Table of contents
1. Android sound effect C/S architecture
2. Initialization and use of EffectHAL sound effect framework
2.1 Sound effect framework initialization
2.2 Create and load sound effect algorithm
2.3 Execute sound effect algorithm
3. AudioFlinger’s secondary encapsulation of the sound effect framework
4. Binding process of Device sound effects
4.1 How DeviceHAL processes sound effect data
4.2 How AudioFlinger processes sound effect data
5. Binding process of Stream sound effects
6. How StreamHAL processes sound effect data
7. The binding process of Track sound effects
8. The binding process of Aux sound effects
9. Data transmission flow chart for all sound effects processing
In Android’s sound effect architecture, all sound effect algorithms are mounted and run in the AudioHAL process. According to the location where the sound effect algorithm is applied, it can be divided into three categories: Track sound effects, Stream sound effects, and Device sound effects. That is: processing sound effects for a certain Track, processing sound effects for a certain StreamType, and processing sound effects for a certain Device. InAndroid13 Audio Subsystem Analysis (1)---Overall Architecture we have seen that Track is only a concept in the APP layer and AudioServer framework layer , when it comes to the AudioHAL layer, there is no concept of Track, only Stream and Device. In other words, the AudioFlinger module has mixed the data of multiple Tracks together and then output them to StreamOut. Therefore, it can be imagined that the sound effect processing for Track will inevitably be called across processes. In order to transmit the Track audio data across processes to the sound effect algorithm for processing, and then get the data processed by the algorithm back, it will lead to additional shared memory creation overhead. , increase memory consumption. This is where I think the Android sound architecture design is unreasonable. Let's take a look at the design principles of Android sound architecture.
1. Android sound effect C/S architecture
Since Android runs all sound effect algorithms in the AudioHAL process, and the core control and user is AudioFlinger in the AudioServer process, it will inevitably be designed into a C/S architecture through the Binder mechanism. On the server side, it provides two main HIDL interfaces: IEffectsFactory.hal and IEffect.hal. When the AudioHAL process is initialized (source code in /hardware/interfaces/audio/common/all-versions/default/service.cpp), IEffectsFactory will be added to the ServiceManager as a HIDL server. The client can obtain a specified sound effect algorithm engine: IEffect through IEffectsFactory. The following is the EffectHAL architecture class diagram:

The EffectHAL architecture is divided into three layers:
- Effect client proxy layer: the module with the yellow background in the picture. They are compiled and packaged in the libaudiohal.so library, called by AudioFlinger, and run in the AudioServer process. Source code location:/frameworks/av/media/libaudiohal/
- Effect server implementation layer: the module with blue background in the picture. Runs in the AudioHAL process. Source code location: /hardware/interfaces/audio/effect/all-versions/default/. Among them, EffectsFactory.c is used to parse the sound effect configuration file audio_effects.xml and load the module that calls the sound effect algorithm. Its source code is located at: /frameworks/av/media/libeffects/factory/. It will be compiled and packaged into the libeffects.so library. Therefore,If we want the sound effects algorithm to run in the AudioServer process without calling it across processes, we can directly load the libeffects.so library and implement it by calling the EffectsFactory.c module. Of course, the changes will not be small. The advantage of modifying the existing Android sound effect framework is that it provides an algorithm control interface for upper-layer APPs. We can also save trouble and directly add a custom type of AudioBufferProvider to the AudioMixer mixer, so that customized sound effects processing can be performed on a single AudioTrack.
- The interface definition layer provided to algorithm manufacturers: there are only two main structures, audio_effect_library_t and effect_interface_s. effect_handle_t is a pointer to the effect_interface_s structure. They are all defined in the file /hardware/libhardware/include/hardware/audio_effect.h. The Android sound effect architecture allows algorithm manufacturers to compile and package multiple algorithms of their own into an so library. Therefore, the audio_effect_library_t structure defines an interface for obtaining an algorithm engine in the so library. The effect_interface_s structure definition is an interface that needs to be implemented by a specific sound effect algorithm.
- The white part in the picture: AudioBuffer class (/hardware/interfaces/audio/effect/7.0/types.hal defined in the file) and the audio_buffer_t structure (defined in the file /system/media/audio/include/system/audio_effect.h), both represent shared memory blocks. It encapsulates a pointer to the shared memory address. Only the AudioBuffer class is used by C++ code, and the audio_buffer_t structure is used by C code.
- In addition to the above-mentioned modules, there is also a commonly used module that is not shown in the figure. It is the EffectDescriptor class used by C++ code (/hardware/interfaces/audio/effect/7.0/types.hal defined in the file) and the effect_descriptor_t structure used by C code (defined in the file /system/media/audio/include/system/audio_effect.h ). They are all information used to describe a certain sound effect algorithm, includingtypeUUID (a certain type of sound effect algorithm defined by OpenSL ES, such as a noise reduction algorithm All defined is a TypeUUID, no matter which algorithm manufacturer implements it), UUID (represents the uniqueness of a specific implementation of the noise reduction algorithm Identifier, the UUID of the noise reduction algorithm implemented by different manufacturers will not be the same), flags (represents the capabilities supported by this algorithm, detailed explanation can be foundflags a>, represent this algorithm The CPU and memory occupied, but some algorithm implementation manufacturers do not provide this part of the information description. For example, Android's own multi-channel to two-channel algorithm EffectDownmix does not. AudioPolicyService will statistically monitor the CPU and memory usage of all algorithms based on these two fields, but it is obviously inaccurate. memoryUsage and cpuLoad file). The remaining fields, such as /hardware/interfaces/audio/effect/7.0/types.hal
Although Android supports third-party algorithm manufacturers to implement their own algorithms based onaudio_effect.h->effect_interface_sinterface, and also implemented some sound effect algorithms by default for use by the upper layer. Their source code is located in the /frameworks/av/media/libeffects/ directory. Mainly include the following types:
- EffectDownmix: Used to convert multi-channel into stereo two-channel.
- DynamicsProcessing: Dynamic range adjustment sound effects.
- EffectHapticGenerator: Generate vibration effect data based on audio data.
- LoudnessEnhancer: Volume amplification sound effect.
- PreProcessing: The pre-processing algorithm used in the audio upstream recording path. Contains AGC automatic gain algorithm, AEC echo cancellation algorithm, and NS noise reduction algorithm. This is the 3A algorithm often referred to in call scenarios. Because the NS noise reduction algorithm is also called ANS in some places. These three algorithms Android are implemented by calling the sound effect module in WebRTC. Obviously, for call scenarios, it will be more efficient to run the 3A algorithm directly in the DSP chip. Therefore, in practice, no one from any mobile phone manufacturer will use the PreProcessing algorithm provided by Android.
- Visualizer: Convert audio PCM data into visual waveforms.
- BassBoost: Bass boost sound effect.
- PresetReverb: Ambient reverberation sound effect. Mainly suitable for music playback scenarios.
- EnvironmentalReverb: Environmental reverberation sound effect. Provides more reverb parameter settings. Suitable for game play scenarios.
- Equalizer: EQ equalizer sound effect.
- Virtualizer: Spatial sound effects.
- EffectPoxy: The sound effect proxy interface defined by Android. Corresponding to the <effectProxy> node in the sound effect configuration file audio_effects.xml, it saves two sound effect subclasses, one is the ordinary sound effect defined in the <libsw> node and runs in the AudioHAL process. One is the proxy sound effect defined in the <libhw> node that communicates with the sound effect algorithm running in the DSP. That is to say, the Android sound effect architecture provides an interface for controlling the sound effect algorithm running in the DSP. But the sound effect algorithm manufacturer needs to implement the control end based on the audio_effect.h->effect_interface_s interface, and in Configure in the a>audio_effects.xml file.
2. Initialization and use of EffectHAL sound effect framework
We mentioned the audio_effects.xml sound effect configuration file earlier, so when does the Android sound effect framework parse the sound effects in the loaded configuration file? It uses a similar "lazy loading mode" and is not initialized when EffectsFactory.cpp is created and added to the HIDL server. It is initialized when someone on the client calls a function in the EffectsFactoryHalInterface.h interface. That is, it will only be initialized when someone uses it.
Below I will take the DownmixerBufferProvider in AudioMixer as an example to present the initialization process of the sound effect framework. AudioMixer is a mixer used by AudioFlinger to convert AudioTrack audio data to channel number, Format sampling precision, and sampling rate. Among them, DownmixerBufferProvider is one of its sub-modules, which is used to convert multi-channel into two-channel. The conversion algorithm uses EffectDownmix provided in the sound effect framework. Their source code is located in the /frameworks/av/media/libaudioprocessing/ directory. The reason why I chose DownmixerBufferProvider as an example to explain the initialization process of the sound effect framework is because it directly uses the EffectsFactoryHalInterface.h interface and EffectHalInterface.h interface in the libaudiohal.so library without going through AudioFlinger. Therefore, there are no concepts such as sessionId, EffectChain, and AudioEffect involved in AudioFlinger. You can understand more simply and clearly how to call the Android sound effect framework through the libaudiohal.so library.
The process of using the sound effect framework mainly consists of three steps:
- Check whether there is a channel conversion sound effect?
- Initialize the channel conversion sound effect. Including creating the sound effect proxy interface object EffectHalInterface, creating the shared memory EffectBufferHalInterface, and setting the parameters of the sound effect algorithm.
- Channel conversion sound effect algorithm processing. First copy the prepared audio data to the shared memory, and then pass theEffectHalInterface->process()interface Notify the sound effect algorithm for processing.
2.1 Sound effect framework initialization
DownmixerBufferProvider is queried in its init() function. The method it uses is to first passEffectsFactoryHalInterface->queryNumberEffects()Interface, query the total number of sound effect algorithms existing in the current sound effect framework, and then loop throughEffectsFactoryHalInterface->getDescriptor(uint32_t index,effect_descriptor_t *pDescriptor)Interface , get the description object of each sound effect algorithmeffect_descriptor_t, and finally take a look at theseeffect_descriptor_tWhether the TypeUUID ofDownmix exists. Let's trace the first interface of the sound effects framework queryNumberEffects() and see how the sound effects framework is initialized.
BufferProviders.cpp->DownmixerBufferProvider::init()
|->EffectsFactoryHalHidl.cpp->queryNumberEffects()
|->EffectsFactoryHalHidl.cpp->queryAllDescriptors()
|->EffectsFactory.cpp->getAllDescriptors()//Binder跨进程调用
|->EffectsFactory.c->EffectQueryNumberEffects()//libeffects库中的代码
|->EffectsFactory.c->init()It can be seen that the final call isEffectsFactory.c(/frameworks/av/media/libeffects/factory/ )'s EffectQueryNumberEffects() interface. Among the interface functions provided by EffectsFactory.c, it will first call its own init() function to initialize the sound effects framework. A global variablegInitDone is used in the init() function, so the init() function will only be executed once. In the init() function, it will first query the "ro.audio.ignore_effects" system property. If this system property is configured to true, it will not initialize and parse the audio_effects.xml sound effect configuration file, and it will not initialize all Sound effect algorithm. When debugging the audio playback performance of the device, we can set this system property to true to bypass all sound effect processing. Let's take a look at what the init() function does.
