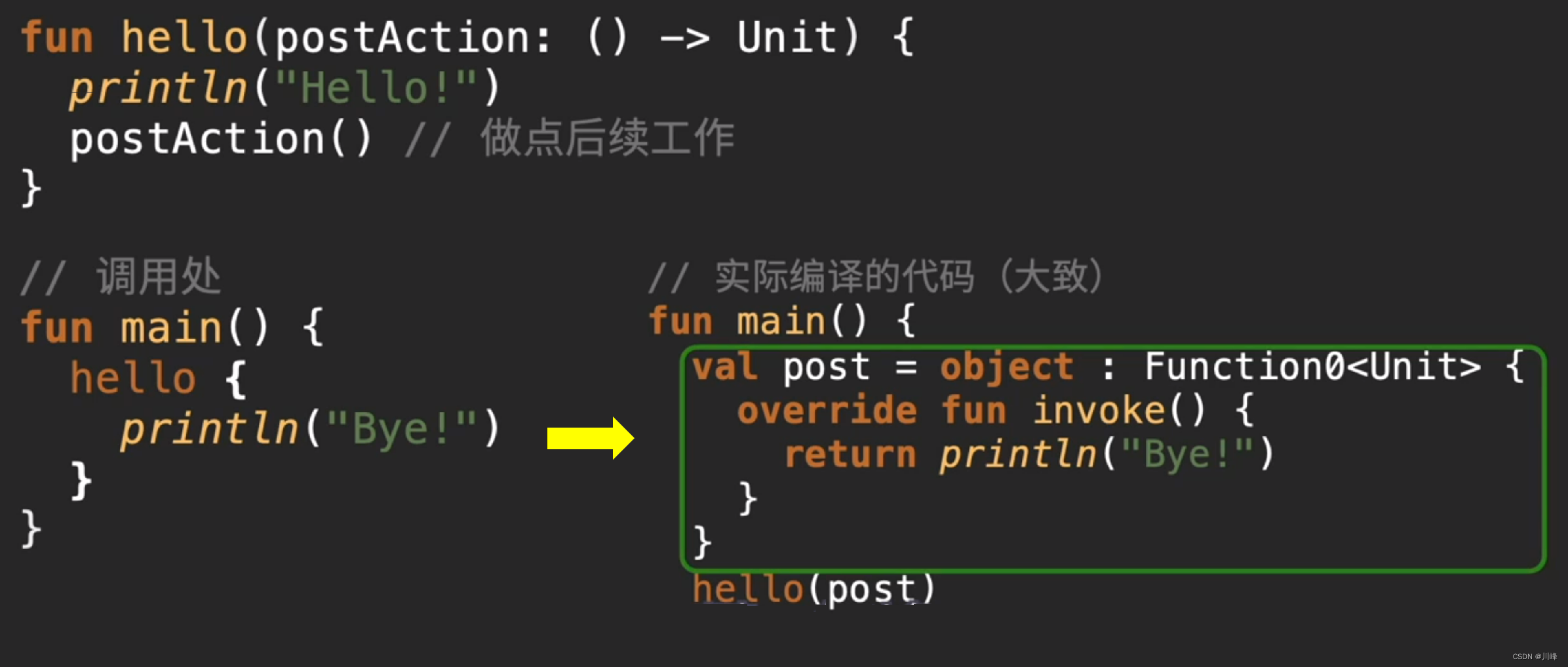

- After the function object is passed as a parameter in kotlin, a temporary object will be created for the real function call.
- If this kind of function is used in a high-frequency call scenario such as
forloop, it will cause memory jitter and frequent GC due to the creation of a large number of temporary objects, and even cause OOM.
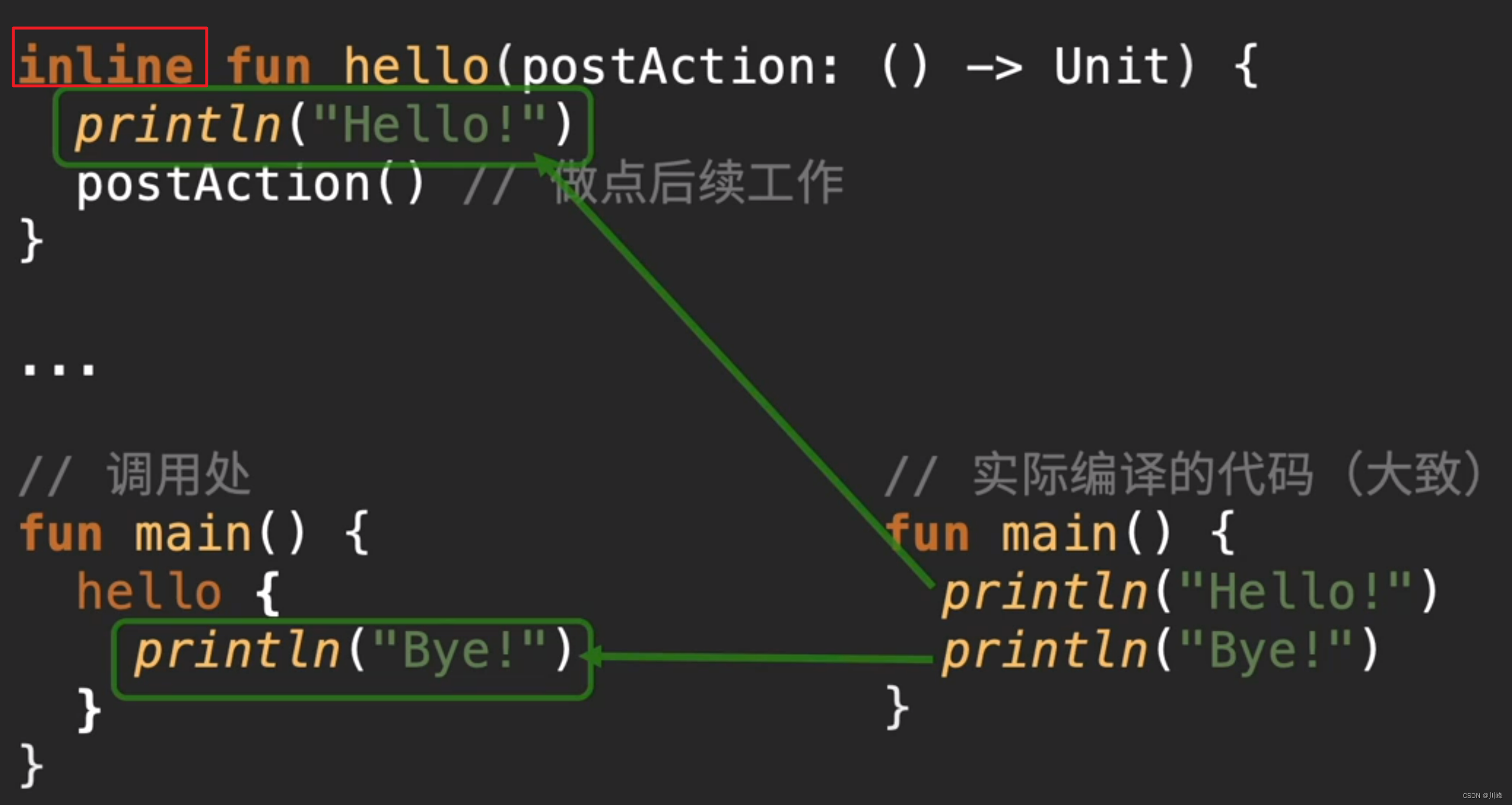
- If you add the
inlinekeyword to the function, it will insert the called function into the calling place and flatten it, thus avoiding the impact of generating temporary function objects. Therefore,inlinekeyword optimization should be aimed at high-order functions.
