Table of contents
(4.7) forward_list one-way linked list
(4.9) unordered_map and unordered_set, etc.
(4.10) The difference between the two containers vector and list
(1) Classification of iterators
(2) Function objects defined in the standard library
1. Overview of STL
- C++ Standard Library: The English name is C++Standard Library.
- Standard Template Library: The English name is StandardTemplateLibrary (STL). Included in the C++ standard library, as an important part of the C++ standard library or the core of the C++ standard library, it deeply affects the standard library.
- The C++ standard library contains many header files, among which there are dozens or hundreds of header files related to STL (different STL versions have different numbers of files). When using STL, you also need to include these header files into your own project. The header file names in the modern version of the standard library have removed the .h extension and become header files without extensions. There are also some standard header files in C language. In the past, such as #include<stdlib.h>, it is recommended to write #include<cstdlib> in the new version. Note that in this way of writing, there is an extra letter c in front of the file name, and the file extension .h is also removed. Of course, the old version of writing #include<stdlib.h> can still be used (because these .h files still exist).
- Components of STL: containers, iterators, algorithms (can be understood as some functions provided by STL, used to implement some functions, such as search for search, and sorting for sort, copy is used for copying), allocator (used to allocate memory), others (including adapters, functors/function objects, etc.).

1.Container
Containers in STL can be divided into three categories: sequential containers, associative containers, and unordered containers.
(1) Sequential container
Sequence Containers means that when you put it in, place the element (the data put in the container is called the element in the container) where it will be. For example, if you put it in the front, then it will be there. It will always stay at the front. This is the sequence container. Containers such as array, vector, deque, list, forward_list, etc. are all sequential containers.
(2) Associated containers
Each element of this kind of container is a key/value pair. It is particularly fast and convenient to use this key to find the value.
The interior of an associative container generally uses a data structure called a "tree" to store data. When I just talked about the sequential container, the author said that the sequential container is where the element is placed when it is put in. The association container is different. When you put an element into the association container, the association container will automatically place the element in a certain position according to some rules, such as key.
In other words, the programmer cannot control where elements are inserted, only the inserted content. Set, map, multiset, multimap, etc. all belong to Associative Containers.
(3) Unordered container
This container is a container introduced in C++11. According to the official statement, the position of the elements in this container is not important. The only important thing is whether the element is in this set. Generally, when inserting this kind of element, you don't need to arrange the position of the element to be inserted. This kind of container will also automatically arrange the position of the element. Therefore, according to the characteristics of this kind of container, Unordered Containers should belong to an associative container.
As the number of elements added to this container increases, it is likely that the position of an element in the container will change. This is determined by the algorithm inside the container. Therefore, the name "unordered container" is quite appropriate. Unordered containers are generally implemented using a data structure such as a hash table. For example, unordered_set, unordered_multiset, unordered_map, unordered_multimap, etc. are all unordered containers.
The C++ standard does not require any container to use any specific implementation. But generally speaking, there are rules to follow. For example, map uses a data structure like a tree to store data, and containers starting with hash_ generally use a data structure like a hash table to store data.
(4) Commonly used containers
(4.1) array array
Array is a sequential container. It is actually an array, so its space is continuous and its size is fixed. It is as big as you apply for at the beginning, and its size cannot be increased.
(4.2)vector
The space of vector is continuous. As this space grows, you need to find a new memory that is large enough to accommodate all the current elements, and move all the elements to the new memory. It is easy to think of this move, the elements in the old container must be Destruction, these moved elements must re-execute the constructor to construct. This obviously greatly affects program execution efficiency.
The number of elements in the container can be viewed using size, and the space of the container can be viewed using capacity. The result of capacity must not be less than size, which means that the amount of space in the container must not be less than the number of elements.
When an element is deleted from the vector container, it will cause a destructor to be executed, and then the memory of all subsequent elements will be moved forward (at least on the surface, the element object will be moved forward), but these moved objects will not be executed. Any constructor and destructor, this means that the compiler has its own internal processing, which is good.
Inserting elements into the middle of the vector container will cause some subsequent elements to be destructed and reconstructed, and inserting elements from the middle is very costly. So, if you don’t know in advance how many elements are to be inserted into the vector, and you just insert one when needed, then obviously the operating efficiency of the vector container will not be high - frequently and in large quantities Construction, destruction, and finding a new entire block of memory are all taboo for developers. However, if you know in advance that there will be no more than 10 elements in the vector container during the entire program, for example, the programmer knows that there will be no more than 10 elements at most, then let the capacity equal 10 in advance (reserve 10 elements in the container space), so that when inserting elements into the container, as long as there are no more than 10 elements, there is no need to frequently construct and destroy element objects. In other words, there is no need to find a new entire block of memory to relocate elements (so, making good use of capacity can also improve the efficiency of the vector container.).
(4.3) deque queue
The sequential container deque is a double-ended queue (two-way open), and deque is the abbreviation of double-ended queue. This queue is equivalent to a dynamic array. Because it is double-ended, inserting and deleting data at the head or tail will be fast. However, if you insert data in the middle, the efficiency will be lower because other elements need to be moved.
Deque is actually a segmented array. When there are many elements inserted, it will divide the elements into multiple segments. Of course, the memory of each segment is continuous (so it can only be said that the memory is segmented and continuous).
(4.4) stack stack
Stack is somewhat similar to vector, but please note that vector also supports insert and erase, that is to say, vector supports the operation of inserting and deleting elements from the middle. However, stack only supports adding elements to the top of the stack and removing elements from the top of the stack (deleting elements), because the original intention of the stack container design requires this feature.
Deque contains the stack function.
(4.5) queue queue
Deque is a double-ended queue, but queue is an ordinary queue (queue for short). Queue is a relatively basic data structure, which is characterized by first-in, first-out. In other words, elements enter from one end and are taken out (delete elements) from the other end. The original intention of the queue container design requires this feature.
Deque also includes the queue function.
(4.6) list Two-way table
The sequential container list is a doubly linked list. The elements don't need to be close together, you just need to use pointers to associate the elements by pointing.
Characteristics of list doubly linked list: To find elements, you have to find them along the chain, so the efficiency of the search is not outstanding, but because it is a doubly linked list, inserting and deleting elements at any position is very fast - pointers in several elements Just change the direction.
(4.7) forward_list one-way linked list
This is a newly added sequential container in C++11, which is a one-way linked list. forward_list has one less chain (pointer) in one direction than list, and is officially called a restricted list. Missing a pointer in one direction will cause certain access inconveniences, but without a pointer in one direction, the elements in a container can save 4 bytes of memory (under the x86 platform). If there are many elements in the container, the memory saved is also considerable.
Many containers have push_back member functions, but the forward_list container only has push_front, which shows that this container is most suitable for inserting elements from the front.
(4.8) map and set
Map and set are both associative containers. The internal implementation of containers such as map and set is mostly a red-black tree. The data structure of the red-black tree itself has a good mechanism for saving data. When saving data to this kind of container, you do not need to specify the location of the data. This kind of container will automatically arrange the position of the added elements according to the internal algorithm.
When inserting elements, because this type of container needs to find a suitable location for the inserted element, the insertion speed may be slower. However, the advantage is that the search time is faster, so for application scenarios that need to find elements quickly, Focus on using containers such as map and set.
Each element (tree node) of the map container is a key/value pair. This kind of container can find value by key very quickly, but it does not allow two identical keys to appear in one map container. Therefore, if the key is likely to be repeated, please use a multimap container.
The elements in the set container are not divided into keys and values. Each element is a value. After the element is saved into the container, the container will automatically put the element in a position. The value of each element is not allowed to be repeated, and inserting repeated elements has no effect. If you want to insert repeated elements, use a multiset container.
(4.9) unordered_map and unordered_set, etc.
In the past, old containers such as hash_set, hash_map, hash_multiset, and hash_multimap can also be used, but they are not recommended. Newer versions of containers generally start with unordered_. Containers starting with unordered_ are unordered containers (a type of associative container). Unordered containers are generally implemented using hash tables (hash tables).
Each element of unordered_map and unordered_multimap is also a key-value pair. The keys saved in unordered_map are not allowed to be repeated, while the keys saved in unordered_multimap can be repeated.
Each element of unordered_set and unordered_multiset is a value. The values saved in unordered_set are not allowed to be repeated, while the values saved in unordered_multiset can be repeated.
(4.10) The difference between the two containers vector and list
- Vector is similar to an array, its memory space is continuous, list is a doubly linked list, and its memory space is not continuous.
- The efficiency of inserting and deleting elements in vector is relatively low, but the efficiency of inserting and deleting elements in list is very high.
- When vector has insufficient memory, it will find a new piece of memory, destruct the elements in the original memory, and re-create these objects (elements in the container) in the newly found memory.
- Vector can perform efficient random access (jump to a specified location for access), but list cannot do this. For example, if you want to access the fifth element, vector is extremely fast because the memory is continuous. It can locate the fifth element in one go (a pointer can reach the specified position by jumping a certain number of bytes). On the other hand, if you want to find the fifth element in the list, you have to follow the chain one by one until you find the fifth element. So vector random access is very fast, while list random access is slower.
2. Distributor
The allocator is closely related to the container. However, when writing code, the system default allocator is generally used, and there is no need to specify the allocator yourself.
std::list<int> list;
std::list<int, std::allocator<int>> list;The introduction of the allocator mainly plays the role of a memory pool, greatly reducing calls to malloc to reduce the waste of memory allocation. (The allocator allocates a large block of memory at a time, and then allocates a small block of this large block of memory to the programmer for use at a time, and uses a linked list to manage these memory blocks. This The memory allocation mechanism of this kind of memory pool effectively reduces the number of calls to malloc, which is equivalent to reducing the waste of memory, and also improves the program running efficiency to a certain extent.)
#include <list>
void TestSTL()
{
//分配器
std::list<int> list;//默认的分配器std::allocator<int>,并没有实现内存池
list.push_back(1);
list.push_back(2);
list.push_back(3);
//迭代器
for (std::list<int>::iterator iter = list.begin(); iter != list.end(); iter++)
{
std::cout << *iter << std::endl;
}
}By default, the system provides programmers with the default allocator allocator. This is a class template that is written in the standard library and directly provided to programmers. Of course, programmers can also write their own allocator for use in containers, which is feasible. How the default allocator is implemented, unless you read its source code, it is not clear whether it allocates memory through a memory pool, or it may not implement any memory pool at all, but simply calls the underlying malloc to allocate memory, this is possible.
An allocator is a class template that takes a type template parameter. Containers in the C++ standard library, such as std::vector, std::list, etc., use std::allocator as their allocator by default. But users can provide custom allocators to change how the container acquires and releases memory. A typical allocator defines the following types and functions:
- value_type: The type of assigned value.
- allocate(): allocate uninitialized memory.
- deallocate(): Releases memory previously allocated by allocate.
- construct(): Constructs the element at the given position.
- destroy(): Destroy the element that has been constructed at the given position.
3.Iterator
An iterator is an object that “can traverse all or part of the elements of an STL container” (for ease of understanding, an iterator can be understood as an object that behaves like a pointer). Iterator is used to represent a certain position in the container, and the iterator is provided by the container. That is to say, generally speaking, it is the container that defines the specific type details of the iterator.
Since iterators can be understood as objects that behave similarly to pointers, for pointers, you can use *p to read the content pointed by the pointer, so for iterators, you can generally read what the iterator points to using *iter. Content.
(1) Classification of iterators
An iterator is like a pointer, jumping around to represent a position. Classification is also divided according to its jumping ability, and each classification corresponds to a struct structure. Iterators are mainly divided into the following five categories, and these structures have an inheritance relationship.
- Output iterator
- Input iterator
- Forward iterator
- Bidirectional iterator
- Random-access iterator
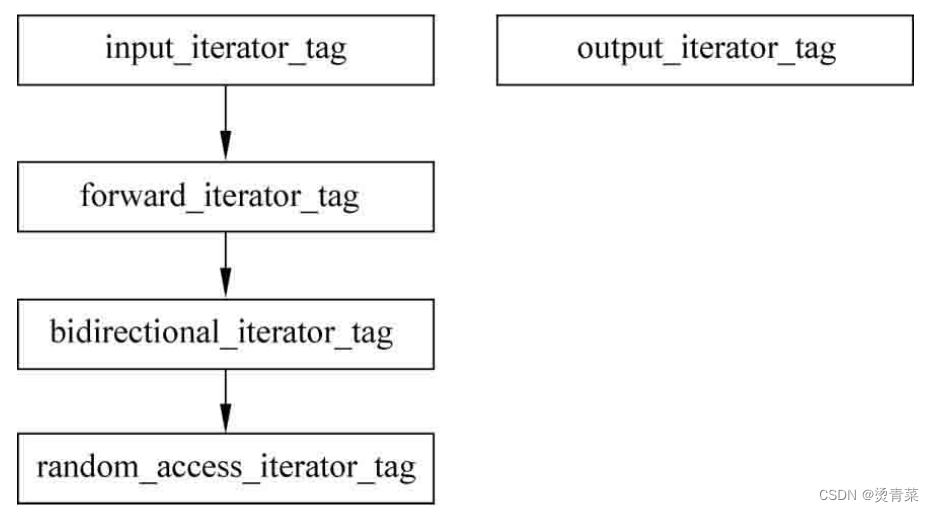

The so-called random reading refers to skipping a certain number of elements. For example, if the current position is at the first element, you can immediately skip 3 elements and go directly to the 4th element. Random access iterators seem to be the most flexible because random access iterators support the most operations, such as jumping multiple elements at a time. The element memory of the containers array and vector it supports are all continuous, so it is very convenient to jump to the fifth element. You can jump immediately by doing an addition operation. Although deque, a double-ended queue container, supports random access iterators, this container is piecewise continuous, which means that it is not truly continuous in memory. Although it is not truly continuous, its iterators are still random. Access, that is, you can jump to multiple elements at one time. This design is quite exquisite. In short, most containers that support random access iterators are memory contiguous.
