Table of contents
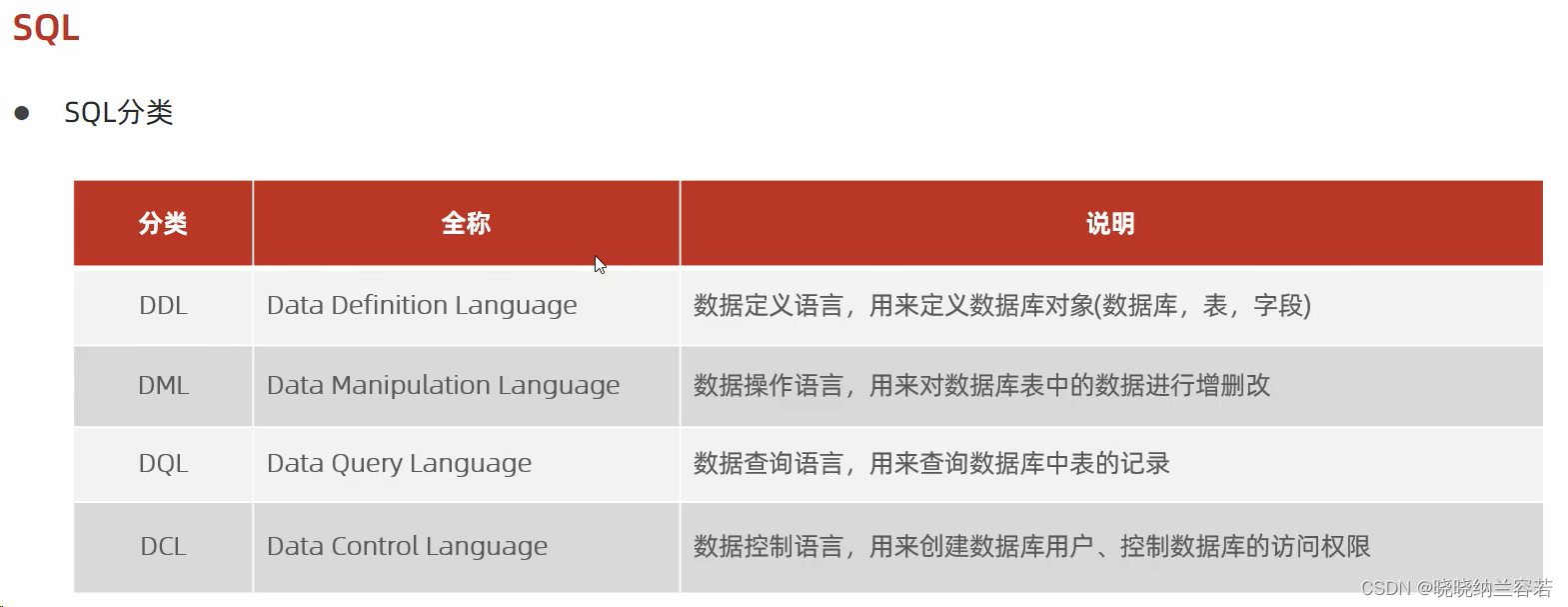
2--Classification of SQL statements
1--General syntax of SQL

2--Classification of SQL statements
3--DDL statement
3-1--Database operations
# 查询所有数据库
show databases;
# 查询当前使用数据库
select database();
# 创建数据库
create database 数据库名
create database if not exists 数据库名; # 不存在时创建,存在则不创建
create database 数据库名 default charset 字符集; # 使用特定字符集
# 删除数据库
drop database if exists 数据库名;
# 使用特定数据库
use 数据库名;
3-2--Table operations
# 查询当前数据库所有表
show tables;
# 查询表结构
desc 表名;
# 查询指定表的建表语句
show create table 表名;
# 创建表
create table 表名(
字段1 字段1类型[COMMENT 字段1注释],
字段2 字段1类型[COMMENT 字段2注释],
字段3 字段1类型[COMMENT 字段3注释],
......