inline、nolinline、crossinline
- inline:Compile the function by inlining (that is, the function content is inserted directly into the calling point)
- noinline: Partially turn off this optimization to get rid of the restriction that "function type parameters cannot be used as objects"
- crossinline: allows function type parameters in inline functions to be called indirectly, at the cost of not being used in Lambda expressions< /span>
return
noinline and crossinline are mainly used to solve some possible side effects or collateral damage after adding inline, and to carry out remedial measures. As for when You need to use them, there is no need to remember the rules as Android Studio will prompt for it when needed.
What is SAM conversion
SAM conversion (Single Abstract Method) is a simplified writing method forinterface classes with only one method, for example:
// Single Abstract Method
public interface Listener {
void onChanged();
}
public class MyView {
private Listener mListener;
public void setListener(Listener listener) {
mListener = listener;
}
}
MyView view = new MyView();
view.setListener(new Listener() {
@Override
public void onChanged() {
}
});
If you write it this way, the compiler will prompt you to convert it into a lambda expression (jdk 1.8):
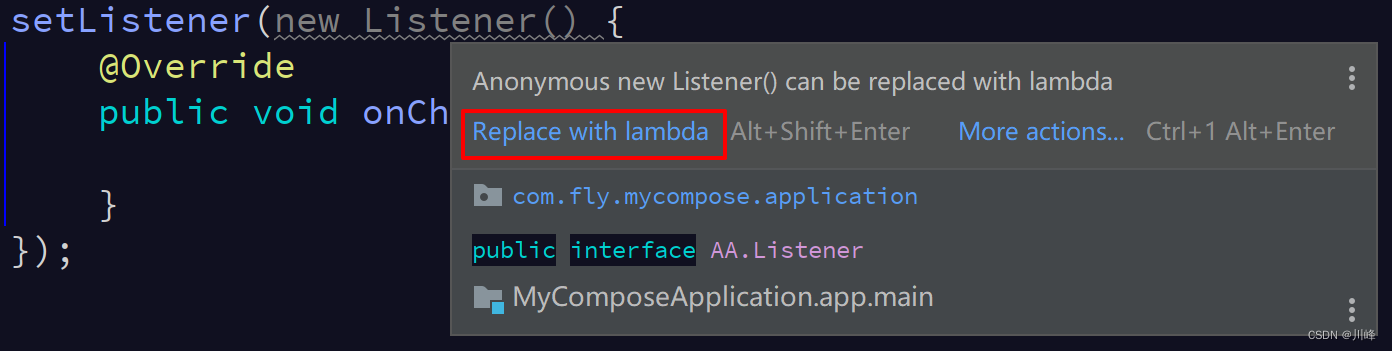
So the code can be simplified to the following:
MyView view = new MyView();
view.setListener(() -> {
// todo
});
Of course, if you are calling java code in kotlin, you can also remove the parentheses and directly call the method followed by {} to become a more thorough lambda writing method.
MyView().setListener {
// todo
}
out and in in generics
Currently in KotlinoutRepresentativeCorporate,inRepresentative< /span> Java-like /span>:Lower limit signchange,Thank you for your deep understanding of Kotlin's knowledgereverse change
// Kotlin 使用处协变
fun sumOfList(list: List<out Number>)
// Java 上界通配符
void sumOfList(List<? extends Number> list)
// Kotlin 使用处逆变
fun addNumbers(list: List<in Int>)
// Java 下界通配符
void addNumbers(List<? super Integer> list)
We know that Java's upper bound wildcard and lower bound wildcard are mainly used for the input and output parameters of functions. One of them is read-only and the other is write-only. In Kotlin, these two are named out and in are more clear in meaning.
