concept
Sorting problems can be divided into internal sorting and external sorting. If the entire sorting process can be completed without accessing external memory, this type of sorting problem is called internal sorting; conversely, if the number of records participating in the sorting is large and the entire sequence sorting process cannot be completed in memory, then this type of sorting problem is called The sorting problem is external sorting.
In internal sorting, if for two equal elements K i and K j (i ≠ j) Ki and Kj (i≠j) Ki和Kj(i=j), in the pre-exclusion order R i Ri Ri 领前于 R j Rj Rj(即 i < j i<j i<j), if Ri is still ahead of Rj in the sorted sequence, then the sorting method used is said to be stable R j Rj Rj 领前于 R i Ri Ri, then the sorting method used is said to be unstable.
-
Stability is very important when the data set to be sorted contains multiple keywords and needs to be sorted based on one of the keywords while maintaining the relative order of the other keywords. This ensures that the sorted results will still maintain the correct order when the keywords are the same, and will not disrupt the sorting of other keywords.
-
In some practical applications, the original data may already be partially ordered. If the sorting algorithm is stable, then the relative order of equal elements will be maintained without destroying the original partial ordering.
-
In some scenarios, the stability of sorting is a constraint of the problem. For example, if students' scores need to be sorted, and students with the same score are required to be sorted according to the order of their test numbers in the class, then only a stable sorting algorithm can meet the requirements.
insertion sort
The basic idea of insertion sort is to divide the sequence to be sorted into two parts, sorted and unsorted. Each time, the first element is taken out of the unsorted part and inserted into the appropriate position of the sorted part until the unsorted part is empty. . The specific operations are as follows:
- existing R [ 1.. i − 1 ] R[1..i-1] R[1..i−1] 中查找 R [ i ] R[i] R[i] 的插入位置,使得 R [ 1.. j ] . k e y ≤ R [ i ] . k e y < R [ j + 1.. i − 1 ] . k e y R[1..j].key ≤ R[i].key < R[j+1..i-1].key R[1..j]eyk.≤R[i]. key<R[j+1..i−1].key;
- 将 R [ j + 1.. i − 1 ] R[j+1..i-1] R[j+1..i−All records in 1] are moved back one position;
- General R [ i ] R[i] R[i] R [ j + 1 ] R[j+1] R[j+1] 电影上。
In this way, an insertion operation is completed. For the sequence to be sorted, the above operation is repeated until all sorting is completed.
direct insertion sort
The basic idea of direct insertion sort is to divide the sequence to be sorted into two parts, sorted and unsorted. Each time, the first element is taken out of the unsorted part and inserted into the appropriate position of the sorted part until the unsorted part is empty. until. The specific operations are as follows:
- Initially, set R [ 1 ] R[1] R[1] ward, R [ 2.. n ] R[2..n] R[2..n]Constructionless order area;
- Insert the elements of the unordered area into the ordered area in sequence, so that the ordered area is always ordered. The insertion operation includes the following three steps:
1) In R [ 1.. i − 1 ] R[1..i-1] R[1..i−1] 中查找 R [ i ] R[i] R[i] 的插入位置,使得 R [ 1.. j ] . k e y ≤ R [ i ] . k e y < R [ j + 1.. i − 1 ] . k e y R[1..j].key ≤ R[i].key < R[j+1..i-1].key R[1..j]eyk.≤R[i]. key<R[j+1..i−1].key ;
2) General R [ j + 1.. i − 1 ] R[j+1..i-1] < /span>R[j+1..i−1] Intermediate possession record after transfer to one position;
3) General R [ i ] R[i] R[i] R [ j + 1 ] R[j+1] R[j+1] 电影上。 - Repeat step 2 until the unordered area is empty and sorting is completed.
