Generative Adversarial Network GAN
1. Network as Generator
The input is no longer just x, there is a simple distribution (sample distribution), and the output is also a distribution
Why distribution
Different distributions mean:The same input will have different output.
Distribution is needed especially when the task requires creativity
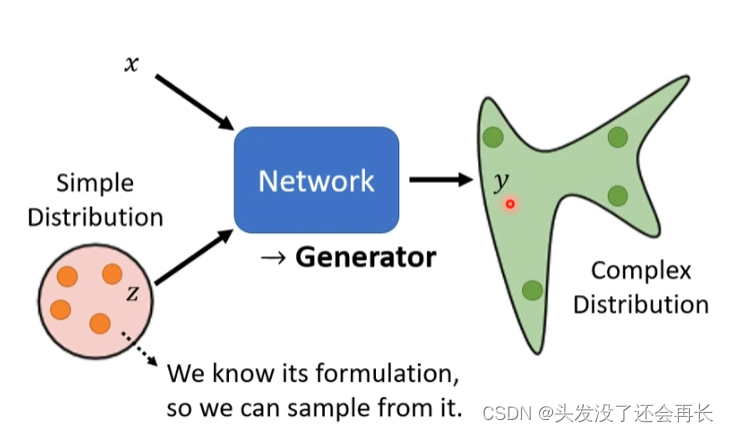
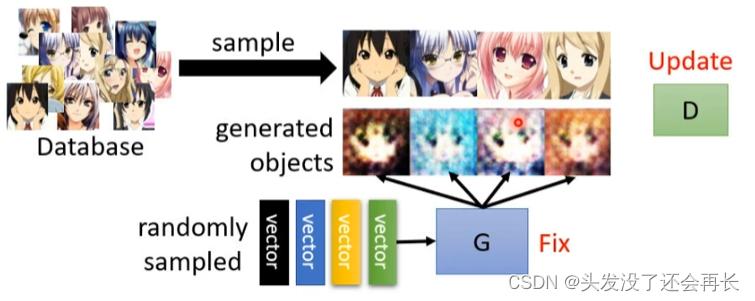
2. Anime Face Generation
2.1 Unconditional generation(No import)
Input one
Assume z is a vector sampled from the normal distribution, and the output y is the face of the two-dimensional task. Generating a picture is actually generating a very high-dimensional vector. Different of z, the output is the face of the secondary character.
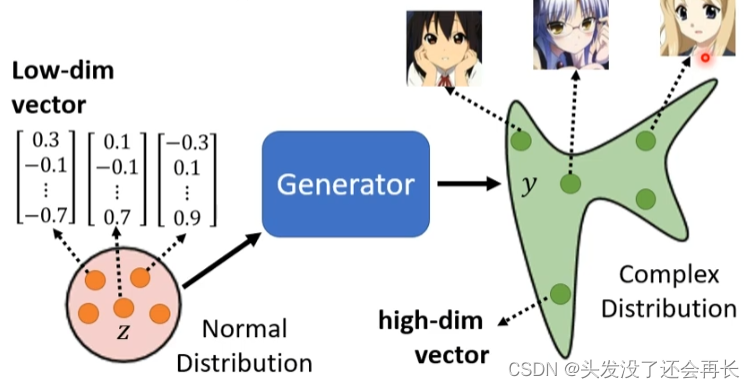
2.2 Discriminator
The larger the scaler, the more like the real image of the two-dimensional task.
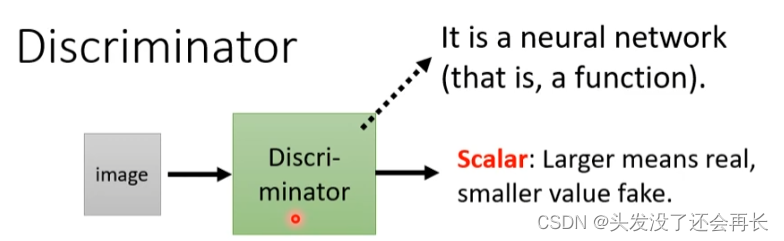
2.3 Basic idea of GAN
About generator and discriminator, they seem to promote each other
In the process of generating the face of the secondary character:
The parameters of the initial generator It is random. The generated image will be thrown to the discriminator. The discriminator compares the image generated by the generator with the real image to determine whether it is generated. Then the generator will evolve. The goal of evolution is to deceive the discriminator.
