0. Summary
Semantic segmentation requires rich spatial information and a large receptive field. However, modern methods often sacrifice spatial resolution for real-time inference speed, resulting in performance degradation. This paper proposes a new bilateral segmentation network (BiSeNet) to solve this problem. We first design a spatial path with small step size to preserve spatial information and generate high-resolution features. At the same time, the context path using a fast downsampling strategy is used to obtain sufficient receptive fields. On top of the two paths, we introduce a new feature fusion module to combine features efficiently. The proposed architecture achieves an appropriate balance between speed and segmentation performance on Cityscapes, CamVid and COCO-Stuff datasets. Specifically, for an input of 2048×1024, we achieve a speed of 105 FPS on an NVIDIA Titan XP card and an average IOU of 68.4% on the Cityscapes test dataset, which is much faster than existing methods with similar performance. .
Keywords: real-time semantic segmentation·bilateral segmentation network
1 Introduction
The study of semantic segmentation is one of the fundamental tasks in computer vision, which involves assigning a semantic label to each pixel. It can be widely used in fields such as augmented reality devices, autonomous driving and video surveillance. These applications require fast interactions or responses with efficient inference speeds.
Recently, real-time semantic segmentation algorithms [1, 17, 25, 39] have demonstrated three main ways to speed up the model.
1) [34,39] try to limit the input size by cropping or resizing to reduce computational complexity. Although this method is simple and effective, the loss of spatial details destroys prediction results, especially around boundaries, resulting in reduced accuracy of metrics and visualizations.
2) Some works do not resize the input image, but crop the channels in the network to improve inference speed [1, 8, 25], especially in the early stages of the base model. However, this reduces spatial capabilities.
3) For the last case, ENet [25] proposes to discard the last stage of the model in pursuit of an extremely compact framework. However, the shortcomings of this method are obvious: since ENet gives up the downsampling operation in the last stage, the receptive field of the model is not enough to cover large objects, resulting in poor discrimination ability. In general, all the above methods make a compromise between accuracy and speed, and are actually less effective. An illustration is given in Figure 1(a).
In order to solve the above problem of spatial detail loss, researchers widely use U-shaped structures [1, 25, 35]. By fusing the hierarchical features of the backbone network, the U-shaped structure gradually increases the spatial resolution and fills in some missing details. However, this technique has two drawbacks.
1) A complete U-shaped structure will slow down the model by introducing additional calculations on high-resolution feature maps.
2) More importantly, most of the spatial information lost in cropping or resizing cannot be easily recovered by involving shallow layers, as shown in Figure 1(b). In other words, U-shaped technology is more suited as a mitigation measure than a necessary solution. Based on the above observations, we propose a bilateral segmentation network (BiSeNet), which consists of two parts: spatial path (SP) and contextual path (CP). As their names suggest, these two components are designed to cope with the loss of spatial information and the reduction of the receptive field, respectively. The design philosophy of these two paths is clear. For spatial paths, we only stack three convolutional layers to obtain 1/8 feature maps, preserving rich spatial details. For the context path, we add a global average pooling layer at the tail of Xception [8], where the receptive field is the maximum value of the backbone network. Figure 1(c) shows the structure of these two components.
In order to pursue better accuracy without losing speed, we also studied the fusion of the two paths and the refinement of the final prediction, and proposed the Feature Fusion Module (FFM) and the Attention Refinement Module (ARM). As our next experiments show, these two additional components can further improve the overall semantic segmentation accuracy on the Cityscapes [9], CamVid [2] and COCO-Stuff [3] benchmarks. Our main contributions are summarized as follows: - We propose a novel approach that decomposes the functions provided by spatial information preservation and receptive fields into two paths. Specifically, we propose a bilateral segmentation network (BiSeNet), which includes a spatial path (SP) and a contextual path (CP). - We designed two specific modules, namely Feature Fusion Module (FFM) and Attention Refinement Module (ARM), to further improve accuracy at an acceptable cost. - We achieved impressive results on Cityscapes, CamVid and COCO-Stuff benchmarks. Specifically, we achieved 68.4% accuracy on the Cityscapes test dataset at 105 FPS.
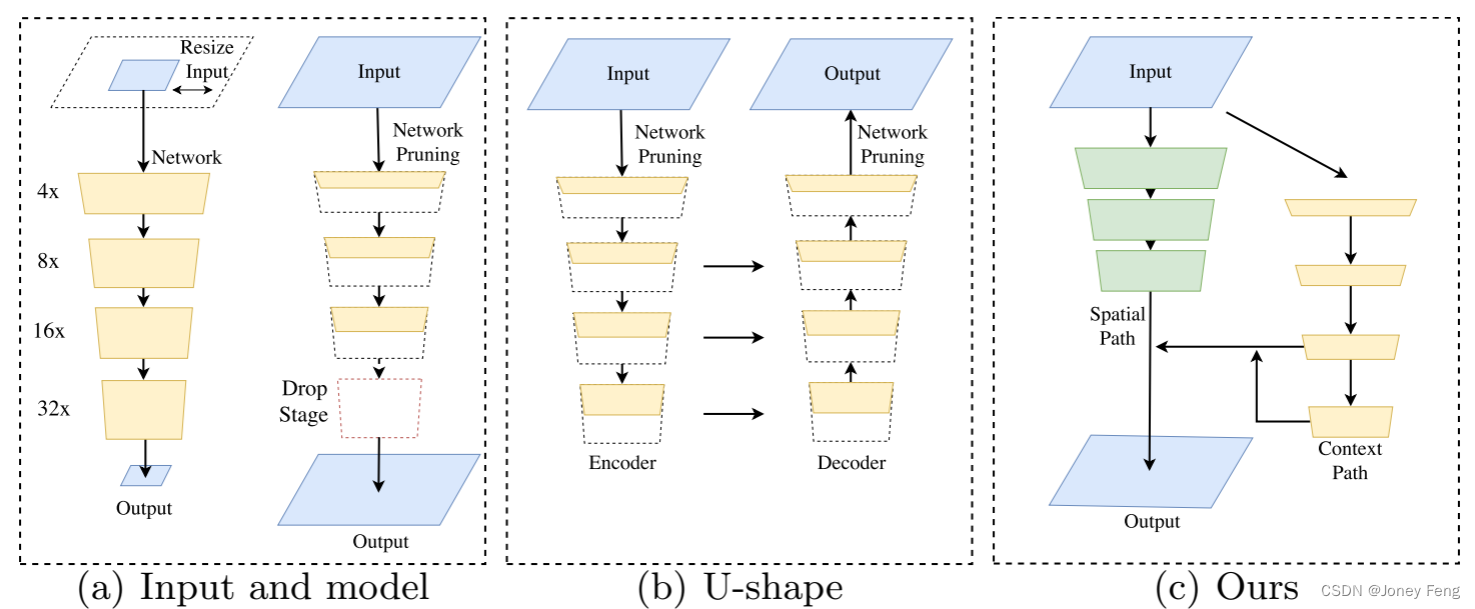 Figure 1. Schematic diagram of the acceleration architecture and our proposed approach.
Figure 1. Schematic diagram of the acceleration architecture and our proposed approach.
(a) shows the case of cropping or resizing operations on the input image and implementing lightweight models through cropping channels or deletion stages.
(b) represents the U-shaped structure.
(c) Demonstrates our proposed bilateral segmentation network (BiSeNet). Black dashed lines represent operations that destroy spatial information, while red dashed lines represent operations that shrink the receptive field. The green block is our proposed spatial path (SP).
In the network part, each block represents a feature map of different downsampling sizes. The length of the block represents the spatial resolution, while the thickness represents the number of channels.
2.Related work
Recently, many methods based on FCN [22] have achieved state-of-the-art performance on different benchmarks on semantic segmentation tasks. Most of these methods aim to encode more spatial information or expand the receptive field. Spatial information: Convolutional neural networks (CNN) [16] encode high-level semantic information through continuous down-sampling operations. However, in semantic segmentation tasks, the spatial information of images is crucial to predict detailed output. Modern existing methods strive to encode rich spatial information. DUC [32], PSPNet [40], DeepLab v2 [5] and Deeplab v3 [6] use dilated convolutions to preserve the spatial size of feature maps. Global convolutional networks [26] utilize “large convolutional kernels” to expand the receptive field.
U-shaped structure method: U-shaped structure [1,10,22,24,27] can restore a certain degree of spatial information. The original FCN [22] network encodes different levels of features through a skip connection network structure. Some methods introduce their specific refinement structures into U-shaped network structures. [1,24] use deconvolution layers to create a U-shaped network structure. U-net [27] introduces a useful skip connection network structure. Global convolutional networks [26] combine U-shaped structures with “large convolution kernels”. LRR [10] adopts Laplacian pyramid to reconstruct the network. RefineNet [18] adds a multi-path refinement structure to refine predictions. DFN [36] designs a channel attention block to implement feature selection. However, in U-shaped structures, some lost spatial information cannot be easily recovered.
Contextual information: Semantic segmentation requires contextual information to generate high-quality results. Most common methods expand the receptive field or incorporate different contextual information. [5, 6, 32, 37] adopt different dilation rates in convolutional layers to capture diverse contextual information. Driven by the image pyramid, multi-scale feature sets are always applied in semantic segmentation network structures. In [5], an “ASPP” module is proposed to capture contextual information of different receptive fields. PSPNet [40] applies a “PSP” module containing several average pooling layers at different scales. [6] designed an “ASPP” module with global average pooling to capture the global context of images. [38] improved the neural network through a scale-adaptive convolutional layer to obtain adaptive field context information. DFN [36] adds global pooling on top of the U-shaped structure to encode global context.
Attention mechanism: The attention mechanism can utilize high-level information to guide the forward network [23,31]. In [7], the attention of CNN depends on the scale of the input image. In [13], they applied channel attention to recognition tasks and achieved state-of-the-art results. Similar to DFN [36], they learn global context as attention and revise features.
Real-time segmentation: Real-time semantic segmentation algorithms require a way to quickly generate high-quality predictions. SegNet [1] utilizes small network structures and skip connection methods to achieve fast speeds. E-Net [25] designs a lightweight network from scratch and provides extremely high speeds. ICNet [39] uses image concatenation to accelerate semantic segmentation methods. [17] adopted a cascade network structure to reduce the calculation amount of "easy areas". [34] designed a novel dual-column network with spatial sparsity to reduce computational cost. The difference is that our proposed method adopts a lightweight model to provide sufficient receptive fields. Furthermore, we set up a shallow but wide network to capture sufficient spatial information.
3. Bilateral segmentation of the network
In this section, we first introduce our proposed Bilateral Segmentation Network (BiSeNet) with spatial path and contextual path in detail. Furthermore, we illustrate the effectiveness of these two paths separately. Finally, we demonstrate how to combine the features of these two paths using the feature fusion module and present the overall architecture of our BiSeNet.

Figure 2. Overview of the bilateral segmentation network.
(a) Network architecture. The length of the block indicates the size of the space, while the thickness indicates the number of channels.
(b) Components of the Attention Refinement Module (ARM).
(c) Components of the feature fusion module (FFM). The read line indicates that the process is only performed during testing.
3.1. Spatial path
In the semantic segmentation task, some existing methods [5, 6, 32, 40] try to preserve the resolution of the input image through dilated convolution to encode sufficient spatial information, while a few methods [5, 6, 26, 40 ] then try to use the pyramid pooling module, empty space pyramid pooling or "big kernel" to capture enough receptive fields. These methods show that spatial information and receptive fields are critical to achieve high accuracy. However, satisfying both requirements simultaneously is difficult. Especially in the case of real-time semantic segmentation, existing modern methods [1, 25, 39] exploit small input images or lightweight base models for acceleration. The size of small input images causes most of the spatial information to be lost, while lightweight models destroy spatial information through channel pruning.