void InsertionSort(SqList& L) {
// 对顺序表 L 作直接插入排序
for (int i = 2; i <= L.length; ++i) {
if (L.r[i].key < L.r[i - 1].key) {
// 将当前待排序的记录暂存到监视哨中,等待插入
L.r[0] = L.r[i];
int j;
for (j = i - 1; L.r[0].key < L.r[j].key; --j) {
// 将记录后移,寻找插入位置
L.r[j + 1] = L.r[j];
}
L.r[j + 1] = L.r[0]; // 插入到正确位置
}
}
}
Best case scenario:
- The sequence is in order, the number of comparisons: n-1, the number of moves: 0
Worst case:

Time complexity is about O ( n 2 ) O(n^2) O(n2)
Other insertion sort
Insert in half
void BiInsertionSort(SqList &L) {
for (int i = 2; i <= L.length; ++i) {
L.r[0] = L.r[i]; // 将 L.r[i] 暂存到 L.r[0]
int low = 1, high = i - 1;
while (low <= high) {
int mid = (low + high) / 2; // 折半
if (L.r[0].key < L.r[mid].key)
high = mid - 1; // 插入点在低半区
else
low = mid + 1; // 插入点在高半区
}
for (int j = i - 1; j >= high + 1; --j) {
L.r[j + 1] = L.r[j]; // 记录后移
}
L.r[high + 1] = L.r[0]; // 插入
}
}
L.r[high + 1] = L.r[0]; // 插入是在 h i g h + 1 high+1 high+Insert at the position of 1 (at this time, low>high)
Hill sort
Hill sort (also known as reducing increment sort)
Basic idea: First make "macro" adjustments to the record sequence to be sorted, and then make "micro" adjustments. The so-called "macro" adjustment refers to the "jump" insertion sort. The specific steps are:
1. Divide the record sequence into several subsequences, and perform insertion sorting on each subsequence.
2. When the records in the entire sequence are "basically in order", perform a direct insertion sort on all the records.
Example: General n n nrecording component d d dPerson order:
R [ 1 ] , R [ 1 + d ] , R [ 1 + 2 d ] , … , R [ 1 + k d ] { R[1],R[1+d],R[1+2d],…,R[1+kd] } R[1],R[1+d],R[1+2d],…,R[1+kd]
R [ 2 ] , R [ 2 + d ] , R [ 2 + 2 d ] , … , R [ 2 + k d ] { R[2],R[2+d],R[2+2d],…,R[2+kd] } R[2],R[2+d],R[2+2d],…,R[2+kd]
… … …
R [ d ] , R [ 2 d ] , R [ 3 d ] , … , R [ k d ] , R [ ( k + 1 ) d ] { R[d],R[2d],R[3d],…,R[kd],R[(k+1)d] } R[d],R[2d],R[3d],…,R[kd],R[(k+1)d]
Then, d d d is called an increment, and its value gradually shrinks from large to small during the sorting process until it is reduced to 1 in the last sorting pass.

Bubble Sort
void BubbleSort(Elem R[], int n) {
int i = n;
while (i > 1) {
int lastExchangeIndex = 1;
for (int j = 1; j < i; j++) {
if (R[j+1].key < R[j].key) {
Swap(R[j], R[j+1]);
lastExchangeIndex = j;
} //if
} //for
i = lastExchangeIndex; // 本趟进行过交换的最后一个记录的位置
} // while
} // BubbleSort
-
The end condition of bubble sort is that no "exchange records" are performed in the last pass.
-
Under normal circumstances, i decreases by 1 for each "bubble" trip, but this is not the case for every trip. Specifically, during each sorting pass, we record the position of the last exchange operation. If after the end of a sorting pass, the position of the last exchange operation is the same as the position at the end of the previous sorting pass, then it means that this time Sorting does not perform any exchange operations, which means that the elements after this position are already in order. At this point, we can consider that the sequence is in order, so we end the execution of the algorithm.