EffectsFactory.c->init()
|->EffectsXmlConfigLoader.cpp->EffectLoadXmlEffectConfig()
|->EffectsConfig.cpp->parse()//解析audio_effects.xml配置文件,保存到EffectsConfig.h->Config结构体中。
|->EffectsXmlConfigLoader.cpp->loadLibraries()//将加载成功的音效so库所对应的libeffects/EffectsFactory.h->lib_entry_t结构体保存到gLibraryList列表中。
|->EffectsXmlConfigLoader.cpp->loadLibrary()//从"/vendor/lib64/soundfx"目录中加载音效so库。获取该so库中的声明为AUDIO_EFFECT_LIBRARY_INFO_SYM的结构体,从而获取到audio_effect_library_t结构体句柄。
|->EffectsXmlConfigLoader.cpp->loadEffects()//将获取的effect_descriptor_t数据保存到lib_entry_t->effects列表中
|->EffectsXmlConfigLoader.cpp->loadEffect()
|->audio_effect.h->audio_effect_library_t.get_descriptor()
|->EffectDownMix.cpp->DownmixLib_GetDescriptor()//实际调用的是音效so库中的函数,用于获取effect_descriptor_t结构体数据
|->EffectsFactory.c->updateNumEffects()//将所有lib中effect_descriptor_t的总数汇总后保存到gNumEffects变量中When the execution of this code is completed, the sound effect framework is completedThe audio_effects.xml file is parsed, all sound effects so libraries are loaded, and each sound effect corresponding to Description object effect_descriptor_t. However, the processing object effect_handle_t corresponding to the sound effect algorithm has not been created at this time. It will not be created until someone actually uses it.
Let's take a look at the audioeffects.xml configuration file. This configuration file includes 5 types of nodes:
<libraries>Node. It contains the names of all sound effects so libraries. EffectsFactory.c will load the so library in the "/vendor/lib64/soundfx" directory through this name. Then obtain the structure declared as AUDIO_EFFECT_LIBRARY_INFO_SYM in the so library, thereby obtaining the handle of the audio_effect_library_t structure.
<libraries>
<library name="downmix" path="libdownmix.so"/>
<library name="proxy" path="libeffectproxy.so"/>
<library name="bundle" path="libbundlewrapper.so"/>
<library name="offload_bundle" path="libqcompostprocbundle.so"/>
</libraries><effects>node. It contains all sound effect algorithm declarations. Each sound effect algorithm needs to specify the so library name to which it belongs and its own unique UUID. Through this UUID, we can get the description structure corresponding to the sound effect through the audio_effect_library_t->get_descriptor(uuid, effect_descriptor_t *pDescriptor)interface a>. effect_handle_t audio_effect_library_t->create_effect(uuid,effect_handle_t *pHandle). You can also obtain its corresponding usage interface througheffect_descriptor_t
<effects>
<effect name="downmix" library="downmix" uuid="93f04452-e4fe-41cc-91f9-e475b6d1d69f"/>
<effectProxy name="bassboost" library="proxy" uuid="14804144-a5ee-4d24-aa88-0002a5d5c51b">
<libsw library="bundle" uuid="8631f300-72e2-11df-b57e-0002a5d5c51b"/>
<libhw library="offload_bundle" uuid="2c4a8c24-1581-487f-94f6-0002a5d5c51b"/>
</effectProxy>
</effects><postprocess> node. Used to bind multiple sound effect algorithms to a certain streamType. AudioPolicyService will parse this node during initialization. The following configuration means that all AudioTracks declared as AUDIO_STREAM_MUSIC will load the bassboost bass enhancement sound effect and loudness_enhancer volume amplification sound effect during playback. It is equivalent to configuring a global sound effect.
<postprocess>
<stream type="music">
<apply effect="bassboost"/>
<apply effect="loudness_enhancer"/>
</stream>
</postprocess><preprocess>node. Used to bind multiple sound effect algorithms to an inputSource. AudioPolicyService will parse this node during initialization. The following configuration means that all AudioRecords (i.e. VoIP chat scenarios) that declare AUDIO_SOURCE_VOICE_COMMUNICATION will load the AEC algorithm and NS algorithm when recording audio data.
<preprocess>
<stream type="voice_communication">
<apply effect="aec"/>
<apply effect="ns"/>
</stream>
</preprocess><deviceEffects> node. Used to bind multiple sound effect algorithms to a device. AudioPolicyService will parse this node during initialization. The following configuration means binding an AGC algorithm to the built-in microphone. That is to say, no matter what scene is recorded, the AGC algorithm will be executed.
<deviceEffects>
<devicePort type="AUDIO_DEVICE_IN_BUILTIN_MIC" address="bottom">
<apply effect="agc"/>
</devicePort>
</deviceEffects>As can be seen from the above,the audioeffects.xml file contains two parts of configuration content. Part of it is the configuration declaration sound effect algorithm, which is parsed by AudioHAL. Part of it is to configure global sound effects: Stream sound effects and Device sound effects, which are parsed by AudioPolicyService. After EffectsFactory.c completes the initialization, the audio_effect_library_t list and effect_descriptor_teffect_descriptor_t are saved in the local memory of the AudioHAL process. a> list, used for upper-layer query.
2.2 Create and load sound effect algorithm
In the constructor of DownmixerBufferProvider, the EffectsFactoryHalInterface->createEffect(uuid,sessionId,ioId,deviceId,sp<EffectHalInterface> *effect) interface is used to create the proxy object EffectHalHidl of IEffect.hal. The ioId refers to the Id corresponding to StreamOutHAL in PlaybackThread. sessionId, ioId, and deviceId do not need to be specified. They mainly tell the sound effect algorithm who the data it processes is for. The only thing that must be specified is the UUID. As you can guess, EffectsFactory.c uses UUID to find and create the effect_handle_t interface corresponding to the sound effect. Let’s take a brief look at the calling process:
BufferProviders.cpp->DownmixerBufferProvider::DownmixerBufferProvider()
|->EffectsFactoryHalHidl.cpp->createEffect()//创建EffectHalHidl对象
EffectsFactory.cpp->createEffect()//Binder跨进程调用,获取IEffect对象
|->EffectsFactory.cpp->createEffectImpl()//创建IEffect对象(DownmixEffect对象),生成effectId。并保存到EffectMap集合中。
|->EffectsFactory.c->EffectCreate()//libeffects库中。获取effect_handle_t句柄
|->EffectsFactory.c->doEffectCreate()
|->audio_effect.h->audio_effect_library_t.create_effect()
|->EffectDownMix.cpp->DownmixLib_Create()//返回的是downmix_module_t结构体句柄
|->EffectDownMix.cpp->Downmix_Init()//设置输入源的数据格式为:7.1声道、浮点型、44.1K采样率。输出的数据格式为:双声道、浮点型、44.1K
|->EffectsFactory.cpp->dispatchEffectInstanceCreation()//根据effect_descriptor_t结构体中的type(即OpenSL ES中定义的音效类型UUID),创建对象。new DownmixEffect对象。When this code is executed, on the client side, EffectsFactoryHalHidl.cpp creates an EffectHalHidl object for use by DownmixerBufferProvider calls. EffectHalHidl has a member variable IEffect (returned by IEffectFactory), which points to the DownmixEffect.cpp object in the server AudioHAL process. DownmixEffect has a member variable Effect.cpp. Effect has a member variable effect_handle_t. The effect_handle_t pointer points to EffectDownMix. downmix_module_t structure of cpp. In this way, the DownmixerBufferProvider is finally connected to the EffectDownMix algorithm. The following is the call diagram:
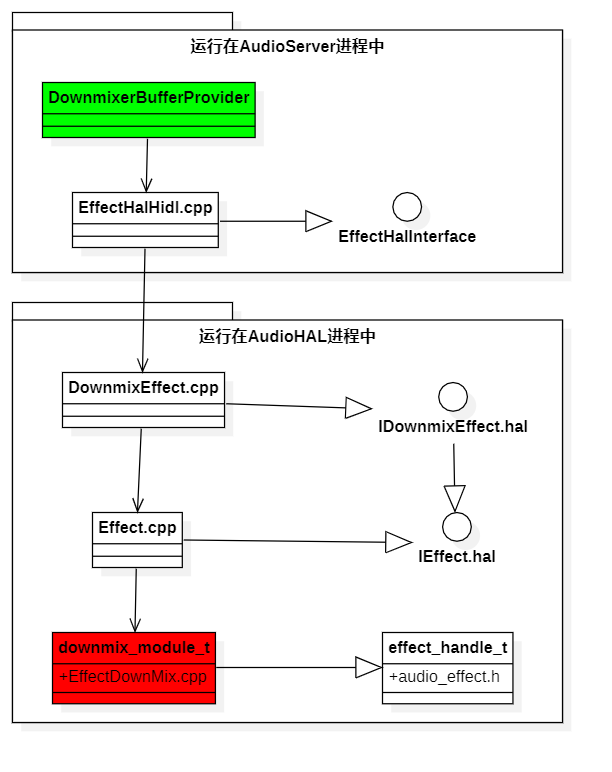
The green DownmixerBufferProvider with the green icon above represents the user of the sound effect algorithm. The downmix_module_t marked in red represents the implementation of the sound effect algorithm, and the white part in the middle is the sound effect framework mentioned above.
After creating the EffectHalHidl object, you need to create shared memory. We process the sound effect algorithm function process from the effect_handle_t interface (effect_handle_t self,audio_buffer_t *inBuffer,audio_buffer_t *outBuffer< /span> member variable of the EffectBufferHalHidl object. Then EffectBufferHalHidl will create a shared memory through the IAllocator interface and save it in AudioBuffer.data, which will be passed to the Effect server. Its calling code is very simple as follows:mExternalData pointer points to the local data memory block. Saved in the external interface of EffectsFactoryHalHidl. The mirrorBuffer(void* external,size_t size,sp<EffectBufferHalInterface>* buffer)), it can be seen that the sound effect algorithm requires two memory spaces, one is used to save the data memory block inBuffer input to the sound effect algorithm, and the other is used to output the data after the sound effect algorithm is processed. Memory block outBuffer. We can create a shared memory through the
BufferProviders.cpp->DownmixerBufferProvider::DownmixerBufferProvider()
|->EffectsFactoryHalHidl.cpp->mirrorBuffer(&mInBuffer)//创建输入数据共享内存块
|->EffectBufferHalHidl.cpp->mirror()//创建EffectBufferHalHidl对象
|->EffectBufferHalHidl.cpp->init()//创建共享内存
|->EffectsFactoryHalHidl.cpp->mirrorBuffer(&mOutBuffer)//创建输出数据共享内存块
|->EffectBufferHalHidl.cpp->mirror()//创建EffectBufferHalHidl对象
|->EffectBufferHalHidl.cpp->init()//创建共享内存
|->EffectHalHidl.cpp->setInBuffer(mInBuffer)//为音效绑定输入共享内存块
|->EffectHalHidl.cpp->setOutBuffer(mOutBuffer)//为音效绑定输出共享内存块When the above code is executed, the sound effect user creates two new shared memory blocks. For use by algorithms.