Based on this observation, we propose a spatial path to preserve the spatial dimensions of the original input image and encode rich spatial information. The spatial path consists of three layers. Each layer consists of a convolution with stride 2, followed by batch normalization [15] and ReLU [11]. Therefore, the output feature map extracted by this path is 1/8 of the original image. Due to the large spatial size of the feature map, it encodes rich spatial information. Figure 2(a) shows the details of the structure.
3.2.Context path
While spatial paths encode rich spatial information, contextual paths aim to provide sufficient receptive fields. In semantic segmentation tasks, receptive fields are very important for performance. To expand the receptive field, some methods take advantage of pyramid pooling modules [40], empty space pyramid pooling [5, 6] or “big kernels” [26]. However, these operations are computationally demanding and memory intensive, resulting in slow speeds. Considering both large receptive field and efficient computation, we propose context path. Context paths utilize lightweight models and global average pooling [5, 6, 21] to provide large receptive fields. In this work, a lightweight model like Xception [8] can quickly downsample feature maps to obtain large receptive fields, thereby encoding high-level semantic context information. Then, we add global average pooling at the tail of the lightweight model, which can provide the largest receptive field with global contextual information. Finally, we combine the upsampled output features of global pooling with the features of the lightweight model. In the lightweight model, we adopt a U-shaped structure [1, 25, 35] to fuse the features of the last two stages, which is an incomplete U-shaped pattern. Figure 2(c) shows the overall view of the context path.
Attention refinement module: In the context path, we propose a specific attention refinement module (ARM) to optimize features at each stage. As shown in Figure 2(b), ARM adopts global average pooling to capture global context and calculates an attention vector to guide feature learning. This design optimizes the output features of each stage in the context path. It can easily integrate global context information without any upsampling operations. Therefore, its computational cost is negligible.
3.3.Network architecture
Through spatial path and contextual path, we propose BiSeNet for real-time semantic segmentation, as shown in Figure 2(a). We use a pre-trained Xception model as the backbone of the context path and three convolutional layers with strides as the spatial path. Then, we fuse the output features of these two paths to make the final prediction. It achieves both real-time performance and high accuracy. First, we focus on the practical computational aspects. Although the spatial path has a larger spatial size, it has only three convolutional layers. Therefore, it is computationally inexpensive. As for context paths, we use lightweight models for fast downsampling. In addition, the two paths are calculated simultaneously, greatly improving efficiency. Second, we discuss the accuracy aspects of this network. In our paper, spatial paths encode rich spatial information, while contextual paths provide large receptive fields. They complement each other for higher performance.
Feature fusion module: The features of the two paths are different in the level of feature expression. Therefore, we cannot simply add these features together. The spatial information captured by spatial paths mainly encodes rich detailed information. In addition, the output features of the context path mainly encode contextual information. In other words, the output features of the spatial path are low-level, while the output features of the contextual path are high-level. Therefore, we propose a specific feature fusion module to fuse these features. Given the different levels of features, we first concatenate the output features of spatial paths and contextual paths. Then, we leverage batch normalization [15] to balance the scales of the features. Next, we pool the connected features into a feature vector and calculate a weight vector, similar to SENet [13]. This weight vector can reweight features, which is equivalent to feature selection and combination. Figure 2(c) shows the details of this design.
Loss function: In this paper, we also utilize an auxiliary loss function to supervise the training of our proposed method. We use the main loss function to supervise the output of the entire BiSeNet. Furthermore, we add two specific auxiliary loss functions to supervise the output of the context path, similar to deep supervision [35]. All loss functions are softmax losses, as shown in Equation 1. Furthermore, we use parameter α to balance the weights of primary loss and auxiliary loss, as shown in Equation 2. In our paper, α is equal to 1. The joint loss makes it easier for the optimizer to optimize the model.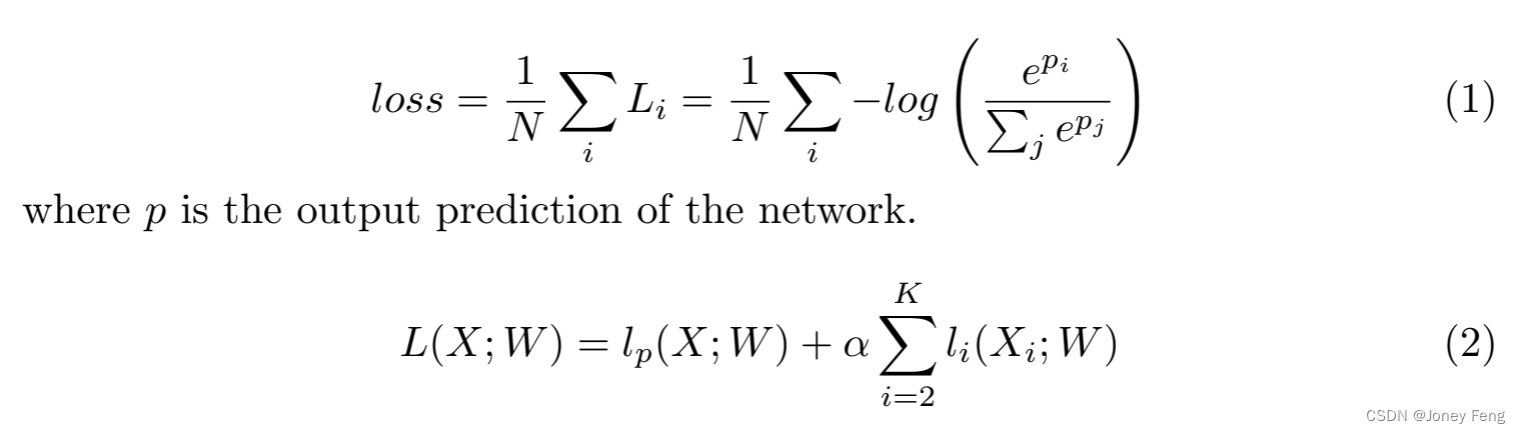
Where, l_p is the main loss of the connection output. Xi is the output feature of the i-th stage of the Xception model. li is the auxiliary loss in the i-th stage. In our paper, K equals 3. L is the joint loss function. Here, we only use the auxiliary loss during the training phase.
4.Experimental results
We use the modified Xception model [8], Xception39, for real-time semantic segmentation tasks. Our implementation code will be released publicly. We evaluate our proposed BiSeNet on the Cityscapes [9], CamVid [2] and COCO Stuff [3] benchmark datasets. The dataset and implementation protocol are first introduced. Next, we describe in detail our speed strategy compared to other methods. We then study the effect of each component of our proposed method. We evaluate all performance results on the Cityscapes validation set. Finally, we report accuracy and speed results on the Cityscapes, CamVid, and COCO-Stuff datasets compared to other real-time semantic segmentation algorithms.
Cityscapes: Cityscapes [9] is a large-scale urban street view dataset taken from a car perspective. It contains 2,975 finely annotated images for training and another 500 images for validation. In our experiments, we only used fine datasets. In testing, it provided 1,525 images without ground truth for a fair comparison. The images all have a resolution of 2,048×1,024, and each pixel is annotated into 19 predefined categories. CamVid: CamVid [2] is another street view dataset from the perspective of driving a car. It contains a total of 701 images, of which 367 are used for training, 101 for validation, and 233 for testing. The images have a resolution of 960×720 and have 11 semantic categories. COCO-Stuff: COCO-Stuff [3] augments the popular COCO [20] dataset with all 164,000 images, 118,000 for training, 5,000 for validation, 20,000 for test-dev, and 20,000 for on test-challenge. It covers 91 item categories and 1 "unlabeled" category.
4.1. Implement the protocol
In this section, we elaborate on our implementation protocol. Network: We apply three convolutions to the Spatial Path and the Context Path of the Xception39 model. We then use the Feature Fusion module to combine the features of these two paths to predict the final result. The output resolution of Spatial Path and final prediction is 1/8 of the original image.
Training details: We use mini-batch stochastic gradient descent (SGD) [16] with a batch size of 16, a momentum of 0.9, and a weight decay of 1e-4 in training. Similar to [5, 6, 21], we adopt a "poly" learning rate strategy, where the initial rate is multiplied by the power of (1 - max iter iter) with each iteration raised to the power of 0.9. The initial learning rate is 2.5e-2. Data augmentation: We augment the dataset by performing mean subtraction, random horizontal flipping, and random scaling on the input images during training. Scaling includes {0.75, 1.0, 1.5, 1.75, 2.0}. Finally, we randomly crop the images to a fixed size for training.
4.2.Ablation experiment
In this subsection, we study the impact of each component in our proposed BiSeNet step by step in detail. In the following experiments, we use Xception39 as the base network and evaluate our method on the Cityscapes validation dataset [9]. Baseline model: We use the Xception39 network pretrained on the ImageNet dataset [28] as the backbone of Context Path, and directly upsample the output of the network as the original input image, similar to FCN [22]. We take the performance of the base model as our baseline, as shown in Table 1.
Ablation experiment of U-shape component: We propose Context Path to provide sufficient receptive field. We use the lightweight model Xception39 as the backbone of Context Path for fast downsampling. At the same time, we use U-shape structure [1, 25, 35] to combine the features of the last two stages in the Xception39 network, called U-shape-8s, instead of the standard U-shape structure, called U-shape -4s. The numbers represent the downsampling factors of the output features, as shown in Figure 2. There are two reasons for using U-shape-8s structure. First, the U-shape structure can recover a certain degree of spatial information and spatial size. Secondly, compared with U-shape-4s, U-shape-8s structure is faster, as shown in Table 2. Therefore, we use U-shape-8s structure, which improves the performance from 60.79% to 66.01%, as shown in Table 2. Ablation experiments of spatial path components: As mentioned in Section 1, existing modern methods for real-time semantic segmentation tasks face the challenge of spatial information loss. Therefore, we propose spatial paths to preserve spatial size and capture rich spatial information. The spatial path consists of three convolutions with stride 2, followed by batch normalization [15] and ReLU [11]. This improves the performance from 66.01% to 67.42%, as shown in Table 3. Spatial paths encode rich spatial information details. Figure 3 shows that BiSeNet can obtain more detailed spatial information, such as some traffic signs.
Ablation experiment of attention refinement module: In order to further improve performance, we specially designed an attention refinement module (ARM). This module contains global average pooling to encode the output features into vectors. Then, we utilize convolution, batch normalization [15] and ReLU units [11] to calculate the attention vector. The original features will be reweighted by attention vectors. For raw features, it can easily capture global contextual information without complex upsampling operations. The effect of ARM is shown in Table 3.
Ablation experiment of feature fusion module: Based on spatial path and Context Path, we need to fuse the output features of these two paths. Considering the different levels of features, the features of the spatial path belong to the low level and the features of the Context Path belong to the high level, so we propose a feature fusion module to effectively combine these features. First, we evaluate the effect of the simple summation of these features and our proposed feature fusion module, as shown in Table 3. The gap in comparative performance explains that the characteristics of the two paths belong to different levels. Ablation experiment of global average pooling: We expect that Context Path can provide sufficient receptive field. Although the original Xception39 model can theoretically cover most areas of the input image, we still use global average pooling [21] to further expand the receptive field. This ensures that the effective receptive field is large enough. In this article, we add global average pooling at the end of the Xception39 model. We then upsample the output of global average pooling and add it with the output of the last stage in the Xception39 model, similar to DFN [36]. This improves the performance from 67.42% to 68.42%, demonstrating the effectiveness of this design, as shown in Table 3.
Table 1. Accuracy and parameter analysis of our baseline models Xception39 and Res18 on the Cityscapes validation dataset. Here we use FCN-32s as the basic structure. FLOPS is estimated for an input of 3×640×360.