字段n 字段n类型[COMMENT 字段n注释]
)[COMMENT 表注释];
# example:
create table tb_user(
-> id int comment '编号',
-> name varchar(50) comment '姓名',
-> age int comment '年龄',
-> gender varchar(1) comment '性别'
-> ) comment '用户表';
3-3--Data type
Data types in MySQL include three categories: numerical types, string types and date and time types;
Numeric type: Specify the use of unsigned by adding unsigned;
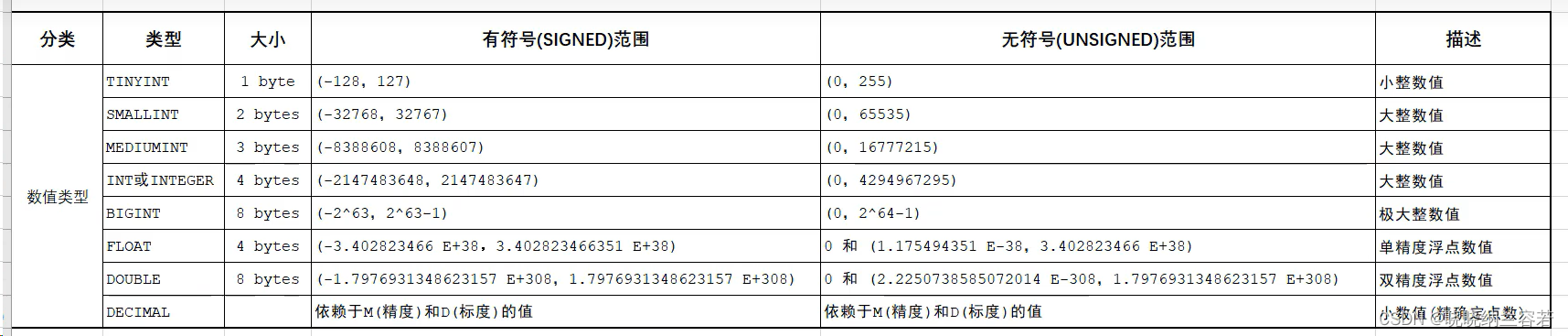
String type: The performance of char will be better than that of varchar.

Datetime type:

Case:

create table emp(
-> id int comment '编号',
-> workno varchar(10) comment '工号',
-> name varchar(10) comment '姓名',
-> gender char(1) comment '性别',
-> age tinyint unsigned comment '年龄',
-> idcard char(18) comment '身份证号',
-> entrydate date comment '入职时间'
-> ) comment '员工表';
3-4--Modify and delete
# 添加字段
alter table 表名 add 字段名 类型(长度) [comment 注释];
# 为 emp 表增加一个新的字段"昵称",字段名为nickname,类型为varchar(20);
alter table emp add nickname varchar(20) comment "昵称";
# 修改数据类型
alter table 表名 modify 字段名 新数据类型(长度);
# 修改字段名和字段类型
alter table 表名 change 旧字段名 新字段名 类型(长度) [comment 注释];
# 将 emp 表的 nickname 字段修改为 username,类型为varchar(30)
alter table emp change nickname username varchar(30) comment "用户名";
# 修改表名
alter table 表名 rename to 新表名;
# 将 emp 表的表名修改为employee
alter table tmp rename to employee;
# 删除字段
alter table 表名 drop 字段名;
# 将 emp 表的字段 username 删除;
alter table tmp drop username;
# 删除表
drop table [if exists] 表名;