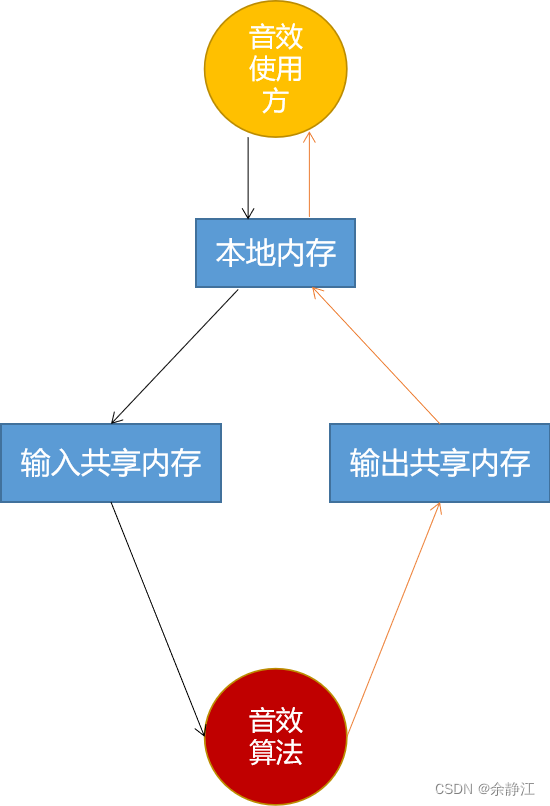
The above picture shows the transfer path of audio data when using the sound effect algorithm: copy from "local memory" to "input shared memory". After the sound effect algorithm reading and processing is completed, new data is written to the "output shared memory" Memory", EffectBufferHalHidl will copy the data in the "output shared memory" back to the "local memory" for subsequent use by the sound effect caller. Of course, if the memory size required for the data before and after sound effect processing is exactly the same, you can also point the input and output to the same shared memory. However, when using the sound effects processing of the Android architecture, at least one shared memory block must still be created. So, this is where I think the Android sound architecture design is unreasonable. Because in the Android sound effect architecture, the user of Track sound effects is AudioFlinger. Therefore, there will inevitably be situations where additional shared memory needs to be created due to cross-process communication.
After the newly created shared memory is passed to EffectHalHidl, the algorithm needs to be configured, such as the sampling rate, number of channels, and Format precision of the input audio data; the required output audio data format, etc. What is called is the EffectHalHidl->command() interface. Because the logic is relatively simple, the code calling process will not be listed here.
2.3 Execute sound effect algorithm
DownmixerBufferProvider notifies the execution of the sound effect algorithm through the EffectHalHidl.cpp->process() interface. Finally, through layer-by-layer calls, it will be called toeffect_handle_t.process()< /span> interface. The implementation of the EffectDownMix algorithm for this interface is the EffectDownMix.cpp->Downmix_Process() function.
Looking at the source code of the Downmix_Process() function, you will find that EffectDownMix does not write the processing algorithm itself, but calls it/system/media/audio_utils/include/audio_utils/ChannelMix.h ->process()interface. And the ChannelMixBufferProvider module, which is similar to DownmixerBufferProvider and provides the same functions, is also processed using ChannelMix.h. However, AudioMixer regards DownmixerBufferProvider as the preferred module for multi-channel to two-channel processing. It is obviously not necessary unless we implement a channel conversion algorithm ourselves and configure it in audioeffects.xml file. Otherwise, it is recommended that you modify the AudioMixer code (AudioMixer.cpp->prepareForDownmix() function) and change the module for multi-channel conversion to dual-channel processing by default to the ChannelMixBufferProvider module. The effect is exactly the same , but there is no need to call across processes, no need to create new shared memory, and less system resources are consumed.
BufferProviders.cpp->DownmixerBufferProvider::copyFrames()
|->EffectBufferHalHidl.cpp->setExternalData()//设置本地内存的指针,因为在构造函数中没有指定。
|->EffectBufferHalHidl.cpp->update()//将待处理的数据从本地内存拷贝到共享内存中
|->EffectHalHidl.cpp->process()//通知音效算法处理
|->EffectHalHidl.cpp->processImpl()
|->EffectHalHidl.cpp->prepareForProcessing()
|->DownmixEffect.cpp->prepareForProcessing()//Binder跨进程调用
|->Effect.cpp->prepareForProcessing()//创建并运行"effect"线程
|->EffectHalHidl.cpp->needToResetBuffers()
|->EffectHalHidl.cpp->setProcessBuffers()
|->DownmixEffect.cpp->setProcessBuffers()//Binder跨进程调用
|->Effect.cpp->setProcessBuffers()
|->AudioBufferManager.cpp->wrap()//将创建的AudioBufferWrapper对象保存到mBuffers集合中。
|->new AudioBufferWrapper()
|->AudioBufferManager.cpp->AudioBufferWrapper::init()//构建audio_buffer_t结构体,将audio_buffer_t.raw指针指向AudioBuffer共享内存
|->Effect.cpp->ProcessThread::threadLoop()
|->audio_effect.h->effect_interface_s.process()
|->EffectDownMix.cpp->Downmix_Process()
|->ChannelMix.h->process()
|->EffectBufferHalHidl.cpp->commit()//将共享内存中的数据拷贝给本地内存The above is the calling process code for sound effect processing. What needs to be explained is:
- When processing data for the first time, server-side Effect.cpp will create a new independent thread named "effect". That is, each sound effect algorithm runs in its own independent thread during execution.
- The client EffectHalHidl.cpp and the server Effect.cpp will implement a synchronization mechanism based on MessageQueue. When the server has not finished processing the data, the EffectHalHidl.cpp->process() function will make the current calling thread sleep and wait. When the server processes After completing the data and waking up the client through MessageQueue, the EffectHalHidl.cpp->process() function will return. In other words, the EffectHalHidl.cpp->process() function is blocking.
3. AudioFlinger’s secondary encapsulation of the sound effect framework
As the core controller of the EffectHAL sound effect framework, AudioFlinger provides an AudioEffect.java interface for the upper-layer APP, allowing users to start a sound effect and control the relevant parameters of the sound effect algorithm. Then inside its own module, three internal classes, EffectHandle, EffectModule, and EffectChain, are defined.
EffectHandle exists as the server side of AudioEffect and communicates with AudioEffect across processes. They are 1:1 related.
EffectModule exists as the control end of the real sound effect algorithm and is associated with EffectHalHidl. As mentioned above, with the EffectHalHidl object, EffectModule is associated with the EffectHAL layer. You can truly control a sound effect algorithm. EffectModule and EffectHalHidl have a 1:1 relationship. EffectModule and EffectHandle have a 1:n relationship.
EffectChain is a list collection that contains a set of EffectModule objects. In other words, the EffectChain list contains multiple sound effect algorithms. The purpose is to bind this set of sound effect algorithms to a specified data transmission location. Such an AudioTrack can be bound to multiple sound effect algorithms. At the same time, each PlaybackThread will contain multiple EffectChain objects, so that each EffectChain can be bound to different data transmission locations.
Here are their class diagrams:

Because the class diagram above needs to reflect inheritance and the real relationship, there are many nested levels, and it is not easy to intuitively see the relationship between AudioEffect, EffectHandle, EffectModule, and EffectChain. The following is a simplified relationship diagram:
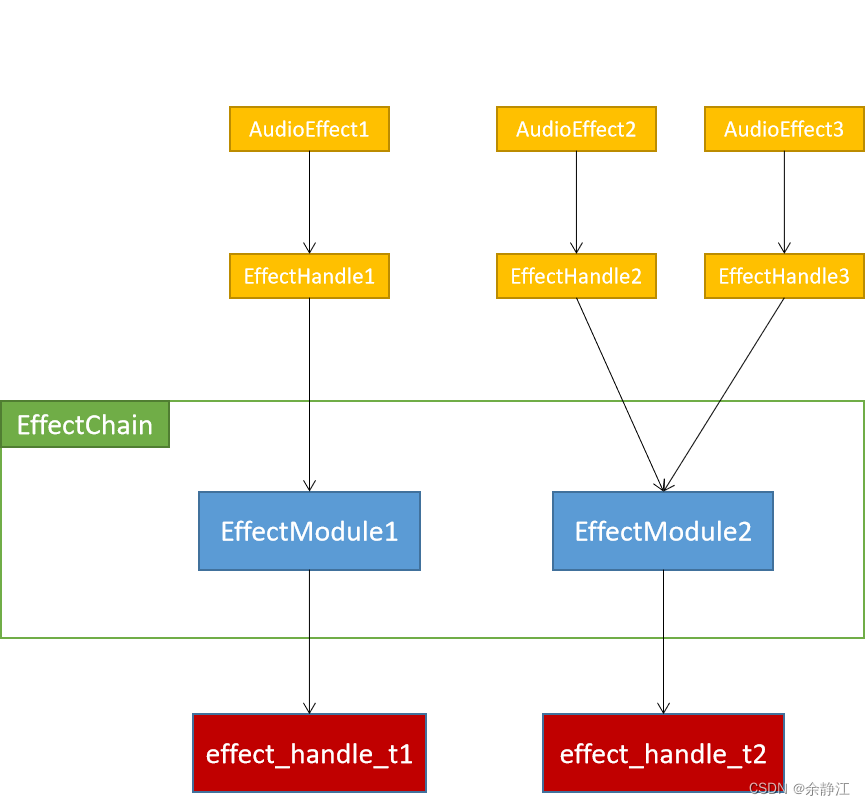
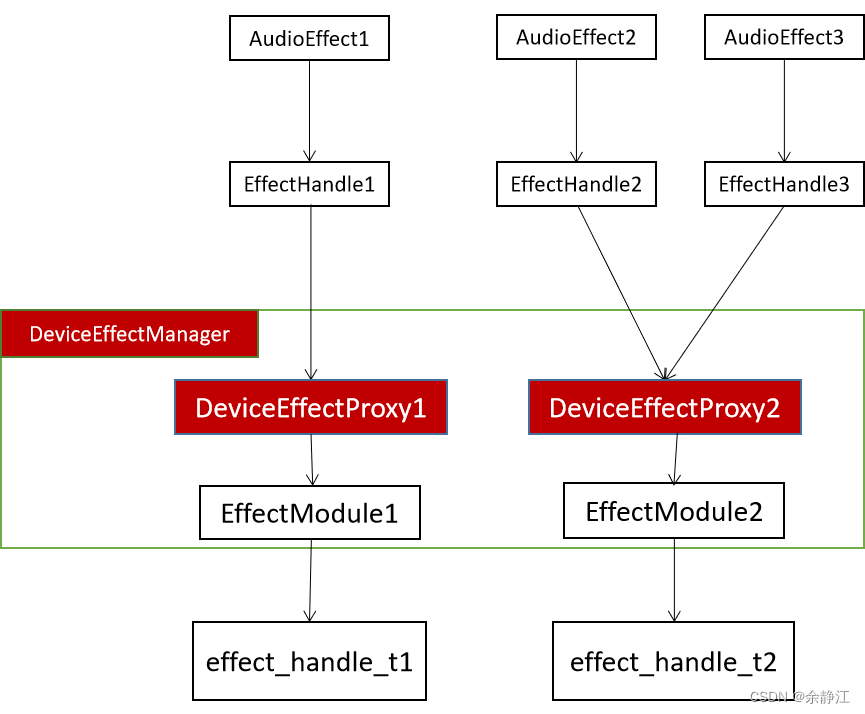
EffectHandle, EffectModule, and EffectChain are all defined in the Effect.h file in the AudioFlinger module (/frameworks/av/services/audioflinger/directory) and implemented in the Effects.cpp file. When looking at the Effect.h file, you will find that Android also defines a DeviceEffectProxy class, which, like EffectModule, inherits from EffectBase. DeviceEffectProxy represents the sound effect bound to Device. When using Device sound effects, EffectHandle is associated with DeviceEffectProxy, not directly with EffectModule. At the same time, in the DeviceEffectManager.h file, a DeviceEffectManager class is also defined to manage all DeviceEffectProxy objects. The DeviceEffectProxy class has a member variable mHalEffect, which is associated with the EffectModule object. In other words, DeviceEffectProxy ultimately controls the real sound effect algorithm through EffectModule. Below is the relationship diagram in the case of Device sound effects. The parts marked in red in the diagram are the changed parts.