The second-generation generator will generate another set of images, and then hand them over to the second-generation discriminator for judgment, and the cycle repeats until the training is stopped.
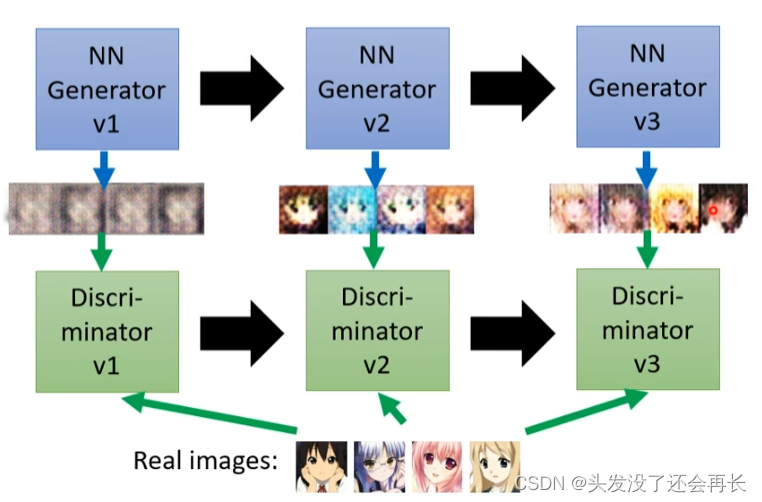
2.4 Algorithm
- Initialize one
generatorand onediscriminator - Under each training step
- Fix generator G and update discriminator D. After using the generator to generate some pictures, compare them with real samples to train a discriminator. The goal of D is to distinguish the difference between real two-dimensional tasks and the two-dimensional characters generated by G . For D, the real label can be marked as 1, and the generated label can be marked as 2. In this case, it can be regarded as a , train a classifier, and output the label of the image. Or think of it as, mark the real label as 1, mark the generated label as 0, and let D learn to distinguish it.
分类问题regression的问题
- Fix discriminator D and train generator G. The purpose of training is to let Generator deceive Discriminator, that is, to make the output value of Discriminator as large as possible. Throw the input z into G, G generates a picture (high-dimensional vector), throw the picture into D, D outputs a score, fix the parameters of D to train G , the bigger the output of D, the better. The connection of G and D can actually be regarded as a large network, but there is the output of a high-dimensional vector in the middle. The dimensions of this vector and the image are identical. The training method is no different from the training of other networks.
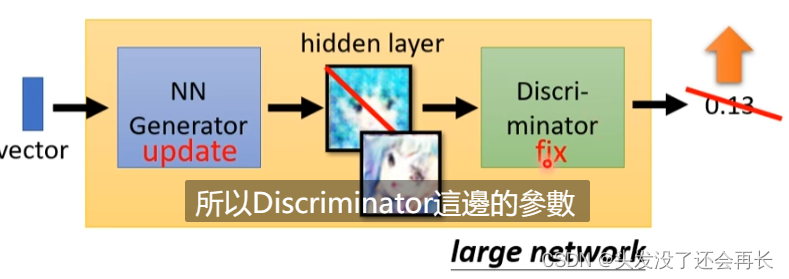
- Then fix G, train D, and repeat the above two steps until you get satisfactory results and stop training.
- Fix generator G and update discriminator D. After using the generator to generate some pictures, compare them with real samples to train a discriminator. The goal of D is to distinguish the difference between real two-dimensional tasks and the two-dimensional characters generated by G . For D, the real label can be marked as 1, and the generated label can be marked as 2. In this case, it can be regarded as a , train a classifier, and output the label of the image. Or think of it as, mark the real label as 1, mark the generated label as 0, and let D learn to distinguish it.
