In the field of large language models (LLM), there are multiple training mechanisms with different means, requirements and goals. Since they serve different purposes, it is important not to confuse them with each other and to understand the different scenarios in which they are suitable.
In this article I would like to outline some of the most important training mechanisms, includingpre-training, Fine-tuning, Reinforcement Learning with Human Feedback (RLHF), and Adaptersthat bridges the gap between prompts and actual training. prompting The concept of adjustmentsthe role of prompting, which itself is not considered a learning mechanism, and clarify In addition, I will discuss .
pre-training

Pretraining is the most basic form of training, the same as you know in other areas of machine learning. Here you start with an untrained model (i.e. a model with randomly initialized weights) and train to predict the next token given a sequence of previous tokens. To do this, a large number of sentences are collected from various sources and fed to the model in small chunks.
The training model used here is calledself-supervision. From the perspective of the model being trained, we can say that it is a supervised learning method because the model always gets the correct answer after making a prediction. For example, given the sequence"I like ice"...the model might predict"cones"during the learning process. as label, this does not require human intervention. Although this is not the model itself, it is still performed automatically by the machine, hence the idea of AI self-supervisingcream" as input, ""I like ice ", we can automatically split it into "I like ice cream") Yes, the tags do not need to be collected through an expensive process up front, but they are already included in the data. Given the sentence supervisionsupervision (rather than simple self. Eventually, the loss can be calculated and the model weights adjusted to better predict the next time. Reasons for calling it cream" as the next word, and then may be told that the answer is wrong because the actual next word is "
Eventually, by training on large amounts of text, the model learns to encode general language structures (e.g., it learns, I like It can be followed by a noun or participle) and the knowledge contained in the text. saw. For example, it is understood that "Joe Biden is..." This sentence is often followed by President of the United States< /span>, thus represents this knowledge.
Others have already done this pre-training, and you can use out-of-the-box models like GPT. But why train a similar model? If the data you are working with has language-like properties, but is not a universal language itself, then training the model from scratch becomes necessary. Musical score is an example, it is structured a bit like language. There are certain rules and patterns about which parts follow each other, but an LLM trained in natural language cannot handle this kind of data, so you have to train a new model. However, due to the many similarities between musical notation and natural language, the structure of an LLM may be suitable.
fine-tuning

Although pretrained LLM is capable of performing a wide variety of tasks due to the knowledge it encodes, it has two major drawbacks, namely the structure of its output and the lack of knowledge not encoded in the data in the first place.
As you know, LLM always predicts the next token based on the sequence of tokens given before. It might be fine for continuing a given story, but in other cases it's not what you want. If you need a different output structure, there are two main ways to do it. You can write the hints in such a way that the model's lazy ability to predict the next token solves your task (this is called hint engineering), or You can change the output of the last layer so that it reflects your task, just like you would in any other machine learning model. Consider a classification task withN classes. With just-in-time engineering, you can instruct the model to always output a classification label given an input. With fine-tuning, you change the last layer to have N output neurons and derive the predicted class from the neuron with the highest activation.
Another limitation of LLM is its training data. Since the data sources are quite rich, the most famous LL.M. encodes a large amount of common knowledge. So they can tell you about the presidents of the United States, Beethoven's major works, the basics of quantum physics, and Sigmund Freud's major theories. However, there are some areas that the model does not understand, and fine-tuning may be relevant to you if you need to use these areas.
The idea of fine-tuning is to take an already pre-trained model and continue training with different data, changing only the weights of the last layer during training. This requires only a fraction of the resources required for initial training and therefore can be performed much faster. On the other hand, the structure learned by the model during pre-training is still encoded in the first layer and can be exploited. Let's say you want to teach a model about your favorite but little-known fantasy novel that isn't yet part of the training data. With fine-tuning, you can leverage your model's knowledge of natural language to allow it to understand new areas of fantasy fiction.
RLHF fine-tuning