# 删除指定表,并重新创建该表
truncate table 表名; # 重新创建的是一个空表4--DML statement
4-1--Insert data
# 给指定字段添加数据
insert into 表名(字段名, 字段名2, ...) values(值1, 值2, ...);
# example
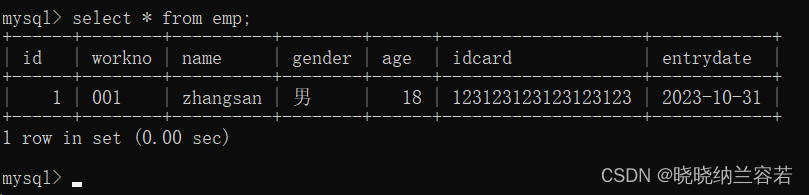
insert into emp(id, workno, name, gender, age, idcard, entrydate) values(1, '001', 'zhangsan', '男', 18, '123123123123123123', '2023-10-31');
# 展示插入后表的结果
select * from 表名;
# example
select * from emp;
# 给全部字段添加数据
insert into 表名 values(值1, 值2, ...);
# 一次插入多条记录,使用,来分隔两条记录
insert into 表名 values(...), (...);

4-2--Modify data
# 指定条件来修改指定数据
update 表名 set 字段1=值1, z字段2=值2, ..., where 条件;
# example
update emp set name = 'lisi', age = 19 where id = 1;
# 不指定条件来修改所有数据
update 表名 set 字段1=值1, z字段2=值2, ...;
# update emp set age = 20;

4-3--Delete data
# 删除指定数据
delete from 表名 where 条件;
# 删除全部数据
delete from 表名;
5--DQL statement
5-1--Basic query
# 查询多个字段
select 字段1, 字段2, 字段3, ... from 表名;
select * from 表名;
# 设置别名
select 字段1 as 别名1, 字段2 as 别名2, ... from 表名;
# 去除重复记录
select distinct 字段列表 from 表名;5-2--Conditional query
Commonly used conditions are as follows:

# 基本语法
select 字段列表 from 表名 where 条件列表;
# 基本实例
# 1. 查询年龄等于 88 的员工
select * from emp where age = 88;
# 2. 查询年龄小于 20 的员工
select * from emp where age < 20;
# 3. 查询年龄小于等于 20 的员工
select * from emp where age <= 20;
# 4. 查询没有身份证号的员工
select * from emp where idcard is null;
# 5. 查询由身份证号的员工
select * from emp where idcard is not null;
# 6. 查询年龄不等于 88 的员工
select * from emp where age != 88;
