
Handwriting SE Layer
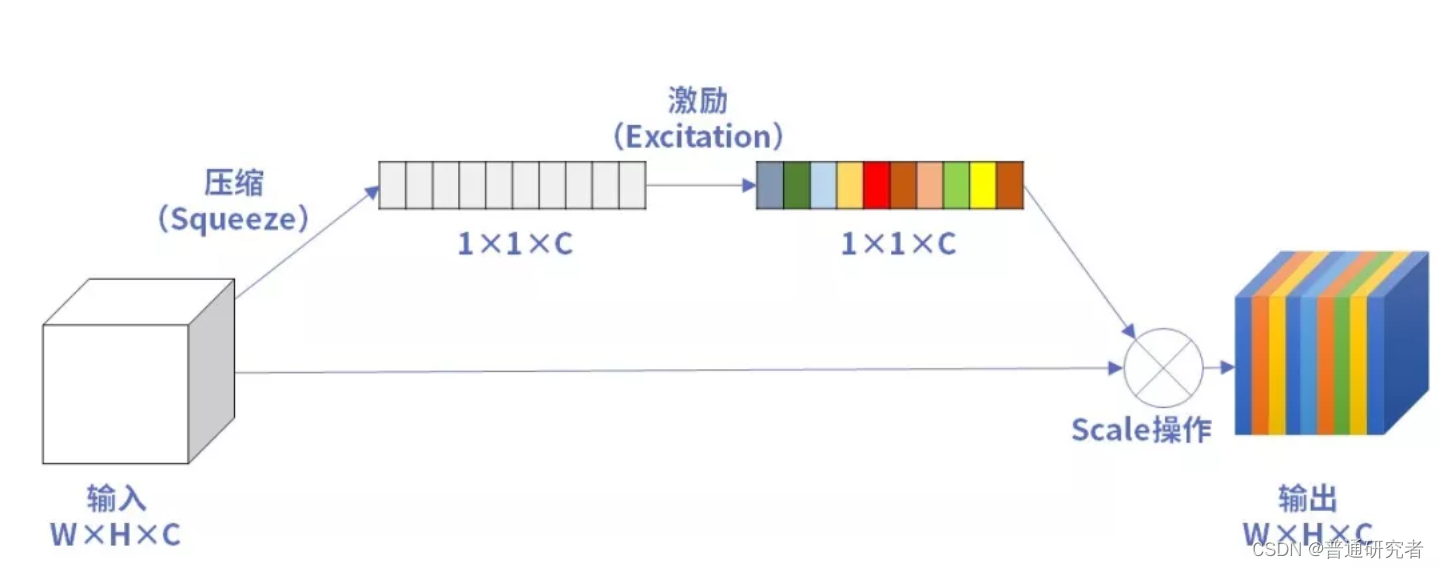
SE (Squeeze-and-Excitation) Layer is an attention mechanism that is usually applied to different levels of deep neural networks to improve the representation capabilities of the model.SE Layer mainly consists of two steps: Squeeze and Excitation. The following is a simple Python implementation of handwritten SE Layer:
```python
import torch
import torch.nn as nn
import torch.nn.functional as F
class SELayer(nn.Module):
def __init__(self, channels, reduction_ratio=16):
super(SELayer, self).__init__()
self.channels = channels
self.reduction_ratio = reduction_ratio
# Squeeze操作
self.squeeze = nn.AdaptiveAvgPool2d(1)
# Excitation操作
self.excitation = nn.Sequential(
nn.Linear(channels, channels // reduction_ratio),
nn.ReLU(inplace=True),
nn.Linear(channels // reduction_ratio, channels),
nn.Sigmoid()
)
def forward(self, x):
# Squeeze
squeezed = self.squeeze(x)
squeezed = squeezed.view(-1, self.channels)
# Excitation
excitation = self.excitation(squeezed)
excitation = excitation.view(-1, self.channels, 1, 1)
# Scale输入特征
scaled_inputs = x * excitation
return scaled_inputs
# 使用例子
input_tensor = torch.randn((1, 64, 224, 224))
se_layer = SELayer(channels=64)
output = se_layer(input_tensor)
print(output.shape)
Handwritten NMS
Non-maximum suppression (NMS) is a technique commonly used in target detection,Used to filter the bounding boxes with the highest confidence and suppress other bounding boxes that overlap them by a large amount. The following is a simple Python implementation of handwritten NMS:
def non_max_suppression(boxes, scores, threshold):
"""
非极大值抑制
参数:
- boxes: 边界框列表,每个边界框表示为 [x1, y1, x2, y2]
- scores: 边界框对应的置信度列表
- threshold: 重叠阈值,大于该阈值的边界框将被抑制
返回:
- selected_indices: 选中的边界框的索引
"""
selected_indices = []
# 根据置信度排序
order = scores.argsort()[::-1]
while len(order) > 0:
# 选取置信度最高的边界框
i = order[0]
selected_indices.append(i)
# 计算当前边界框与其他边界框的IoU(交并比)
x1 = max(boxes[i][0], boxes[order[1:], 0])
y1 = max(boxes[i][1], boxes[order[1:], 1])
x2 = min(boxes[i][2], boxes[order[1:], 2])
y2 = min(boxes[i][3], boxes[order[1:], 3])
intersection = max(0, x2 - x1) * max(0, y2 - y1)
area_i = (boxes[i][2] - boxes[i][0]) * (boxes[i][3] - boxes[i][1])
area_others = (boxes[order[1:], 2] - boxes[order[1:], 0]) * (boxes[order[1:], 3] - boxes[order[1:], 1])
iou = intersection / (area_i + area_others - intersection)
# 保留IoU小于阈值的边界框
mask = iou <= threshold
order = order[1:][mask]
return selected_indices
# 使用例子
boxes = [[100, 100, 200, 200], [150, 150, 250, 250], [100, 120, 180, 200]]