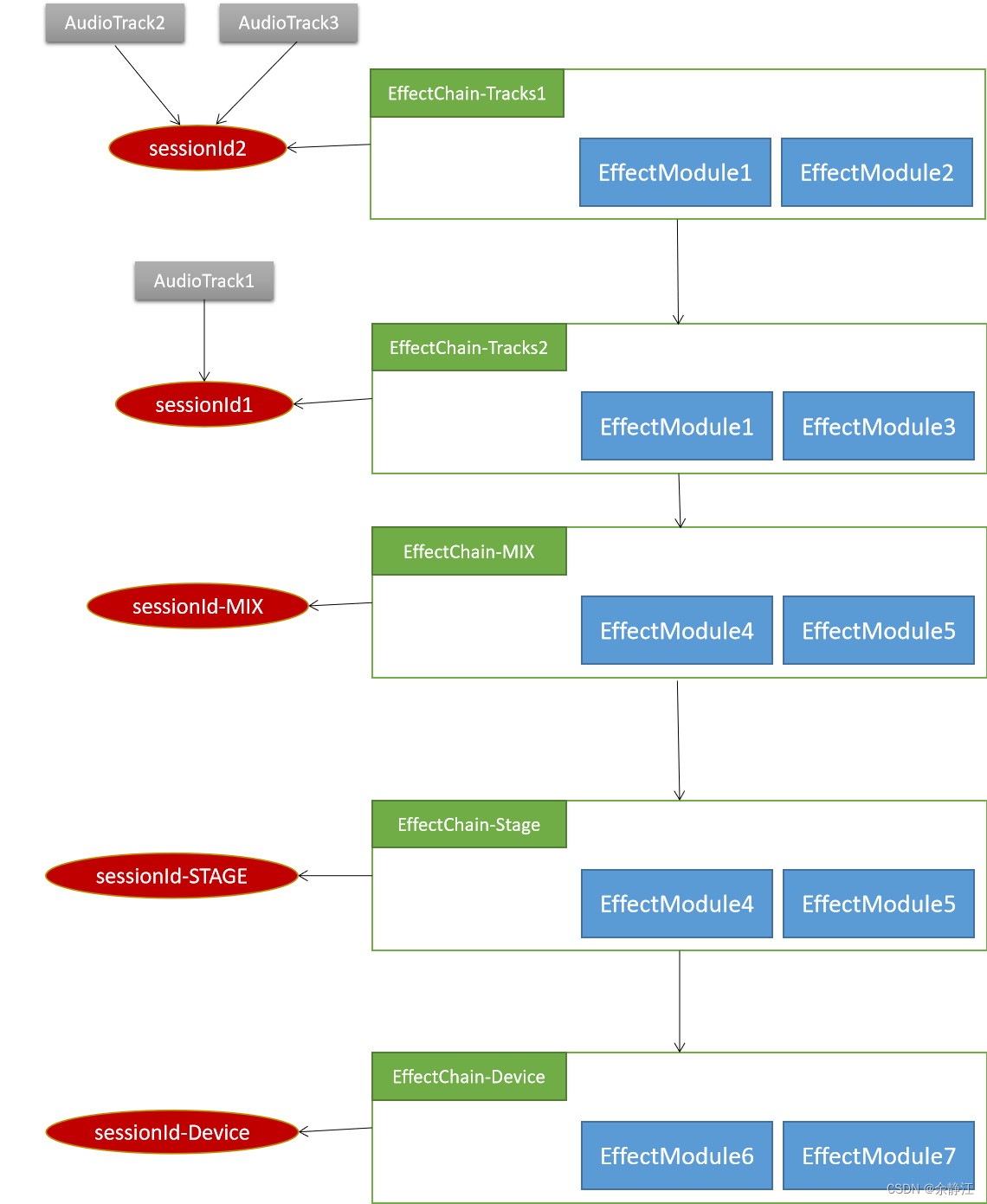
After understanding AudioFlinger’s architecture for secondary encapsulation of sound effects, let’s take a look at how AudioFlinger binds sound effects to specified locations. In order to bind sound effects, Android introduces the concept of sessionId. AudioTrack is bound to EffectChain through sessionId. When AndroidFlinger receives the AudioTrack creation request (AudioFlinger.cpp->createTrack() function), it will assign a new unique The seesionId is a positive integer that increases according to the order in which the Track is created. That is to say, the later a Track is created, the greater the value of its assigned seesionId.
The reason why the value of seesionId is specified is because the AudioFlinger module will sort EffectChain according to the size of sessionId, sorting from large to small. At the same time, /system/media/audio/include/system/audio.h of audio_session_t< In a i=4> enumeration, three global sound effects are defined: AUDIO_SESSION_OUTPUT_MIX (value is 0), AUDIO_SESSION_OUTPUT_STAGE (value is -1), AUDIO_SESSION_DEVICE (value is -2). After sorting in this way, the execution sequence between multiple EffectChains can be obtained. EffectChain-Track is executed first, then EffectChain-Mix, then EffectChain-Stage, and finally EffectChain-Device. The following is the execution sequence diagram:
EffectChain-Track2---》EffectChain-Track1---》EffectChain-Mix---》EffectChain-Stage---》EffectChain-DeviceAUDIO_SESSION_OUTPUT_MIXThis seesionId will be used for binding of Aux sound effects.
AUDIO_SESSION_OUTPUT_STAGEThis seesionId will be used for binding of spatial audio (Spatializer) related sound effects.
AUDIO_SESSION_DEVICEThis sessionId will be used for binding Device sound effects.
When the upper-layer application APP creates its own AudioTrack, it can also specify a known seesionId through the existing AudioTrack objectAudioTrack.java->getAudioSessionId()< /span> function has been checked and verified. AudioFlinger .cpp->createTrack() function, the constructor of AudioTrack.java, AudioTrack.java->Builder.setSessionId() function when creating a new AudioTrack object . In this way, multiple AudioTracks are bound to the same sessionId. This also realizes the n:1 relationship between AudioTrack and sessionId. However, AudioTrack cannot specify a negative sessionId. In other words, AudioTrack cannot be bound to global sound effects. Because in the AudioTrack.java->Builder.setSessionId() function is obtained, and then set through the
So how is sessionId associated with Effect? When we create a new AudioEffect object, we need to specify a sessionId. The AudioFlinger module will then be notified to create the AudioHandle corresponding to the AudioEffect (AudioFlinger.cpp->createEffect() function). The AudioFlinger module will first search for the corresponding Track based on the seesionId. If the Track is found, the PlaybackThread corresponding to the Playback Track will be found. Then find the corresponding EffectChain object based on this sessionId from the mEffectChains list of PlaybackThread. If not, create a new EffectChain object. Therefore, sessionId and EffectChain have a 1:1 correspondence. Finally, create the corresponding EffectModule object for this AudioEffect and add it to the EffectChain list. At this point, AudioTrack and EffectModule have established an n:n relationship based on sessionId. The following is a relationship diagram:
As can be seen from the figure, when the same sound effect is bound to a different seeingId, a new EffectModule object will be re-created. For example, when the BassBoost bass enhancement sound effect is bound to the sessionId of QQ Music and Kugou Music respectively, two different BassBoost objects will be created. In this way, the two sound effects processes will not interfere with each other.
We talked about the execution order between multiple EffectChains before. So what is the execution order of multiple EffectModules in EffectChain? AudioFlinger is controlled based on the flags in the effect_descriptor_t structure (sound effect algorithm description class). In the flags specified by the sound effect algorithm you implement, you can specify any of the following flags:
EFFECT_FLAG_INSERT_FIRST: Indicates inserting your own sound effect algorithm into the front of EffectChain. That is: executed first. If multiple sound effect algorithms specify this flag, they will be sorted according to the time when the EffectModule was created, and the ones created later will be executed later.
EFFECT_FLAG_INSERT_LAST: Indicates that this sound effect algorithm is inserted into the end of EffectChain for execution. If multiple sound effect algorithms declare this flag, the newly created EffectModule will be inserted in front of the last one.
EFFECT_FLAG_INSERT_ANY: Indicates inserting this sound effect algorithm into INSERT_FIRST and INSERT_LAST. If there are multiple entries, they will be inserted backwards in order of the time they were added.
EFFECT_FLAG_INSERT_EXCLUSIVE: Indicates exclusive. This means that the inserted EffectChain can only contain this sound effect algorithm.
The following is the execution sequence of multiple EffectModules in EffectChain:
INSERT_FIRST1--》INSERT_FIRST2--》INSERT_ANY1--》INSERT_ANY2--》INSERT_LAST2--》INSERT_LAST1When the PlaybackThread in AudioFlinger is executed, three local memory blocks will be created: mMixerBuffer, mEffectBuffer, and mSinkBuffer.
