Article directory
1. What is NLP
The full name of NLP isNatuarl Language Processing, which means natural language processing in Chinese and is an important direction in the field of artificial intelligence
One of the greatest aspects of natural language processing (NLP) is the computational research that spans multiple fields, from artificial intelligence to computational linguistics, that study the interaction between computers and human language. It focuses on how computers can accurately and quickly process large natural language corpora. What is a natural language corpus? It is language learning expressed in real-world languages, a comprehensive approach to understanding a set of abstract rules from text and the relationship of language to another language.
Human language is an abstract information symbol, which contains rich semantic information, and humans can easily understand its meaning. Computers can only process numerical information and cannot directly understand human language, so human language needs to be converted into numerical values. Not only that, communication between humans involves contextual information, which is also a huge challenge for computers.
2. NLP task types
Let’s first take a look at the NLP task types, as shown in the figure below:
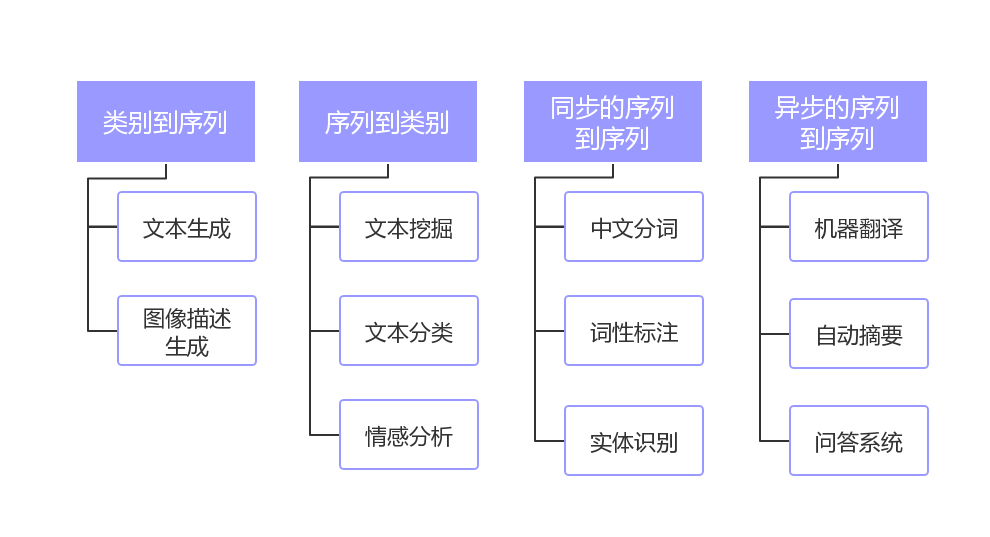
Mainly divided into four categories:
- category to sequence
- sequence to category
- synchronized sequence to sequence
- Asynchronous sequence to sequence
The "category" can be understood as a label or classification, and the "sequence" can be understood as a piece of text or an array. A brief overview of the task of NLP is the process of converting one data type into another. This is the same or similar to most machine learning models, so mastering the technology stack of NLP is equivalent to mastering the technology stack of machine learning. .
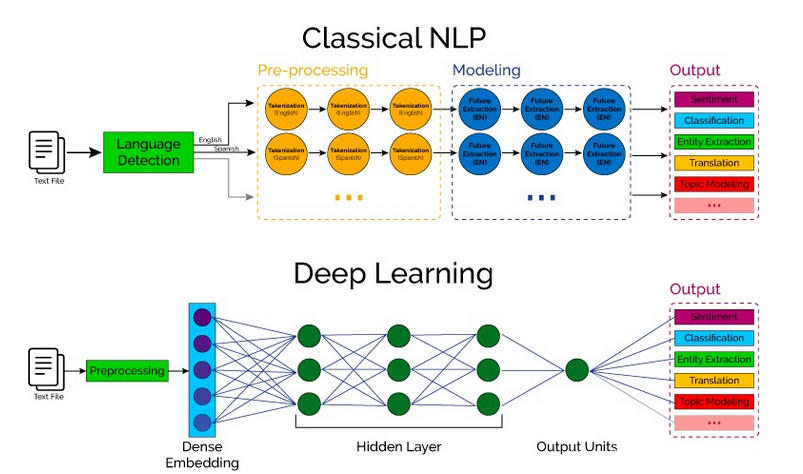
Comparison of traditional methods and deep learning methods NLP
3. Preprocessing of NLP
In order to complete the above NLP tasks, we need some preprocessing, which is the basic process of NLP tasks. Preprocessing includes: corpus collection, text cleaning, word segmentation, removal of stop words (optional), standardization and feature extraction, etc.
