[Serial port data analysis] Comparison of two parsing solutions in C language and Python (structure struct and class classes store data, structure nested Python representation method, long byte data storage and parsing: bytes type conversion to flout)
Article directory
Here, a serial port data protocol is used as an example. C language and Python are used for analysis respectively, and no third-party libraries are used to complete it.
C language uses structure struct to complete, while Python uses class class to complete
data protocol

Format description
Frame start: two bytes, fixed value 0x23 0x55.
Data field length: Two bytes, indicating the length of the data field.
Device address: two bytes, fixed value 0x52 0x07.
Data field: function code and data. Among them, the function code COM is one byte, and the data DATA is optional. See the function code definition for details.
Frame check: Two bytes, accumulated bit by bit, from the beginning of the frame to the end of the data.
End of frame: two bytes, fixed value 0x0D 0x0A.
The data field is in little-endian format, and the others are in big-endian format.
Structure definition
typedef struct
{
uint8_t START[2]; 起始位
uint8_t BCNT[2]; 数据长度,表示从ADDR字节的后一字节开始,到校验码的前一字节为止,数据的长度;也是命令位+数据位的长度。即BCNT=len(COM+DATA[])
uint8_t ADDR[2]; 地址位
uint8_t COM; 命令字节
uint8_t DATA[25]; 数据字节
uint8_t CHK[2]; 校验码 表示校验码前所有字节之和。
CHK=START0+START1+BCNT0+BCNT1+ADDR0+ADDR1+COM+DATA[]
uint8_t STOP[2]; 停止位
}GUI_Struct;
If the received data is:
23 55 00 04 52 07 01 AB 12 45 XX 0D 0A
Starting bit 23 55 Data byte AB 12 45< /span> Stop bit 0D 0A Check code XX Command is 01 ADDR is 52 07
Data length 4
Data Format
There are four data formats in total
The string is composed of single characters concatenated one by one
u uint8_t occupies 1 byte and 8-bit unsigned integer Type
f4 float occupies 4 bytes of single-precision floating point
d8 double occupies 8 bytes of double-precision floating point
c char Occupies 1 byte of single character ASCII code
Among them, f4 and d8 are in little-endian format. When sending data, the low bit is sent first and then the high bit.
For example:
In a floating point number, 0x40 80 00 00 represents 4.0f, where 00 is the low bit and 40 is the high bit:
If sent in little-endian format, 0x00 0x00 0x80 0x40 will be sent in sequence.
When using C language to process data, it is recommended to directly use the memcpy() function to copy from the address when receiving floating point numbers. The number of bytes copied is 4 or 8 (double precision). Floating point); Similarly, when sending floating point data, the memcpy() function is also used to copy the variable value to the DATA array to be sent to avoid errors in the big and small endian formats.
C language data analysis
/*
BCNT 数据长度 表示从ADDR字节的后一字节开始 到校验码的前一字节为止 数据的长度 也是命令位+数据位的长度
BCNT=len(COM+DATA[])
CHK 检验码 表示校验码前所有字节之和
CHK=START0+START1+BCNT0+BCNT1+ADDR0+ADDR1+COM+DATA[]
*/
typedef struct
{
uint8_t START[2];
uint8_t BCNT[2];
uint8_t ADDR[2];
uint8_t COM;
uint8_t DATA[50];
uint8_t CHK[2];
uint8_t STOP[2];
bool Flag; //校验数据是否正确的标志 解析数据时正确则有效 发送数据时无关
}GUI_Struct;
//数据字节为小端格式 其他为大端格式
Array to structure
Analysis idea:
Determine the starting bit
Get the data length
Calculate the sequence number of the check digit a>
