Problem Description
There are m identical machines and n workpieces. Each workpiece has 1 process. Each workpiece can be assigned a machine for processing according to any process.
| artifact | A | B | C | D | AND | F | G | H | I |
|---|---|---|---|---|---|---|---|---|---|
| Workpiece number | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Processing time | 4 | 7 | 6 | 5 | 8 | 3 | 5 | 5 | 10 |
| Time of arrival | 3 | 2 | 4 | 5 | 3 | 2 | 1 | 8 | 6 |
| Delivery time | 10 | 15 | 30 | 24 | 14 | 13 | 20 | 18 | 10 |
Number of devices: 3
objective function
Minimize total delivery delay time
Coding instructions
The number of machines is m, the number starting from 0 is 0,1,...,m-1, and the number of workpieces is n, numbering also starts from 0.
defines two variables job_id and job. The former represents the processing sequence of the workpiece (not strictly the order of processing A first and then processing B. , each workpiece here is independent, and the entire ID is just to naturally select a processing sequence after redistributing the machine), the latter indicates which machine is used to process each workpiece.
For example, job_id=[4, 0, 5, 8, 1, 6, 2, 7, 3], job=[0, 1, 2, 2, 1, 0, 2, 1, 0] means "the workpiece numbered 4 is assigned to the machine numbered 0", "the workpiece numbered 0 "Assigned to the machine numbered 1", the order of workpiece processing on the machine numbered 0 is 4,6,3, and so on.
Note that the encoding of chromosomes in parallel machine scheduling problems is generally divided into machine selection part and The workpiece sorting part, the machine selection part, normally here should allocate machines to workpieces first, and then sort the machines assigned to each workpiece, but in my code, the workpieces are directly sorted first. Shuffle and then select the machine. At first glance, the final effect seems to be similar, but you will know when you look at the code. My code is to shufflejob_id After that, selection crossover mutation is directly performed on a group as a unit. That is, a job_id value corresponds to a population (rather than an individual, but in theory each individual should correspond to a different order), which may lead to time complexity when dealing with large-scale problems. The degree is too high (I’m really lazy here, but I’ve been reading the code for the past two days and it’s 5555, and it’s the original sin). A capable brother can kick me after he’s done with it.
For specific ideas, you can read this article:https://blog.csdn.net/qq_38361726/article/details/120669250
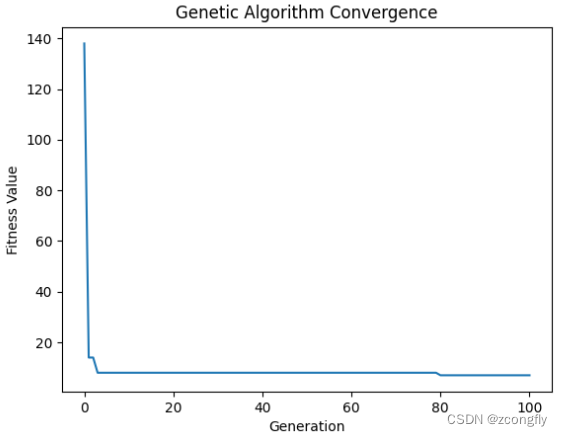
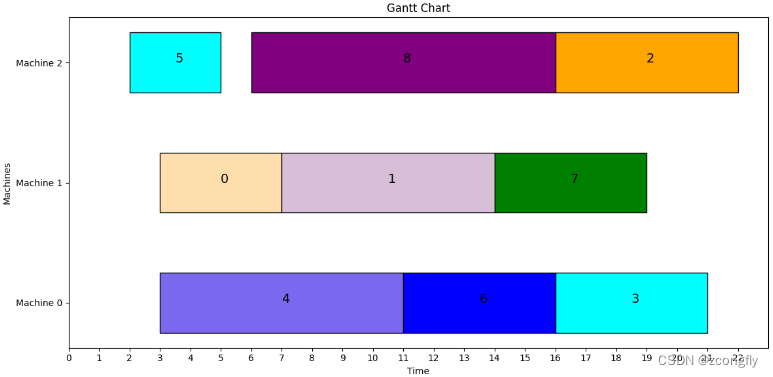
Operation result
最佳加工顺序: [4, 0, 5, 8, 1, 6, 2, 7, 3]
最佳调度分配: [0, 1, 2, 2, 1, 0, 2, 1, 0]
最小交货期延时时间: 7
python code
import random
import numpy as np
import matplotlib.pyplot as plt
import copy
# 定义遗传算法参数
POP_SIZE = 100 # 种群大小
MAX_GEN = 100 # 最大迭代次数
CROSSOVER_RATE = 0.7 # 交叉概率
MUTATION_RATE = 0.2 # 变异概率
def sort_by_id(id, sequence):
# 根据id对sequence进行排序
new_sequence = sequence[:]
for i in range(len(id)):
sequence[i] = new_sequence[id[i]]
# 随机生成初始种群,这里的每个个体表示第i个工件选择在第choose[i]台机器进行加工,工件和机器编码都是从0开始
def get_init_pop(pop_size):
pop = []
for _ in range(pop_size):
choose = []
for _ in range(len(job_id)):
choose.append(random.randint(0, machine_num - 1))
pop.append(list(choose))
return pop
# 计算染色体的适应度(makespan) 以最小化交货期延时为目标函数,这里计算的是交货期总延时时间
def fitness(job):
delay_times = [[] for _ in range(machine_num)] # 每个工件超过交货期的延时时间
finish_times = [[] for _ in range(machine_num)] # 每个工件完成加工的时间点
for i in range(len(job)):
if finish_times[job[i]]:
finish_times[job[i]].append(
pro_times[job_id[i]] + max(finish_times[job[i]][-1], arr_times[job_id[i]]))
else:
finish_times[job[i]].append(pro_times[job_id[i]] + arr_times[job_id[i]])
delay_times[job[i]].append(max(finish_times[job[i]][-1] - deadlines[job_id[i]], 0))
return sum(element for sublist in delay_times for element in sublist)
# 选择父代,这里选择POP_SIZE/2个作为父代
def selection(pop):
fitness_values = [1 / fitness(job) for job in pop] # 以最小化交货期总延时为目标函数,这里把最小化问题转变为最大化问题
total_fitness = sum(fitness_values)
prob = [fitness_value / total_fitness for fitness_value in fitness_values] # 轮盘赌,这里是每个适应度值被选中的概率
# 按概率分布prob从区间[0,len(pop))中随机抽取size个元素,不允许重复抽取,即轮盘赌选择
selected_indices = np.random.choice(len(pop), size=POP_SIZE // 2, p=prob, replace=False)
return [pop[i] for i in selected_indices]
# 交叉操作 这里是单点交叉
def crossover(job_p1, job_p2):
cross_point = random.randint(1, len(job_p1) - 1)
job_c1 = job_p1[:cross_point] + job_p2[cross_point:]
job_c2 = job_p2[:cross_point] + job_p1[cross_point:]
return job_c1, job_c2
# 变异操作
def mutation(job):
index = random.randint(0, len(job) - 1)
job[index] = random.randint(0, machine_num - 1) # 这样的话变异概率可以设置得大一点,因为实际的变异概率是MUTATION_RATE*(machine_num-1)/machine_num
return job
# 主遗传算法循环
# 以最小化延迟交货时间为目标函数
# TODO: 没有考虑各机器的负载均衡
def GA(is_shuffle): # 工件加工顺序是否为无序
best_id = job_id # 初始化job_id
best_job = [0, 0, 0, 0, 0, 0, 0, 0, 0] # 获得最佳个体
# "makespan" 是指完成整个生产作业或生产订单所需的总时间,通常以单位时间(例如小时或分钟)来衡量。
best_makespan = fitness(best_job) # 获得最佳个体的适应度值
# 创建一个空列表来存储每代的适应度值
fitness_history = [best_makespan]
pop = get_init_pop(POP_SIZE)
for _ in range(1, MAX_GEN + 1):
if is_shuffle:
random.shuffle(job_id)
pop = selection(pop) # 选择
new_population = []
while len(new_population) < POP_SIZE:
parent1, parent2 = random.sample(pop, 2) # 不重复抽样2个
if random.random() < CROSSOVER_RATE:
child1, child2 = crossover(parent1, parent2) # 交叉
new_population.extend([child1, child2])
else:
new_population.extend([parent1, parent2])