scores = [0.9, 0.8, 0.75]
threshold = 0.5
selected_indices = non_max_suppression(boxes, scores, threshold)
print("Selected Indices:", selected_indices)
In this example,non_max_suppression the function accepts the bounding box list, the corresponding confidence list, and the overlap threshold as input, and returns the index of the selected bounding box. Inside the function, the bounding boxes are first sorted in descending order according to their confidence, and then the bounding boxes with the highest confidence are selected in order, their IoU with other bounding boxes is calculated, and the bounding boxes with IoU less than the threshold are retained. This process is repeated until all bounding boxes have been processed. This will get the final selected bounding box index.
Handwritten IoU
Intersection over Union (IoU), or intersection and union ratio, is an indicator used to measure the degree of overlap between two bounding boxes. The following is a simple Python implementation of handwritten IoU:
def calculate_iou(box1, box2):
"""
计算两个边界框的IoU(交并比)
参数:
- box1: 第一个边界框,表示为 [x1, y1, x2, y2]
- box2: 第二个边界框,表示为 [x1, y1, x2, y2]
返回:
- iou: 交并比
"""
# 计算交集的坐标
x1 = max(box1[0], box2[0])
y1 = max(box1[1], box2[1])
x2 = min(box1[2], box2[2])
y2 = min(box1[3], box2[3])
# 计算交集的面积
intersection = max(0, x2 - x1) * max(0, y2 - y1)
# 计算并集的面积
area_box1 = (box1[2] - box1[0]) * (box1[3] - box1[1])
area_box2 = (box2[2] - box2[0]) * (box2[3] - box2[1])
union = area_box1 + area_box2 - intersection
# 计算交并比
iou = intersection / union if union > 0 else 0.0
return iou
# 使用例子
box1 = [100, 100, 200, 200]
box2 = [150, 150, 250, 250]
iou = calculate_iou(box1, box2)
print("IoU:", iou)
In this example,calculate_iou the function accepts two bounding boxes as input and calculates their intersection and union ratio. The function first calculates the intersection coordinates and area of the two bounding boxes, then calculates their union area, and finally obtains the intersection ratio through the ratio of the intersection and the union. This function returns a value in the range [0, 1] indicating how much the two bounding boxes overlap.
Compare YOLOv1 and YOLOv3
YOLO (You Only Look Once) is a series of target detection algorithms, among which YOLOv1 (released in 2016) and YOLOv3 (released in 2018) are of two versions. Here are some key comparisons between YOLOv1 and YOLOv3:
1. Network structure and complexity:
YOLOv1:
uses a fully connected layer and does not use a convolutional layer, resulting in more network parameters.