Time complexity is about O ( n 2 ) O(n^2) O(n2)
Quick sort
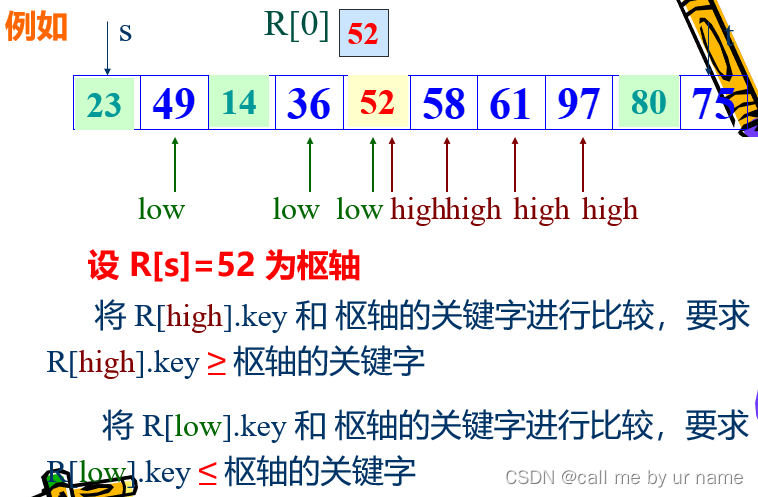
Find a record and use its keyword as the "pivot". All records whose keywords are smaller than the pivot will be moved to before the record. On the contrary, all records with keywords greater than the pivot will be moved to after the record.
After one sorting, the unordered sequence of records R [ s . . t ] R[s..t] R[s..t R [ s . . i − 1 ] R[s..i-1] < /span>General division:]R[s..i−1]和 R [ i + 1.. t ] R[i+1..t] R[i+1..t],且 R [ j ] . k e y ≤ R [ i ] . k e y ≤ R [ p ] . k e y ( s ≤ j ≤ i − 1 ) 枢轴 ( i + 1 ≤ p ≤ t ) R[j].key\leq R[i].key \leq R[p].key (s\leq j\leq i-1)~ 枢轴 ~(i+1\leq p\leq t) R[j]. key≤R[i]. key≤R[p]. key(s≤j≤i−1) 枢轴 (i+1≤p≤t)in i i i represents the position of the pivot record, j ≤ i − 1 j \leq i-1 j≤i−The keywords of the records of 1 are less than or equal to the pivot keyword, p ≥ i + 1 p \geq i+1 < /span>p≥i+The keywords of the records of 1 are all greater than or equal to the pivot keyword. Note that this assumes that the location of the pivot is not s s s或 t t t, otherwise there will be no corresponding side.