pop = [mutation(job) if random.random() < MUTATION_RATE else job for job in new_population]
best_gen_job = min(pop, key=lambda x: fitness(x))
best_gen_makespan = fitness(best_gen_job) # 每一次迭代获得最佳个体的适应度值
if best_gen_makespan < best_makespan: # 更新最小fitness值
best_makespan = best_gen_makespan
best_job = copy.deepcopy(best_gen_job) # TODO: 不用deepcopy的话不会迭代,但是这里应该有更好的方法
best_id = copy.deepcopy(job_id)
fitness_history.append(best_makespan) # 把本次迭代结果保存到fitness_history中(用于绘迭代曲线)
# 绘制迭代曲线图
plt.plot(range(MAX_GEN + 1), fitness_history)
plt.xlabel('Generation')
plt.ylabel('Fitness Value')
plt.title('Genetic Algorithm Convergence')
plt.show()
return best_id, best_job, best_makespan
def plot_gantt(job_id, job):
# 准备一系列颜色
colors = ['blue', 'yellow', 'orange', 'green', 'palegoldenrod', 'purple', 'pink', 'Thistle', 'Magenta', 'SlateBlue',
'RoyalBlue', 'Cyan', 'Aqua', 'floralwhite', 'ghostwhite', 'goldenrod', 'mediumslateblue', 'navajowhite',
'moccasin', 'white', 'navy', 'sandybrown', 'moccasin']
job_colors = random.sample(colors, len(job))
# 计算每个工件的开始时间和结束时间
start_time = [[] for _ in range(machine_num)]
end_time = [[] for _ in range(machine_num)]
id = [[] for _ in range(machine_num)]
job_color = [[] for _ in range(machine_num)]
for i in range(len(job)):
if start_time[job[i]]:
start_time[job[i]].append(max(end_time[job[i]][-1], arr_times[job_id[i]]))
end_time[job[i]].append(start_time[job[i]][-1] + pro_times[job_id[i]])
else:
start_time[job[i]].append(arr_times[job_id[i]])
end_time[job[i]].append(start_time[job[i]][-1] + pro_times[job_id[i]])
id[job[i]].append(job_id[i])
job_color[job[i]].append(job_colors[job_id[i]])
# 创建图表和子图
plt.figure(figsize=(12, 6))
# 绘制工序的甘特图
for i in range(len(start_time)):
for j in range(len(start_time[i])):
plt.barh(i, end_time[i][j] - start_time[i][j], height=0.5, left=start_time[i][j], color=job_color[i][j],
edgecolor='black')
plt.text(x=(start_time[i][j] + end_time[i][j]) / 2, y=i, s=id[i][j], fontsize=14)
# 设置纵坐标轴刻度为机器编号
machines = [f'Machine {
i}' for i in range(len(start_time))]
plt.yticks(range(len(machines)), machines)
# 设置横坐标轴刻度为时间
# start = min([min(row) for row in start_time])
start = 0
end = max([max(row) for row in end_time])
plt.xticks(range(start, end + 1))
plt.xlabel('Time')
# 图表样式设置
plt.ylabel('Machines')
plt.title('Gantt Chart')
# plt.grid(axis='x')
# 自动调整图表布局
plt.tight_layout()
# 显示图表
plt.show()
if __name__ == '__main__':
# 定义多机调度问题的工件和加工时间
job_id = [0, 1, 2, 3, 4, 5, 6, 7, 8] # 工件编号
pro_times = [4, 7, 6, 5, 8, 3, 5, 5, 10] # 加工时间
arr_times = [3, 2, 4, 5, 3, 2, 1, 8, 6] # 到达时间
deadlines = [10, 15, 30, 24, 14, 13, 20, 18, 10] # 交货期
machine_num = 3 # 3台完全相同的并行机,编号为0,1,2
job_id, best_job, best_makespan = GA(True)
print("最佳加工顺序:", job_id)
print("最佳调度分配:", best_job)
print("最小交货期延时时间:", best_makespan)
plot_gantt(job_id, best_job)