Single-scale predictions.
YOLOv3:
Use convolutional layers to build Darknet-53 as a feature extraction network, which improves feature learning capabilities.
Use multi-scale prediction and use features at different levels for target detection.
2. Multi-scale prediction:
YOLOv1:
Target detection is only performed in the last output layer, and the detection effect for small targets is not ideal.
YOLOv3:
Utilizes the FPN (Feature Pyramid Network) structure to perform target detection from feature maps at different levels, which helps to handle targets of different sizes.
3. 锚框(Anchor Boxes):
YOLOv1:
uses predefined bounding boxes, but does not use the concept of anchor boxes.
YOLOv3:
Introduce anchor boxes to allow the model to learn features of different target shapes. Feature maps at each scale use different numbers and sizes of anchor boxes.
4. Number of categories and number of output channels:
YOLOv1:
is trained on 20 categories.
YOLOv3:
is usually trained on larger data sets and supports more categories.
5. Performance:
YOLOv1:
is relatively slow and has slightly lower performance.
YOLOv3:
Achieves higher detection accuracy and better generalization performance through improvements in network structure and the use of multi-scale prediction.
6. Technology innovation:
YOLOv1:
The first end-to-end real-time object detection system.
YOLOv3:
introduces multi-scale prediction, anchor box and other technologies to improve detection performance.
Overall, YOLOv3 has significant improvements in network structure, performance and functions, especially the introduction of multi-scale prediction, anchor box and other mechanisms, making it more suitable for target detection tasks of different sizes and shapes.
What are the solutions to overfitting besides regularization?
Overfitting refers to the phenomenon that a machine learning model performs too well on the training set but performs poorly on unseen data. This is usually due to the model overlearning the noise and sample-specific details in the training data, and losing the ability to generalize to the overall data distribution. In addition to regularization, several solutions exist for mitigating overfitting.
A common approach isdata augmentation, by randomly transforming the training data to generate new training samples, thereby expanding the training set. This helps the model learn more invariants and improve generalization capabilities.Stop earlyis another simple yet effective strategy that prevents overfitting by monitoring validation set performance and stopping training after model performance reaches its peak.Ensemble learningImprove performance by combining predictions from multiple models and reduce the risk of overfitting from a single model.DropoutIt is a method of randomly disabling some units in a neural network during training, helping to prevent the model from over-relying on certain features.
Other strategies includeweight decay, regularize the model parameters by adding the sum of squares or the sum of absolute values of the weights in the loss function;Model simplification, that is, choose a simpler model structure;Feature selection, by selecting a more representative feature set; andcross validationVerify that the model performance is evaluated by dividing the training set and validation set multiple times. These methods can be used individually or in combination, with the choice depending on the nature of the problem and the characteristics of the data. In practice, by comprehensively considering multiple methods, the best strategy to alleviate overfitting can be found, thereby improving the generalization ability of the model.
How to improve small goals
Solving the problem of small target detection is an important challenge in the field of target detection, because small targets are usually easily ignored due to small size, sparse pixels and other reasons. In order to improve the accuracy of small targets, researchers have proposed a series of improvement methods. first,The introduction of image pyramid and feature pyramidThis enables the model to detect at different scales, thereby capturing the target more comprehensively. By adding high-resolution feature learning to the network, it helps the network better capture the detailed information of small targets. in addition,Adjust the size of the anchor box, making it more suitable for small targets, is a common strategy.A smaller IoU threshold is used in the IoU suppression phase, it is easier to retain the detection frames of multiple small targets.Enhancement of regularization techniques, such as dropout or weight decay, helps prevent the network from overfitting large targets in the training data, allowing it to better adapt to small targets.Data augmentation strategy, such as random scaling, cropping and rotation, help the model better understand the changes of small targets in different scenarios. Transfer learning and the use of soft labels are also effective means to improve small target detection performance. The combination and adjustment of these methods is often the key to achieving more accurate small target detection, and needs to be considered comprehensively based on the characteristics of specific problems and data sets. By continuously improving and tuning these methods, the model's detection accuracy and generalization ability for small targets can be effectively improved.