The mMixerBuffer memory block stores all audio data of Tracks that are not bound to any sound effect algorithm.
The mEffectBuffer memory block stores all Track audio data processed by the sound effect algorithm.
The mSinkBuffer memory block stores the audio data that ultimately needs to be output to StreamOut in the AudioHAL process.
All Track data will first be passed to the AudioMixer mixer for multi-channel conversion, sampling accuracy adjustment, and resampling, and then will be passed to the bound sound effect algorithm for processing or to the mMixerBuffer memory block.
When PlaybackThread plays this time, all Tracks are not bound to the sound effect algorithm, and PlaybackThread will copy the data in mMixerBuffer directly to mSinkBuffer.
When PlaybackTread plays this time, all Tracks are bound to have sound effect algorithms, and there is no data in the mMixerBuffer memory block, so it will not be copied and moved anywhere.
When PlaybackTread plays this time, there are tracks bound to the sound effect algorithm and tracks that are not bound. PlaybackThread will first copy the data in mMixerBuffer to mEffectBuffer, and then copy the data of mEffectBuffer to mSinkBuffer.
The following is the audio data transmission flow chart:

4. Binding process of Device sound effects
Android supports two ways to bind a sound effect algorithm to the Device for processing. One is to dynamically create an AudioEffect object and assign the seesionId to the object to be AUDIO_SESSION_DEVICE. The other is to declare it in the <deviceEffects> node of the audio_effects.xml file, and then after it is parsed by AudioPolicyService, it notifies AudioFlinger to bind. Below I will explain the binding method through the audio_effects.xml configuration file.
In its initialization function onFirstRef(), AudioPolicyService will create an AudioPolicyEffects object. In its constructor, AudioPolicyEffects will parse the audio_effects.xml file and then notify AudioFlinger to bind sound effects. The following is the code calling process:
AudioPolicyService.cpp->onFirstRef()
|->new AudioPolicyEffects()
|->AudioPolicyEffects.cpp->loadAudioEffectXmlConfig()//mInputSources集合中保存的是<preprocess>节点中的配置。mOutputStreams集合中保存的是<postprocess>节点中的配置。mDeviceEffects集合中保存的是<deviceEffects>节点中的配置。
|->EffectsConfig.cpp->parse()//libeffectsconfig
|->AudioPolicyEffects.cpp->initDefaultDeviceEffects()AudioPolicyEffects, like EffectHAL, also calls EffectsConfig.cpp->parse() to parse the audio_effects.xml file. It will save the configuration in the <deviceEffects> node to the mDeviceEffects collection, and save the configuration in the <preprocess> node. The configuration is saved to the mInputSources collection, and the configuration in the <postprocess> node is saved to the mOutputStreams collection.
Then the initDefaultDeviceEffects() function is called to notify AudioFlinger to bind Device sound effects. In this function, an AudioEffect.cpp object is created for each sound effect algorithm to be bound, the session ID is set to AUDIO_SESSION_DEVICE, and the DeviceType to be bound is set to the AudioEffect object. Then call the AudioEffect->setEnabled(true) function. After doing this, the AudioEffect object will notify AudioFlinger to bind the Device sound effect when it is initialized. The following is the code calling process:
AudioPolicyEffects.cpp->initDefaultDeviceEffects()//绑定Device音效。为每个Device对应的所有Effect,都分别创建一个包名为android的客户端AudioEffect对象。并初始化它。
|->AudioEffect.cpp->set(AUDIO_SESSION_DEVICE)
|->AudioFlinger.cpp->createEffect()//Binder跨进程调用
|->DeviceEffectManager.cpp->AudioFlinger::DeviceEffectManager::createEffect_l()
|->new DeviceEffectProxy()//从mDeviceEffects列表中找不到此音效时,新创建一个。
|->new EffectHandle()//mEffect引用的是DeviceEffectProxy对象
|->Effects.cpp->AudioFlinger::DeviceEffectProxy::init()
|->Effects.cpp->AudioFlinger::DeviceEffectProxy::onCreatePatch()
|->Effects.cpp->AudioFlinger::DeviceEffectProxy::checkPort()//为当前Device绑定音效
|->AudioEffect.cpp->setEnabled(true) As can be seen from the above code flow, AudioFlinger creates a DeviceEffectProxy object through its own member variable DeviceEffectManager. The place where Device sound effect binding is implemented is in the DeviceEffectProxy::checkPort() function. This function implements two binding methods for Device sound effects:
- One is to let DeviceHAL in the AudioHAL process directly process the sound effect data. Implemented by calling the audio.h->audio_hw_device_t.add_device_effect(audio_port_handle_t device, effect_handle_t effect) interface. In this way, there will be no cross-process calls and shared memory creation during the sound effect algorithm processing. That is to say, the data generated by the sound effect algorithm will be processed by the AudioHAL process instead of AudioFlinger. AudioFlinger is only responsible for controlling the parameters of the sound effect algorithm.
- Another method is to find the PlaybackThread corresponding to the Device, let the PlaybackThread create the EffectModule object, and insert it into the EffectChain corresponding to the sessionId of AUDIO_SESSION_DEVICE. Finally, the PlaybackThread calls the EffectChain->process_l() function to process the sound effect when transmitting audio data. Algorithm-generated data. That is to say, the AudioServer process is responsible for processing the sound effect data. This approach results in cross-process calls and additional shared memory creation.
4.1 How DeviceHAL processes sound effect data
Using this method, the loaded sound effect algorithm must be declared as a pre-processing sound effect type (EFFECT_FLAG_TYPE_PRE_PROC) or a post-processing sound effect type (EFFECT_FLAG_TYPE_PRE_PROC) a> this flag. They are declared by setting effect_descriptor_t->flags in the implementation code of the sound effect algorithm. EFFECT_FLAG_HW_ACC_TUNNEL). And declare EFFECT_FLAG_TYPE_POST_PROC
In the DeviceEffectProxy::checkPort() function, if the sound effect algorithm to be bound contains EFFECT_FLAG_HW_ACC_TUNNEL flag, a new one will be created EffectModule object, saving it to its own DeviceEffectProxy::mHalEffect variable.
Let's take a look at what the AudioEffect.cpp->setEnabled(true) function does?
AudioPolicyEffects.cpp->initDefaultDeviceEffects()
|->AudioEffect.cpp->setEnabled(true)
|->Effects.cpp->AudioFlinger::EffectHandle::enable()//对应的是DeviceEffectProxy
|->Effects.cpp->AudioFlinger::DeviceEffectProxy::setEnabled()
|->Effects.cpp->AudioFlinger::EffectBase::setEnabled()//执行的是DeviceEffectProxy对象的方法
|->Effects.cpp->AudioFlinger::EffectBase::setEnabled_l()//mState = STARTING,设置的是DeviceEffectProxy对象状态
|->Effects.cpp->AudioFlinger::DeviceEffectProxy::ProxyCallback::onEffectEnable(sp<EffectBase>& effectBase)//传入的是DeviceEffectProxy对象,所以直接返回null
|->Effects.cpp->AudioFlinger::EffectHandle::enable()//执行的DeviceEffectProxy的mEffectHandles集合中保存的EffectHandle对象,对应的是EffectModule对象
|->Effects.cpp->AudioFlinger::EffectBase::setEnabled()//执行的是EffectModule对象的方法
|->Effects.cpp->AudioFlinger::EffectBase::setEnabled_l()//mState = STARTING,设置的是EffectModule对象状态
|->Effects.cpp->AudioFlinger::DeviceEffectProxy::ProxyCallback::onEffectEnable(sp<EffectBase>& effectBase)传入的是EffectModule对象
|->Effects.cpp->AudioFlinger::EffectModule::start()
|->Effects.cpp->AudioFlinger::EffectModule::start_l()
|->EffectHalHidl.cpp->command(EFFECT_CMD_ENABLE)//通知EffectHAL层enable
|->Effects.cpp->AudioFlinger::EffectModule::addEffectToHal_l()//只有EFFECT_FLAG_TYPE_PRE_PROC或EFFECT_FLAG_TYPE_POST_PROC才执行下面的代码
|->Effects.cpp->AudioFlinger::DeviceEffectProxy::ProxyCallback::addEffectToHal()
|->Effects.cpp->AudioFlinger::DeviceEffectProxy::addEffectToHal()
|->DeviceEffectManager.h->DeviceEffectManagerCallback::addEffectToHal()
|->DeviceEffectManager.h->DeviceEffectManager::addEffectToHal()
|->AudioFlinger.cpp->addEffectToHal()
|->DeviceHalHidl.cpp->addDeviceEffect()
|->Device.cpp->addDeviceEffect()//Binder跨进程调用
|->EffectMap.cpp->EffectMap::getInstance().get(effectId)//源码在/hardware/interfaces/audio/common/all-versions/default/目录
|->audio.h->audio_hw_device_t.add_device_effect() From the above code calling process, we can see that the nested relationship between Effect and Callback in the Effects.cpp file is quite deep. In the end, through layers of calls, we finally calledaudio.h->audio_hw_device_t.add_device_effect(audio_port_handle_t device, effect_handle_t effect)interface. Successfully passed the effect_handle_t handle of this sound effect algorithm to DeviceHAL's audio_hw_device_t Association binding.
4.2 How AudioFlinger processes sound effect data
In the DeviceEffectProxy::checkPort() function, the PlaybackThread corresponding to the Device that needs to be bound to the sound effect is found through the PatchPanel::Patch object, and then the createEffect_l(AUDIO_SESSION_DEVICE) function is called to load the sound effect.