select * from emp where age <> 88;
# 7. 查询年龄在15岁到20岁之间的员工(闭区间)
select * from emp where age >= 15 && age <= 20;
select * from emp where age >= 15 and age <= 20;
select * from emp where age between 15 and 20;
# 8. 查询性别为女 且年龄小于 25 岁的员工
select * from emp where gender = '女' and age < 25;
# 9. 查询年龄等于 18 或 20 或 40 的员工
select * from emp where age = 18 or age = 20 or age = 40;
select * from emp where age in (18, 20, 40);
# 10. 查询姓名为两个字的员工
select * from emp where name like '__';
# 11. 查询身份证号最后一位是X的员工
select * from emp where idcard like '%X';5-3--Aggregation function
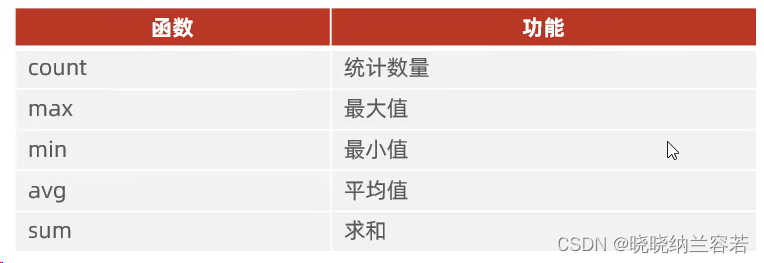
Aggregation functions are used to perform longitudinal calculations on the data as a whole;
Common aggregate functions:
# 基本语法:
select 聚合函数(字段列表) from 表名; # null 值不参与聚合函数的计算
# 代码实例
# 1. 统计员工数量
select count(*) from emp;
# 2. 统计员工平均年龄
select avg(age) from emp;
# 3. 统计员工最大年龄
select max(age) from emp;
# 4. 统计员工最小年龄
select min(age) from emp;
# 5. 统计深圳地区员工的年龄总和
select sum(age) from emp where workaddress = '深圳';
5-4--Group query
基本语法
select 字段列表 from 表名 where 条件 group by 分组字段名 having 分组后过滤条件;
where 和 having 的区别:
1. 执行时机不同,where是分组之前进行过滤,不满足where条件的不会参与分组,having是对分组之后的结果进行过滤
2. 判断条件不同,where不能对聚合函数进行判断,而having可以
分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
# 代码实例:
1. 根据性别分组,统计男性员工和女性员工的数量
select gender, count(*) from emp group by gender;
2. 根据性别分组,统计男性员工和女性员工的平均年龄
select gender, avg(age) from emp group by gender;
