introduction
The SPP-Net network is a deep learning network structure. Its biggest feature is that it can accept input images of any size. Before SPPNet, most neural networks needed to input fixed-size images, which brought a lot of inconvenience to the detection of images of different sizes, because a series of operations such as scaling and cropping of images were required, which to a certain extent led to The loss and deformation of image information limits the accuracy of recognition.
Introduction to SPP-Net
SPP-Net是出自论文:《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》。
Before this, all neural networks needed to input fixed-size images, such as 224*224 (ImageNet), 32*32 (LenNet), 96*96, etc. In this way, when we want to detect pictures of various sizes, we need to go through a series of operations such as crop or warp, which will lead to the loss and deformation of picture information to a certain extent, limiting the recognition accuracy. Moreover, from a physiological point of view, when the human eye sees a picture, the brain will first think that it is a whole, and will not crop or warp, so it is more likely that our brain collects some shallow information and These arbitrary-shaped targets are recognized only at deeper levels.
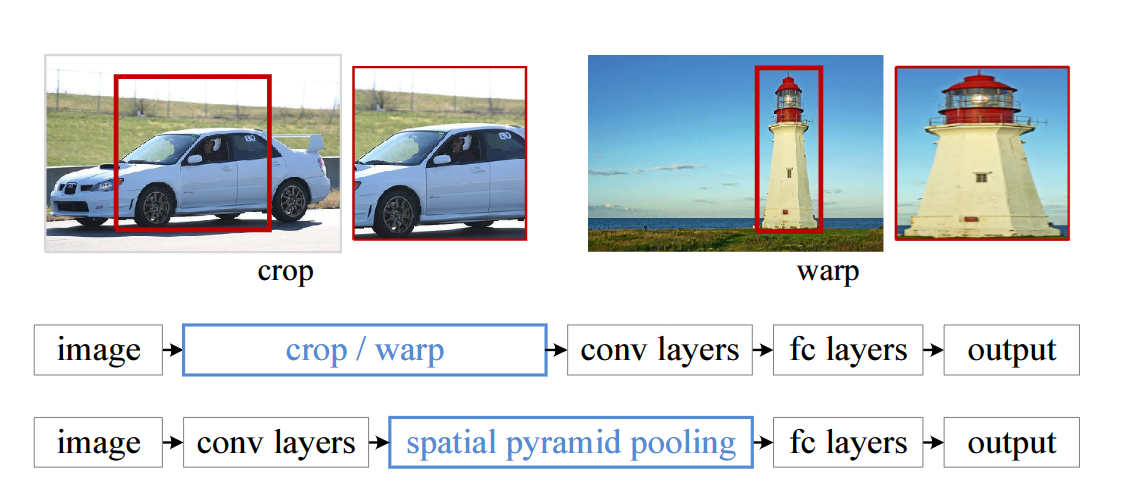
SPP-Net improves the shortcomings of these networks. The basic idea is to input the entire image, extract the feature map of the entire image, and then use the spatial relationship to extract the feature map of the entire image in the spatial pyramid pooling layer. Extract features of each region proposal. SPPNet uses the Spatial Pyramid Pooling (SPP) method. The main idea of this method is to divide the feature map obtained by passing the convolutional layer of a picture of any size into small blocks of different sizes, and then perform a pooling operation on each small block, so that a fixed-length output can be obtained. Solved the problem of variable input image size.
A normal deep network consists of two parts, the convolution part and the fully connected part. The reason why the input image needs to have a fixed size is not the convolution part but the fully connected part. Therefore, the SPP layer acts after the last layer of convolution, and the output of the SPP layer is a fixed size.
SPP-net not only allows the input of images of different sizes during testing, but also allows the input of images of different sizes during training. Overfit can be prevented at the same time through images of different scales. Compared with R-CNN extracting 2000 proposals, SPP-net only needs to throw the entire graph into it to obtain features, which increases the operation speed by about 100 times.