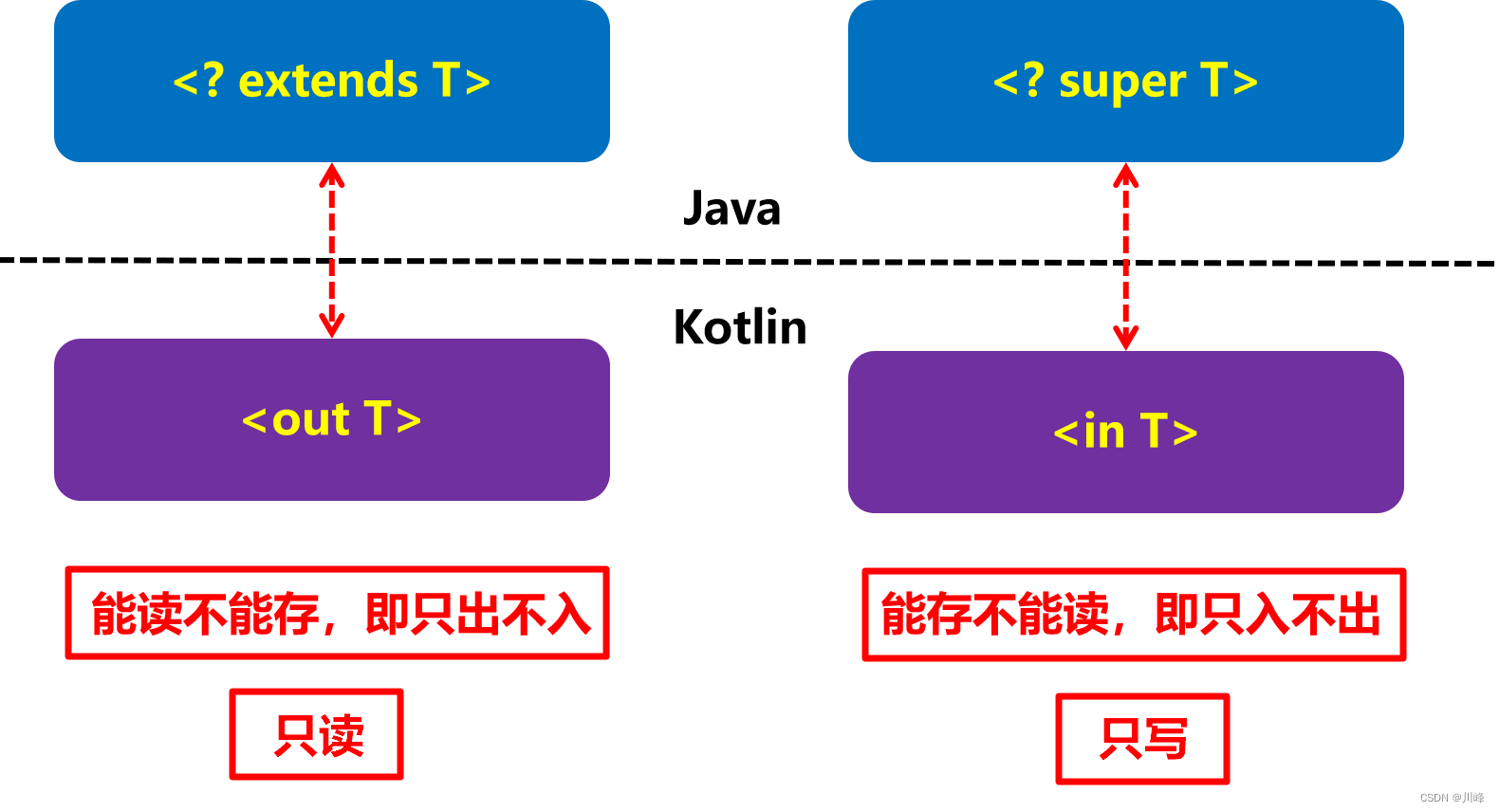
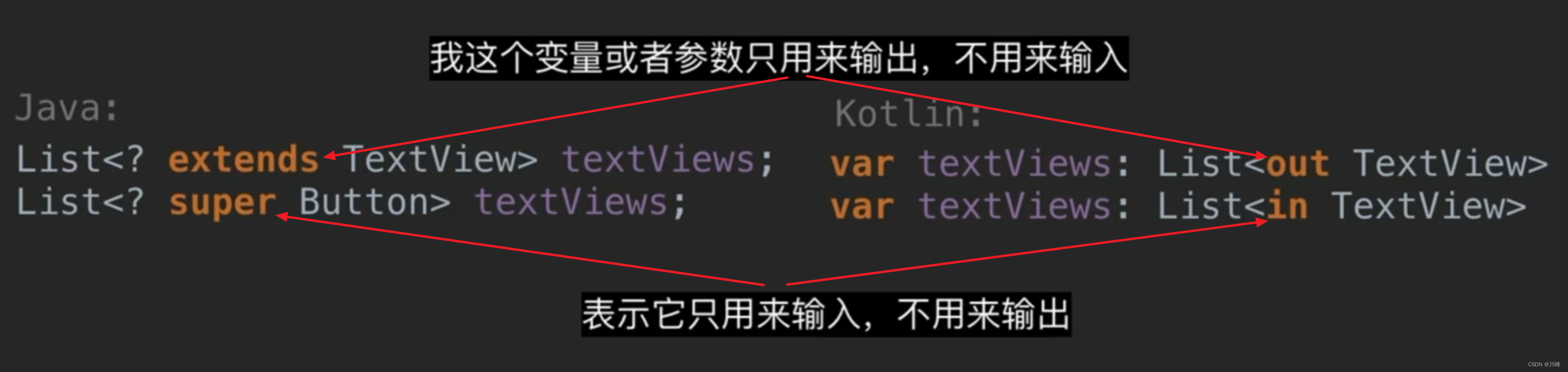

In general, Kotlin generics are more concise and safer, but like Java, they are subject to type erasure and are compile-time generics.
In addition, kotlin can directly use out or in to specify the generic read and write mode on the class, but Java cannot:
// 这个类,就是只能获取,不能修改了
// 声明的时候加入 一劳永逸了 <out T>
class Worker<out T> {
// 能获取
fun getData(): T? = null
// 不能修改
/*
* fun setData(data: T) { }
* fun addData(data: T) { }
*/
}
// 这个类,就是只能修改,不能获取
// 声明的时候加入 一劳永逸了 <in T>
class Student<in T> {
/* fun a(list: Mutablelist<in T>) **/
fun setData(data: T) {
}
fun addData(data: T) {
}
// 不能获取
// fun getData() : T
}
// Java 不允许你在声明方向的时候,控制读写模式
public class Student /*<? super T>*/ {
}

- Generics on class
TThe precedingoutorinkeyword applies to the entire class scope and all users using this Generic place. - Why is Kotlin designed like this: It means that all scenarios using
Tare only used for output or only for input, so in order to avoid that I will It's so troublesome to writeoutfor variables or parameters, so I just declare it directly on the class. - When to use
outorin: This is a design issue. The designer of the class needs to consider the responsibilities of this class, whether it is only used Used for production or only for consumption.
The difference in assignment when using out or in on a class:
- A subclass generic object can be assigned to a parent class generic object using
out - Generic objects of the parent class can be assigned to generic objects of the subclass using
in
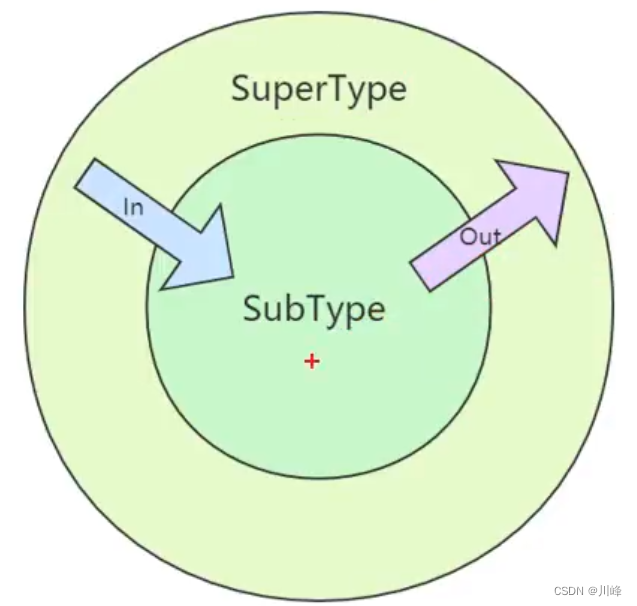
// 子类泛型对象可以赋值给父类泛型对象,用 out
val production1: Producer<Food> = FoodStore()
val production2: Producer<Food> = FastFoodStore()
val production3: Producer<Food>= BurgerStore()
// 父类泛型对象可以赋值给子类泛型对象,用 in
val consumer1: Consumer<Burger> = Everybody()
val consumer2: Consumer<Burger> = ModernPeople()
val consumer3: Consumer<Burger> = American()
For the assignment of , using out and in has the same behavior as Java's upper and lower bound wildcards.
* in Kotlin generics is equivalent to ? in Java generics:

The difference between multiple inheritance of generic parameters of classes in Java and Kotlin:
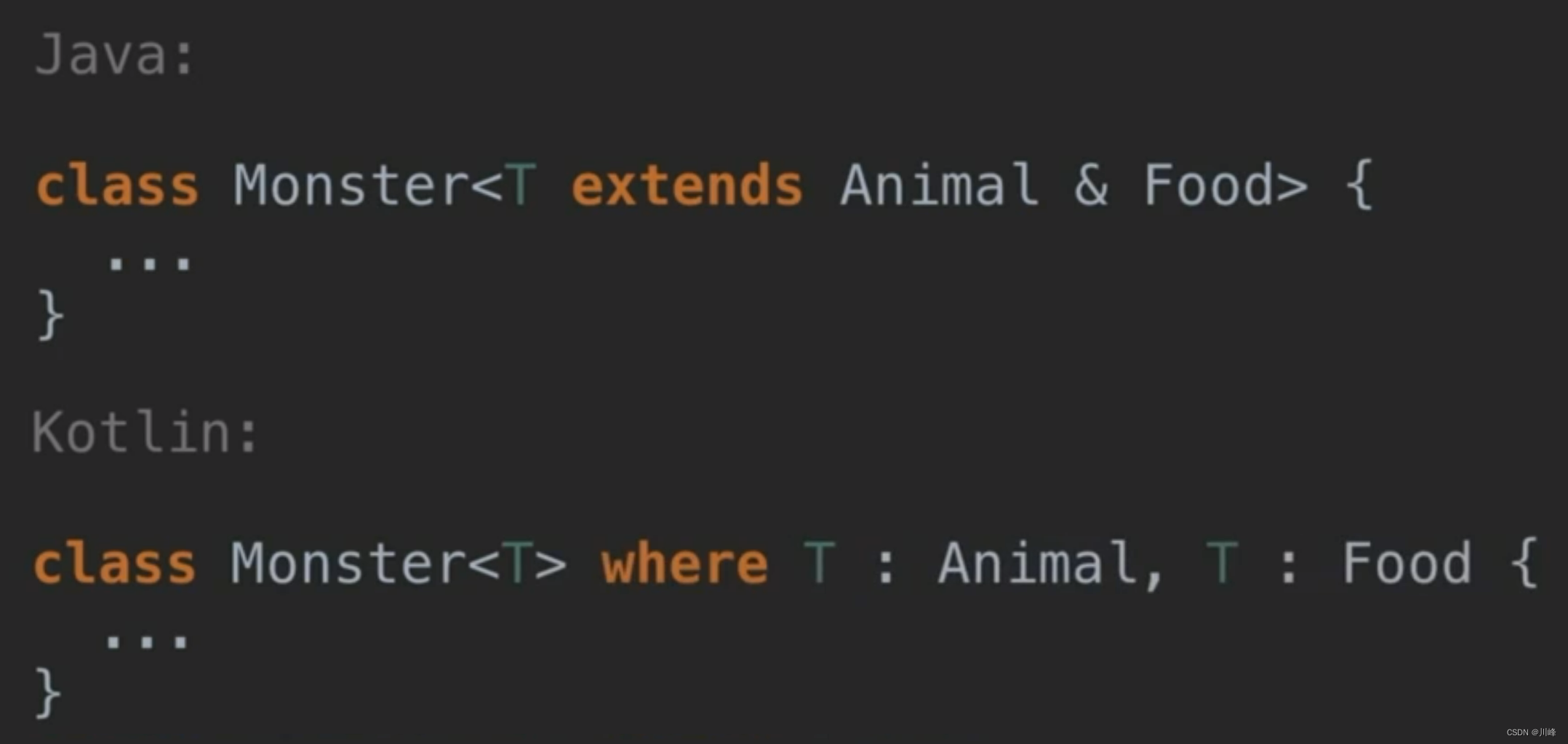
Kotlin generic method example:
fun <T> instanceRetrofit(apiInterface: Class<T>) : T {
// OKHttpClient 用于请求服务器
val mOkHttpClient = OkHttpClient().newBuilder()
.readTimeout(10000, TimeUnit.SECONDS) // 添加读取超时时间
.connectTimeout(10000, TimeUnit.SECONDS) // 添加连接超时时间
.writeTimeout(10000, TimeUnit.SECONDS) // 添加写出超时时间
.build()
val retrofit: Retrofit = Retrofit.Builder()
.client(mOkHttpClient) // 请求方,处理响应方
.addCallAdapterFactory(RxJava2CallAdapterFactory.create()) // 使用 RxJava 处理响应
.addConverterFactory(GsonConverterFactory.create()) // 使用 Gson 解析 JavaBean
.build()
return retrofit.create(apiInterface)
}
To briefly summarize:
Although the meanings of kotlin's out in and Java's <? extends T> and <? super T> are the same, the writing methods are slightly different:
- Java's upper bound wildcards and lower bound wildcards can only be used as method parameters, for input and output parameters, and cannot be written directly to the class.
-
outinin Kotlin can be written directly on the class, which directly indicates that the genericTis used in the entire class and has this meaning. - When the generic
Tis declared asouton the class, it means thatTcan only be output from the current class , and cannot be entered. - When the generic
Tis declared asinon the class, it means thatTcan only be input from the current class , but cannot be output.
Common extension functions apply, also, run, let in the Kotlin standard library
When using it, you can make some judgments through simple rules:
- needs to return itself -> choose from
applyandalsothisUse in scope as parameter ----> selectapplyitUse in scope as parameter ----> selectalso
- does not need to return itself -> choose from
runandletthisUse in scope as parameter ----> selectrunitUse in scope as parameter ----> selectlet
applySuitable for performing additional operations on an objectletis suitable for use when is empty (it is better to use member variables instead of local variables, local variables are more suitable to useif)withSuitable for the same object for multiple operations time
apply VS also
applyThe return values of and also are the objects of the current caller, that is, the current instance of the T type:
public inline fun <T> T.apply(block: T.() -> Unit): T {
block()
return this
}
public inline fun <T> T.also(block: (T) -> Unit): T {
block(this)
return this
}
Both of them are extension functions of the current callerT type, but in apply is also the current The caller is an extension function of type , so can use to access the current object, and in =7> is just an ordinary function, but the parameter of this ordinary function is passed in the current object, so it can only be used in access the current object. blockTlambdathisalsoblocklambdait
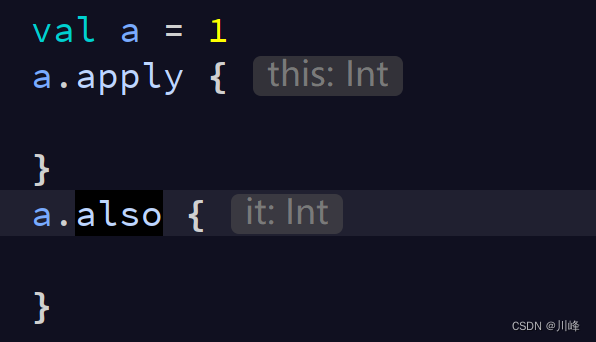
applyIt is often used to call some operations on an object instance immediately after creating it:
ArrayList<String>().apply {
add( "testApply")
add("testApply")
add( "testApply")
println("$this")
}.also {
println(it)
}
let VS run
letThe return values of and run are both the return values of block, that is, the return value of lambda expression: < /span>
public inline fun <T, R> T.let(block: (T) -> R): R {
return block(this)
}
public inline fun <T, R> T.run(block: T.() -> R): R {
return block()
}
Both of them are extension functions of the current callerT type, but in run is also the current The caller is an extension function of type , so can use to access the current object, and in =7> is just an ordinary function, but the parameter of this ordinary function is passed in the current object, so it can only be used in access the current object. blockTlambdathisletblocklambdait
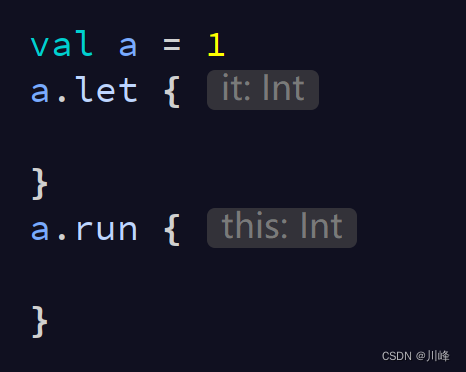
let One of the more commonly used operations isnull operation:
// 避免为 nu1ll 的操作
str?.let {
println(it.length)
}
object singleton
We know that object is the singleton pattern born in kotlin. Let’s take a look at what it looks like when translated into Java code:
object Singleton {
var x: Int = 2
fun y() {
}
}
The above code is compiled into Java bytecode and decompiled to the following code:
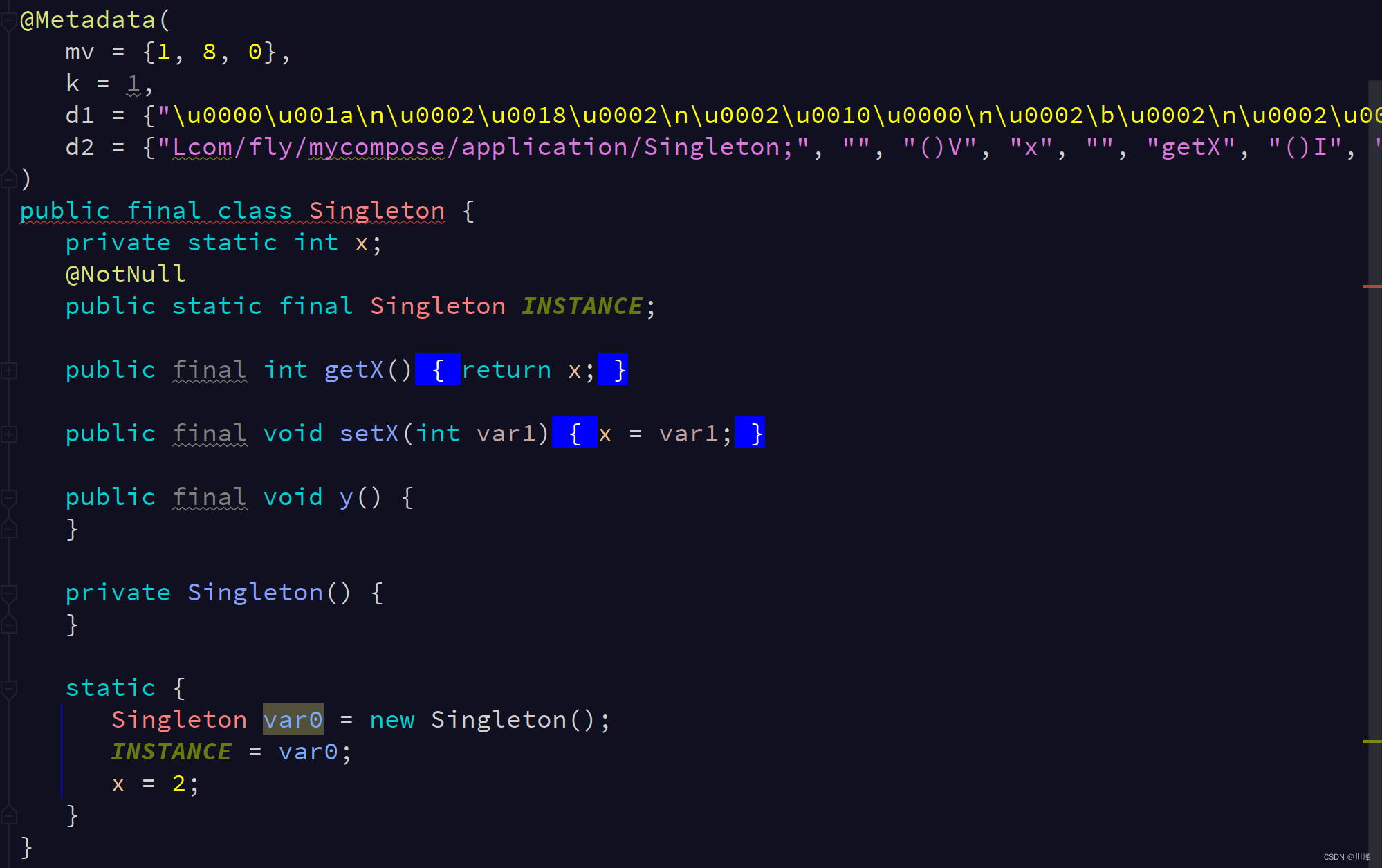
In fact, it isa single instance of the bad guy pattern.
If you want to generate a singleton for an ordinary class, you can use the companion object companion object to generate:
class Singleton {
companion object {
var x: Int = 2
fun y() {
}
}
}
After the above code is translated into Java, it looks like this:
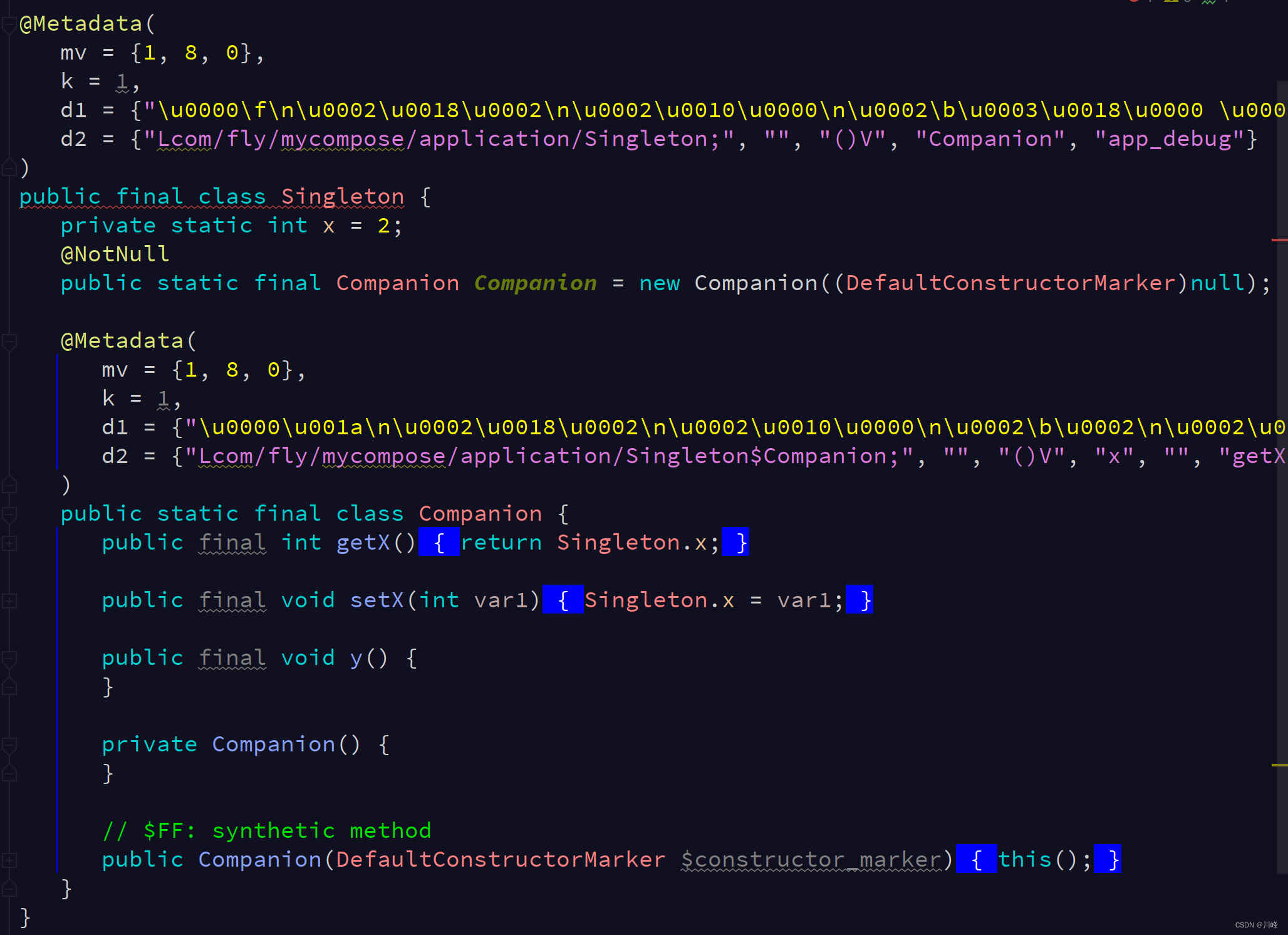
We see that it is still asingle case of the villain pattern, but the object instance of this villain is an object named Instance object of a>Companion'sstatic inner class. In addition, only the member attributes in companion object are placed in the outer class, while the member methods in companion object are placed in the static inner class.
If you want to implement the singleton pattern of the static inner class version in Java:
public class Singleton {
private Singleton() {
}
private static class SingletonHolder {
/** 静态初始化器,由 JVM 类加载过程来保证线程安全 */
private static Singleton instance = new Singleton();
}
public static Singleton getInstance() {
return SingletonHolder.instance;
}
}
It can be written like this:
class Singleton private constructor() {
private object Holder {
val INSTANCE = Singleton()
}
companion object {
val instance = Holder.INSTANCE
}
}
Two very useless things in Kotlin: Nothing and Unit
The reason why these two things are useless is because they are used for marking and prompting. It can only be said that their actual usefulness is not that great, but they are more convenient for marking and reminding.
For example, in Java, you can see writing similar to the following in various source codes:
/**
* 当遇到姓名为空的时候,请调用这个函数来抛异常
* @return throw NullPointerException
*/
public String throwOnNameNull() {
throw new NullPointerException("姓名不能为空!");
}
Corresponding to the equivalent writing method in Kotlin:
/**
* 当遇到姓名为空的时候,请调用这个函数来抛异常
*/
fun throwOnNameNull() : String {
throw NullPointerException("姓名不能为空!")
}
The main function of is to throw an exception, but if it is written like this, it will be very confusing. It is obviously just throwing an exception, but the return value is String, so At this time, you can use Unit or Nothing to replace it:
/**
* 当遇到姓名为空的时候,请调用这个函数来抛异常
*/
fun throwOnNameNull() : Nothing {
throw NullPointerException("姓名不能为空!")
}
In this way, when developers see this function, they will know that it will return nothing. It's just a reminder.
Nothing can also be used as a generic argument to serve as ablank placeholder, for example:
val emptyList: List<Nothing> = listOf()
var apples: List<Apple> = emptyList
var users: List<User> = emptyList
var phones: List<Phone> = emptyList
var images: List<Image> = emptyList
val emptySet: Set<Nothing> = setOf()
var apples: Set<Apple> = emptySet
var users: Set<User> = emptySet
var phones: Set<Phone> = emptySet
var images: Set<Image> = emptySet
val emptyMap: Map<String, Nothing> = emptyMap()
var apples: Map<String, Apple> = emptyMap
var users: Map<String, User> = emptyMap
var phones: Map<String, Phone> = emptyMap
var images: Map<String, Image> = emptyMap
val emptyProducer: Producer<Nothing> = Producer()
var appleProducer: Producer<Apple> = emptyProducer
var userProducer: Producer<User> = emptyProducer
var phoneProducer: Producer<Phone> = emptyProducer
var imageProducer: Producer<Image> = emptyProducer
The only advantage of writing this way is that it is simple and convenient and saves memory.
NothingAnother function is that when you don’t know what to return, you can return it, for example:
fun sayMyName(first: String, second: String) {
val name = if (first == "Walter" && second == "White") {
"Heisenberg"
} else {
return // 语法层面的返回值类型为 Nothing,赋值给 name
}
println(name)
}
Although is not written explicitly here, at the grammatical level, return returns Nothing.
For Unit, it is mainly used to benchmark the void keyword in Java, indicating that nothing is returned, that is, empty is returned. Why should we design this? Can't we just use void directly? This is because the void keyword in Java means that it returns null, but itis not an actual type. In some places, you cannot use it as a type to express the meaning of "returning nothing". For example, the most common example is AsyncTask that was often used in previous development:
class BackgroundTask extends AsyncTask<String, Void, Void> {
@Override
protected Void doInBackground(String... strings) {
// do something
return null;
}
@Override
protected void onProgressUpdate(Void[] values) {
super.onProgressUpdate(values);
}
@Override
protected void onPostExecute(Void o) {
}
}
Recall the three generic parameters of AsyncTask:public abstract class AsyncTask<Params, Progress, Result>
Params:doInBackgroundThe accepted parameter type of the methodProgress:onProgressUpdateThe accepted parameter type of the methodResult: The accepted parameter type of theonPostExecutemethod, and the return parameter type of thedoInBackgroundmethod
In the above code, sincevoid is a keyword, not a type, it cannot be used as an actual parameter in the position of a generic, so a very embarrassing scene will occur. , we must recreate a type similar to the void keyword, that is, capitalized Void (it is actually a class), and in the above code, we see The return parameter type of the doInBackground method is Void, but it is actually return instead of null. And if you don’t write thisnull, it won’t compile. This is very embarrassing.
In order to avoid this embarrassing scenario, kotlin simply defines a Unit type to represent this Void, which, you can use it to define variables, and it can appear anywhere a type is required. is an actual type

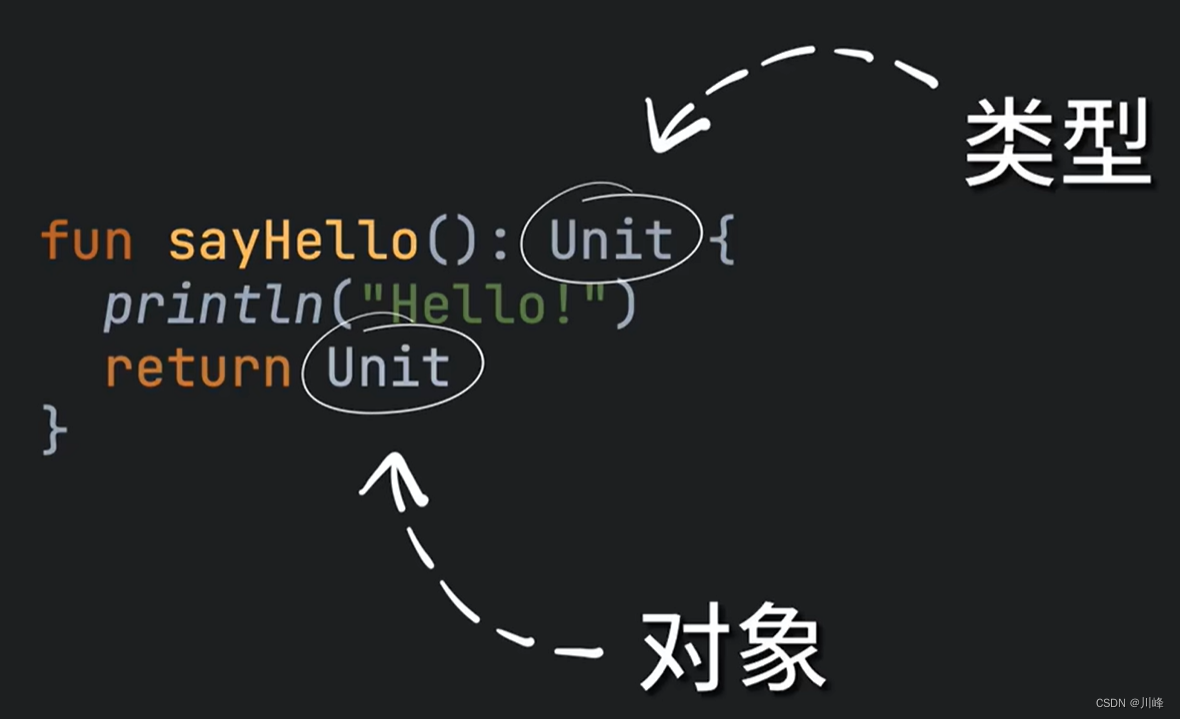
But when general functions in Kotlin do not have a return value, we can omit writing this Unit.
Unit is more commonly seen in lambda expressions and parameter definitions of higher-order functions, for example:
fun foo(block : (Int, String) -> Unit) : Unit {
return block(123, "hello")
}
val sum : (Int, Int) -> Unit = {
x, y -> x + y }
fun main() {
val a = sum(1, 2)
}
To be precise, its main use in Kotlin is to express function types, because if it is just a keyword instead of a type, then you cannot write it where you need to express the function type.
About Unit Another common scenario is the use of the side effect API of Jetpack Compose, for example:
LaunchedEffect(Unit) {
...
}
This way of writing seems strange, but you can understand it after taking a look at the source code of Unit:
/**
* The type with only one value: the `Unit` object. This type corresponds to the `void` type in Java.
*/
public object Unit {
override fun toString() = "kotlin.Unit"
}
We found that it is a object singleton, and object corresponds to a final class in Java, so object The singleton is unchanged at runtime, it is a constant.