3. 查询年龄小于45的员工,并根据工作地址分组,获取员工数量大于等于3的工作地址
select workaddress, count(*) from emp where age < 45 group by workaddress having count(*) > 3;5-5--Sort query
基本语法:
select 字段列表 from 表名 order by 字段1 排序方式1, 字段2 排序方式2;
排序方式:
asc 表示升序(默认值)
desc 表示降序
使用多字段排序时,当第一个字段值相同时,会根据第二个字段进行排序代码实例:
# 1. 根据年龄对员工进行升序排序
select * from emp order by age asc;
# 2. 根据入职时间对员工进行降序排序
select * from emp order by entrydate desc;
# 3. 根据年龄对员工进行升序排序,当年龄相同时按照入职时间进行降序排序
select * from emp order by age asc, entrydate desc;5-6--Page query
基本语法:
select 字段列表 from 表名 limit 起始索引, 查询记录数;
注意事项:
起始索引从 0 开始,起始索引 = (查询页码 - 1) * 每页显示记录数;
不同数据库对于分页查询有不同的实现, MySql中是limit;
如果查询的是第一页数据,则起始索引可以省略;代码实例:
# 1. 查询第1页员工数据,每页显示10条记录
select * from emp limit 0, 10;
select * from emp limit 10; # 第一页可以省略查询页码
# 2. 查询第二页员工数据
select * from emp limit 10 10; # (2 - 1) * 10 = 105-7--Execution sequence
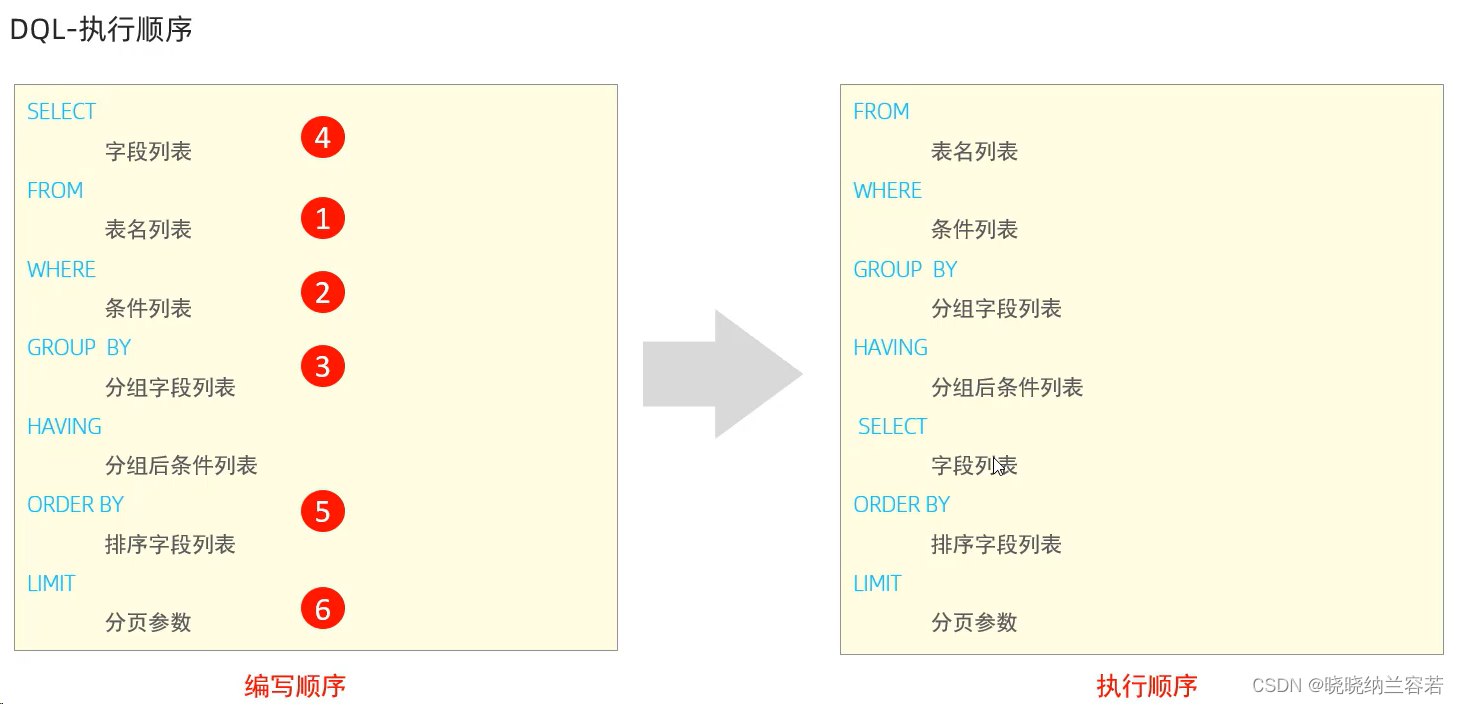
6--DCL statement
6-1--User management
# 1. 查询用户
use mysql;
selece * from user;
# 2. 创建用户
create user '用户名'@'主机名' identified by '密码';
# 3. 修改用户密码
alter user '用户名'@'主机名' identified with mysql_native_password by '新密码';
# 4. 删除用户
drop user '用户名'@'主机名';
主机名可以使用 % 通配,表示可以从任何主机登录数据库;6-2--Permission control
Common permissions:
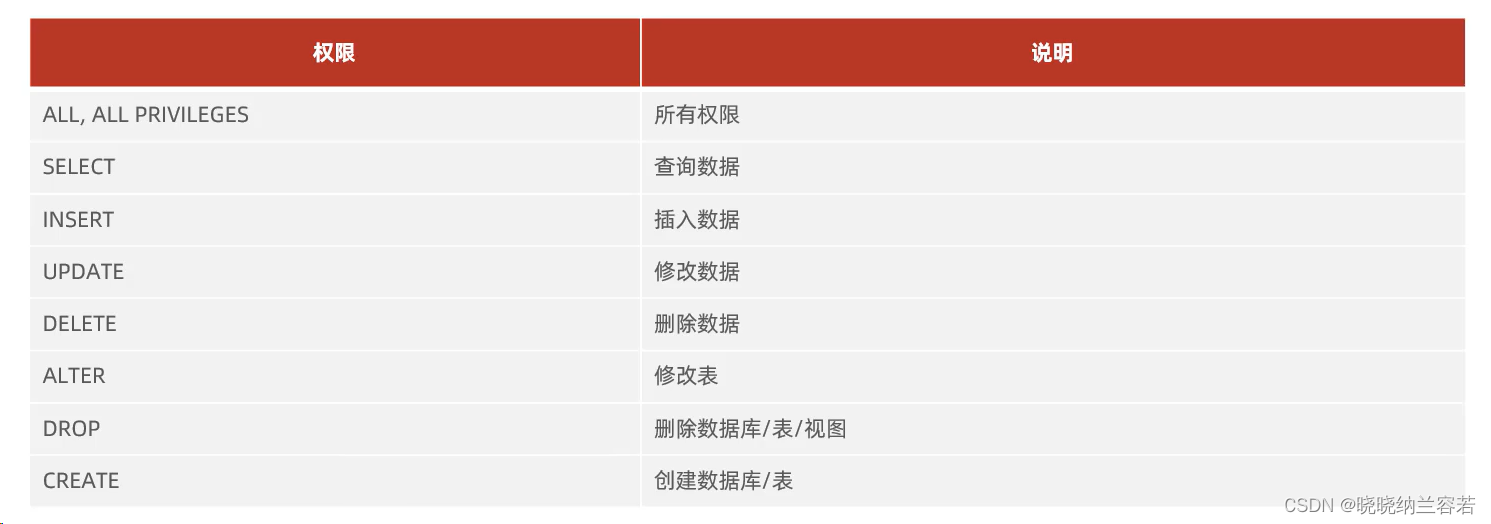
基本语句
# 1. 查询权限
show grants for '用户名'@'主机名';
# 2. 授予权限
grant 权限列表 on 数据库名.表名 to '用户名'@'主机名';
# 3. 撤销权限
revoke 权限列表 on 数据库名.表名 from '用户名'@'主机名';
多个权限之间使用逗号分隔,授权时数据库名和表名可以使用 * 进行通配,表示所有