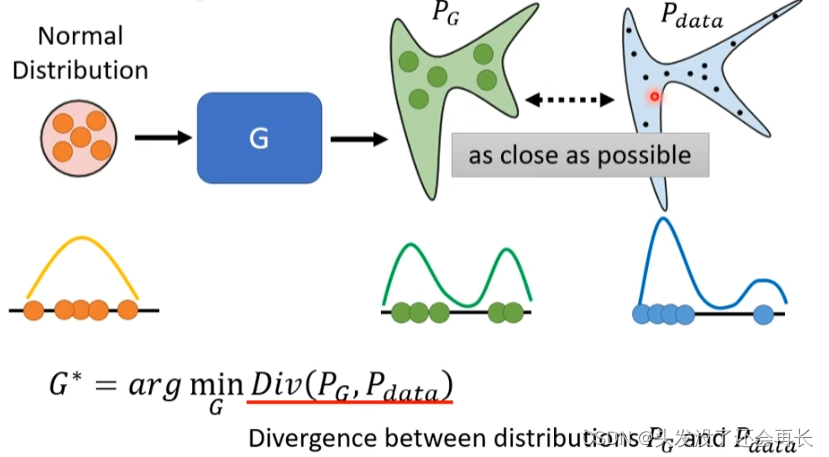
3. Our Objective
PG is the distribution of pictures generated by Generator, and Pdata is the distribution of real data. We hope that the divergence between PG and Pdata is as small as possible. This divergence is a certain distance between PG and Pdata.
3.1 How to calculate divergence?
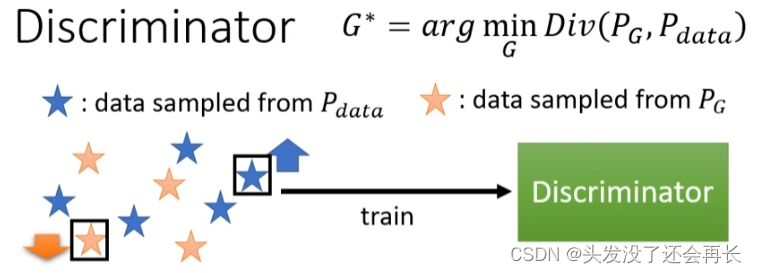
In GAN, only sample is enough
We cansample Pdata from the pictures in the real database< a i=3>, you can also sample PG from G
and then useDiscriminatoris enough
In Discriminator, there arePdataandPGfor training, if it is Pdata, give the higher one Score, if it is PG, give a low score , the formula is as follows:
We hopeVthat the bigger the better, then< /span> So Div(PG, Pdata) can be replaced by maxV(D, G), and we have the following formulaDyThe bigger the better, so the data from the real data sample is given a higher score, and vice versa for PG.