int Partition (RedType& R[], int low, int high) {
pivotkey = R[low].key; // 用子表的第一个记录作枢轴记录
while (low < high) {
// 从表的两端交替地向中间扫描
while (low < high && R[high].key >= pivotkey)
--high;
R[low] ←→ R[high]; // 将比枢轴记录小的记录交换到低端
while (low < high && R[low].key <= pivotkey)
++low;
R[low] ←→ R[high]; // 将比枢轴记录大的记录交换到高端
}
return low; // 返回枢轴所在位置
} // Partition
void QSort (RedType & R[], int low, int high) {
// 对记录序列R[low..high]进行快速排序
if (low < high) {
// 长度大于1
pivotloc = Partition(R, low, high);
// 对 R[s..t] 进行一次划分
QSort(R, low, pivotloc - 1);
// 对低子序列递归排序,pivotloc是枢轴位置
QSort(R, pivotloc + 1, high); // 对高子序列递归排序
}
} // QSort
Time complexity: O ( n l o g n ) O(nlogn) O(nlogn)
selection sort
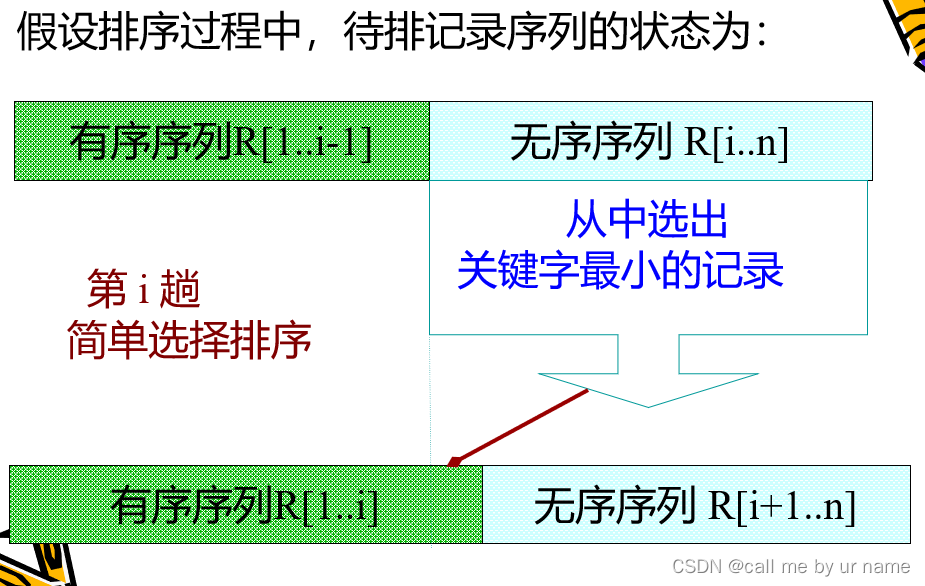
Select the smallest element from the unsorted sequence and put it into the sorted sequence
The difference from insertion sort:
- Insertion: Find the first element of the unsorted sequence and find the insertion position in the ordered sequence
- Selection: Find the smallest element in the unsorted sequence and add it to the end of the ordered sequence