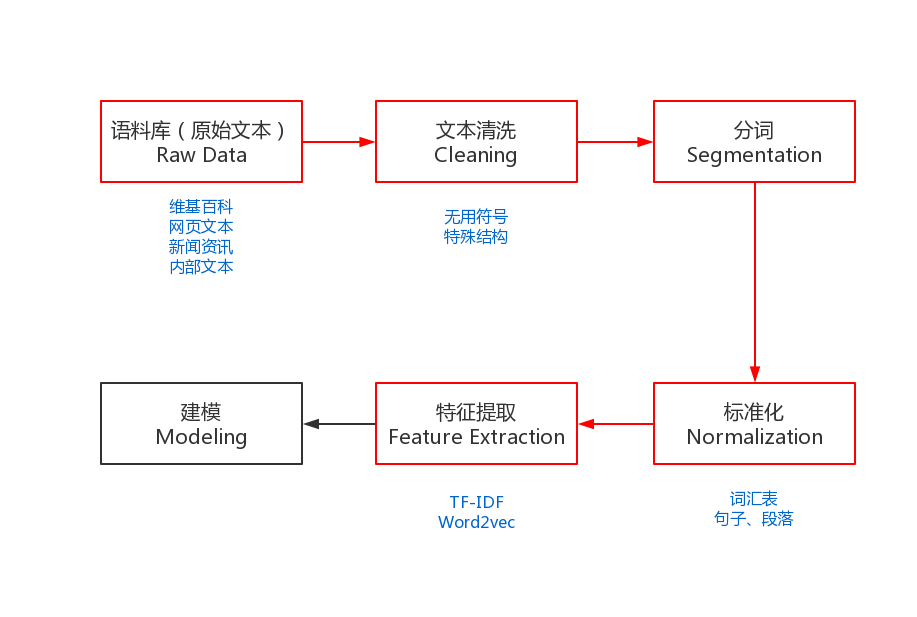
The red part in the picture is the preprocessing process of the NLP task, which is different from the process of other machine learning tasks.
6 steps for English NLP corpus preprocessing

- Participle – Tokenization
- Stemming – Stemming
- Lemmatization – Lemmatization
- Parts of speech tagging – Parts of Speech
- Named entity recognition – NER
- Chunking – Chunking
4 steps for Chinese NLP corpus preprocessing
- Chinese word segmentation – Chinese Word Segmentation
- Parts of speech tagging – Parts of Speech
- Named entity recognition – NER
- Remove stop words
Step 1: Collect your data – corpus
For NLP tasks, without a large amount of high-quality corpus, it is difficult for a clever woman to make a meal without rice, and it is impossible to work.
There are many ways to obtain corpora. The most common way is to directly download open source corpora, such as the Wikipedia corpus.
However, such open source corpora generally cannot meet the personalized needs of business, so you need to develop your own crawlers to capture specific content. This is also a way to obtain corpora. Of course, every Internet company will also have a large amount of corpus data based on its own business, such as user reviews, e-books, product descriptions, etc., which are all good corpora.
Sample data source
Every machine learning problem starts with data, such as a list of emails, posts, or tweets. Common sources of textual information include:
- Product reviews (on Amazon, Yelp, and various app stores)
- User-generated content (tweets, Facebook posts, StackOverflow questions)
- Troubleshooting (customer requests, support tickets, chat logs)
Now, data is oil for Internet companies, which contains huge business value. Therefore, friends must develop the habit of collecting data in their daily work. When encountering a good corpus, be sure to remember to back it up (under reasonable and legal conditions, of course). It will be of great help to you in solving problems.
Step 2: Clean the data - text cleaning
The first rule we follow is: "Your model will always be as good as your data."
One of the key skills of a data scientist is knowing whether the next step should be to work on the model or the data. A good rule of thumb is to look at the data first and then clean it. A clean dataset will allow the model to learn meaningful features rather than overmatching irrelevant noise.
After we obtain the corpus we want through different channels, we need to clean it next. Because a lot of corpus data cannot be used directly, and it contains a large number of useless symbols and special text structures.
Data types are divided into:
- Structured data: relational data, json, etc.
- Semi-structured data: XML, HTML, etc.
- Unstructured data: Word, PDF, text, log, etc.
The original corpus data needs to be converted into an easy-to-process format. Generally, when processing HTML and XML, Python's lxml library is used, which is very rich in functions and easy to use. For some log or plain text data, we can use regular expressions to process it.
Regular expressions use a single string to describe and match a series of strings that conform to a certain syntax rule. The sample code for Python is as follows:
import re
# 定义中文字符的正则表达式
re_han_default = re.compile("([\u4E00-\u9FD5]+)", re.U)
sentence = "我/爱/自/然/语/言/处/理"
# 根据正则表达式进行切分
blocks= re_han_default.split(sentence)
for blk in blocks:
# 校验单个字符是否符合正则表达式
if blk and re_han_default.match(blk):
print(blk)
Output:
我
爱
自
然
语
言
处
理
In addition to the above, we also need to pay attention to the encoding of Chinese. The default encoding of Chinese under the windows platform is GBK (gb2312), and the default encoding of Chinese under the linux platform is UTF-8. Before performing NLP tasks, we need to unify the encoding of corpus from different sources to avoid various inexplicable problems.
If you cannot determine the encoding of the corpus in advance, then I recommend that you use Python’s chardet library to detect the encoding, which is simple and easy to use. It supports both command line: chardetect somefile and code development.
The following is a checklist for cleaning data:
- Remove all irrelevant characters, such as any non-alphanumeric characters
- Tokenize text by splitting it into individual words
- Remove irrelevant words such as "@" twitter mentions or URLs
- Convert all characters to lowercase so words like "hello", "Hello" and "HELLO" are treated the same
- Consider combining misspelled or alternately spelled words into a single representation (e.g. "cool"/"kewl"/"cooool")
- Consider word-opening reduction (reducing words like "am", "are" and "is" to common forms like "be")
After following these steps and checking for additional errors, we can start training the model using clean labeled data!
Step 3: Word segmentation
3 Typical Differences between Chinese and English Participles

Difference 1: Different word segmentation methods, Chinese is more difficult
English has natural spaces as separators, but Chinese does not. Therefore, how to segment is a difficult point. In addition, there are many cases of multiple meanings of a word in Chinese, which leads to ambiguity easily. The difficult part will be explained in detail below.
Difference 2: English words have multiple forms
English words have a wealth of transformations. In order to cope with these complex transformations, English NLP has some unique processing steps compared to Chinese, which we call lemmatization and stemming. Chinese is not required
Part-of-speech restoration: does, done, doing, and did need to be restored to do through part-of-speech restoration.
Stemming: words such as cities, children, and teeth need to be converted into basic forms such as city, child, and tooth.
Difference 3: Chinese word segmentation needs to consider granularity issues
For example, "University of Science and Technology of China" has many classification methods:
- University of Science and Technology of China
- China \ Science and Technology \ Universities
- China \ Science \ Technology \ Universities
The larger the granularity, the more accurate the meaning, but it will also lead to less recall. Therefore, Chinese requires different scenarios and requirements to choose different granularity. This is not available in English.
Chinese word segmentation is a relatively large topic, and the related knowledge points and technology stack are very rich. It can be said that understanding Chinese word segmentation is equivalent to understanding most of NLP.
Three major difficulties in Chinese word segmentation

Difficulty 1: There is no unified standard
At present, there is no unified standard for Chinese word segmentation, and there is no generally accepted specification. Different companies and organizations have their own methods and rules.
Difficulty 2: How to segment ambiguous words
For example, "The table tennis auction is over" has two participle methods to express two different meanings:
- Table Tennis \ Auction \ Finished
- Table tennis \ racket \ for sale \ finished
Difficulty 3: Recognition of new words
In the era of information explosion, a bunch of new words will appear every three days. How to quickly identify these new words is a major difficulty. For example, when "Blue Skinny Shiitake Mushroom" became popular, it needed to be quickly identified.
Chinese word segmentation has experienced more than 20 years of development, overcoming many difficulties and making great progress. It can be roughly divided into two stages, as shown in the following figure:
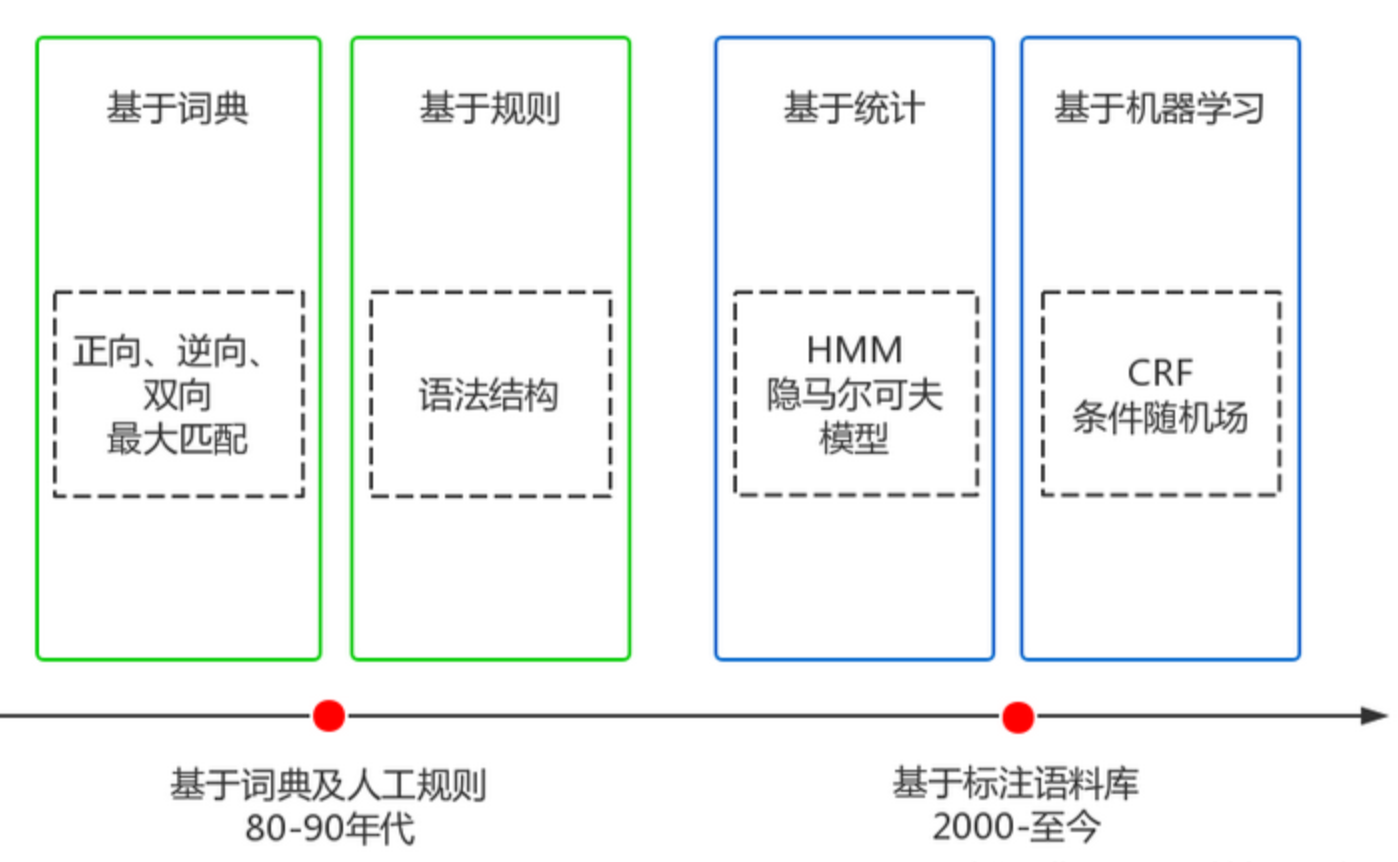
Dictionary matching and rules
Advantages: fast, low cost
Disadvantages: Not very adaptable, effects vary widely in different fields
The basic idea is based on dictionary matching. The Chinese text to be segmented is segmented and adjusted according to certain rules, and then matched with the words in the dictionary. If the matching is successful, the words will be segmented according to the words in the dictionary. If the matching fails, adjust or re-select, and so on. That’s it. Representative methods include forward maximum matching, reverse maximum matching and two-way matching.
Based on statistics and machine learning
Advantages: Strong adaptability
Disadvantages: higher cost, slower speed
Currently commonly used algorithms of this type are HMM, CRF and other algorithms. For example, Stanford and Hanlp word segmentation tools are based on the CRF algorithm. Taking CRF as an example, the basic idea is to label and train Chinese characters. It not only considers the frequency of word occurrence, but also considers the context. It has good learning ability, so it has good results in the recognition of ambiguous words and unregistered words.
Common word segmenters use a combination of machine learning algorithms and dictionaries. On the one hand, they can improve the accuracy of word segmentation, and on the other hand, they can improve domain adaptability.
At present, the mainstream Chinese word segmentation technology adopts a solution based on dictionary maximum probability path + unregistered word recognition (HMM). The typical representative is jieba word segmentation, a popular multi-lingual Chinese word segmentation package.
Chinese word segmentation tool
The following rankings are based on the number of stars on GitHub:
- Hanlp
- Stanford participle
- ansj tokenizer
- Harbin Institute of Technology LTP
- KCWS tokenizer
- jieba
- I
- Tsinghua University THULAC
- ICTCLAS
English word segmentation tool
- Hard
- Spacy
- Gen
- NLTK
Step 4: Standardize
Standardization is to provide some necessary basic data for subsequent processing, including removing stop words, vocabulary, training data, etc.
After we have completed the word segmentation, we can remove the stop words, such as: "wherein", "what's more", "what", etc., but this step is not necessary. The choice must be based on the actual business. For example, keyword mining needs to be removed. Stop words are not required for training word vectors.
The vocabulary list is to create a list of all unique words for the corpus. Each word corresponds to an index value, and the index value cannot be changed. The biggest function of the vocabulary is to convert words into a vector, which is One-Hot encoding.
Suppose we have a vocabulary like this:
我
爱
自然
语言
处理
Then, we can get the following One-Hot encoding:
我: [1, 0, 0, 0, 0]
爱: [0, 1, 0, 0, 0]
自然:[0, 0, 1, 0, 0]
语言:[0, 0, 0, 1, 0]
处理:[0, 0, 0, 0, 1]
In this way, we can simply convert words into numerical data that can be directly processed by computers. Although One-Hot coding can complete some NLP tasks better, it still has many problems.
When the dimension of the vocabulary is particularly large, the word vectors after One-Hot encoding will be very sparse, and One-Hot encoding also lacks semantic information of the words. Because of these problems, the famous Word2vec and the upgraded version of Word2vec, BERT, came into existence.
In addition to the vocabulary, we also need to provide training data when training the model. Model learning can be roughly divided into two categories:
Supervised learning, on the labeled data set with known answers, the prediction results given by the model are as close as possible to the real answer, suitable for prediction tasks
Unsupervised learning, learning without labels Data is to reveal some rules about the hidden structure of data, which is suitable for description tasks
According to different learning tasks, we need to provide different standardized data. In general, the cost of obtaining labeled data is very expensive. Although unsupervised learning does not require such costs, in solving practical problems, supervised learning is still the mainstream method because the effect is better.
The annotated training data roughly looks like this (training data for sentiment analysis):
距离 川沙 公路 较近 公交 指示 蔡陆线 麻烦 建议 路线 房间 较为简单 __label__1
商务 大床 房 房间 很大 床有 2M 宽 整体 感觉 经济 实惠 不错 ! __label__1
半夜 没 暖气 住 ! __label__0
Each line is a training sample, __label__0 and __label__1 are classification information, and the rest is the text data after word segmentation.
Step 5: Feature extraction
In order to better train the model, we need to convert the original features of the text into specific features. There are two main methods of conversion: statistics and Embedding.
Original features: require humans or machines to be converted, such as text and images.
Specific characteristics: have been organized and analyzed by humans and can be used directly, such as: the importance and size of the object.
4. NLP representation method
Currently commonly used text representation methods are divided into:
- Discrete Representation;
- Distributed Representation;
Discrete Representation
One-Hot
One-Hot encoding, also known as "one-hot encoding" or "dumb encoding", is the most traditional and basic word (or character) feature representation method . This encoding represents a word (or word) as a vector whose dimension is the length of the dictionary (or dictionary) (the dictionary is generated from the corpus). In this vector, the value of the current word position is 1 and the rest The position is 0.