Effects.cpp->AudioFlinger::DeviceEffectProxy::checkPort()
|->Threads.cpp->AudioFlinger::ThreadBase::createEffect_l(AUDIO_SESSION_DEVICE)
|->Threads.cpp->AudioFlinger::PlaybackThread::checkEffectCompatibility_l()//FAST线程要求AUDIO_SESSION_DEVICE只能应用EFFECT_FLAG_TYPE_POST_PROC音效。
|->new EffectChain()
|->Threads.cpp->AudioFlinger::PlaybackThread::addEffectChain_l()//初始化EffectChain
|->EffectsFactoryHalHidl.cpp->mirrorBuffer()
|->EffectBufferHalHidl.cpp->mirror()//创建共享内存,mExternalData指向的是PlaybackThread的mEffectBuffer
|->halOutBuffer = halInBuffer;//输入和输出共享内存都指向的是mEffectBuffer
|->Effects.h->EffectChain::setInBuffer(halInBuffer)
|->Effects.h->EffectChain::setOutBuffer(halOutBuffer)
|->mEffectChains.insertAt(chain, i)//按照sessionId从大到小插入。全局session都是负数,所以在最后。顺序:track-EffectChain、MIX-EffectChain、STAGE-EffectChain、DEVICE-EffectChain
|->Effects.cpp->AudioFlinger::EffectChain::createEffect_l()//创建EffectModule
|->new EffectModule()
|->Effects.cpp->AudioFlinger::EffectChain::EffectCallback::createEffectHal()
|->EffectsFactoryHalHidl.cpp->createEffect()//通知EffectHAL去创建真正的音效算法对象
|->Effects.cpp->AudioFlinger::EffectChain::addEffect_ll(){
effect->setInBuffer(mInBuffer);
if (idx_insert == previousSize) {
if (idx_insert != 0) {
mEffects[idx_insert-1]->setOutBuffer(mInBuffer);
}
effect->setOutBuffer(mOutBuffer);
} else {
effect->setOutBuffer(mInBuffer);
}
}As can be seen from the above calling code flow, a new EffectChain is created in PlaybackThread, and the input and output shared memory blocks of EffectChain are created, both of which point to the mEffectBuffer local memory block. All EffectModule objects contained in this EffectChain use the input memory block of EffectChain for their input and output shared memory blocks. Only the output memory block of the last EffectModule uses the output memory block of EffectChain. But when the EffectChain corresponding to AUDIO_SESSION_DEVICE creates a shared memory block, the input and output are the same, so it doesn't matter. The following is the audio data transmission flow chart:

5. Binding process of Stream sound effects
There are two binding methods for Stream sound effects. One is to declare it in the <postprocess> node of the audio_effects.xml file, so that the AudioPolicyEffects module will save the configuration information to the mOutputStreams collection after parsing.
Another way to dynamically bind is to create a StreamDefaultEffect.java object and specify the TypeUUID, UUID, and AudioAttributes.Usage of the sound effect to be bound in the constructor of the class. In its constructor, it will be called through layers, and finally the addStreamDefaultEffect() function of AudioPolicyEffects will be called. AudioPolicyEffects will find the StreamType corresponding to AudioAttributes.Usage through AudioPolicyManager, and then find the corresponding sound effect description object effect_descriptor_t from EffectHAL according to the UUID. Finally, the StreamType and effect_descriptor_t are saved together into the mOutputStreams collection.
Let's take a look at how AudioPolicyEffects binds Stream sound effects through the mOutputStreams collection.
In the play() function of AudioTrack.java, the addTrack_l() function of PlaybackThread will be called, and the addTrack_l() function will call the AudioPolicyService::startOutput() function. The startOutput() function will eventually call AudioPolicyEffects::addOutputSessionEffects( )function. Therefore, the binding is done by the addOutputSessionEffects() function.
AudioTrack.java->play()
|->Threads.cpp->AudioFlinger::PlaybackThread::addTrack_l()
|->AudioPolicyInterfaceImpl.cpp->AudioPolicyService::startOutput()
|->AudioPolicyEffects.cpp->AudioPolicyEffects::addOutputSessionEffects(
audio_io_handle_t output,
audio_stream_type_t stream,
audio_session_t audioSession)
|->new AudioEffect()
|->AudioEffect.cpp->set()
|->AudioPolicyEffects.cpp->AudioPolicyEffects::EffectVector::setProcessorEnabled(true)
|->AudioEffect.cpp->setEnabled(true)
|->Effects.cpp->AudioFlinger::EffectBase::setEnabled_l()//mState = STARTING
The three parameters passed in the addOutputSessionEffects() function are the Id (output) of the PlaybackThread corresponding to this AudioTrack, the StreamType (stream) corresponding to this AudioTrack, and the seesionId (audioSession) of this AudioTrack. In this way, the addOutputSessionEffects() function can find the sound effect algorithm description object effect_descriptor_t it needs to bind from the mOutputStreams collection based on StreamType, and also find the UUID of the sound effect algorithm. Then the addOutputSessionEffects() function creates an AudioEffect.cpp object and assigns the UUID of Effect and the seesionId of AudioTrack to the object.
It can be seen that the method of binding Stream sound effects in Android is no different from binding Track sound effects. That is: when each AudioTrack corresponding to this StreamType is ready to play, a new AudioEffect is created for their associated seeingId.
The reason for this design, I think, is that multiple AudioTracks corresponding to the same StreamType can be assigned to different PlaybackThreads for processing. In this way, the two AudioTracks cannot be placed in the mEffectBuffer memory block corresponding to the same thread for processing. .
As can be seen from the above, Stream sound effects are actually StreamType sound effects in a strict sense. It is not directly bound to a StreamOut stream.
<preprocess>The node binding process is similar and will not be described in detail here.
6. How StreamHAL processes sound effect data
When I looked at the /hardware/libhardware/include/hardware/audio.h interface file, I found that the audio_stream_t structure defines a function:audio_stream_t->add_audio_effect(effect_handle_t effect ). Does this mean that sound effects can be bound to the StreamOut stream? That is: let StreamHAL directly process the sound effect data like DeviceHAL processes the sound effect data, without creating and moving shared memory? The answer is yes. However, when I analyze the setup process in AudioFlinger below, we will find that this process is very unreasonably designed and has loopholes. If I understand it wrong, please correct me!
If you want to bind a sound effect algorithm to StreamHAL for processing. Just declare it in your own sound effect algorithm as a pre-processing sound effect type (EFFECT_FLAG_TYPE_PRE_PROC) or a post-processing sound effect type ( EFFECT_FLAG_TYPE_POST_PROC) will do. AudioFlinger will eventually call the audio_stream_t->add_audio_effect(effect_handle_t effect) interface of the StreamHAL layer for binding.
The entrance to the AudioFlinger module call is in the audio data processing function threadLoop() of PlaybackThread. That is, in the loop execution function of the playback thread.
AudioFlinger::PlaybackThread::threadLoop()
|->Effects.cpp->AudioFlinger::EffectChain::process_l()
|->Effects.cpp->AudioFlinger::EffectModule::process()
|->Effects.h->EffectBase::isProcessImplemented()//判断effect_descriptor_t->flags是否包含EFFECT_FLAG_NO_PROCESS
|->Effects.cpp->AudioFlinger::EffectModule::updateState()
|->Effects.cpp->AudioFlinger::EffectModule::start_l()
|->AudioFlinger::EffectModule::addEffectToHal_l()//只有EFFECT_FLAG_TYPE_PRE_PROC或EFFECT_FLAG_TYPE_POST_PROC才执行下面的代码
|->AudioFlinger::EffectChain::EffectCallback::addEffectToHal()
|->StreamHalHidl.cpp->addEffect()
|->Stream.cpp->addEffect(effectId)//Binder跨进程调用
|->EffectMap.cpp->EffectMap::getInstance().get(effectId)//源码在/hardware/interfaces/audio/common/all-versions/default/目录
|->audio.h->audio_stream_t.add_audio_effect()
As can be seen from the above code flow, EffectModule will call the binding interface of StreamHAL in its start_l() function. The only criterion for whether to call it is whether the sound effect algorithm declares a pre-processing sound effect type (EFFECT_FLAG_TYPE_PRE_PROC) or a post-processing sound effect type (EFFECT_FLAG_TYPE_POST_PROC).
As long as the sound effect algorithm is declared, it will be bound. It doesn't matter what type of seesionId is associated with this sound effect algorithm, that is, it can be associated with AudioTrack sessionId, AUDIO_SESSION_OUTPUT_MIX, or AUDIO_SESSION_OUTPUT_STAGE.
Only AUDIO_SESSION_DEVICE will not work, because the EffectModule corresponding to AUDIO_SESSION_DEVICE, its EffectModule::mCallback variable points to DeviceEffectProxy::ProxyCallback, not EffectChain::EffectCallback, so it is ultimately bound to DeviceHAL.
With such a simple and crude design, I can think of two loopholes:
- The same StreamHAL will be bound to the same type of sound effect algorithm multiple times. For example, I bound the bass enhancement algorithm to sessionId1 of AudioTrack1 that is processed in the same PlaybackThread, and bound the bass enhancement algorithm to seesionId2 of AudioTrack2. The UUIDs of their two algorithms are exactly the same, but there will be two different EffectModule objects, so in the end the interface will is executed twice. Moreover, the handles of effect_handle_t are different objects. The remedy is to modify the /hardware/interfaces/audio/core/all-versions/default/Stream.cpp->addEffect() function. Add a judgment for the same algorithm UUID. If the sound effect algorithm with the same UUID has been bound, it will no longer be calledaudio_stream_t->add_audio_effect(effect_handle_t effect)interface.
- AudioFlinger and StreamHAL will process sound effect data at the same time. Because in the EffectModule::process() function, the sound effect processing type (EFFECT_FLAG_TYPE_PRE_PROC or EFFECT_FLAG_TYPE_POST_PROC) is not judged. It is only judged whether the EFFECT_FLAG_NO_PROCESS flag is declared for this sound effect algorithm. Only if the EFFECT_FLAG_NO_PROCESS flag is declared, the sound effect data will not be processed. In other words, the data generated by the sound effect algorithm that does not declare the EFFECT_FLAG_NO_PROCESS flag will be processed by AudioFlinger and StreamHAL at the same time. The reason why this does not happen with Device sound effects is that the EffectModule bound to DeviceHAL has both mInBuffer and mOutBuffer null, that is, no shared memory data is created. It cannot be processed. There are two remedies: one is to declare the EFFECT_FLAG_NO_PROCESS flag in the implementation code of the sound effect algorithm, but you need to ensure that the StreamHAL implemented by the SoC manufacturer does not use this flag to determine whether to let the sound effect algorithm process it. Another method is to modify the EffectModule::process() function and add the judgment of the sound effect processing type (EFFECT_FLAG_TYPE_PRE_PROC or EFFECT_FLAG_TYPE_POST_PROC). If the EffectModule containing these two flags does not notify the sound effect algorithm to process the data.
7. The binding process of Track sound effects
Through the previous introduction, you can basically guess the method of binding sound effects to an AudioTrack. Just follow two steps:
- Create an AudioEffect.java object. In its constructor, specify the AudioTrack sessionId obtained from AudioTrack.java->getAudioSessionId(), the UUID or TypeUUID of the specified sound effect algorithm. However, the constructor of AudioEffect.java is of @hide type and does not support 3rd APP calls. Android creates a java file for all sound effect algorithms supported by the system, such as BassBoost.java. These sound effect classes are inherited from AudioEffect.java. And by default, its TypeUUID is assigned to the AudioEffect.java parent class. Therefore, ordinary 3rd APP can directly new BassBoost object, just specify the seesionId. In other words, ordinary 3rd APP cannot bind the sound effect algorithm type expanded by the device manufacturer itself. Unless the AudioEffect.java object is created directly through the Java reflection mechanism.
- Call the AudioEffect.java->setEnabled(true) function to start the sound effect algorithm.
Let me take the BassBoost bass enhancement algorithm as an example to see how it is bound to AudioTrack.
new BassBoost(AudioTrackSessionId)
|->AudioEffect.java->AudioEffect(EFFECT_TYPE_BASS_BOOST,AudioTrackSessionId)
|->AudioEffect.java->native_setup()
|->android_media_AudioEffect.cpp->android_media_AudioEffect_native_setup()
|->new AudioEffect(attributionSource)
|->AudioEffect.cpp->set()
|->AudioFlinger.cpp->createEffect()//Binder跨进程调用
|->Threads.cpp->AudioFlinger::ThreadBase::createEffect_l()
|->Threads.cpp->AudioFlinger::PlaybackThread::checkEffectCompatibility_l()
|->Threads.cpp->AudioFlinger::PlaybackThread::addEffectChain_l()
|->EffectsFactoryHalHidl.cpp->mirrorBuffer()//mExternalData指向的是PlaybackThread的mEffectBuffer
|->halOutBuffer = halInBuffer
|->halInBuffer=EffectsFactoryHalHidl.cpp->allocateBuffer()//新创建共享内存块
|->PlaybackTracks.h->Track::setMainBuffer()//设置所有关联此seesionId的track的mMainBuffer,设置的是halInBuffer中的共享内存。
|->Effects.h->EffectChain::setInBuffer()
|->Effects.h->EffectChain::setOutBuffer()//halOutBuffer::mExternalData指向的是PlaybackThread的mEffectBuffer
|->Effects.cpp->AudioFlinger::EffectChain::createEffect_l()
|->Effects.cpp->AudioFlinger::EffectChain::addEffect_ll(){
effect->setInBuffer(mInBuffer);
if (idx_insert == previousSize) {
if (idx_insert != 0) {
mEffects[idx_insert-1]->setOutBuffer(mInBuffer);
}
effect->setOutBuffer(mOutBuffer);
} else {
effect->setOutBuffer(mInBuffer);
}
}After executing the above code process, AudioFlinger will create a new input shared memory block halInBuffer and output shared memory block halOutBuffer for EffectChain. mExternalData of halOutBuffer points to mEffectBuffer of PlaybackThread. All EffectModule objects contained in EffectChain use the input memory block of EffectChain for their input and output shared memory blocks. Only the output memory block of the last EffectModule uses the output memory block of EffectChain.
All AudioTracks bound to this sessionId have their mMainBuffers pointing to the input shared memory halInBuffer of EffectChain. After the AudioMixer mixer processes the data of each AudioTrack, it will copy the data to the memory block pointed to by mMainBuffer.
In this way, the audio data transmission channel is successfully established. The following is the transmission flow chart:

Then,How will it be handled when there are two AudioTracks running on different PlaybackThreads bound to the same sessionId?
For example, I first create an AudioTrackA, which runs in DeepBuffer PlayackThread. Then create an AudioEffect and bind it to TrackA-sessionId. Finally, create an AudioTrackB, let it run in the Primary PlaybackThread, and assign TrackA-sessionId to AudioTrackB.
In this case, the result is that AudioEffect will eventually be bound to AudioTrackB for execution, and AudioTrackA will be unbound to remove this AudioEffect sound effect. The key processing code is in the function AudioFlinger.cpp->createTrack() where AudioFlinger creates AudioTrackB. As follows:
// move effect chain to this output thread if an effect on same session was waiting
// for a track to be created
if (lStatus == NO_ERROR && effectThread != NULL) {
// no risk of deadlock because AudioFlinger::mLock is held
Mutex::Autolock _dl(thread->mLock);
Mutex::Autolock _sl(effectThread->mLock);
if (moveEffectChain_l(sessionId, effectThread, thread) == NO_ERROR) {
effectThreadId = thread->id();
effectIds = thread->getEffectIds_l(sessionId);
}
}The AudioFlinger.cpp->moveEffectChain_l() function will eventually call PlaybackThread::removeEffectChain_l() to delete EffectChain. code show as below:
size_t AudioFlinger::PlaybackThread::removeEffectChain_l(const sp<EffectChain>& chain)
{
audio_session_t session = chain->sessionId();
ALOGV("removeEffectChain_l() %p from thread %p for session %d", chain.get(), this, session);
for (size_t i = 0; i < mEffectChains.size(); i++) {
if (chain == mEffectChains[i]) {
mEffectChains.removeAt(i);
// detach all active tracks from the chain
for (const sp<Track> &track : mActiveTracks) {
if (session == track->sessionId()) {
ALOGV("removeEffectChain_l(): stopping track on chain %p for session Id: %d",
chain.get(), session);
chain->decActiveTrackCnt();
}
}
// detach all tracks with same session ID from this chain
for (size_t i = 0; i < mTracks.size(); ++i) {
sp<Track> track = mTracks[i];
if (session == track->sessionId()) {
track->setMainBuffer(reinterpret_cast<effect_buffer_t*>(mSinkBuffer));
chain->decTrackCnt();
}
}
break;
}
}
return mEffectChains.size();
}As you can see from the above code, PlaybackThread deletes all sound effects associated with AudioTrackA and points AudioTrackA's mainBuffer to mSinkBuffer.
8. The binding process of Aux sound effects
Android supports AudioTrack to bind an Aux sound effect (auxiliary effect). When AudioTrack is bound to an Aux sound effect, AudioMixer mixer will process the audio data. AudioTrack data is copied into two copies, one copy is processed in the ordinary Track sound effect bound to it, the other copy is processed in the Aux sound effect, and finally merged by PlaybackThread. I think this is a bug in Android, because in the source code, the person who wrote the Threads.cpp code will disable the Aux sound effect bound to AudioTrack when it is bound to a normal Track sound effect. However, the person who wrote the Effects.cpp code clearly did not disable the Aux sound effect in the implementation function of sound effect disabling. Therefore, in the end, it was not disabled, so that ordinary Track sound effects and Aux sound effects could process the same AudioTrack data at the same time. I will explain the code logic in detail below.
For algorithms defined as Aux sound effects, the EFFECT_FLAG_TYPE_AUXILIARY flag must be declared. Otherwise, it cannot be used as an Aux sound effect bound to AudioTrack.
The EffectModule of all Aux sound effects will be put into the EffectChain of MIX sessionId. In other words, Aux sound effects can only be associated to AUDIO_SESSION_OUTPUT_MIX. And MIX sessionId can only be associated with Aux sound effects.
The method of binding Aux sound effects is mainly divided into four steps:
- Create an Aux sound effect control object AudioEffect, specify the sessionId as AUDIO_SESSION_OUTPUT_MIX. Requires APP to have the "android.permission.MODIFY_AUDIO_SETTINGS" permission.
- Start the Aux sound effect: call the AudioEffect.java->setEnabled(true) interface.
- Bind sound effects to AudioTrack: call the AudioTrack.java->attachAuxEffect(int effectId) interface. The input parameter effectId can be obtained through the AudioEffect.java->getId() function. An AudioTrack can only be bound to one Aux sound effect. If you need to cancel the binding, just pass 0 in the AudioTrack.java->attachAuxEffect(int effectId) function.
- Set the data volume for Aux sound effect processing. The default is 0, which means Aux sound effects will not process data. Set by calling the AudioTrack.java->setAuxEffectSendLevel(float level) interface.
The following is the data transmission flow chart of Aux sound effects:

Let me take EnvironmentalReverb as an example to analyze the creation process of Aux sound effects.
//创建Aux音效
new EnvironmentalReverb(AUDIO_SESSION_OUTPUT_MIX)
|->AudioEffect.java->AudioEffect(EFFECT_TYPE_ENV_REVERB,AUDIO_SESSION_OUTPUT_MIX)
|->AudioFlinger.cpp->createEffect()//Binder跨进程调用
|->ServiceUtilities.cpp->settingsAllowed()//将Effect绑定到MIX SessionId时,需要APP拥有"android.permission.MODIFY_AUDIO_SETTINGS"权限。没有声明此权限就会直接返回。
|->AudioFlinger.cpp->getEffectDescriptor(uuid,type,EFFECT_FLAG_TYPE_AUXILIARY)//找到声明了EFFECT_FLAG_TYPE_AUXILIARY标识的音效描述对象,没有声明的就会直接返回。
|->AudioSystem.cpp->getOutputForEffect(effect_descriptor_t)//为此音效找到合适的PlaybackThreadId
|->AudioPolicyIntefaceImpl.cpp->AudioPolicyService::getOutputForEffect()
|->AudioPolicyManager.cpp->getOutputForEffect()
|->AudioPolicyManager.cpp->selectOutputForMusicEffects()//查找outputstream的逻辑是先找到STRATEGY_MEDIA现在对应的播放Device,再根据Device找到可播放到该Device的outputStream。有多个outputStream时,按照以下顺序返回:1: An offloaded output. 2: A deep buffer output 3: The primary output 4: the first output in the list
|->Engine.cpp->getOutputDevicesForAttributes(AUDIO_USAGE_MEDIA)
|->mEffects.moveEffects(AUDIO_SESSION_OUTPUT_MIX, mMusicEffectOutput, output);
|->AudioPolicyClientImpl.cpp->AudioPolicyService::AudioPolicyClient::moveEffects(AUDIO_SESSION_OUTPUT_MIX, mMusicEffectOutput, output)
|->AudioFlinger.cpp->moveEffects()
|->AudioFlinger.cpp->moveEffectChain_l(AUDIO_SESSION_OUTPUT_MIX,srcThread,dstThread)//通知AudioFlinger,将AUDIO_SESSION_OUTPUT_MIX对应的EffectChain,从旧的PlaybackThread移动到指定的PlaybackThread中。
|->Threads.cpp->AudioFlinger::ThreadBase::createEffect_l()
|->Threads.cpp->AudioFlinger::PlaybackThread::addEffectChain_l()
|->EffectsFactoryHalHidl.cpp->mirrorBuffer(&halInBuffer)//mExternalData指向的是PlaybackThread的mEffectBuffer
|->halOutBuffer = halInBuffer;
|->Effects.h->EffectChain::setInBuffer(halInBuffer)
|->Effects.h->EffectChain::setOutBuffer(halOutBuffer)
|->Threads.cpp->AudioFlinger::ThreadBase::checkSuspendOnAddEffectChain_l(chain)//检查一下自己这个EffectChain对应的sessionId是否被禁用音效了
|->Effects.cpp->AudioFlinger::EffectChain::createEffect_l()
|->Effects.cpp->AudioFlinger::EffectChain::addEffect_ll(){
mEffects.insertAt(effect, 0);//每次都将新添加的Aux音效插入到队列的最前面。
EffectsFactoryHalHidl.cpp->allocateBuffer(halBuffer)//新创建一块共享内存
effect->setInBuffer(halBuffer);
effect->setOutBuffer(mInBuffer);
}As can be seen from the above code calling process, there are three main differences from the Track sound effect creation process.
One is that when creating an Aux sound effect, AudioFlinger will query a suitable PlaybackThread from the AudioPolicyManager to bind. Because this Aux sound effect corresponds to the global MIX-sessionId, rather than the Track-sessionId like the Track sound effect, it is impossible to find its associated PlaybackThread based on the specific Track object.
AudioPolicyManager returns the PlaybackThread corresponding to MUSIC streamType. When an AudioTrack is bound to this Aux sound effect, AudioFlinger will move the EffectModule of this Aux sound effect to the PlaybackThread corresponding to the AudioTrack.
The second difference is that the sound effect shared memory blocks created are different. AudioFlinger will create a new input shared memory block for each Aux sound effect. Then point the output memory of the Aux sound effect to the input\output shared memory block of EffectChain-MIX. Because the input memory block and output memory block of EffectChain-MIX are the same.
The third difference is that AudioFlinger limits the EffectChain corresponding to MIX sessionId to only exist in one PlaybackThread. That is: MIXsessionId-EffectChain is globally unique. In other words, all Aux sound effects can only be processed in the same PlaybackThread. The following is the code for the relevant restrictions, in the AudioFlinger.cpp->createEffect() function.
} else if (checkPlaybackThread_l(io) != nullptr
&& sessionId != AUDIO_SESSION_OUTPUT_STAGE) {
// allow only one effect chain per sessionId on mPlaybackThreads.
for (size_t i = 0; i < mPlaybackThreads.size(); i++) {
const audio_io_handle_t checkIo = mPlaybackThreads.keyAt(i);
if (io == checkIo) {
if (hapticPlaybackRequired
&& mPlaybackThreads.valueAt(i)
->hapticChannelMask() == AUDIO_CHANNEL_NONE) {
ALOGE("%s: haptic playback thread is required while the required playback "
"thread(io=%d) doesn't support", __func__, (int)io);
lStatus = BAD_VALUE;
goto Exit;
}
continue;
}
const uint32_t sessionType =
mPlaybackThreads.valueAt(i)->hasAudioSession(sessionId);
if ((sessionType & ThreadBase::EFFECT_SESSION) != 0) {
ALOGE("%s: effect %s io %d denied because session %d effect exists on io %d",
__func__, descOut.name, (int) io, (int) sessionId, (int) checkIo);
android_errorWriteLog(0x534e4554, "123237974");
lStatus = BAD_VALUE;
goto Exit;
}
}
}Let’s take a look at the binding process of Aux sound effects:
//绑定Aux音效
AudioTrack.java->attachAuxEffect(int effectId)
AudioTrack.cpp->attachAuxEffect()
Tracks.cpp->AudioFlinger::TrackHandle::attachAuxEffect()
Tracks.cpp->AudioFlinger::PlaybackThread::Track::attachAuxEffect()
AudioFlinger.cpp->moveAuxEffectToIo(EffectId,dstThread)//只将此EffectModule从原来PlaybackThread-MIXsessionId-EffectChain中移动到此AudioTrack运行的PlaybackThread的MIXsessionId-EffectChain中。此时就会有两个MIXsessionId-EffectChain
Threads.cpp->AudioFlinger::PlaybackThread::attachAuxEffect()
Tracks.cpp->AudioFlinger::PlaybackThread::Track::setAuxBuffer(effect->inBuffer())//将此AudioTrack的AuxBuffer指向EffectModule的输入共享内存块。
As can be seen from the above code, AudioFlinger points Track's mAuxBuffer pointer to the input shared memory block of the Aux sound effect. At the same time, the Aux sound effect EffectModule will be moved to the PlaybackThread corresponding to this AudioTrack.
I think there are loopholes in the design of the Aux sound effect binding process. It assumes a premise that all AudioTracks that use Aux sound effects are of Music StreamType type. Because when the AudioTrack of the Music StreamType type is created, the AudioPolicyManager will forcibly bind it to the DeepBuffer PlaybackThread (AudioPolicyManager.cpp->selectOutputForMusicEffects() function). Therefore, there will be no movement of the Aux sound effects at all. Because all Music AudioTracks are in DeepBuffer PlaybackThread, and all Aux sound effects are also in DeepBuffer PlaybackThread when they are created. Because when the AudioEffect of the Aux sound effect is created, the AudioPolicyManger also selects the DeepBuffer PlaybackThread (AudioPolicyManager.cpp->selectOutputForMusicEffects() function) for it.
In fact, Aux sound effects generally serve Music StreamType scenes, which include music playback, video playback, and game playback.
However, assume that there is already an AudioTrack of Music StreamType bound to this Aux sound effect, which runs in DeepBuffer PlaybackThread. Now we forcefully create an audioTrack of System StreamType, let it run in the Primary PlaybackThread, and then bind this Aux sound effect, which will cause movement. The EffectModule moves from the DeepBuffer Thread to the Primary Thread, and the EffectChain corresponding to the MIX sessionId also moves to Primary Thread. The AudioTrack of the previous Music StreamType will be unbound to this Aux sound effect, and there will be no Aux sound effect processing. If you create a new Aux sound effect later, such as a new PresetReverb() object, AudioFlinger will obtain the DeepBuffer PlaybackThread from the AudioPolicyManger in the createEffect() function, and then bind it, but in AudioFlinger.cpp->createEffect() The function restricts the EffectChain corresponding to MIX sessionId to only exist in one PlaybackThread (the third point above), causing PresetReverb sound effect creation to fail. That is to sayall Aux sound effects created later will fail, and Aux sound effects can no longer be created.
Therefore, I think there is a loophole in the process of binding Aux sound effects designed by Android. I think the simple modification method is that since the designer wants MIX sessionId to be bound only to Aux sound effects, and the EffectChain corresponding to MIX sessionId is globally unique. Then it is better to create a new EffectChain directly, bind it to MIX sessionId, and then save this EffectChain as a member variable of AudioFlinger. When the DeepBuffer type PlaybackThread operates Aux sound effects, it is obtained directly from the member variable EffectChain of AudioFlinger. There is no need to move EffectChain objects between various types of PlaybackThreads.
Now let's take a look at another bug I found, which is mentioned at the beginning of the chapter: when a normal Track sound effect is started, the Aux sound effect will be disabled, but the disabling fails.
Let's take a look at the startup process of ordinary Track sound effects, in the AudioEffect.cpp->setEnabled(true) function.
//Track音效启动
AudioEffect.cpp->setEnabled(true)
Effects.cpp->AudioFlinger::EffectHandle::enable()
Effects.cpp->AudioFlinger::EffectChain::EffectCallback::checkSuspendOnEffectEnabled(true)
Threads.cpp->AudioFlinger::ThreadBase::checkSuspendOnEffectEnabled(enabled, effect->sessionId())
Threads.cpp->AudioFlinger::ThreadBase::setEffectSuspended_l(NULL, enabled, AUDIO_SESSION_OUTPUT_MIX)//当enable的是Track音效时,通知AUDIO_SESSION_OUTPUT_MIX对应的EffectChain禁用!
Effects.cpp->AudioFlinger::EffectChain::setEffectSuspendedAll_l(true)
desc = new SuspendedEffectDesc();
mSuspendedEffects.add((int)kKeyForSuspendAll, desc);
Effects.cpp->AudioFlinger::EffectChain::getSuspendEligibleEffects()
Effects.cpp->AudioFlinger::EffectChain::isEffectEligibleForSuspend()//绑定到AUDIO_SESSION_OUTPUT_MIX中的Aux音效不会被禁用,直接返回了!
Threads.cpp->AudioFlinger::ThreadBase::updateSuspendedSessions_l(NULL, true, AUDIO_SESSION_OUTPUT_MIX)//向mSuspendedSessions集合中添加kKeyForSuspendAll。SuspendedSessionDesc.mType=0
desc = new SuspendedSessionDesc()//SuspendedSessionDesc.mType=0
sessionEffects.add(kKeyForSuspendAll, desc);
mSuspendedSessions.replaceValueFor(sessionId, sessionEffects)The two key functions in the above code flow areThreads.cpp->AudioFlinger::ThreadBase::checkSuspendOnEffectEnabled(enabled, effect->sessionId()). The following is the key code of these two functions:Effects.cpp->AudioFlinger::EffectChain::isEffectEligibleForSuspend()and
void AudioFlinger::ThreadBase::checkSuspendOnEffectEnabled(bool enabled,
audio_session_t sessionId,
bool threadLocked) {
if (mType != RECORD) {
// suspend all effects in AUDIO_SESSION_OUTPUT_MIX when enabling any effect on
// another session. This gives the priority to well behaved effect control panels
// and applications not using global effects.
// Enabling post processing in AUDIO_SESSION_OUTPUT_STAGE session does not affect
// global effects
if (!audio_is_global_session(sessionId)) {
setEffectSuspended_l(NULL, enabled, AUDIO_SESSION_OUTPUT_MIX);
}
}
}
bool AudioFlinger::EffectChain::isEffectEligibleForSuspend(const effect_descriptor_t& desc)
{
// auxiliary effects and visualizer are never suspended on output mix
if ((mSessionId == AUDIO_SESSION_OUTPUT_MIX) &&
(((desc.flags & EFFECT_FLAG_TYPE_MASK) == EFFECT_FLAG_TYPE_AUXILIARY) ||
(memcmp(&desc.type, SL_IID_VISUALIZATION, sizeof(effect_uuid_t)) == 0) ||
(memcmp(&desc.type, SL_IID_VOLUME, sizeof(effect_uuid_t)) == 0) ||
(memcmp(&desc.type, SL_IID_DYNAMICSPROCESSING, sizeof(effect_uuid_t)) == 0))) {
return false;
}
return true;
}That is to say, in PlaybackThread, after it is found that the Track sound effect is activated, the EffectChain of MIX sessionId will be notified to disable all Aux sound effects in it. And also added a comment to explain the reason for disabling:
// suspend all effects in AUDIO_SESSION_OUTPUT_MIX when enabling any effect on
// another session. This gives the priority to well behaved effect control panels
// and applications not using global effects.
// Enabling post processing in AUDIO_SESSION_OUTPUT_STAGE session does not affect
// global effects
When EffectChain performs the disabling operation, it specifically adds a judgment. If it is a request to disable the Aux sound effect corresponding to the MIX session ID, it will not be processed! And a special comment has been added to explain this:
// auxiliary effects and visualizer are never suspended on output mix
So, the end result is an AudioTrack that can bind Track sound effects and Aux sound effects at the same time.
9. Data transmission flow chart for all sound effects processing

The above is the data transmission flow chart for all sound effect type processing, which does not include the processing of AUDIO_SESSION_OUTPUT_STAGE. Currently< a i=3>AUDIO_SESSION_OUTPUT_STAGE will only be used in association with spatial audio (Spatializer). I will explain it when I write the framework design of spatial audio.