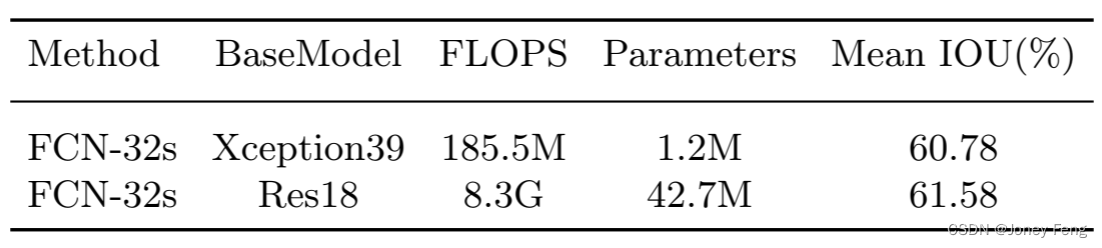
Table 2. Speed analysis of U-shape-8s and U-shape-4s on an NVIDIA Titan XP card. Image size is W×H.

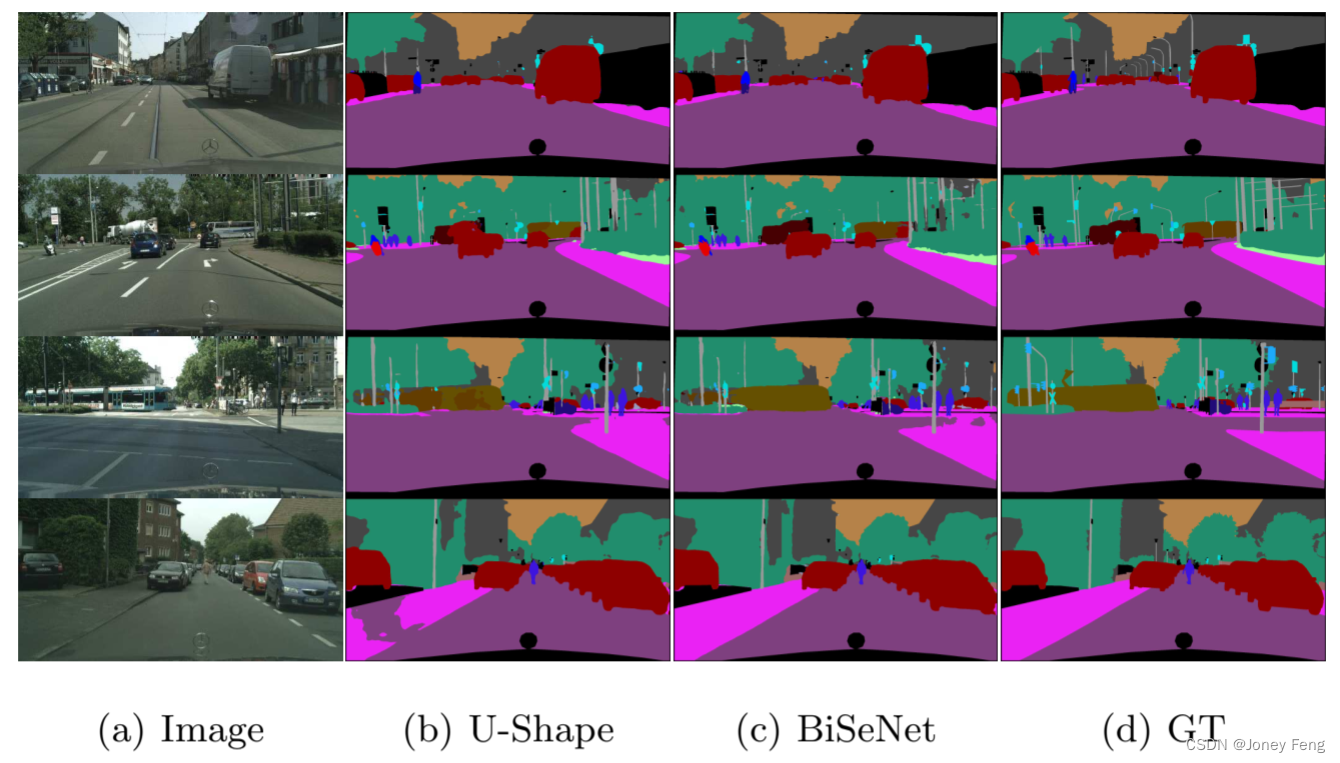
Figure 3. Sample output results before and after adding the spatial path. The output of BiSeNet has more detailed information than the output of U-shape.
Table 3. Detailed performance comparison of each component in our proposed BiSeNet. CP: Context Path; SP: Spatial Path; GP: Global Average Pooling; ARM: Attention Refinement Module; FFM: Feature Fusion Module.

Table 4. Accuracy and parameter analysis of our baseline models Xception39 and Res18 on the Cityscapes validation dataset. Here we use FCN-32s as the basic structure. FLOPS is estimated for an input of 3×640×360.
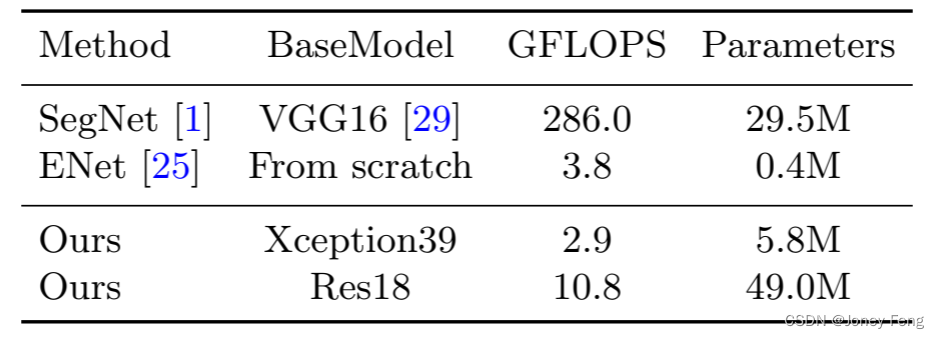
Table 5. Speed comparison of our method with other state-of-the-art methods. Image size is W×H. Ours1 and Ours2 are BiSeNet based on Xception39 and Res18 models.