You can also see the difference between vector and list containers: the two containers support different iterator types. The vector container supports random access iterators, and the list container supports bidirectional iterators. No random access iterator supports so many iterator operations. Therefore, one of the main differences between vector containers and list containers is that vector can perform efficient random access, but list cannot do this.
4. Algorithm
Algorithms can be understood as functions. A more accurate statement is: algorithms are understood as function templates. STL provides many algorithms, such as search, sorting, etc., there are dozens or hundreds of them, and the number is still increasing.
Each container has many member functions suitable for the various operations of the container itself. The algorithm is different from these member functions. The algorithm can be understood as a global function or global function template (not for a certain container, but for some or large parts). Applicable to some containers). Since the algorithm is a function template, it has parameters, that is, formal parameters. The types of these formal parameters passed in are generally iterator types, which are used to represent a range of elements in a container. This You also need to pay attention to the interval.
It is generally believed that there are two benefits of this kind of front-closed and then-open interval:
- As long as the algorithm determines that the iterator is equal to the following open interval, it means that the iteration is over.
- If the first parameter is equal to the second parameter, this represents an empty interval.
#include <vector>
#include <algorithm>
int main() {
std::vector<int> v = {4, 2, 5, 3, 1};
std::sort(v.begin(), v.end());
// 现在v包含{1, 2, 3, 4, 5}
return 0;
}An algorithm is a global function (or global function template) used with an iterator. These algorithms have nothing to do with specific containers, only iterators, and most containers have iterators. In other words, these algorithms are suitable for most containers and do not need to be specially customized for a certain container.
Of course, implementing the algorithm as a separate function (function template) also violates the encapsulation feature of object-oriented programming (packaging member variables and member functions together), which is a pity.
(1) Commonly used algorithms
(1.1)for_each
For_each looks like a statement, but is actually an algorithm.
The first and second formal parameters of for_each are both iterators, representing a range (or a range of elements in a container). The third parameter of for_each is actually a callable object.
(1.2)find
Find is used to find a specific value.
Some containers have their own member functions with the same name (including but not limited to the find function mentioned here), and member functions with the same name are preferred (but unlike algorithms, member functions with the same name generally do not need to be passed in iterators as the first two parameters) , if there is no member function with the same name, the global algorithm will be considered.
(1.3)find_if
The call to find_if returns an iterator (such as vector<int>::iterator), pointing to the first element that meets the condition. If such an element does not exist, this iterator will point to vector.end(). This algorithm is similar to find, except that the third parameter of find is a number, and the third parameter of find_if here is a callable object (lambda expression). There is a rule in this callable object - find the first Elements that satisfy this rule.
(1.4)sort
Sort is used for sorting purposes.
When the sort algorithm is applied to a list container, an error will be reported, indicating that this algorithm is not applicable to the list container. Because the sort algorithm works on random access iterators but not on bidirectional iterators.
The list container has its own sort member function. Of course, the sort member function provided by the list container itself is used.
5. Function object
The third parameter of sort is a function object (function object) or functor (functors), which is used to specify a sorting rule. Functors are actually function objects, but the name functor is older, and the new name is function object.
This kind of function object is generally used in STL to work with algorithms to achieve some specific functions. In other words, these function objects are mainly used to serve algorithms.

(1) Custom function object
bool myCompare(int a, int b) {
return (a > b);
}
int main() {
std::vector<int> v = {1, 5, 2, 4, 3};
std::sort(v.begin(), v.end(), myCompare);
}(2) Function objects defined in the standard library
In addition to the function objects written by yourself, the standard library also provides many function objects that can be used ready-made. Function object classification: arithmetic operation class, relational operation class, logical operation class, bit operation class.
#include <functional>



std::cout << std::plus<int>()(3, 5) << std::endl;- plus <int> is an instantiated class.
- Adding a parentheses after the class name, that is, "plus<int>()" means generating a temporary object of class plus<int> (because operator() is overloaded in plus, this temporary object is a callable object).
- In order to call this callable object, add parentheses () after the temporary object. Then, whatever parameters are in operator() of the plus class template, there must be what parameters are in the parentheses. (Two parameters are required in operator() of the plus class template.)