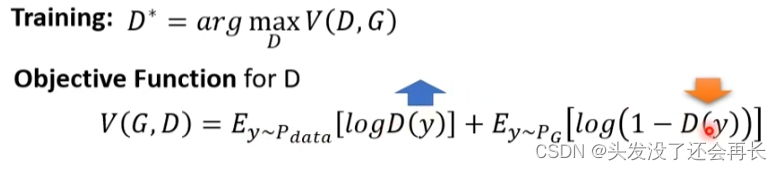

4. Some techniques for training GAN
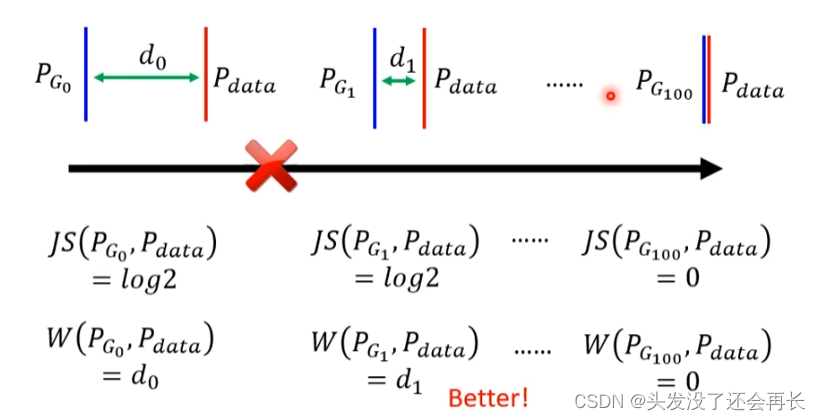
4.1 JS divergence is not suitable
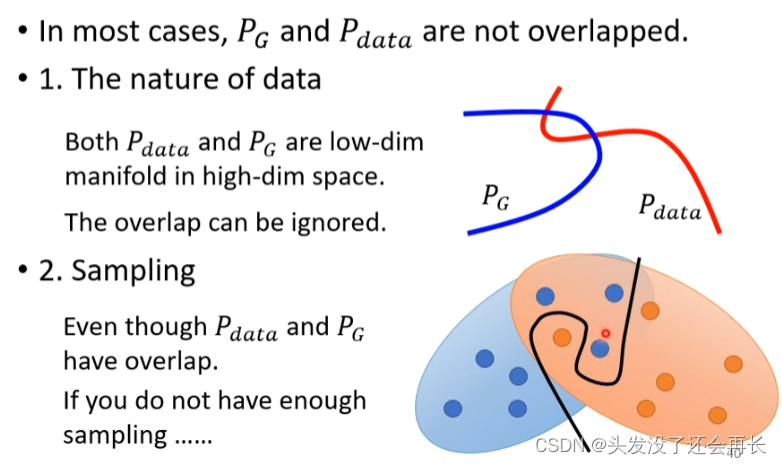
In most cases,PG and Pdata cannot overlap
In this case, the calculated JS divergence is log2.< /span>

4.2 Wasserstein distance
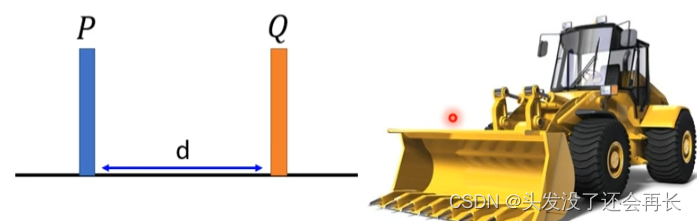
Okay, in the picture below, imagine P as a pile of soil, and Q as the destination of the pile of soil. You need to push P to Q (the shape remains the same), and the pushing distance d represents the wasserstein distance
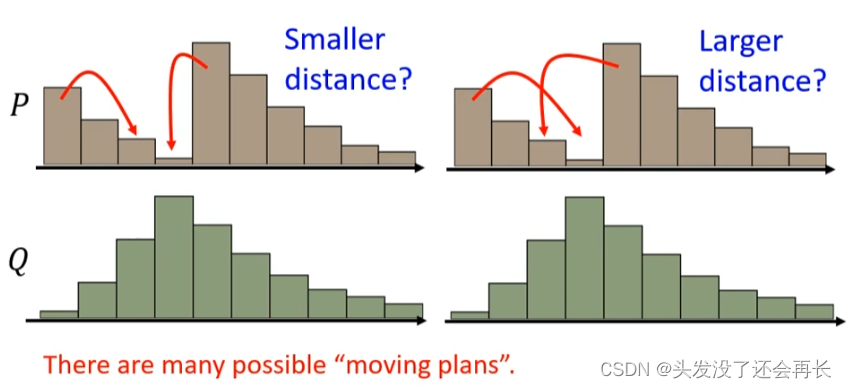
But if P and Q are more complicated, then some processing is required before they can be moved. Let’s exhaust all the ways to turn P into Q. The one with the smallest distance is the wasserstein distance.
So instead ofwasserstein distance, we can know whether G is doing better and better
4.3 WAGAN
UseWseeerstein distanceEvaluatethe distance between Pdata and PG