void SelectSort(Elem R[], int n) {
// 对记录序列 R[1..n] 进行简单选择排序。
for (int i = 1; i < n; ++i) {
// 选择第 i 小的记录,并交换到位
int j = SelectMinKey(R, i);
// 在 R[i..n] 中选择关键字最小的记录
if (i != j) {
// 与第 i 个记录交换
R[i] ↔ R[j];
}
}
} // SelectSort

Heap sort

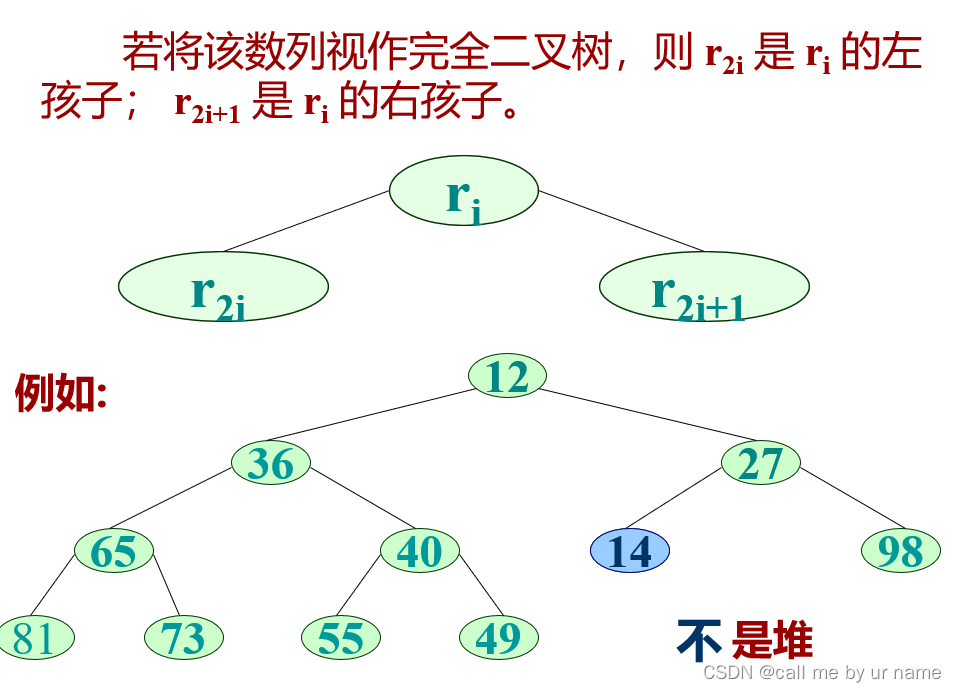
It’s a bit unclear just by looking at the definition, but based on the tree it should be very clear
Build a big pile
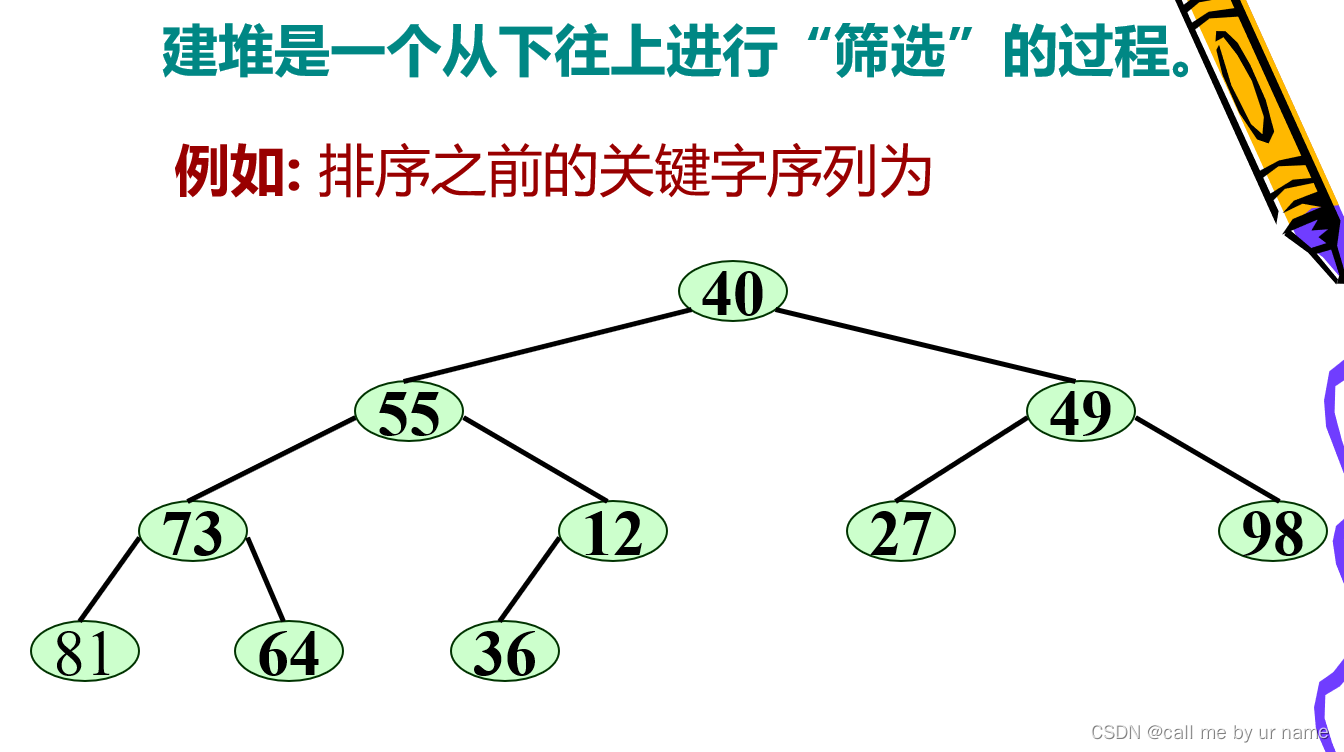
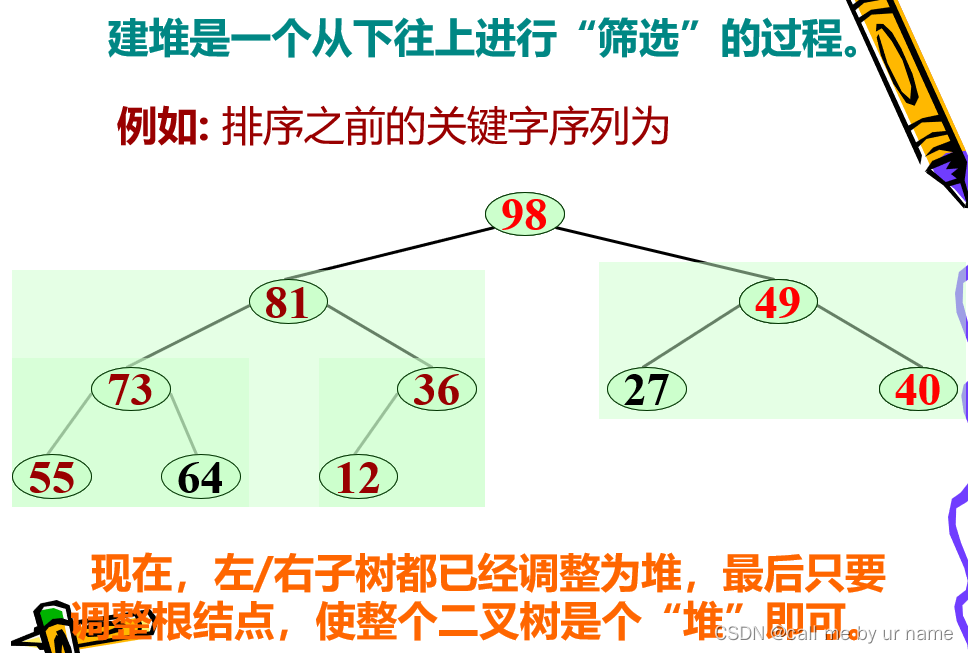
bottom up
merge sort
- The process of merge sort is based on the following basic idea: "merge" two or more ordered subsequences into one ordered sequence
- In internal sorting, 2-way merge sort is usually used. That is: put two adjacent records into an ordered subsequence

It's relatively simple, just take a look
exercise
Each sort

The last exam is not involved
-
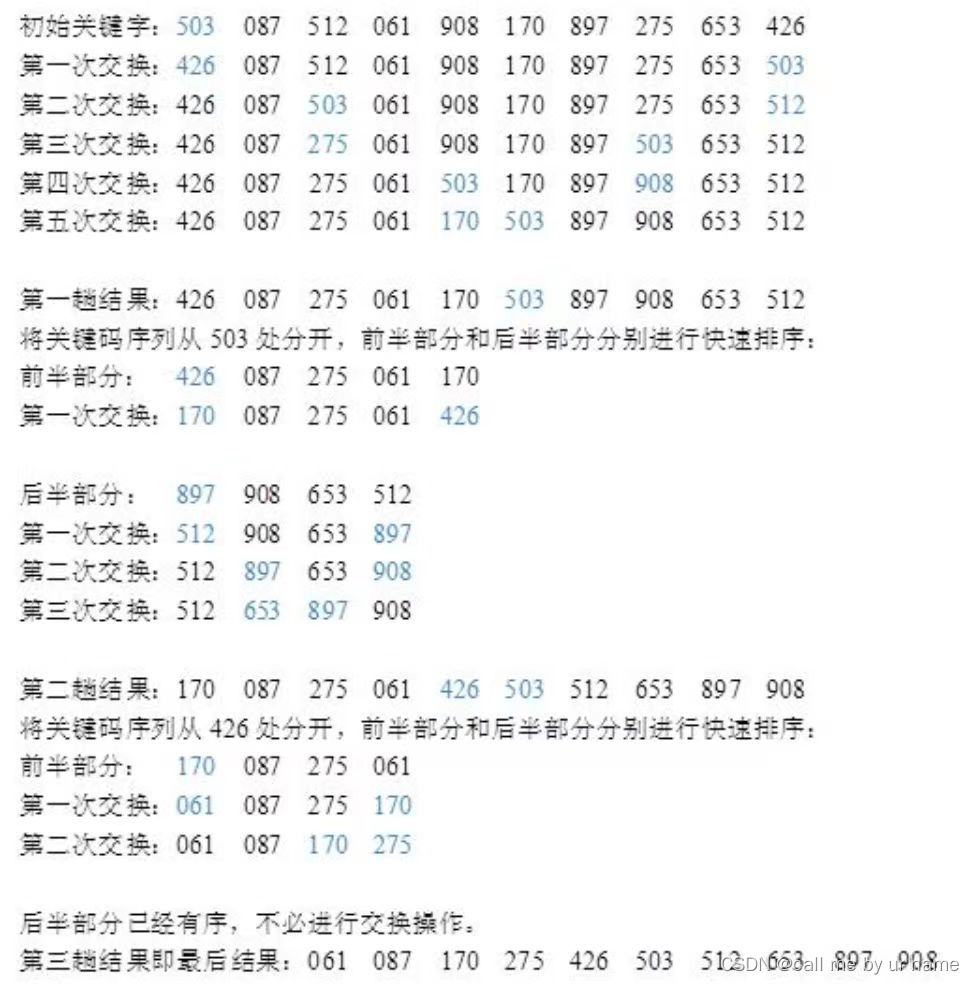
Direct entry/exclusion order:503 087 512 061 908 170 897 275 653 426
First result :087 503 512 061 908 170 897 275 653 426
Second result: 087 503 512 061 908 170 897 275 653 426