A special case of fine-tuning models is reinforcement learning with human feedback (RLHF), which is one of the main differences between GPT models and chatbots like Chat-GPT. Through this fine-tuning, the model is trained to produce output that is most useful to humans in conversation with the model.
The main idea is as follows: given an arbitrary prompt, generate multiple outputs of the model for that prompt. People rank these outputs based on their perceived usefulness or appropriateness. Given four samples A, B, C, and D, one might think that C is the best output, B is slightly worse but equal to D, and A is the worst output for this prompt. This results in the order C > B = D > A. Next, this data is used to train the reward model. This is a completely new model that learns to score the output of LL.M.s by giving rewards that reflect human preferences. Once the reward model is trained, it can replace humans in the product. Now, the output of the model is rated by a reward model, and this reward is provided as feedback to the LLM, which is then adjusted to maximize the reward; very similar to the idea of GANs.
As you can see, this training requires human-labeled data, which requires considerable effort. However, the amount of data required is limited, as the idea of the reward model is to generalize from this data so that it can score the llm on its own once it understands its own part. RLHF is often used to make LLM output more conversational or to avoid undesirable behavior, such as models being mean, intrusive, or insulting.
Adapters
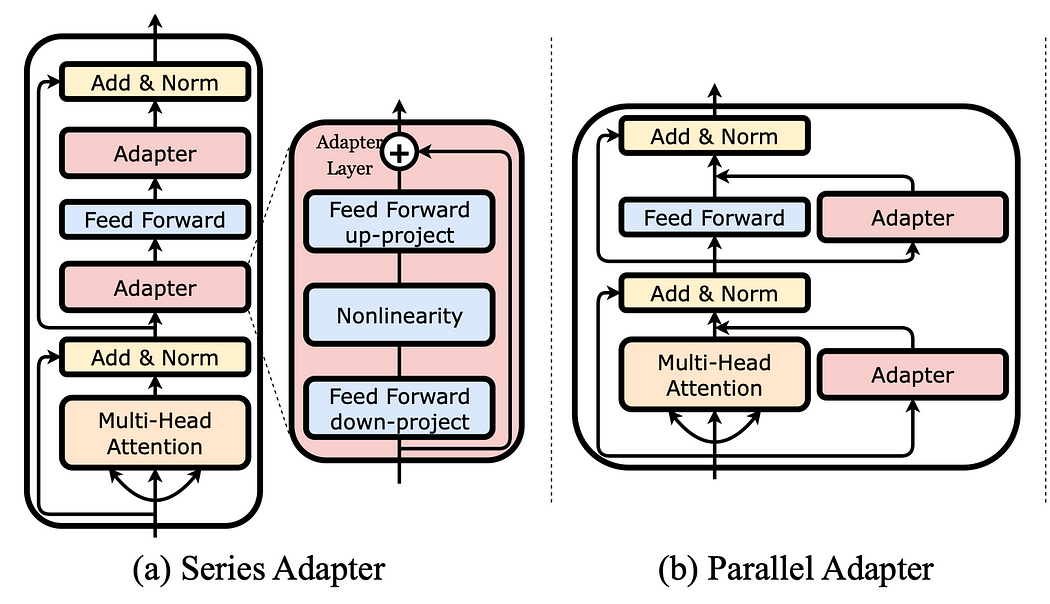
Both adapters plug into existing networks. Image taken fromhttps://arxiv.org/pdf/2304.01933.pdf.
In the previously mentioned fine-tuning, we adjusted some parameters of the model in the last layer, while other parameters in the previous layers remained unchanged. However, there is an alternative that guarantees greater efficiency with a smaller number of parameters required for training, which are called dapters.
Using adapters means adding additional layers to an already trained model. During fine-tuning, only those adapters are trained, while the remaining parameters of the model are not changed at all. However, these layers are much smaller than the ones that come with the model, which makes it easier to adjust them. Additionally, they can be inserted at different locations in the model, not just at the end. In the image above you can see two examples; one where adapters are added serially as a layer, and one where adapters are added in parallel to an existing layer.
Prompting

You might be wondering if hints count as another way of training the model. Hinting means building the instructions before the actual model input, especially if you use few-shot hinting, you can provide examples to the LLM in the hint, much like training, training also consists of examples presented to the model. Model. However, there are reasons why cues are different from training models. First, from a simple definition, we are only talking about training when the weights are updated, not during prompting. When you create a prompt, you do not change any models, you do not change the weights, you do not generate a new model, and you do not change the knowledge or representation encoded in the model. Prompts should be seen as a way to guide the LLM and tell it what you want to get out of it. Take the following tips as an example:
"""Classify a given text regarding its sentiment.
Text: I like ice cream.
Sentiment: negative
Text: I really hate the new AirPods.
Sentiment: positive
Text: Donald is the biggest jerk on earth. I hate him so much!
Sentiment: neutral
Text: {user_input}
Sentiment:"""I instructed the model to do sentiment classification, and you may have noticed that the examples I gave the model were all wrong! If you train a model using such data, it will confuse positive, negative andneutral tags. What happens now if I ask the model to classify the sentence "I like ice cream" in my example? Interestingly, it classifies it as Positive, which is the opposite of prompting, but is semantically correct of. This is because prompting does not train the model and does not change its representation of what it has learned. The hint just tells the model the structure I expect, i.e. I expect the sentiment label (can be Positive, Negative) follows the colon. Neutral or
Prompt tuning

Although prompts themselves are not training for llm, there is a method called cue tuning (also known as < a i=3>soft prompt) mechanism, which is related to prompts and can be regarded as a kind of training.
In the previous example, we considered the prompt as natural language text given to the model to tell the model what to do, and that preceded the actual input. That is, the model input becomes<prompt><instance>, so for example< label the following a positive, negative, or middle:> <I like Ice Cream> ;. When we create a prompt ourselves, we call it a hard prompt. In soft prompt, the format of <prompt><instance> will be retained, but the prompt itself is not designed by ourselves, but through data educational. Specifically, hints are composed of parameters in a vector space, and these parameters can be tuned during training to obtain smaller losses and thus better answers. That is, after training, the prompt will be the sequence of characters that yields the best answer for the given data. However, the model parameters are not trained at all.
One of the great things about cue tuning is that you can train multiple cues for different tasks but still use them with the same model. Just like in hard prompts, you can build a prompt for text summarization, a prompt for sentiment analysis, and a prompt for text classification, but all prompts use the same model that you can adapt for this purpose Three tips, but still using the same model. In contrast, if you use fine-tuning, you end up with three models, each serving only its specific task.
generalize
We just saw a variety of different training mechanisms, so let's give a brief summary at the end.
- Pre-training the LLM means teaching it to predict the next token in a self-supervised manner.
- Fine-tuning is adjusting the weights of the pre-trained LLM in the last layer and can be used to adapt the model to a specific context.
- RLHF aims to adjust the model's behavior to match human expectations and requires additional labeling work.
- Adapters allow for a more efficient way of fine-tuning due to the small layers added to the pre-trained LLM.
- The hint itself is not considered training as it does not change the model's internal representation.
- Hint tuning is a technique for adjusting weights that produces hints but does not affect the model weights themselves.
Of course, there are many more training mechanisms out there, and new ones are being invented every day. LL.M.s can do more than just predict text, and teaching them to do so requires a variety of skills and techniques, some of which I've just introduced to you.
further reading
Instruct-GPT is one of the most famous examples of RLHF:
An overview of common adapter forms can be found in the LLM-Adapters project:
Some good explanations on tip tuning can be found here: