Index optimization and query optimization
Which dimensions can be used for database tuning?
- The index is invalid and the index is not fully utilized - one index creation
- There are too many JOINs in related queries (design defects or last resort requirements) --SQL optimization
- Server tuning and various parameter settings (buffering, number of threads, etc.) – adjust my.cnf
- Too much data – sub-database and sub-table
Knowledge points about database tuning are very scattered. Different DBMS, different companies, different positions, and different projects encounter different problems
. Here we divide it into three chapters to explain in detail.
Although there are many techniques for SQL query optimization, they can be divided into physical query optimization and Logical query optimization Two big blocks.
- Physical query optimization is throughindex and table connection method Wait for other technologies to optimize. The key here is to master the use of indexes.
- Logical query optimization is to improve query efficiency through SOL Equivalent transformation. To put it bluntly, it is possible to improve the execution efficiency by changing the query writing method. Higher
1. Index failure case
One of the most effective ways to improve performance in MySQL is to design reasonable indexes on the data table. Indexes provide efficient access to data and speed up queries, so indexes have a crucial impact on query speed.
- Indexes can be used to quickly locate a record in the table, thereby increasing the speed of database queries and improving database performance.
- If no index is used during the query, the query statement will scan all records in the table. In the case of large amounts of data, the query speed will be very slow.
In most cases (by default) B+ trees are used to build indexes. Only the spatial column type index uses R-tree, and the MEMORY table also supports hash index
In fact, the optimizer has the final say whether to use an index or not. What is the optimizer based on? Based on cost overhead (CostBaseOptimizer), it is not based on rules (Rule-BasedOptimizer), nor is it based on semantics. Whatever comes with a low cost. In addition, whether the SQL statement uses an index is related to the database version, data volume, and data selectivity.
Explanation:
SQL_NO_CACHEis a query hint (Query Hint) in MySQL, which is used to tell MySQL not to cache the results of the query when querying. Usually, MySQL will use query cache in query results to improve performance. If the same query result already exists in the query cache, MySQL will directly return the results in the cache without performing the actual query operation.
1.0 Data preparation
#1. 数据准备CREATE DATABASE atguigudb2;USE atguigudb2;#建表
CREATE TABLE `class`
(
`id` INT(11) NOT NULL AUTO_INCREMENT,
`className` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
`monitor` INT NULL,
PRIMARY KEY (`id`)
) ENGINE = INNODB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8;
CREATE TABLE `student`
(
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stuno` INT NOT NULL,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`classId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
# CONSTRAINT `fk_class_id` FOREIGN KEY (`classId`) REFERENCES `t_class` (`id`)
) ENGINE = INNODB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8;
SET GLOBAL log_bin_trust_function_creators = 1;
#随机产生字符串
DELIMITER //
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n
DO
SET return_str = CONCAT(return_str, SUBSTRING(chars_str, FLOOR(1 + RAND() * 52), 1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER ;
# 用于随机产生多少到多少的编号
DELIMITER //
CREATE FUNCTION rand_num(from_num INT, to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num + RAND() * (to_num - from_num + 1));
RETURN i;
END //
DELIMITER ;
# 创建往stu表中插入数据的存储过程
DELIMITER //
CREATE PROCEDURE insert_stu(START INT, max_num INT)
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0; #设置手动提交事务REPEAT
REPEAT
#循环
SET i = i + 1; #赋值
INSERT INTO student (stuno, NAME, age, classId) VALUES ((START + i), rand_string(6), rand_num(1, 50), rand_num(1, 1000));
UNTIL i = max_num END REPEAT;
COMMIT; #提交事务
END //
DELIMITER ;
# 执行存储过程,往class表添加随机数据
DELIMITER //
CREATE PROCEDURE `insert_class`(max_num INT)
BEGIN
DECLARE i INT DEFAULT 0; SET autocommit = 0;
REPEAT
SET i = i + 1; INSERT INTO class (classname, address, monitor) VALUES (rand_string(8), rand_string(10), rand_num(1, 100000));
UNTIL i = max_num END REPEAT;
COMMIT;
END //
DELIMITER ;
# 执行存储过程,往class表添加1万条数据
CALL insert_class(10000);
# 执行存储过程,往stu表添加50万条数据
CALL insert_stu(100000, 500000);
SELECT COUNT(*)
FROM class;
SELECT COUNT(*)
FROM student;
# 删除某表上的索引 存储过程
DELIMITER //
CREATE PROCEDURE `proc_drop_index`(dbname VARCHAR(200), tablename VARCHAR(200))
BEGIN
DECLARE done INT DEFAULT 0;DECLARE ct INT DEFAULT 0;DECLARE _index VARCHAR(200) DEFAULT '';
DECLARE _cur CURSOR FOR SELECT index_name
FROM information_schema.STATISTICS
WHERE table_schema = dbname AND table_name = tablename AND seq_in_index = 1 AND index_name <> 'PRIMARY';
#每个游标必须使用不同的declare continue handler for not found set done=1来控制游标的结束DECLARE CONTINUE HANDLER FOR NOT FOUND SET done=2 ;
#若没有数据返回,程序继续,并将变量done设为2OPEN _cur;FETCH _cur INTO _index;WHILE _index<>'' DO SET @str = CONCAT("drop index " , _index , " on " , tablename ); PREPARE sql_str FROM @str ;EXECUTE sql_str;DEALLOCATE PREPARE sql_str;SET _index=''; FETCH _cur INTO _index; END WHILE;CLOSE _cur;
END //
DELIMITER ;
# 执行存储过程
CALL proc_drop_index("atguigu2", "student");
2.1 Full value matching
# 创建索引前后
# 145 ms (execution: 126 ms, fetching: 19 ms)
# 76 ms (execution: 34 ms, fetching: 42 ms)
SELECT SQL_NO_CACHE *
FROM student
WHERE age = 30
AND classId = 4
AND name = 'abcd';
CREATE INDEX idx_age ON student (age);
Create another index and discover the joint index used
CREATE INDEX idx_age_classId ON student(age, classId);
EXPLAIN SELECT SQL_NO_CACHE *
FROM student
WHERE age = 30
AND classId = 4
AND name = 'abcd';
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | student | null | ref | idx_age_classId | idx_age_classId | 10 | const,const | 12 | 10 | Using where |
Continue to create a joint index for these three fields and discover the three joint indexes used.
CREATE INDEX idx_age_classId_name ON student(age, classId, name);
2.2 Best left prefix rule (joint index)
When MySQL builds a joint index, it will abide by the best left prefix matching principle, that is, leftmost first. When retrieving data, matching starts from the leftmost of the joint index;
# 使用idx_age_classId索引 顺序一致
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name='abcd';
# 没用上索引 因为没有classid开头顺序的索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.classid=1 AND student.name='abcd';
Delete the first two indexes and retain student(age, classId, name);
It was found that although the index was used, key_len=5, indicating that only part of the age field of the joint index was used (int4 bytes + 1null)
First, take the classid of the query condition and match it in the first column of the index, but there is no result, and then take the age match to find the available index.
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.classid=1 AND age=30 AND student.name='abcd';
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | student | null | ref | idx_age_classId,idx_age_classId_name | idx_age_classId_name | 73 | const,const,const | 1 | 100 | null |
This way the index is not used at all:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.classid=1 AND student.name='abcd';
First taking the classid of the query condition and matching it with the first column of the index has no result, and then taking the name to match it still has no result because the index only exists for the one starting with age.
Conclusion: MySQL can create indexes for multiple fields, and an index can include 16 fields. For multi-column indexes, the filter conditions to use the index must be met in the order in which the index is created. Once a field is skipped, the fields behind the index cannot be used. If the first field among these fields is not used in the query condition, the multi-column (or joint) index will not be used.
Alibaba "Java Development Manual": The index file has the leftmost prefix matching feature of B-Tree. If the value on the left is not determined, then this index cannot be used.
2.3 Primary key insertion order
For a table using the InnoDB storage engine, when we do not explicitly create an index, the data in the table is actually stored in the leaf nodes of the clustered index. The records are stored in the data page, and the data pages and records are sorted according to the primary key value of the record from small to large. Therefore, if the primary key value of the record we insert increases in sequence, then every time we insert When one data page is full, switch to the next data page and continue inserting. If the primary key information we insert is suddenly large or small, it will be more troublesome. Suppose the records stored in a certain data page are full, and the primary key value stored in it is Between 1~100
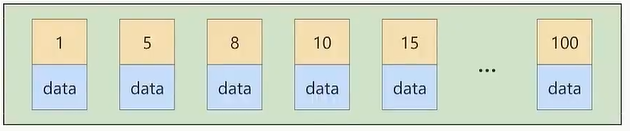
If another record with a primary key value of 9 is inserted at this time, its insertion position will be as shown below:
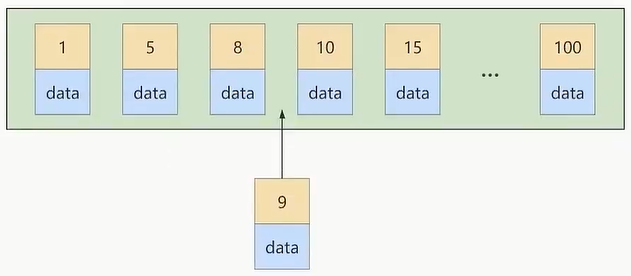
But this data page is already full, what should I do if I insert it again? We need to split the current page into two pages and move some records in this page to the newly created page. What do page splits and record shifts mean? Meaning: performance loss! So if we want to avoid such unnecessary performance loss as much as possible, it is best to increase the primary key value of the inserted record in sequence, so that such performance loss will not occur. So we suggest: let the primary key have AUTO_INCREMENT, and let the storage engine generate the primary key for the table by itself instead of manually inserting it, for example: person_info table:
CREATE TABLE person_info
(
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
birthday DATE NOT NULL,
phone_number CHAR(11) NOT NULL,
country varchar(100) NOT NULL,
PRIMARY KEY (id),
KEY idx_name_birthday_phone_number (name(10), birthday, phone_number)
);
The custom primary key column ID has the AUTO_INCREMENT attribute. When inserting a record, the storage engine will automatically fill in the auto-incremented primary key value for us. Such primary keys take up little space, are written sequentially, and reduce page splits.
2.4 Calculation and functions cause index failure
CREATE INDEX idx_name ON student(NAME);
# 可以使用上索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
# 无法使用索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
The first: Index optimization takes effect because secondary indexes can be used for matching. The second: Index optimization fails because a function is used, but for MySQL, it is not known what the function does, so the index cannot be used.
CREATE INDEX idx_sno ON student(stuno);
# 无法使用索引
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno+1 = 900001;
# 可以使用索引
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno = 900000;
2.5 Type conversion (automatic or manual) causes index failure
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name=123;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name='123';
Type conversion occurred in name=123 and the index became invalid.
Conclusion: When designing entity class attributes, they must correspond to database field types. Otherwise, type conversion will occur
1.6 The column index on the right side of the range condition is invalid
CREATE INDEX idx_age_cid_name ON student(age, classId, name);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.classId>20 AND student.name = 'abc';
key_len=10, age and classid are added together, there is no name
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | student | null | range | idx_age_cid_name | idx_age_cid_name | 10 | null | 18728 | 10 | Using index condition |
Columns to the right of the range cannot be used. For example: (<) (<=) (>) (>=) and between, etc.
If this kind of SQL occurs frequently, you should pay attention to the order of joint index creation and place the range query condition at the end of the statement:
CREATE INDEX idx_age_name_classid ON student(age, name, classid);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name = 'abc' AND student.classId>20;
Range queries in application development, such as amount queries and date queries, are often range queries. The query conditions should be placed at the end of the where statement.
1.7 Not equal to (!= or <>) index invalid
CREATE INDEX idx_name ON student(NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name <> 'abc';
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name != 'abc';
1.8 is null can use index, is not null cannot use index
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NULL;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NOT NULL;
It is best to set the fields to NOT NULL constraints when designing the data table. For example, you can set the default value of the INT type field to 0 and the default value of the character type to the empty string (‘’)
In the same way, using NOT LIKE in a query cannot use the index, resulting in a full table scan.
1.9 like index starting with wildcard character % is invalid
In the query statement using the LIKE keyword, if the first character of the matching string is "%", the index will not work. The index will only work if "%" is not in the first position
# 使用索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name LIKE 'ab%';
# 未使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name LIKE '%ab%';
Alibaba "Java Development Manual": [Mandatory] Left-fuzzy or full-fuzzy is strictly prohibited in page searches. If necessary, please use a search engine to solve the problem.
1.10 There are non-indexed columns before and after OR, and the index is invalid.
In the WHERE clause, if the condition column before the OR is indexed, but the condition column after the OR is not indexed, the index will be invalid. In other words, the index is only used in the query when the columns in the two conditions before and after OR are both indexes.
Because the meaning of OR is that as long as one of the two conditions is met, it is meaningless to index only one conditional column. As long as the conditional column is not indexed, a full table scan will be performed, so the indexed conditional column will also be invalid.
CREATE INDEX idx_age ON student(age);
# 因为classid字段没有索引,所以没有使用索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=10 OR classid=100;
# 因为age字段和name字段上都有索引,所以查询中使用了索引。
# 这里使用到了index_merge,简单说index_merge就是对age和name分别进行了扫描,然后将这两个结果集进行了合并。这样的好处就是避免了全表扫描
CREATE INDEX idx_name ON student(name);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=10 OR name= 'able';
1.11 The character sets of databases and tables use utf8mb4 uniformly.
The unified use of utf8mb4 (supported by version 5.5.3 or above) has better compatibility, and the unified character set can avoid garbled characters caused by character set conversion. Different character sets need to be converted before comparison, which will cause index failure.
1.12 General recommendations
For single-column indexes, try to choose an index with better filterability for the current query.
When selecting a combined index, the field with the best filterability in the current query should be placed earlier in the index field order, the better.
When choosing a combined index, try to choose an index that can include more fields in the where clause in the current query.
When selecting a combined index, if a certain field may appear in a range query, try to put this field at the end of the index order.
In short, when writing SQL statements, try to avoid causing index failure.
2. Related query optimization
2.0 Data preparation
CREATE TABLE IF NOT EXISTS type
(
id INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
card INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (id)
);
CREATE TABLE IF NOT EXISTS book
(
bookid INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
card INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (bookid)
);
# 20条
INSERT INTO type(card)
VALUES (FLOOR(1 + (RAND() * 20)));
# 20条
INSERT INTO book(card)
VALUES (FLOOR(1 + (RAND() * 20)));
2.1 Left outer join
There is no index type, all is all:
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | type | null | ALL | null | null | null | null | 20 | 100 | null |
| 1 | SIMPLE | book | null | ALL | null | null | null | null | 20 | 100 | Using where; Using join buffer (hash join) |
CREATE INDEX Y ON book (card);
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | type | null | ALL | null | null | null | null | 20 | 100 | null |
| 1 | SIMPLE | book | null | ref | AND | AND | 4 | atguigu2.type.card | 1 | 100 | Using index |
You can see that the type in the second line has changed to ref, and the rows have also become more obvious for optimization. This is determined by the left join property. The LEFT JOIN condition is used to determine how to search for rows from the right table. There must be all on the left, so the right is our key point and an index must be created;
2.2 Inner join
For inner joins, if only one field in the join condition of the table has an index, the indexed field will be used as the driven table.
For inner joins, when there are indexes in the connection conditions of both tables, the small table will be selected as the driving table - the small table drives the large table
CREATE INDEX Y ON book (card);
DROP INDEX Y ON book;
EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card = book.card;
CREATE INDEX X ON type (card);
DROP INDEX X ON type;
2.3 Principle of JOIN statement
JOIN method connects multiple tables, which is essentially a circular matching of data between tables. Before MySQL version 5.5, MySQL only supported one way of inter-table association, which was Nested Loop Join. If the amount of data in the associated table is large, the execution time of the join association will be very long. In versions after MySQL 5.5, MySQL optimizes nested execution by introducing the BNLJ algorithm.
(1) Driver table and driven table
- The driving table is the master table, and the driven table is the slave table and non-driven table.
- For inner joins
- SELECT * FROM A JOIN B ON …
- Does A have to be a driver table? Not necessarily, the optimizer will optimize based on your query statement and decide which table to check first. The table queried first is the driving table, and vice versa is the driven table. You can view it through the EXPLAIN keyword
- For outer joins
- SELECT FROM A LEFT JOIN B ON …
#或
SELECT FROM B RIGHT JOIN A ON … - It is usually considered that A is the driving table and B is the driven table. But not necessarily. The test is as follows:
CREATE TABLE a(f1 INT, f2 INT, INDEX(f1))ENGINE=INNODB;
CREATE TABLE b(f1 INT, f2 INT)ENGINE=INNODB;
INSERT INTO a VALUES(1,1),(2,2),(3,3),(4,4),(5,5),(6,6);
INSERT INTO b VALUES(3,3),(4,4),(5,5),(6,6),(7,7),(8,8);
# 测试1 使用了索引f1
EXPLAIN SELECT * FROM a LEFT JOIN b ON(a.f1=b.f1) WHERE (a.f2=b.f2);
# 测试2 没有使用索引
EXPLAIN SELECT * FROM a LEFT JOIN b ON(a.f1=b.f1) AND (a.f2=b.f2);
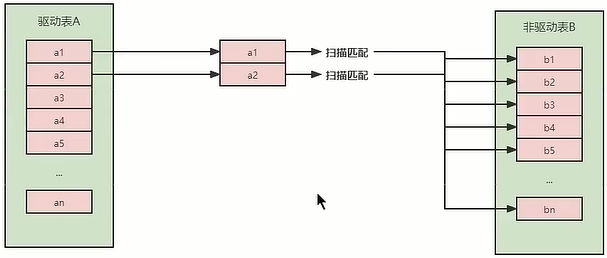
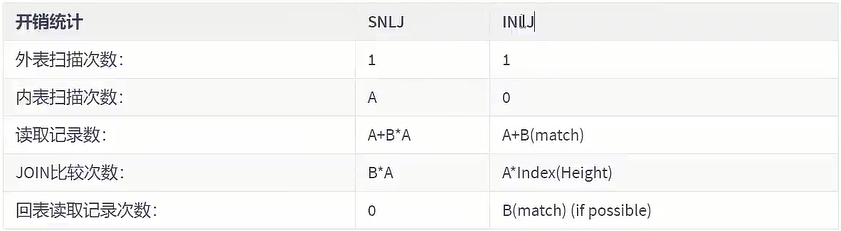
(2) Simple Nested-Loop Join (simple nested loop connection)
The algorithm is quite simple. Take a piece of data 1 from table A, traverse table B, and put the matching data into result...and so on. Each record in the driving table A is judged against the record in the driven table B.
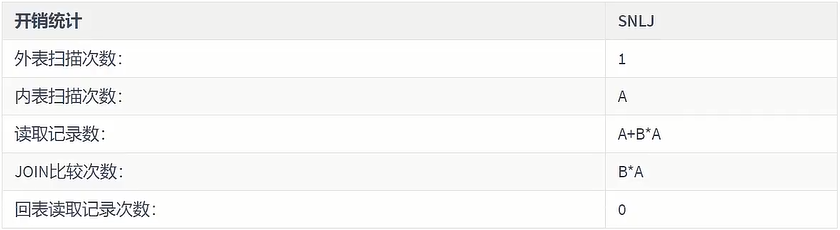
It can be seen that the efficiency of this method is very low. Calculated based on the above table A data of 100 items and table B data of 1000 items, then A*B=100,000 times. The cost statistics are as follows:
Of course, mysql will definitely not connect tables so roughly, so the following two optimization algorithms for Nested-Look Join appeared.
(3) Index Nested-Loop Join (index nested loop join)
The optimization idea of Index Nested-Loop Join is mainly to reduce the number of matches of inner table data, so the driven table must have an index. Directly match the inner table index through the outer table matching conditions to avoid comparing with each record of the inner table, which greatly reduces the number of matches to the inner table.
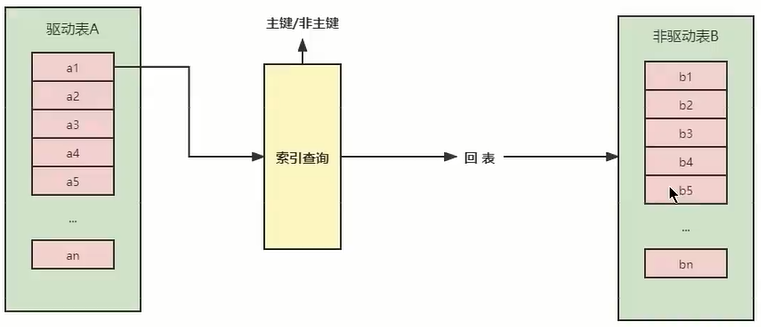
Each record in the driving table is accessed through the index of the driven table. Because the cost of index query is relatively fixed, the MySQL optimizer tends to use a table with a small number of records as the driving table (appearance).
If the driven table is indexed, the efficiency is very high, but if the index is not a primary key index, a table query must be performed. In comparison, the index of the driven table is a primary key index, which will be more efficient.
(4) Block Nested-Loop Join (block nested loop connection)
If an index exists, the index method will be used to join. If the join column does not have an index, the driven table will need to be scanned too many times. Every time the driven table is accessed, the records in the table will be loaded into the memory, and then a record is taken from the driver table to match it. After the match is completed, the memory is cleared, and then a record is loaded from the driver table, and then the driven table is loaded. The records in the table are then loaded into the memory for matching, which repeats itself, greatly increasing the number of IOs. In order to reduce the number of IOs of the driven table, the Block Nested-Loop Join method appeared.
It no longer obtains the data of the driver table one by one, but obtains it piece by piece. The join buffer is introduced, and some data columns related to the join of the driver table (the size is limited by the join buffer) are cached into the join buffer, and then the entire table is cached. Scan the driven table, and each record in the driven table is matched with all the driving table records in the join buffer at once (in-memory operation). Multiple comparisons in a simple nested loop are merged into one, which reduces the complexity of the driven table. Access frequency
Note: Not only the columns of the related table are cached here, but also the columns after SELECT are cached.
In a SQL with N join associations, N-1 join buffers will be allocated. Therefore, when querying, try to reduce unnecessary fields so that more columns can be stored in the join buffer.

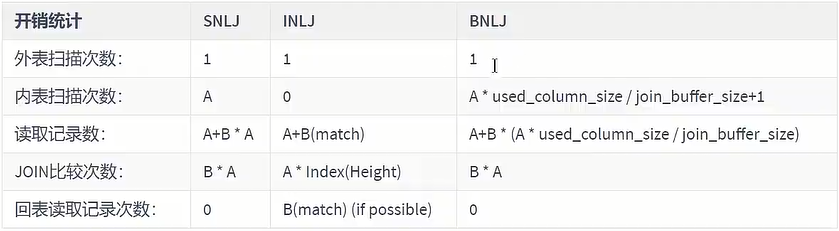
parameter settings:
block_nested_loop: Check the block_nested_loop status through show variables like ‘%optimizer_switch%’. It is enabled by default
join_buffer_size: Whether the driver table can be loaded at once depends on whether the join buffer can store all data. By default, join_buffer_size=256k
The maximum value of join_buffer_size can apply for 4G in 32-bit systems, and it can apply for Join Buffer space larger than 4G under 64-bit operating systems (except for 64-bit Windows, the maximum value will be truncated to 4G and a warning will be issued)
(5) Join summary
Overall efficiency comparison: INLJ>BNLJ>SNLJ
Always use small result sets to drive large result sets (the essence of which is to reduce the amount of data in the outer loop) (the small unit of measurement refers to the number of table rows * the size of each row)
SELECT t1.b, t2.* FROM t1 straight_join t2 ON (t1.b=t2.b) WHERE t2.id<=100; #推荐
SELECT t1.b, t2.* FROM t2 straight_join t1 ON (t1.b=t2.b) WHERE t2.id<=100; #不推荐
Add indexes to the conditions matched by the driven table (reduce the number of loop matches in the memory table)
Increase the join buffer size (the more data is cached at one time, the fewer times the inner package scans the table)
Reduce unnecessary field queries in the driver table (the fewer fields, the more data cached in the join buffer)
(6) Hash Join
BNLJ will be abandoned starting from MySQL version 8.0.20, because hash join has been added since MySQL version 8.0.18 and will use hash join by default.
Nested Loop: Nested Loop is a better choice when the subset of data to be connected is small.
Hash Join is a common way to join large data sets. The optimizer uses the smaller (relatively small) table of the two tables to use the Join Key to create a hash table in memory, and then scans the larger table and detects the hash table. Find rows matching Hash table
This method is suitable for situations where the smaller table can be completely placed in memory, so that the total cost is the sum of the costs of accessing the two tables.
When the table is very large and cannot be completely put into the memory, the optimizer will divide it into several different partitions. The part that cannot be put into the memory will be written into the temporary segment of the disk. This requires a relatively large amount of time. Large temporary segments to maximize I/O performance
It works well in environments with large tables without indexes and parallel queries, and provides the best performance. Most people say it's Join's heavy duty lift. Hash Join can only be applied to equivalent joins (such as WHERE A.COL1=B.COL2), which is determined by the characteristics of Hash

3. Subquery optimization
MySQL supports subqueries starting from version 4.1. You can use subqueries to perform nested queries of SELECT statements, that is, the results of one SELECT query serve as the conditions for another SELECT statement. Subqueries can complete many SQL operations that logically require multiple steps to complete in one go.
Subquery is an important feature of MySQL, which can help us implement more complex queries through a SQL statement. However, the execution efficiency of subqueries is not high. reason:
When executing a subquery, MySQL needs to create a temporary table for the query results of the inner query statement, and then the outer query statement queries records from the temporary table. After the query is completed, these temporary tables are revoked. This will consume too much CPU and IO resources and generate a large number of slow queries.
The temporary table stored in the subquery result set, whether it is a memory temporary table or a disk temporary table, will not have an index, so query performance will be affected to a certain extent.
For subqueries that return a larger result set, the impact on query performance will be greater. In MySQL, you can use join (JOIN) queries instead of subqueries. Join queries do not need to create temporary tables and are faster than subqueries. If indexes are used in the query, the performance will be better.
In MySQL, you can use join (JOIN) queries instead of subqueries. Join queries do not need to create temporary tables and are faster than subqueries. If indexes are used in the query, the performance will be better.
Example: Query the information of students who are monitors in the student table
Use a subquery to create an index for the monitor in the class table
CREATE INDEX idx_moniitor ON class (monitor);
EXPLAIN
SELECT *
FROM student stu1
WHERE stu1.`stuno` IN (SELECT monitor FROM class c WHERE monitor IS NOT NULL);
Recommendation: Use multi-table query
EXPLAIN SELECT stu1.* FROM student stu1 JOIN class c ON stu1.stuno = c.monitor WHERE c.monitor IS NOT NULL;
Example: Take all students who are not class presidents
# 不推荐
EXPLAIN
SELECT SQL_NO_CACHE a.*
FROM student a
WHERE a.stuno NOT IN (SELECT monitor FROM class b WHERE monitor IS NOT NULL);
# 推荐
EXPLAIN
SELECT SQL_NO_CACHE a.*
FROM student a
LEFT OUTER JOIN class b ON a.stuno = b.monitor
WHERE b.monitor IS NULL;
Conclusion: Try tonotuseNOT IN or < /span>, replace with LEFT JOIN xxx ON xx WHERE xx IS NULLNOT EXISTS
4. Sorting optimization
4.1 Sorting optimization
Question: Add an index on the WHERE condition field, but why do you need to add an index on the ORDER BY field?
Answer: In MySQL, two sorting methods are supported, namely FileSort and Index sorting.
- In Index sorting, the index can ensure the orderliness of the data, and there is no need to sort, which is more efficient.
- FileSort sorting is generally performed in memory, which takes up more CPU. If the results to be sorted are large, temporary file I/O will be sent to the disk for sorting, which is inefficient.
Optimization suggestions
- In SQL, you can use indexes in the WHERE clause and ORDER BY clause to avoid full table scans in the WHERE clause and to avoid using FileSort sorting in the ORDER BY clause. Of course, in some cases, full table scan or FileSort sorting is not necessarily slower than indexing. But in general, we still have to avoid it to improve query efficiency.
- Try to use Index to complete ORDER BY sorting. If WHERE and ORDER BY are followed by the same column, use a single index column; if they are different, use a joint index.
- When Index cannot be used, the FileSort method needs to be tuned
4.2 Testing
Delete student and class indexes
Can the index be used in the following, and can using filesort be removed?
Process 1: No index is used
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age, classid;
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age, classid LIMIT 10;
Process 2: Create an index, but there is no limit when ordering by, and the index becomes invalid.
CREATE INDEX idx_age_classid_name ON student(age,classid,NAME);
SELECT SQL_NO_CACHE * FROM student ORDER BY age, classid;Why is the index not used? In fact, when SQL is executed, the optimizer will consider the cost issue. Although there is an index, this index is a secondary index. Therefore, after sorting through the index, you need to return to the table to query all other column information. Simply sort directly in memory and find that it takes less time, so no index is used. (Note: It is not necessary to use an index in any case. The optimizer considers the time cost to select the optimal execution plan). If the sql is changed to SELECT SQL_NO_CACHE age, classid FROM student ORDER BY age, classid;, the upper index will be used. There is no need to return the table (covering the index) here
Process 3: The order is wrong when ordering by, and the index is invalid.
Create indexes age, classid, stuno. Which of the following indexes are invalid?
CREATE INDEX idx_age_classid_stuno ON student(age,classid,stuno);
# 失效
EXPLAIN SELECT * FROM student ORDER BY classid LIMIT 10;
# 失效
EXPLAIN SELECT * FROM student ORDER BY classid,NAME LIMIT 10;
# 有效
EXPLAIN SELECT * FROM student ORDER BY age,classid,stuno LIMIT 10;
# 有效
EXPLAIN SELECT * FROM student ORDER BY age,classid LIMIT 10;
# 有效
EXPLAIN SELECT * FROM student ORDER BY age LIMIT 10;
Process 4: The rules are inconsistent during order by and the index is invalid.
Wrong order, not indexed; reverse direction, not indexed
CREATE INDEX idx_age_classid_stuno ON student(age,classid,stuno);
# 失效 方向反
EXPLAIN SELECT * FROM student ORDER BY age DESC, classid ASC LIMIT 10;
# 失效 最左前缀法则
EXPLAIN SELECT * FROM student ORDER BY classid DESC, NAME DESC LIMIT 10;
# 失效 方向反
# 没有使用索引是因为,最后还要按照classid逆序,所以不如直接文件排序。
EXPLAIN SELECT * FROM student ORDER BY age ASC, classid DESC LIMIT 10;
# 有效
EXPLAIN SELECT * FROM student ORDER BY age DESC, classid DESC LIMIT 10;
Conclusion: In the ORDER BY clause, try to use index sorting and avoid using FileSort sorting.
Process 5: No filtering, no indexing
# 虽然使用了索引,但是key_len都是5,并没有使用到ORDER BY后面的,是因为经过WHERE的筛选剩下的数据不是太多,所以就没有使用
EXPLAIN SELECT * FROM student WHERE age=45 ORDER BY classid;
EXPLAIN SELECT * FROM student WHERE age=45 ORDER BY classid,name;
# 前者没有使用索引,后者使用了索引,前者是因为先进行排序的,再去过滤后,最后回表查询出所有的字段信息,花费的时间会更多。
# 后者因为只取前十条,其中索引排完序再筛选完后取前十条会更快一些
EXPLAIN SELECT * FROM student WHERE classid=45 ORDER BY age;
EXPLAIN SELECT * FROM student WHERE classid=45 ORDER BY age limit 10;
4.3 Summary
INDEX a_b_c(a,b,c)
order by 能使用索引最左前缀
- ORDER BY a
- ORDER BY a,b
- ORDER BY a,b,c
- ORDER BY a DESC, b DESC, c DESC
If WHERE uses the leftmost prefix of the index defined as a constant, order by can use the index
- WHERE a=const ORDER BY b,c
- WHERE a=const AND b=const ORDER BY c
- WHERE a=const ORDER BY b,c
- WHERE a=const AND b>const ORDER BY b,c
Cannot use index for sorting
- ORDER BY a ASC, b DESC, c DESC /Inconsistent ordering/
- WHERE g=const ORDER BY b,c /Lost a index/
- WHERE a=const ORDER BY c /Lost b index/
- WHERE a=const ORDER BY a,d /d is not part of the index/
- WHERE a in (…) ORDER BY b,c / For sorting, multiple equality conditions are also range queries/
4.4 filesort algorithm: two-way sorting and one-way sorting
In MySQL, when ORDER BY or GROUP BY operations are required, the filesort algorithm may be used. The filesort algorithm is used to sort the query result set to meet the requirements of the ORDER BY or GROUP BY clause. According to different scenarios and configurations, the filesort algorithm in MySQL is divided into two types: Two-Phase Sort and One-Phase Sort.
Two-Phase Sort:
Two-way sort is the default sorting algorithm that performs two sorting phases. First, MySQL will try to use the index to complete the sorting. If there is a suitable index to satisfy the ORDER BY or GROUP BY condition, then the sorting is completed with the help of the index. If the index cannot meet the sorting requirements, MySQL will use a two-way sort.
In a two-way sort, MySQL first attempts to use memory (sort_buffer) for sorting. If the memory required for sorting exceeds the sort_buffer setting, MySQL will use disk temporary files for sorting. In this way, two-way sorting uses two resources: memory and disk. Normally, two-way sorting is a more efficient sorting algorithm because it takes full advantage of memory and disk.
One-Phase Sort:
One-way sorting is a special sorting algorithm that only uses memory to complete sorting and does not involve temporary disk files. Single-way sorting usually occurs when the data that needs to be sorted is small. MySQL can ensure that all sorted data is sorted in the sort_buffer memory, thus avoiding the use of temporary disk files.
When the amount of data that needs to be sorted is small, MySQL will give priority to single-way sorting, because single-way sorting avoids disk I/O and is relatively fast. However, if the amount of sorted data is large and exceeds the sort_buffer setting, MySQL will fall back to two-way sorting.
In actual use, you can adjust the size of sort_buffer to affect whether MySQL chooses single-way sorting or dual-way sorting when sorting. If you want to force one-way sorting, you can set sort_buffer to a larger value, but this will also increase memory consumption. Taking into account the performance requirements of the query and the resources of the system, choosing an appropriate sorting algorithm and properly setting the sort_buffer is an important part of optimizing query performance.
5. GROUP BY optimization
- The principle of using index by group by is almost the same as that of order by. Even if the index is not used in group by, it can be used directly.
- group by sorts first and then groups, following the best left prefix rule for index construction
- When the index column cannot be used, increase the settings of the max_length_for_sort_data and sort_buffer_size parameters
- The efficiency of where is higher than that of having. If the conditions can be written in where, do not write them in having.
- Reduce the use of order by, and communicate with the business without sorting without sorting, or put the sorting in the program. Statements such as Order by, groupby, and distinct consume more CPU, and the CPU resources of the database are extremely precious.
- Contains query statements such as order by, group by, and distinct. The result set filtered by the where condition must be kept within 1,000 rows, otherwise SQL will be very slow.
6. Optimize paging queries
In general, when performing paging queries, the performance can be better improved by creating a covering index. A common and very troublesome problem is limit 2000000,10. At this time, MySQL needs to sort the first 2000010 records, and only returns 2000000-2000010 records. The other records are discarded. The cost of query sorting is very high.
EXPLAIN SELECT * FROM student LIMIT 2000000,10
Optimization idea one: Complete the sorting and paging operation on the index, and finally associate it back to other column contents required by the original table query based on the primary key.
EXPLAIN SELECT * FROM student t,(SELECT id FROM student ORDER BY id LIMIT 2000000,10) a WHERE t.id=a.id;
# 查根据name排序的分页,在name上创建索引查找id,再根据id找具体数据,避免了使用聚簇索引数据量大的问题
# 优化前 498 ms (execution: 465 ms, fetching: 33 ms)
SELECT *
FROM student s
ORDER BY name
limit 490000,10;
# 优化后95 ms (execution: 72 ms, fetching: 23 ms)
CREATE INDEX stu_name ON student(name);
WITH order_name (id) AS (select id from student ORDER BY name limit 490000,10)
SELECT *
FROM student s
INNER JOIN order_name o ON s.id = o.id;
Optimization idea 2: This solution is suitable for tables with auto-incrementing primary keys. It can convert limit queries into queries at a certain location.
EXPLAIN SELECT * FROM student WHERE id>2000000 LIMIT 10;
7. Prioritize covering indexes
7.1 When to overwrite an index
Understanding method one: Index is a way to find rows efficiently, but general databases can also use indexes to find data in a column, so it does not have to read the entire row. After all, index leaf nodes store the data they index; when the desired data can be obtained by reading the index, there is no need to read the rows. An index that contains data that satisfies the query result is called a covering index.
Understanding method two: A form of non-clustered composite index, which includes all columns used in the SELECT, JOIN and WHERE clauses in the query (that is, the fields used to build the index are exactly the fields involved in the query conditions).
To put it simply, the index column + primary key contains the columns queried between SELECT and FROM.
7.2 Pros and cons of covering indexes
benefit:
Avoid secondary query of Innodb table index (table return):
Innodb is stored in the order of clustered index. For Innodb, the secondary index saves the primary key information of the row in the leaf node. If the secondary index is used to query the data, after finding the corresponding key value, We also need to perform a secondary query through the primary key to obtain the data we actually need.
In a covering index, the required data can be obtained from the key values of the secondary index, avoiding secondary queries on the primary key, reducing IO operations, and improving query efficiency.
Random IO can be turned into sequential IO to speed up query efficiency (actually, the random IO when returning the table is cut off, leaving only the sequential IO for secondary index query)
Since the covering index is stored in the order of key values, for IO-intensive range searches, the IO required to read each row of data randomly from the disk is much less. Therefore, the covering index can also be used to store random data on the disk during access. Read IO is converted into sequential IO for index lookup
Since covering indexes can reduce the number of tree searches and significantly improve query performance, using covering indexes is a common performance optimization method.
Disadvantages: Maintenance of index fields always comes at a cost. Therefore, there are trade-offs to consider when building redundant indexes to support covering indexes. (Considered by DBA or data architect)
8. Add index to string
# 教师表
create table teacher
(
ID bigint unsigned primary key,
email varchar(64),
…
) engine = innodb;
The lecturer needs to use an email to log in, so a statement similar to this must appear in the business code:
select col1, col2 from teacher where email=’xxx’;
If there is no index on the email field, then this statement can only perform a full table scan.
Indexes can be created using string prefixes, see 3.2.8 for details:
https://blog.csdn.net/a2272062968/article/details/131917628
9. Index push down ICP
Index Condition Pushdown (ICP) is an optimization technology introduced in MySQL version 5.6, which can improve query performance in some cases. The main goal of ICP is to reduce the number of rows that MySQL needs to access the table when executing a query, thereby reducing IO operations and improving query efficiency.
In traditional query execution, MySQL first uses the index to perform conditional filtering, and then retrieves the corresponding row data from the table. ICP reduces actual access to the table by applying additional conditions of the query on the index. When MySQL finds that all conditions of the query can be satisfied directly through the index, ICP will stop row data access to the table, thus avoiding additional IO operations.
ICP is mainly suitable for composite indexes, that is, indexes containing multiple columns. ICP comes into play when all columns of the index are involved in the query and the conditions of the query can be calculated on the index.
The following are some advantages and applicable conditions of ICP:
advantage:
- The actual access to the table is reduced, thereby reducing IO operations and improving query performance.
- In some cases, the creation and use of temporary files and temporary tables for tables can be avoided.
Applicable conditions:
- The index involved in the query is a composite index and contains multiple columns.
- All columns of the index involved in the query must be used in the query, and the query conditions can be calculated on the index.
- The storage engine of the table supports ICP. Currently, the InnoDB and MyISAM storage engines support ICP.
ICP is an automatic optimization feature in MySQL and does not need to be explicitly enabled. When executing a query, MySQL's optimizer will automatically determine whether ICP can be used to optimize the query plan. For queries that are suitable for using composite indexes and meet ICP conditions, ICP will help improve query performance and reduce unnecessary IO operations, thereby speeding up query execution.
10. Ordinary index vs unique index
How to choose between ordinary index and unique index? In fact, there is no difference in query capabilities between these two types of indexes. The main consideration is the impact on update performance. Therefore, it is recommended that you try to choose ordinary indexes
In actual use, you will find that the combined use of ordinary indexes and change buffers is very obvious for updating and optimizing tables with large amounts of data.
If all updates are immediately followed by queries for this record, then you should close the change buffer. In other cases, change buffer can improve update performance
Since unique indexes cannot use the optimization mechanism of the change buffer, if the business can accept it, it is recommended to give priority to non-unique indexes from a performance perspective. But what should we do if "the business may not be guaranteed"?
- First, business correctness takes priority. Our premise is that "the business code has guaranteed not to write duplicate data" when discussing performance issues. If the business cannot guarantee this, or the business requires the database to make constraints, then you have no choice but to create a unique index. In this case, the significance of this section is to provide you with one more troubleshooting idea if you encounter a situation where inserting a large amount of data is slow and the memory hit rate is low.
- Then, in some "archive library" scenarios, you can consider using unique indexes. For example, online data only needs to be retained for half a year, and then historical data is stored in the archive. At this time, the archived data has ensured that there are no unique key conflicts. To improve archiving efficiency, you can consider changing the unique index in the table to a normal index.
11. Other query optimization strategies
11.1 The difference between EXISTS and IN
Question: I don’t quite understand in which case EXISTS is used, and in that case IN is used. Is the selection criterion based on whether the table's index can be used?
Answer: Indexing is a prerequisite. In fact, whether to choose it or not depends on the size of the table. The selection criteria can be understood as small tables driving large tables. In this way the efficiency is highest
For example:
SELECT * FROM A WHERE cc IN (SELECT cc FROM B)
SELECT * FROM A WHERE EXISTS (SELECT cc FROM B WHERE B.cc=A.cc)
When A is less than B, use EXISTS. Because the implementation of EXISTS is equivalent to an external loop, the implementation logic is similar to:
for i in A
for j in B
if j.cc == i.cc then …
Use IN when B is less than A, because the implementation logic is similar to:
for i in B
for j in A
if j.cc == i.cc then …
Whichever table is smaller will be used to drive it. If table A is smaller, EXISTS will be used. If table B is smaller, IN will be used.
11.2 COUNT(*) and COUNT (specific fields) efficiency
Question: There are three ways to count the number of rows in a data table in MYSQL: SELECT COUNT(*), SELECT COUNT(1), and SELECT COUNT (specific fields). What is the query efficiency between these three methods?
answer:
Premise: If you want to count the number of non-empty data rows in a certain field, it is a different matter. After all, the premise of comparing execution efficiency is that the results must be the same.
Link 1: COUNT(*) and COUNT(1) both count all results. There is essentially no difference between COUNT(*) and COUNT(1) (the execution time of the two may be slightly different, but they can still be combined The execution efficiency is regarded as equal). If there is a WHERE clause, all data that meets the filtering conditions will be counted; if there is no WHERE clause, the number of data rows in the data table will be counted.
Step 2: If it is a MyISAM storage engine, the number of rows in the statistical data table only requires O(1) complexity. This is because each MyISAM data table has a meta information that stores the row_count value, and the consistency is determined by the table. level lock to ensure. If it is an InnoDB storage engine, because InnoDB supports transactions and uses row-level locking and MVCC mechanisms, it cannot maintain a row_count variable like MyISAM. Therefore, it is necessary to scan the entire table and perform looping + counting to complete statistics.
Step 3: In the InnoDB engine, if COUNT (specific fields) is used to count the number of data rows, secondary indexes should be used as much as possible. Because the index used for the primary key is a clustered index, the clustered index contains a lot of information and is obviously larger than the secondary index (non-clustered index). For COUNT(*) and COUNT(1), they do not need to search for specific rows, but only count the number of rows. The system will automatically use a secondary index that takes up less space for statistics. If there are multiple secondary indexes, the secondary index with the smaller key_len will be used for scanning. When there is no secondary index, the primary key index will be used for statistics.
11.3 About SELECT(*)
In table queries, it is recommended to specify the fields. Do not use * as the field list of the query. It is recommended to use SELECT<Field List> query.
- During the parsing process, MySQL will query the data dictionary to convert * into all column names in order, which will greatly consume resources and time.
- Cannot use covering index
11.4 Impact of LIMIT 1 on optimization
It is aimed at SQL statements that will scan the entire table. If you can be sure that there is only one result set, then adding LIMIT 1 will not continue scanning when a result is found, which will speed up the query.
If the data table has established a unique index for the field, you can query through the index. If the entire table is not scanned, there is no need to add LIMIT 1.
11.5 Use COMMIT more
Whenever possible, use COMMIT in your program as much as possible, so that the performance of the program will be improved and the demand will be reduced due to the resources released by COMMIT.
Resources released by COMMIT:
- Information on the rollback segment used to recover data
- Lock acquired by program statement
- Space in redo / undo log buffer
- Manage internal spend in the above 3 resources