Text uses one-hot encoding steps:
- Create a dictionary (vocabulary) based on the corpus, and create a mapping of words and indexes (stoi, itos);
- Convert sentences to indexed representation;
- Create OneHot encoder;
- Sentences were coded using the OneHot encoder;
The characteristics of One-Hot encoding are as follows:
- The word vector length is the dictionary length;
- In the vector, the index position of the word has a value of 1 and the rest of the values are 0
- Text encoded using One-Hot, the resulting matrix is a sparse matrix
shortcoming:
- The vector representations of different words are orthogonal to each other and cannot measure the relationship between different words;
- This coding can only reflect whether a certain word appears in a sentence, and cannot measure the importance of different words;
- Using One-Hot to encode text results in a high-dimensional sparse matrix, which wastes computing and storage resources;
Bag Of Word (BOW)
Example:
- Jane wants to go to Shenzhen.
- Bob wants to go to Shanghai.
In the bag-of-words model, word order and lexical information are not considered. Each word is independent of each other. Put the words into a "bag" ”, count the frequency of each word.
Bag-of-words model coding features:
- The bag-of-words model encodes text (rather than words or words);
- The length of the encoded vector is the length of the dictionary;
- This encoding ignores the order in which words appear;
- In the vector, the value of the index position of the word is the number of times the word appears in the text; if the word at the index position does not appear in the text, the value is 0;
shortcoming
- This encoding ignores the position information of the word. Position information is a very important information in the text. The semantics will be very different depending on the position of the word (for example, the encoding of "cat loves to eat mice" and "rats love to eat cats" are the same) ;
- Although this encoding method counts the number of times a word appears in the text, it cannot distinguish between common words (such as "I", "is", "the", etc.) and keywords (such as: " "Natural Language Processing", "NLP", etc.) importance in the text;
TF-IDF (term frequency-inverse document frequency)
In order to solve the problem that the bag-of-words model cannot distinguish between common words (such as "is", "的", etc.) and proper nouns ( Such as: "natural language processing", "NLP", etc.) to the importance of text, the TF-IDF algorithm came into being.
The full name of TF-IDF is: term frequency–inverse document frequency, also known as term frequency-inverse text frequency. in:
The statistical method is mainly to calculate the word frequency (TF) and inverse document frequency (IDF) of the word:
- TF (Term Frequency): The frequency of a certain word appearing in the current text. Words with high frequency are either important words (such as "natural language processing") or common words (such as "I", "is", "of", etc.);
- IDF (Inverse Document frequency): Inverse document frequency. Text frequency refers to the proportion of texts containing a certain word in the entire corpus. Inverse text frequency is the reciprocal of text frequency;
Then, each word will get a TF-IDF value to measure its importance. The calculation formula is as follows:

advantage
- The implementation is simple, the algorithm is easy to understand and has strong interpretability;
- From the calculation method of IDF, we can see that common words (such as "I", "是", "的", etc.) will appear in many articles in the corpus, so the value of IDF will be very small; while keywords (such as: " "Natural Language Processing", "NLP", etc.) will only appear in articles in a certain field, and the value of IDF will be relatively large; therefore: TF-IDF can filter out some common and irrelevant words while retaining the important words of the article. ;
shortcoming
- It cannot reflect the position information of the word. When extracting keywords, the position information of the word (such as words in the title, sentence beginning, and end) should be given higher weight;
- IDF is a weighting that attempts to suppress noise, and it tends to favor words with smaller frequencies in the text, which makes IDF less accurate;
- TF-IDF relies heavily on corpora (especially when training similar corpora, some keywords of the same type are often covered up; for example: when training TF-IDF, there are more entertainment news in the corpus, then entertainment-related keywords The weight will be low), so it is necessary to select a high-quality corpus for training;
Distributed Representation
Theoretical basis:
- In 1954, Harris proposed the distributional hypothesis, laying the theoretical foundation for this method: A word’s meaning is given by the words that frequently appear close-by (words with similar contexts have similar semantics);
- In 1957, Firth further elaborated and clarified the distribution hypothesis: A word is characterized by the company it keeps (the semantics of a word is determined by its context);
n -gram
n-gram is a language model (Language Model, LM). The language model is a discriminative model based on probability. The input of the model is a sentence (a sequence of words), and the output is the probability of the sentence, which is the joint probability of these words. (Note: The language model is to determine whether a sentence is said by a normal person.)
Co-Occurrence Matrix
First specify the window size, and then count the number of co-occurrences of words in the window (and symmetric window) as the word vector.
Corpus:
- I like deep learning.
- I like NLP.
- I enjoy flying.
Remarks: The specified window size is 1 (ie: left and right window_length=1, equivalent to bi-gram). The statistical data are as follows: (I, like), (Iike, deep), (deep, learning), (learning, .), (I, like), (like, NLP), (NLP, .), (I, enjoy), (enjoy, flying), (flying, .). Then the co-occurrence matrix of the corpus is shown in the following table:
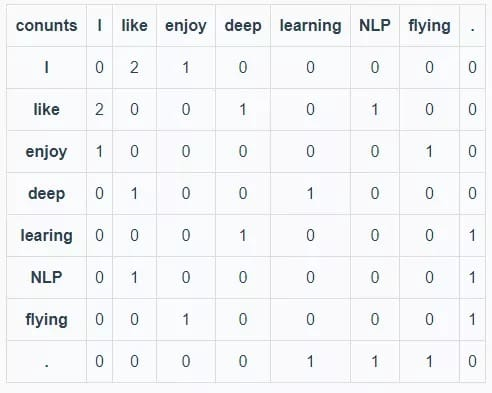
It can be seen from the above co-occurrence matrix that the words like and enjoy both appear in the attachment of word I and the statistical numbers are approximately equal, so their semantic and grammatical meanings are approximately the same.
advantage
- The order of words in the sentence is taken into account;
shortcoming
- The length of the word list is very large, resulting in the length of word vectors being also very large;
- The co-occurrence matrix is also a sparse matrix (dimension reduction can be performed using algorithms such as SVD and PCA, but the calculation amount is very large);
Word2Vec
The word2vec model is a word representation method released by the Google team in 2013. As soon as this method was introduced, the use of pre-trained word vectors blossomed in the field of NLP.
word2vec model
word2vec has two models: CBOW and SKIP-GRAM;
- CBOW: Use contextual words to predict the center word;

- SKIP-GRAM: Use the center word to predict context words;

advantage
- Semantic and grammatical information is learned taking into account the context of the word;
- The obtained word vector has a small dimension, saving storage and computing resources;
- It has strong versatility and can be applied to various NLP tasks;
shortcoming
- There is a one-to-one relationship between words and vectors, which cannot solve the problem of polysemy;
- word2vec is a static model. Although it is highly versatile, it cannot be dynamically optimized for specific tasks;
GloVe
GloVe is a word vector representation algorithm provided by Jeffrey and Richard of Stanford University. The full name of GloVe is Global Vectors for Word Representation. It is an algorithm based on global word frequency statistics (count -based & overall staticstics) word representation algorithm. This algorithm combines the advantages of global matrix factorization and local context window.
Note: The derivation formula of the Glove model is relatively complex, and we will not do a detailed derivation here. For details, you can check the official website (https://nlp.stanford.edu/projects/glove/).
Effect

advantage
- Taking into account the context of the word and the information of the global corpus, semantic and grammatical information is learned;
- The obtained word vector has a small dimension, saving storage and computing resources;
- It has strong versatility and can be applied to various NLP tasks;
shortcoming
- There is a one-to-one relationship between words and vectors, which cannot solve the problem of polysemy;
- Glove is also a static model. Although it is highly versatile, it cannot be dynamically optimized for specific tasks;
ELMO
The word vectors obtained by word2vec and glove algorithms are all static word vectors (static word vectors will fuse the semantics of polysemy words and will not change according to the context after training) , static word vectors cannot solve the problem of polysemy (for example: "I bought 7 pounds of apples today" and "I bought 7 pounds of apples today", the apple is a polysemy). The word vectors trained by the ELMO model can solve the problem of polysemy.
The full name of ELMO is "Embedding from Language Models". This name does not reflect the characteristics of the model well. The title of the paper proposing ELMO can more accurately express the characteristics of the algorithm "Deep contextualized word representation".
The essence of this algorithm is: use a language model to train a neural network. When using word embedding, the word already has contextual information. At this time, the neural network can adjust the word embedding based on the contextual information, so that the adjusted word embedding can better express the The specific meaning in this context solves the problem that static word vectors cannot represent polysemy words.
network model
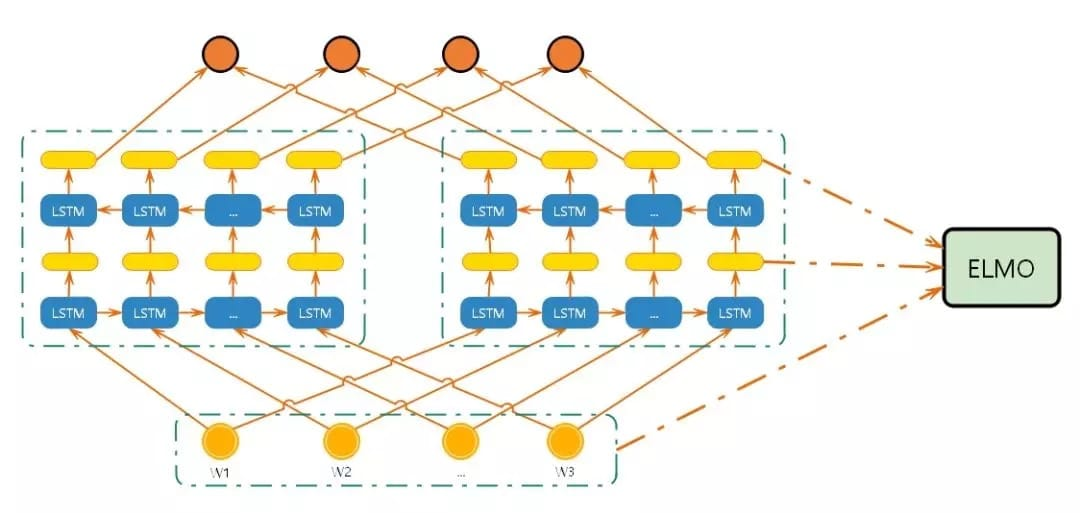
process
- The structure in the figure above uses a character-level convolutional neural network (CNN) to convert words in the text into raw word vectors;
- Enter the original word vector into the first layer of the bidirectional language model;
- The forward iteration contains information about the word and some vocabulary or context before the word (i.e., above);
- The backward iteration contains the word and some lexical or contextual information after the word (i.e., the following);
- These two types of iterative information form the intermediate word vector;
- The intermediate word vector is input to the next layer of the model;
- The final vector is the weighted sum of the original word vector and the two intermediate word vectors;
Effect
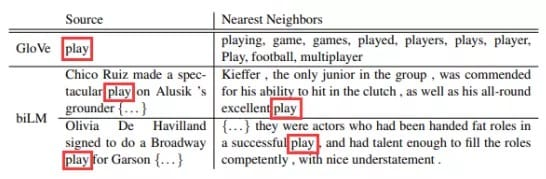
As shown in FIG:
Among the word vectors trained using glove, the words similar to play are mostly related to sports. This is because the corpus related to play in the corpus is mostly related to the field of sports;
When using In the word vectors trained by elmo, when play takes the meaning of performance, the sentences that are similar to it are also sentences similar to performance;
5. Business scenarios of NLP
4 typical applications of NLP

- Text correction: identify typos in text, give tips and correct suggestions
- Sentiment analysis: judging the emotional tendency of texts containing subjective information
- Comment opinion extraction: analyze comment concerns and opinions, and output labels
- Conversation emotion recognition: Identify the emotion categories and confidence levels displayed by the conversational speaker
- Text tags: Output multi-dimensional tags that can reflect the key information of the article
- Article classification: Output the topic classification of the article and the corresponding confidence level
- News summary: extract key information and generate a news summary of specified length
Don’t be confused by these dazzling business scenarios. In fact, the above businesses are based on the output of the NLP preprocessing we talked about before, but they apply different machine learning models, such as: SVM, LSTM, LDA, etc.
Most of these machine learning models are classification models (sequence labeling is also a classification model), and only a few are clustering models. These models are generalized and not just for NLP tasks. If you want to explain this part clearly, you need to open another topic about "Introduction to Machine Learning", so I won't go into too much detail here.
Summary: As long as you master the pre-processing of NLP, you are considered to be an introduction to NLP, because the subsequent processing is some common machine learning models and methods.
6. Conclusion
NLP is a very challenging job, and it is also a job with great room for development. So as long as you overcome the early entry threshold, you will be greeted by a vast world. The road is blocked and long, but the road is coming.
7. Reference materials
8 types of text representation in the field and their advantages and disadvantages
https://easyai.tech/ai-definition/nlp/
https://juejin.im/post/5dccbe0ff265da795315a119