Third result:061 087 503 512 a> 908 170 897 275 653 426
Fourth result:061 087 503 512 908 170 897 275 653 426
Fifth result:061 087 170 503 512 908 897 275 653 426 a >
Sixth result:061 087 170 503 512 897 908 275 653 426
Seventh Consequence: 061 087 170 275 503 512 897 908 653 426
Eighth result:< a i=25>061 087 170 275 503 512 653 897 908 426 Ninth result:061 087 170 275 426 503 512 653 897 908
粗体为已经排好序的序列 -
Hill sort initial keyword: 503 087 512 061 908 170 897 275 653 426
First pass result: d[1]=5 170 087 275 061 426 503 897 512 653 908
The result of the second trip: d[2]=3 061 087 275 170 426 503 897 512 653 908
The result of the third trip: d[3] =1 061 087 170 275 426 503 512 653 897 908
主要注意一下希尔排序是以下标号的后x个作排序——在d[1]=5,a[0]=503是a[5]=170排序的 -
Quick sort
注意,快速排序不是把比Key小的数直接随便放到Key前面,是用low和high遍历出来的 -
Heap sort

小顶堆 -
归并净 (Self-bottom improvement)
503 087 512 061 908 170 897 275 653 426
(087 503) (061 512) (170 908) (275 897) (426 653)
(061 087 503 512) (170 275 897 908) (426 653)
(061 087 170 275 503 512 897 908) (426 653)
(061 087 170 275 426 503 512 653 897 908)