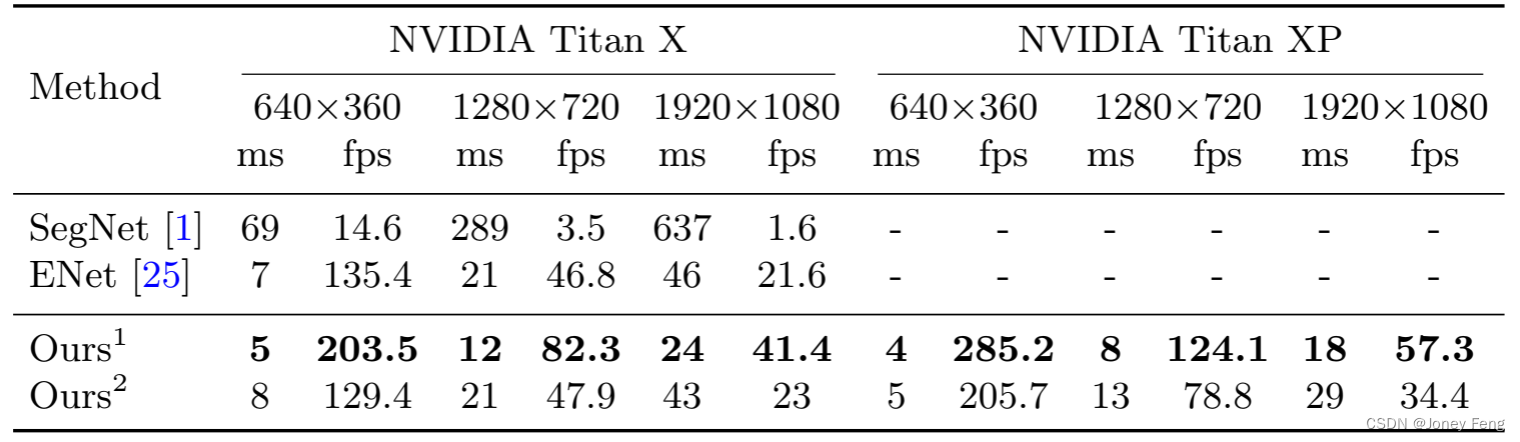
Table 6. Accuracy and speed comparison of our method with other state-of-the-art methods on the Cityscapes test dataset. We train and evaluate on NVIDIA Titan XP with 2048×1024 resolution input. "-" indicates that the method did not give corresponding accuracy speed results.
4.3. Speed and accuracy analysis
In this section, we first analyze the speed of our algorithm. We then report our final results with other algorithms on the Cityscapes [9], CamVid [2] and COCO-Stuff [3] benchmarks.
Speed analysis: Speed is an important factor in algorithms, especially when we apply it in practice. We conduct experiments under different settings to make a thorough comparison. First, we show our FLOPS and parameter states in Table 4. FLOPS and parameters represent the number of operations required to process an image of this resolution. For fair comparison, we chose 640×360 as the resolution of the input image. Meanwhile, Table 5 presents the speed comparison between our method and other methods on input images of different resolutions and different hardware benchmarks. Finally, we report our speed and corresponding accuracy results on the Cityscapes test dataset. From Table 6, we can find that our method achieves significant progress in both speed and accuracy. During the evaluation, we first scale the input image with 2048×1024 resolution to 1536×768 resolution to test the speed and accuracy. At the same time, we calculate the loss function using the online bootstrap ping strategy described in [33]. In this process, we did not employ any testing techniques such as multi-scale or multi-crop testing.
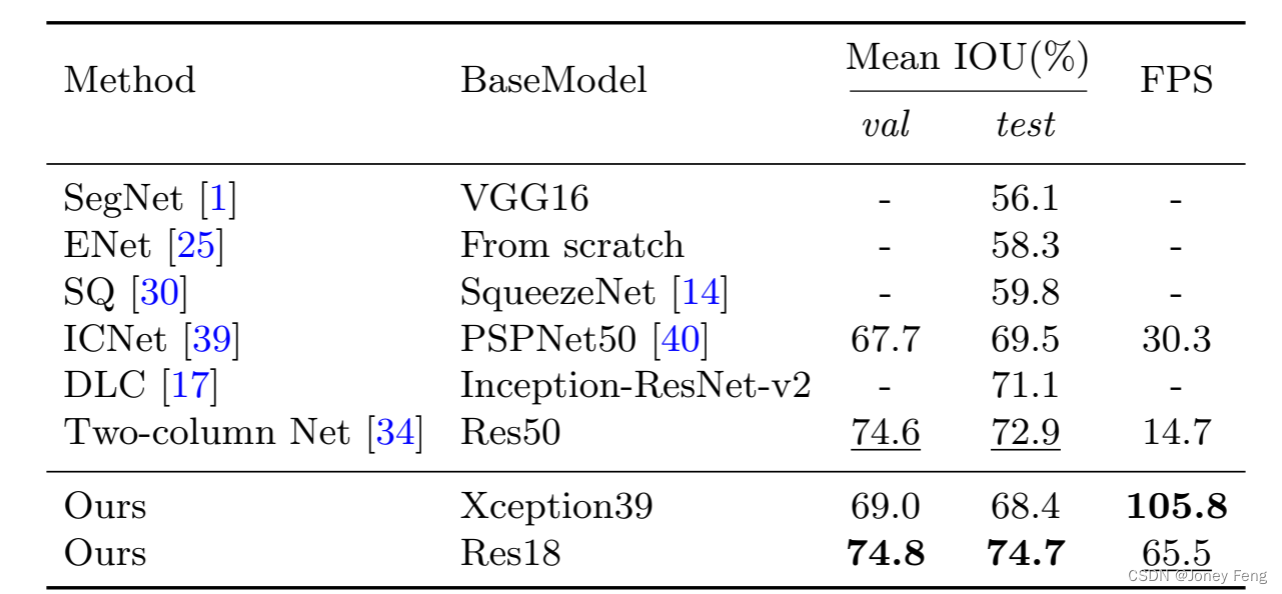
Accuracy analysis: In fact, our BiSeNet can also achieve higher accuracy results on other non-real-time semantic segmentation algorithms. Here we present accuracy results on the Cityscapes [9], CamVid [2] and COCO-Stuff [3] benchmarks. At the same time, to ensure the effectiveness of our method, we also apply it to different base models, such as standard ResNet18 and ResNet101 [12]. Next, we'll elaborate on some training details. Cityscapes: As shown in Table 7, our method also achieves impressive results on different models. To improve accuracy, we randomly select 1024×1024 crops as input. Figure 4 shows some visual examples of our results. CamVid: Table 8 shows the statistical accuracy results on the CamVid dataset. For testing, we train our model using the training and validation datasets. Here, we use a resolution of 960×720 for training and evaluation. COCO-Stuff: We also report our accuracy results on the COCO-Stuff validation dataset in Table 9. During training and validation, we crop the input to 640×640 resolution. For fair comparison, we did not use multi-scale testing.