SoLaunchedEffect(Unit) can also be written as LaunchedEffect(1), LaunchedEffect(2), LaunchedEffect("aaa"), Both a> directly. LaunchedEffect(true) are fine, but when you can’t think of what to write, it’s more convenient to write Unit
interface proxy by
It is similar to the proxy pattern, but it is a little different. Kotlin's by is more about delegating the implementation of an interface to an implementation class object.
For example, ContextWrapper in Android delegates all operations on Context to an internal one called mBase Context Member object to process:
public class ContextWrapper extends Context {
Context mBase;
public ContextWrapper(Context base) {
mBase = base;
}
@Override
public AssetManager getAssets() {
return mBase.getAssets();
}
@Override
public Resources getResources() {
return mBase.getResources();
}
@Override
public PackageManager getPackageManager() {
return mBase.getPackageManager();
}
@Override
public ContentResolver getContentResolver() {
return mBase.getContentResolver();
}
...
}
For another example, if I want to customize a object of type User to implement requirements such as sorting by age, I can write like this: List
class UserList implements List<User> {
List<User> userList;
public UserList(List<User> userList) {
this.userList = userList;
}
public List<User> higherRiskUsers() {
...}
public void sortWithAge() {
...}
@Override
public int size() {
return 0;
}
@Override
public boolean isEmpty() {
return false;
}
@Override
public boolean contains(@Nullable Object o) {
return false;
}
......
}
This is to delegate the operation of List to the internal userList. You can pass in a ArrayListOr an implementation ofLinkedList for it.
But if we write it this way, we find that there are many more methods that are not needed but have to be written, such as size(), isEmpty(), etc., if you use Delegating using Kotlin’s by keyword will simplify things a lot, for example:
class UserList(private val list: List<User>): List<User> by list {
public List<User> higherRiskUsers() {
...}
public void sortWithAge() {
...}
}
In this way, we don’t need to write those methods that have to be written but are not nutritious. Instead, we can hand them over to the implementation class instance of the list parameter passed in the constructor. Objects automatically implement these methods. We only need to care about how to implement the business methods that really need to be added in this class.
To sum up its syntax is:
class 类名(val 实际接口的实现者[a] : 接口类) : 接口类 by [a] {
}
Where a is passed in the actual implementation object instance of the interface to be implemented.
Of course, when using the by keyword, you can also not completely delegate it to the instance object passed in by the constructor. If a method of the implemented interface is overridden in the class, it will It is more flexible to use what you overwrite instead of the object handed to the delegate.
For example, there is one in Kotlin's coroutine source code called SubscribedSharedFlow that delegates to SharedFlow, but it does not fully delegate to the value passed in by the constructor. sharedFlow object, but overrides the method of the SharedFlow interface: collect
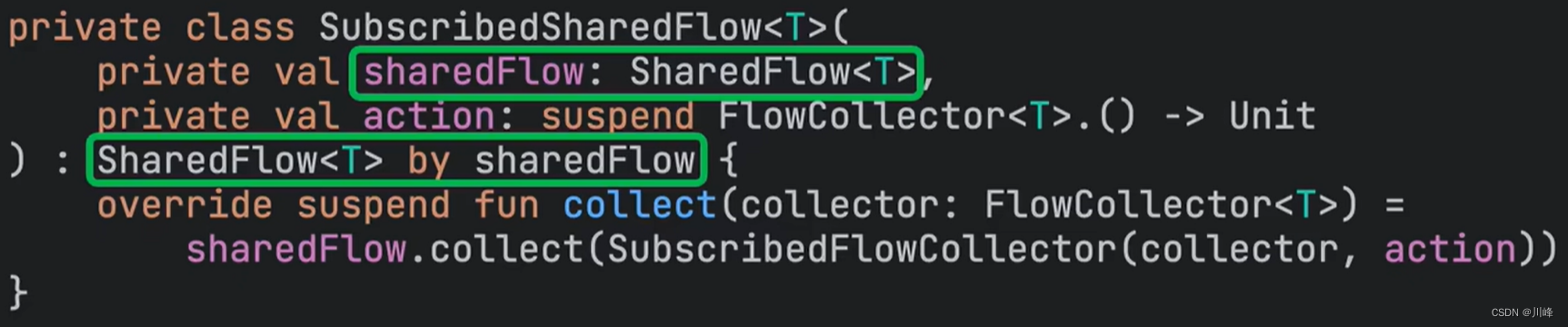
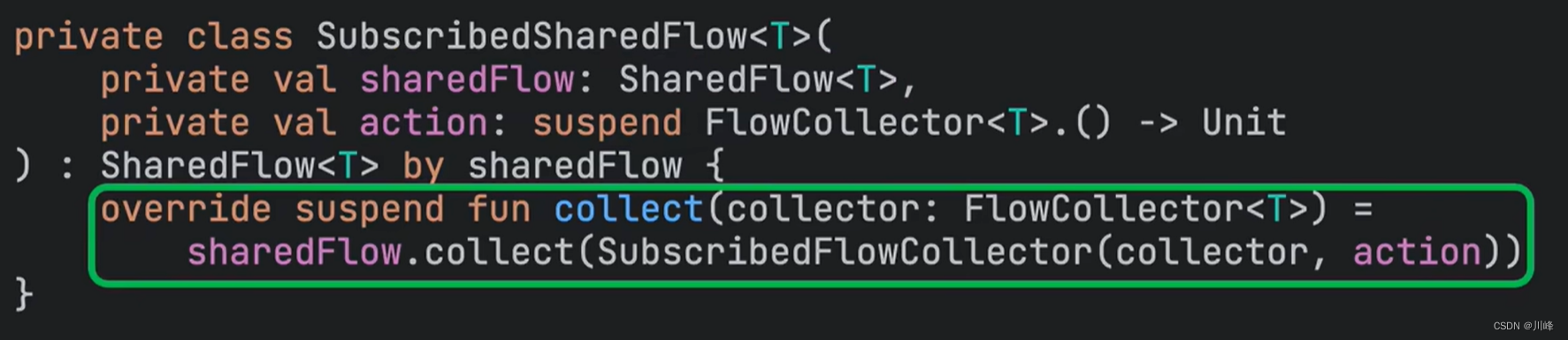
In this way, we can perform some kind of "local customization" function. This feels a bit similar to Java. You inherit a parent abstract class, but you are too lazy to implement each of its abstract methods, but you want to use it when needed. When you are free to override one of its abstract methods, kotlin's by keyword solves this trouble.