Heap sort


The answer to question 4 should be wrong
lookout post
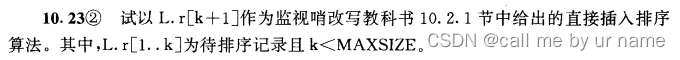
void directInsertSort(int L[], int k) {
int i, j;
for (i = 2; i <= k; i++) {
L[k+1] = L[i];
j = i - 1;
while (L[j] > L[0]) {
L[j + 1] = L[j];
j--;
}
L[j + 1] = L[k+1];
}
}
design algorithm

void process(int A[n]) {
int low = 0;
int high = n - 1;
while (low < high) {
while (low < high && A[low] < 0)
low++;
while (low < high && A[high] > 0)
high++;
if (low < high) {
// 交换 A[low] 和 A[high]
int temp = A[low];
A[low] = A[high];
A[high] = temp;
low++;
high--;
}
}
return;
}
double finger method
time increase O ( n ) O(n) O(n)
Dutch flag question

typedef enum {
RED, WHITE, BLUE} color; // 定义枚举类型表示三种颜色
void Flag_Arrange(color a[], int n) {
int i = 0;
int j = 0;
int k = n - 1;
while (j <= k) {
switch (a[j]) {
case RED:
// a[i] 与 a[j] 交换
// 增加 i 和 j 的值,同时继续处理下一个元素
swap(a[i], a[j]);
i++;
j++;
break;
case WHITE:
// 当遇到白色时,只需要将 j 向右移动一位
j++;
break;
case BLUE:
// a[j] 与 a[k] 交换
// 不增加 j 的值,因为可能需要再次检查交换后的 a[j]
// 减少 k 的值,将蓝色元素移至数组末尾
swap(a[j], a[k]);
k--;
break;
}
}
}