 Figure 4: Example results of BiSeNet based on Xception39, Res18 and Res101 models on the Cityscapes dataset.
Figure 4: Example results of BiSeNet based on Xception39, Res18 and Res101 models on the Cityscapes dataset.
Table 7: Accuracy comparison of our method with other state-of-the-art methods on the Cityscapes test dataset. "-"Indicates that the method does not give corresponding results.
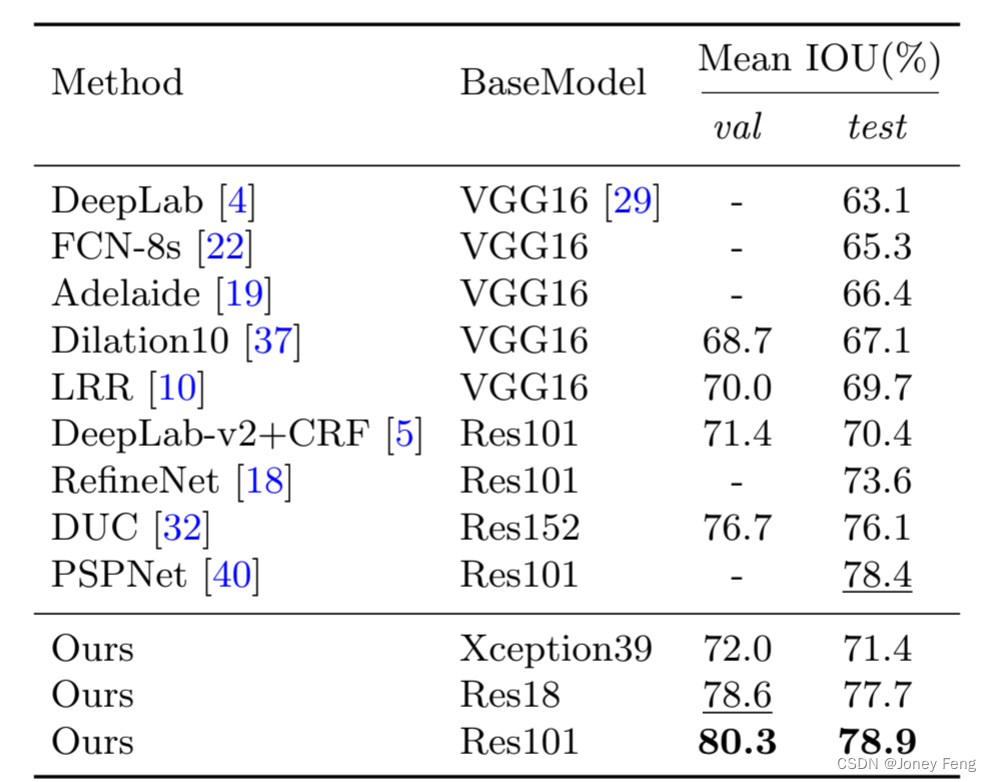 Table 8: Accuracy results on CamVid test dataset. Ours1 and Ours2 represent models based on Xception39 and Res18 networks.
Table 8: Accuracy results on CamVid test dataset. Ours1 and Ours2 represent models based on Xception39 and Res18 networks. 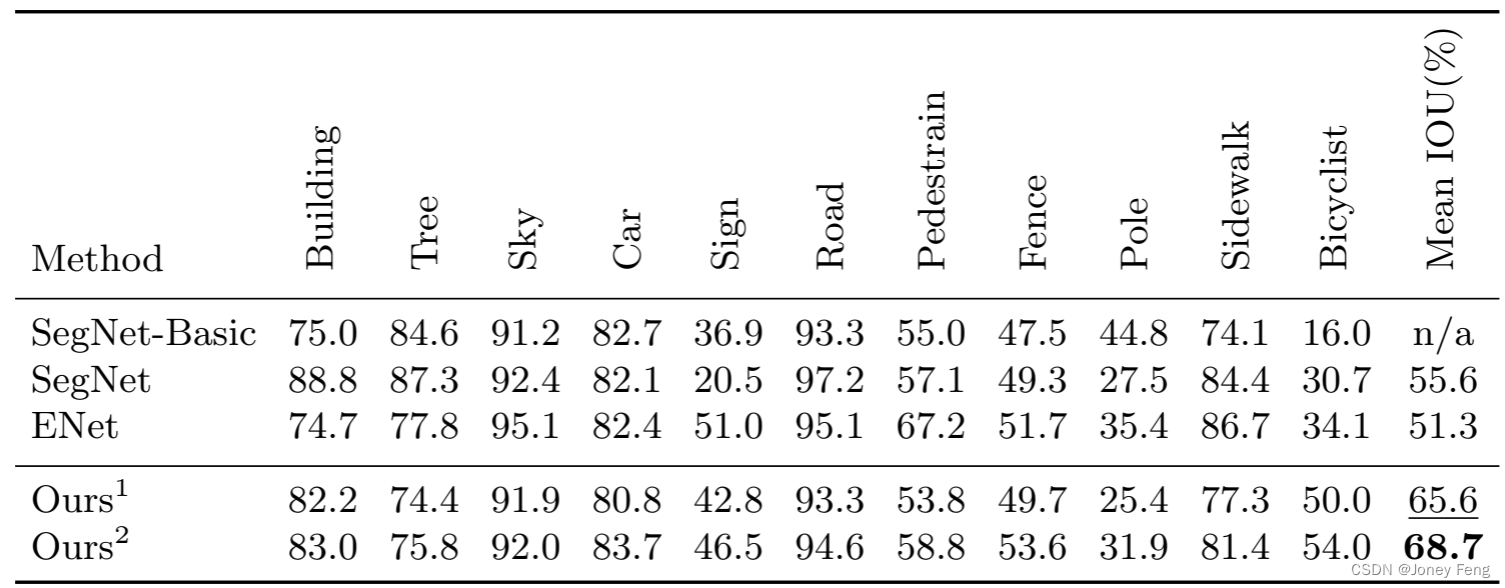 Table 9: Accuracy results on the COCO-Stuff validation data set.
Table 9: Accuracy results on the COCO-Stuff validation data set. 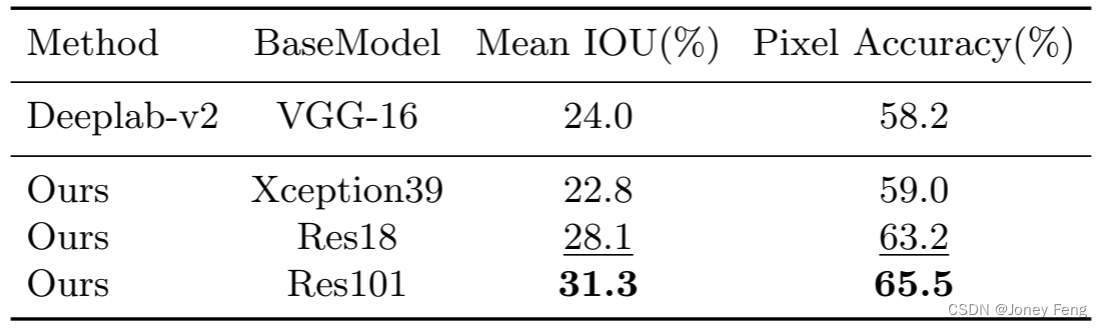
5 Conclusion
This paper proposes Bilateral Segmentation Network (BiSeNet), which aims to simultaneously improve the speed and accuracy of real-time semantic segmentation. Our proposed BiSeNet contains two paths: spatial path (SP) and contextual path (CP). Spatial paths aim to preserve the spatial information of the original image. The context path uses lightweight models and global average pooling [6, 21, 40] to quickly obtain considerable receptive fields. With detailed spatial information and large receptive fields, we achieve an average IOU result of 68.4% on the Cityscapes [9] test dataset at 105 FPS.
references
Badrinarayanan, V., Kendall, A., Cipolla, R.: SegNet: a deep convolutional encoder-decoder architecture for image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence 39(12), 2481-2495 (2017) 2, 4, 5, 6, 9, 11, 12
Brostow, G.J., Shotton, J., Fauqueur, J., Cipolla, R.: Segmentation and recognition using the structure of moving point clouds. European Conference on Computer Vision pp.44-57 (2008) 3,7,8,12
Caesar, H., Uijlings, J., Ferrari, V.: Coco-stuff: Item and material categories in context. In: IEEE Conference on Computer Vision and Pattern Recognition (2018) 3, 7, 8, 12
Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Semantic image segmentation using deep convolutional networks and fully connected CRFs. ICLR(2015)13
Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Semantic image segmentation using deep convolutional networks, atrous convolutions, and fully connected CRFs. arXiv(2016)3,4,5,6,8,13
Chen, L.C., Papandreou, G., Schroff, F., Adam, H.: Rethinking atrous convolutions for semantic image segmentation. arXiv(2017)3,4,5,6,8,14
Chen, L.C., Yang, Y., Wang, J., Xu, W., Yuille, A.L.: Attention to scale: scale-aware semantic image segmentation. In: IEEE Conference on Computer Vision and Pattern Recognition (2016) 4
Chollet, F.: Xception: deep learning using depthwise separable convolutions. IEEE Conference on Computer Vision and Pattern Recognition (2017) 2, 3, 6, 7
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: For semantic urban scenarios Understanding the Cityscapes dataset. In: IEEE Conference on Computer Vision and Pattern Recognition (2016) 3, 7, 8, 12, 14
Ghiasi, G., Fowlkes, C.C.: Laplacian pyramid reconstruction and refined semantic segmentation. In: European Conference on Computer Vision (2016) 4,13
Glorot, X., Bordes, A., Bengio, Y.: Deep sparse rectifier neural networks. In: International conference on artificial intelligence and statistics. PP.315-323(2011)5,9,10
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: IEEE Conference on Computer Vision and Pattern Recognition (2016) 12
Hu, J., Shen, L., Sun, G.: Squeeze and incentive networks. arXiv (2017) 4,7
Iandola, F.N., Moskewicz, M.W., Ashraf, K., Han, S., Dally, W.J., Keutzer, K.: Squeezenet: with 50 times fewer parameters and¡ Alexnet-level accuracy at 1mb model size. arXiv abs/1602.07360 (2016) 12
Ioffe, S., Szegedy, C.: Batch normalization: accelerating deep network training by reducing internal covariate shifts. In: International conference on machine learning. PP.448-456(2015)5,7,9,10
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification using deep convolutional neural networks. In: Neural Information Processing Systems (2012) 3,8
Li, X., Liu, Z., Luo, P., Loy, C.C., Tang, X.: Not all pixels are equal: difficulty-aware semantic segmentation via deep cascades. IEEE Conference on Computer Vision and Pattern Recognition (2017) 2, 4, 12