Determine the stop bit
Get the check code
Calculate whether the check code is correct (the previous items are added in sequence due to the check code definition It is uint16, so you don’t have to worry about crossing the boundary and counting directly from 0)
Get the address bit
Get the command word
Get the data Bit
GUI_Struct Trans_GUI_to_Struct(uint8_t * buf)
{
GUI_Struct GUI_Stu;
GUI_Stu.Flag=false;
uint8_t i=0;
uint8_t CHK_Num=0;
uint16_t Data_Len=0;
uint16_t Check_Sum=0;
GUI_Stu.START[0]=buf[0];
GUI_Stu.START[1]=buf[1];
if(GUI_Stu.START[0]!=GUI_START0 || GUI_Stu.START[1]!=GUI_START1)
{
return GUI_Stu;
}
GUI_Stu.BCNT[0]=buf[2];
GUI_Stu.BCNT[1]=buf[3];
Data_Len=(GUI_Stu.BCNT[0]<<8)|(GUI_Stu.BCNT[1]);
if(!Data_Len)
{
return GUI_Stu;
}
CHK_Num=Data_Len+6;
GUI_Stu.STOP[0]=buf[CHK_Num+2];
GUI_Stu.STOP[1]=buf[CHK_Num+3];
if(GUI_Stu.STOP[0]!=GUI_STOP0 || GUI_Stu.STOP[1]!=GUI_STOP1)
{
return GUI_Stu;
}
GUI_Stu.CHK[0]=buf[CHK_Num];
GUI_Stu.CHK[1]=buf[CHK_Num+1];
for(i=0;i<CHK_Num;i++)
{
Check_Sum=Check_Sum+buf[i];
}
if((Check_Sum>>8)!=GUI_Stu.CHK[0] || (Check_Sum&0x00FF)!=GUI_Stu.CHK[1])
{
return GUI_Stu;
}
GUI_Stu.ADDR[0]=buf[4];
GUI_Stu.ADDR[1]=buf[5];
GUI_Stu.COM=buf[6];
for(i=0;i<Data_Len-1;i++)
{
GUI_Stu.DATA[i]=buf[i+7];
}
GUI_Stu.Flag=true;
return GUI_Stu;
}
Convert structure to array
That is the reverse:
Incoming start bit
Incoming data length
Incoming address bit
Incoming data length bits to calculate data length
Calculate check code sequence number
Incoming command word
Incoming data bits
Calculate check code
Incoming check bit and stop bit
uint8_t Trans_GUI_to_Buf(GUI_Struct GUI_Stu,uint8_t * buf)
{
uint8_t i=0;
uint8_t CHK_Num=0;
uint16_t Data_Len=0;
uint16_t Check_Sum=0;
if(GUI_Stu.START[0]!=GUI_START0 || GUI_Stu.START[1]!=GUI_START1)
{
return 0;
}
if(GUI_Stu.STOP[0]!=GUI_STOP0 || GUI_Stu.STOP[1]!=GUI_STOP1)
{
return 0;
}
buf[0]=GUI_Stu.START[0];
buf[1]=GUI_Stu.START[1];
buf[2]=GUI_Stu.BCNT[0];
buf[3]=GUI_Stu.BCNT[1];
buf[4]=GUI_Stu.ADDR[0];
buf[5]=GUI_Stu.ADDR[1];
Data_Len=(GUI_Stu.BCNT[0]<<8)|(GUI_Stu.BCNT[1]);
if(!Data_Len)
{
return 0;
}
CHK_Num=Data_Len+6;
buf[6]=GUI_Stu.COM;
for(i=0;i<Data_Len-1;i++)
{
buf[i+7]=GUI_Stu.DATA[i];
}
for(i=0;i<CHK_Num;i++)
{
Check_Sum=Check_Sum+buf[i];
}
buf[CHK_Num]=(Check_Sum&0xFF00)>>8;
buf[CHK_Num+1]=Check_Sum&0x00FF;
buf[CHK_Num+2]=GUI_Stu.STOP[0];
buf[CHK_Num+3]=GUI_Stu.STOP[1];
return (CHK_Num+4);
}
C language test
int main(void)
{
uint8_t buf[61]={
0x23,0x55,0x00,0x29,0x52,0x04,0x42,0x03,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x01,0x3C,0x0D,0x0A};
GUI_Struct A;
A=Trans_GUI_to_Struct(buf);
printf("%d %s\n",A.COM,A.START);
printf("%d\n",A.Flag);
GUI_Struct B = A;
Trans_GUI_to_Buf(B,buf);
for(int i=0;i<61;i++)
{
printf(" 0x%02x",buf[i]);
}
printf("\n");
B=Trans_GUI_to_Struct(buf);
printf("%d\n",B.Flag);
}
running result:
66 #U
1
0x23 0x55 0x00 0x29 0x52 0x04 0x42 0x03 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x01 0x3c 0x0d 0x0a 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
1
Python data analysis
The array passed in by Python is of bytes type (actually equivalent to an integer in the form of a list)
The value method is buf[i] although the value type is bytes type But you can use integer calculation method
Here, use class class to store data
class GUI_Struct:
def __init__(self):
self.START = bytes([0,0])
self.BCNT = bytes([0,0])
self.ADDR = bytes([0,0])
self.COM = bytes([0])
self.DATA = bytes([])
self.CHK = bytes([0,0])
self.STOP = bytes([0,0])
self.Bytes_Buf = bytes([])
self.__Trans_to_Struct_Flag = False
self.__Trans_to_Buf_Flag = False
In order to prevent errors in the incoming data, add an initialization function:
def Init_All(self):
self.START= bytes(list(self.START))
self.BCNT= bytes(list(self.BCNT))
self.ADDR= bytes(list(self.ADDR))
self.COM= bytes(list(self.COM))
self.DATA= bytes(list(self.DATA))
self.CHK= bytes(list(self.CHK))
self.STOP= bytes(list(self.STOP))
self.Bytes_Buf= bytes(list(self.Bytes_Buf))
And added two private functions to get the flag
def Get_Trans_to_Struct_Flag(self):
return self.__Trans_to_Struct_Flag
def Get_Trans_to_Buf_Flag(self):
return self.__Trans_to_Buf_Flag
Array to class
The same method as C language
But here the check code needs to avoid pitfalls
Since there is no definition of integer such as uint16 in Python, it is needed with 0x0000FFFF
def Trans_to_Struct(self):
buf=bytes(list(self.Bytes_Buf))
self.__Trans_to_Struct_Flag=False
i=0
CHK_Num=0
Data_Len=0
Check_Sum=0
Data_List = []
self.START=bytes([buf[0],buf[1]])
if self.START!=GUI_START:
return 0
self.BCNT=bytes([buf[2],buf[3]])
Data_Len=(self.BCNT[0]<<8)|(self.BCNT[1])
if Data_Len==0:
return 0
CHK_Num=Data_Len+6
self.STOP=bytes([buf[CHK_Num+2],buf[CHK_Num+3]])
if self.STOP!=GUI_STOP:
return 0
self.CHK=bytes([buf[CHK_Num],buf[CHK_Num+1]])
for i in range(CHK_Num):
Check_Sum=Check_Sum+buf[i]
Check_Sum = Check_Sum&0x0000FFFF
if Check_Sum!=(self.CHK[0]<<8)|self.CHK[1]:
return 0
self.ADDR=bytes([buf[4],buf[5]])
self.COM=bytes([buf[6]])
for i in range(7,Data_Len+6):
Data_List.append(buf[i])
self.DATA=bytes(Data_List)
self.__Trans_to_Struct_Flag=True
return 1
class to array
Similarly, the check digit here is also a pitfall that needs to be avoided
and the append function is used here to add elements in sequence, so it must be done in bit order
def Trans_to_Buf(self):
self.START= bytes(list(self.START))
self.BCNT= bytes(list(self.BCNT))
self.ADDR= bytes(list(self.ADDR))
self.COM= bytes(list(self.COM))
self.DATA= bytes(list(self.DATA))
self.CHK= bytes(list(self.CHK))
self.STOP= bytes(list(self.STOP))
self.__Trans_to_Buf_Flag = False
buf=[]
i=0
CHK_Num=0
Data_Len=0
Check_Sum=0
if self.START!=GUI_START:
return 0
if self.STOP!=GUI_STOP:
return 0
buf.append(self.START[0])
buf.append(self.START[1])
buf.append(self.BCNT[0])
buf.append(self.BCNT[1])
buf.append(self.ADDR[0])
buf.append(self.ADDR[1])
Data_Len=(self.BCNT[0]<<8)|(self.BCNT[1])
if Data_Len == 0:
return 0
CHK_Num=Data_Len+6
buf.append(self.COM[0])
for i in self.DATA:
buf.append(i)
for i in range(CHK_Num):
Check_Sum=Check_Sum+buf[i]
buf.append(((Check_Sum&0x0000FF00)>>8)&0x000000FF)
buf.append(Check_Sum&0x000000FF)
buf.append(self.STOP[0])
buf.append(self.STOP[1])
self.Bytes_Buf=bytes(buf)
self.__Trans_to_Buf_Flag = True
return 1
Python test
A=GUI_Struct()
buf=b'\x23\x55\x00\x29\x52\x04\x42\x03\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01\x3C\x0D\x0A'
A.Bytes_Buf=buf
print(A.Trans_to_Struct())
print(A.COM,A.DATA)
print(A.Get_Trans_to_Struct_Flag())
B=A
print(B.Trans_to_Buf())
print(B.Bytes_Buf)
print(buf)
print(B.Get_Trans_to_Buf_Flag())
print(B.Trans_to_Struct())
print(A.Trans_to_Buf())
running result:
1
b'B' b'\x03\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
True
1
b'#U\x00)R\x04B\x03\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01<\r\n'
b'#U\x00)R\x04B\x03\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01<\r\n'
True
1
1
Python representation of nested structures
The following C language structure:
typedef struct
{
unsigned char obj_src;
unsigned char obj_res0;
unsigned char obj_res1;
unsigned char objCount;
struct
{
unsigned short range;/* 0.01 m*/
short velocity; /* 0.01 km/h*/
} objects[MAX_OBJECTS];
/**/
float vel_self;
}miniradar_output_t;
Is this structure nested in a structure substructure or in the form of an array? The maximum number is MAX_OBJECTS, which is temporarily defined as 8
For Python, the length of the array can be added. and the substructure can be defined as a secondary structure
Thenlen(self.range) represents the number of elements in objects
class RF_Struct:
def __init__(self):
self.obj_src = bytes([0])
self.obj_res0 = bytes([0])
self.obj_res1 = bytes([0])
self.objCount = bytes([0])
self.range=[]
self.velocity=[]
self.vel_self=bytes([0,0,0,0])
self.data_buf=bytes([])
Likewise initialize properties:
def Init_All(self):
self.obj_src = bytes(list(self.obj_src))
self.obj_res0 = bytes(list(self.obj_res0))
self.obj_res1 = bytes(list(self.obj_res1))
self.objCount = bytes(list(self.objCount))
self.range=list(self.range)
for i in range(len(self.range)):
self.range[i]=bytes(list(i))
self.velocity=list(self.velocity)
for i in range(len(self.velocity)):
self.velocity[i]=bytes(list(i))
self.vel_self=bytes(list(self.vel_self))
self.data_buf=bytes(list(self.data_buf))
Array to class
This is more troublesome
There are not only uint16 types, but also int16 types and flout types
def Trans_to_Struct(self):
i=0
r_list=[]
v_list=[]
self.__Trans_to_Struct_Flag = False
buf = self.data_buf
d_size = int((len(buf)-8)%4)
if d_size:
return 0
size = int((len(buf)-8)/4)
self.obj_src=bytes([buf[0]])[0]
self.obj_res0=bytes([buf[1]])[0]
self.obj_res1=bytes([buf[2]])[0]
self.objCount=bytes([buf[3]])[0]
for i in range(size):
r_list.append(bytes([buf[4+4*i],buf[4+4*i+1]]))
v_list.append(bytes([buf[4+4*i+2],buf[4+4*i+3]]))
for i in range(len(r_list)):
r_list[i]=(r_list[i][0]<<8)|r_list[i][1]
v_list[i]=((v_list[i][0]<<8)|v_list[i][1])
if v_list[i]>>15:
v_list[i]=-v_list[i]&0x8000
else:
v_list[i]=v_list[i]&0x8000
self.range=r_list.copy()
self.velocity=v_list.copy()
self.vel_self=bytes([buf[4+4*size],buf[4+4*size+1],buf[4+4*size+2],buf[4+4*size+3]])
ba = bytearray()
ba.append(self.vel_self[3])
ba.append(self.vel_self[2])
ba.append(self.vel_self[1])
ba.append(self.vel_self[0])
self.vel_self=struct.unpack("!f",ba)[0]
self.__Trans_to_Struct_Flag = True
return 1
code testing
data = b'\x03\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x80\x40'
R = RF_Struct()
R.data_buf=data
R.Trans_to_Struct()
print(R.Get_Trans_to_Struct_Flag())
operation result:
True
Long byte data storage and parsing
Long byte data includes 16-bit, 32-bit, 64-bit integer float double types and compressed strings, etc.
Ordinary strings are just multiple 8-bit integer data arrays, so Not counting long byte data
Long byte data involves big-endian conversion
If it is in little-endian format, it will be consistent with memory storage and can be directly used in C language. Just use the memcpy function
Otherwise, you need to use big-endian conversion (see appendix)
For example:
void swap32(void * p)
{
uint32_t *ptr=p;
uint32_t x = *ptr;
x = (x << 16) | (x >> 16);
x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);
*ptr=x;
}
In addition, in C language, long data can be converted to a specific type by direct pointer conversion, such as converting uint32 to flout:
uint32_t i=0x40800000; //注意这里是小端格式 实际内存存储的是 00 00 80 40
flout f=0.0f;
f= *(float *)&i;
printf("%f\n",f);
operation result:
4.0
16-bit shaping analysis
Uint16 is shifted directly. After int16 is shifted, positive and negative must be judged. The same is true for 32-bit and 64-bit.
for i in range(size):
r_list.append(bytes([buf[4+4*i],buf[4+4*i+1]]))
v_list.append(bytes([buf[4+4*i+2],buf[4+4*i+3]]))
for i in range(len(r_list)):
r_list[i]=(r_list[i][0]<<8)|r_list[i][1]
v_list[i]=((v_list[i][0]<<8)|v_list[i][1])
if v_list[i]>>15:
v_list[i]=-v_list[i]&0x8000
else:
v_list[i]=v_list[i]&0x8000
And these two data are a two-dimensional array, so two new lists need to be defined (see the appendix for two-dimensional list operations)
r_list=[]
v_list=[]
Last usecopy()Incoming assignment
self.range=r_list.copy()
self.velocity=v_list.copy()
Floating point parsing

mathematical method
It is purely based on calculation
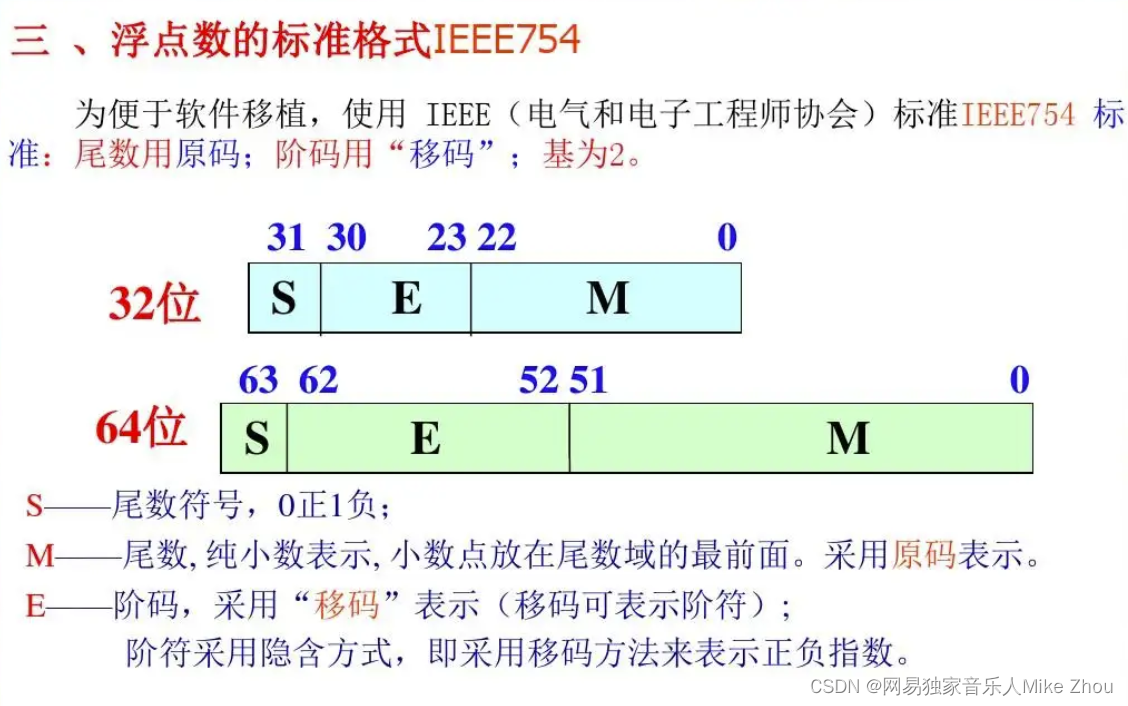
It is more complicated and not recommended to be used
C language method
Pointer address type forced transfer
uint32_t i=0x40800000; //注意这里是小端格式 实际内存存储的是 00 00 80 40
flout f=0.0f;
f= *(float *)&i;
printf("%f\n",f);
Python methods
Use the struct library to operate:
At the same time, use the bytearray type to operate. Note that it must be converted to big-endian format
ba = bytearray()
ba.append(self.vel_self[3])
ba.append(self.vel_self[2])
ba.append(self.vel_self[1])
ba.append(self.vel_self[0])
self.vel_self=struct.unpack("!f",ba)[0]
Compressed string
See Appendix
Appendix: Compressed strings, big and small endian format conversion
Compressed string
First of all, the HART data format is as follows:


The focus is on floating point numbers and string types
Latin-1 is not mentioned and is basically not used a>
floating point number
In floating point numbers, such as 0x40 80 00 00 means 4.0f
In the HART protocol, floating point numbers are sent in big-endian format, that is, the high bit is sent first and the low bit is sent last.
The array sent is: 40,80,00,00
But in C language, floating point numbers are stored in little-endian format, that is, 40 is in the high bit and 00 is in the low bit.
Floating point number: 4.0f< a i=2> Address 0x1000 corresponds to 00 Address 0x1001 corresponds to 00 Address 0x1002 corresponds to 80 Address 0x1003 corresponds to 40
If you use the memcpy function directly, you need to perform big-endian conversion, otherwise it will be stored as:
Address 0x1000 corresponds to 40
Address 0x1001 corresponds to 80 Address 0x1003 corresponds to 00
Address 0x1002 corresponds to 00
Big-endian conversion:
void swap32(void * p)
{
uint32_t *ptr=p;
uint32_t x = *ptr;
x = (x << 16) | (x >> 16);
x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);
*ptr=x;
}
Compressed Packed-ASCII strings
Essentially, the highest 2 bits of the original ASCII are removed and then spliced together, such as spaces (0x20)
After splicing four spaces, it becomes
1000 0010 0000 1000 0010 0000
Hexadecimal: 82 08 20
I checked the table and cannot recognize the ones before 0x20
That is, it can only recognize the ASCII table 0x20-0x5F
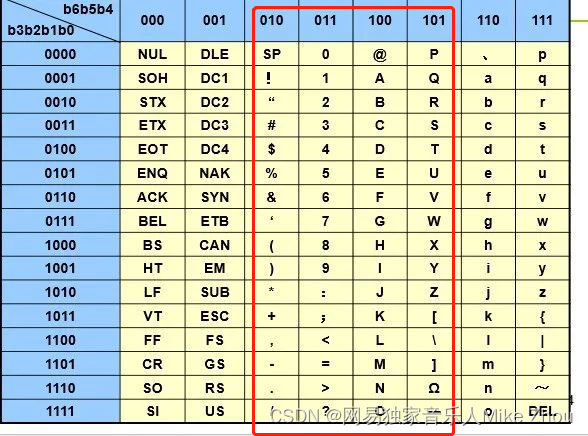
Write the compression/decompression function later:
//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_ASCII_to_Pack(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{
if(str_len%4)
{
return 0;
}
uint8_t i=0;
memset(buf,0,str_len/4*3);
for(i=0;i<str_len;i++)
{
if(str[i]==0x00)
{
str[i]=0x20;
}
}
for(i=0;i<str_len/4;i++)
{
buf[3*i]=(str[4*i]<<2)|((str[4*i+1]>>4)&0x03);
buf[3*i+1]=(str[4*i+1]<<4)|((str[4*i+2]>>2)&0x0F);
buf[3*i+2]=(str[4*i+2]<<6)|(str[4*i+3]&0x3F);
}
return 1;
}
//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_Pack_to_ASCII(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{
if(str_len%4)
{
return 0;
}
uint8_t i=0;
memset(str,0,str_len);
for(i=0;i<str_len/4;i++)
{
str[4*i]=(buf[3*i]>>2)&0x3F;
str[4*i+1]=((buf[3*i]<<4)&0x30)|(buf[3*i+1]>>4);
str[4*i+2]=((buf[3*i+1]<<2)&0x3C)|(buf[3*i+2]>>6);
str[4*i+3]=buf[3*i+2]&0x3F;
}
return 1;
}
Big-endian conversion
When parsing data such as serial ports, it is inevitable to encounter problems with big and small endian formats.
What are big endian and little endian
The so-called big-endian mode means that the high-order bytes are arranged at the low address end of the memory, and the low-order bytes are arranged at the high address end of the memory.
The so-called little endian mode means that the low-order bytes are arranged at the low address end of the memory, and the high-order bytes are arranged at the high address end of the memory.
To put it simply: big endian - high end, little endian - low end
For example, the number 0x12 34 56 78 is represented in memory as:
1) Big endian mode:
Low address ------------------> High address
0x12 | 0x34 | 0x56 | 0x78
2) Little endian mode:
Low address ------------------> High address
0x78 | 0x56 | 0x34 | 0x12
It can be seen that the big-endian mode is similar to the storage mode of strings.
Endianness in data transfer
For example, the address bit, start and end bits are generally in big-endian format
For example:
Starting bit: 0x520A
Then the buf sent should be {0x52,0x0A}
The data bits are generally in little-endian format (a single byte is not divided into big and small endian)
For example:
A 16-bit data is sent out is {0x52,0x0A}
, then the corresponding uint16_t type number is: 0x0A52
For floating point number 4.0f converted to 32 bits it should be:
40 80 00 00
In terms of big-endian storage, the buf sent out is sent in sequence 40 80 00 00
For little-endian storage, 00 00 80 40 is sent
Since memcpy and other functions copy by byte address, the copy format is little-endian, so when the data is stored in little-endian, there is no need to perform big-endian conversion
For example: a>
uint32_t dat=0;
uint8_t buf[]={
0x00,0x00,0x80,0x40};
memcpy(&dat,buf,4);
float f=0.0f;
f=*((float*)&dat); //地址强转
printf("%f",f);
Or better solution:
uint8_t buf[]={
0x00,0x00,0x80,0x40};
float f=0.0f;
memcpy(&f,buf,4);
For data stored in big endian (for example, HART protocol data is all in big endian format), the copied format is still in little endian format, so when the data is stored in little endian format, big endian conversion is required< a i=1> Such as:
uint32_t dat=0;
uint8_t buf[]={
0x40,0x80,0x00,0x00};
memcpy(&dat,buf,4);
float f=0.0f;
swap32(&dat); //大小端转换
f=*((float*)&dat); //地址强转
printf("%f",f);
or:
uint8_t buf[]={
0x40,0x80,0x00,0x00};
memcpy(&dat,buf,4);
float f=0.0f;
swap32(&f); //大小端转换
printf("%f",f);
Or better solution:
uint32_t dat=0;
uint8_t buf[]={
0x40,0x80,0x00,0x00};
float f=0.0f;
dat=(buf[0]<<24)|(buf[0]<<16)|(buf[0]<<8)|(buf[0]<<0)
f=*((float*)&dat);
Summarize
Solid. If the data is in little-endian format, you can directly use the memcpy function to convert it. Otherwise, the address is forced to be transferred by shifting.
For multi-bit data, such as transmitting two floating point numbers at the same time, you can define the structure and then copy it with memcpy (the data is in little-endian format)
For little-endian data, you can write it directly with memcpy. If it is a floating point number, there is no need to perform a forced transfer.
For big-endian data, if you don't mind the trouble or want to make the code more concise (but the execution efficiency will be reduced), you can also use memcpy to write the structure first and then call the big-endian conversion function. However, it should be noted here that the structure must be all unsigned. Integer floating point types can only be forced to be converted again after big and small endian conversion and writing. If floating point types are used in the structure, they need to be forced to be converted twice.
Therefore, for big-endian data, it is recommended to assign values by shifting, then perform forced conversion of individual numbers, and then write them into the general structure.
Multiple structures with different variable sizes have to deal with byte alignment issues
You can use #pragma pack(1) to align them to 1
But it will affect efficiency
Big-endian conversion function
It is implemented directly by operating on the address. The incoming variable is a 32-bit variable
The intermediate variable ptr is the address of the incoming variable
void swap16(void * p)
{
uint16_t *ptr=p;
uint16_t x = *ptr;
x = (x << 8) | (x >> 8);
*ptr=x;
}
void swap32(void * p)
{
uint32_t *ptr=p;
uint32_t x = *ptr;
x = (x << 16) | (x >> 16);
x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);
*ptr=x;
}
void swap64(void * p)
{
uint64_t *ptr=p;
uint64_t x = *ptr;
x = (x << 32) | (x >> 32);
x = ((x & 0x0000FFFF0000FFFF) << 16) | ((x >> 16) & 0x0000FFFF0000FFFF);
x = ((x & 0x00FF00FF00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF00FF00FF);
*ptr=x;
}
Appendix: List assignment types and py packaging
list assignment
BUG recurrence
I wrote a small program when I had nothing to do. The code is as follows:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 19 19:47:01 2021
@author: 16016
"""
a_list = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15']
#print(len(a_list))
#b_list = ['','','','','','','','','','','','','','','','']
c_list = [[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]]
#for i in range(16):
if len(a_list):
for j in range(16):
a_list[j]=str(a_list[j])+'_'+str(j)
print("序号:",j)
print('a_list:\n',a_list)
c_list[j]=a_list
print('c_list[0]:\n',c_list[0])
print('\n')
# b_list[j]=a_list[7],a_list[8]
# print(b_list[j])
# 写入到Excel:
#print(c_list,'\n')
I made a 16-time for loop in the program and added "_" and the loop serial number after each value of list a.
For example, the xth time of looping is Add _x to the , '1_1', '2_2', '3_3', '4_4', '5_5', '6_6', '7_7', '8_8', '9_9', '10_10', '11_11', '12_12', ' 13_13', '14_14', '15_15'] This is also correct
At the same time, I write the value of list a into the empty list c during each cycle. For example, the xth cycle is to write the changed value of list a into the xth position of list c
The value of c[0] after the 0th loop should be ['0_0', '1', '2', '3', '4', '5', '6', '7' , '8', '9', '10', '11', '12', '13', '14', '15'] This is also correct
But in the 1st After this cycle, the value of c[0] has been changing into the value of c[x]
, which is equivalent to changing c_list[0] into c_list[1]...and so on. The value of the resulting list c is exactly the same for every item
I don’t understand what’s going on
My c[0] is only at the 0th time It is assigned a value during the loop but its value changes later
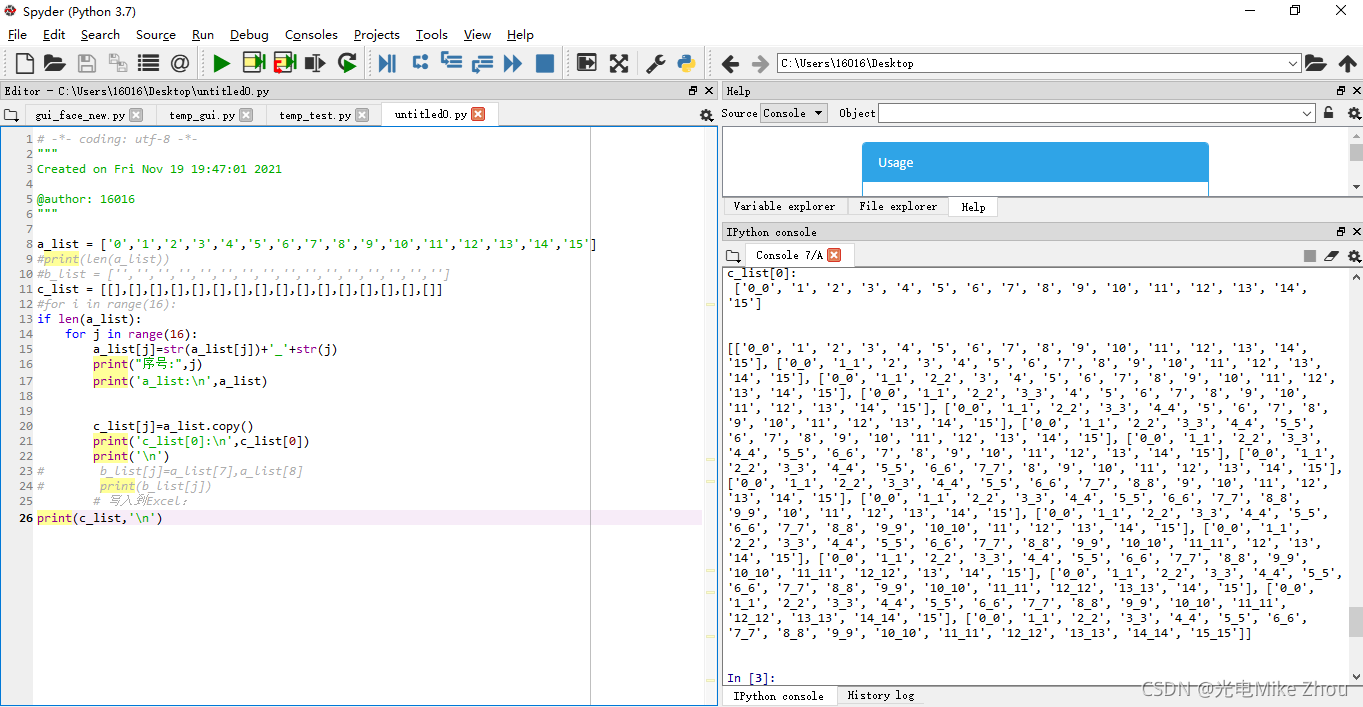
As shown in the figure:
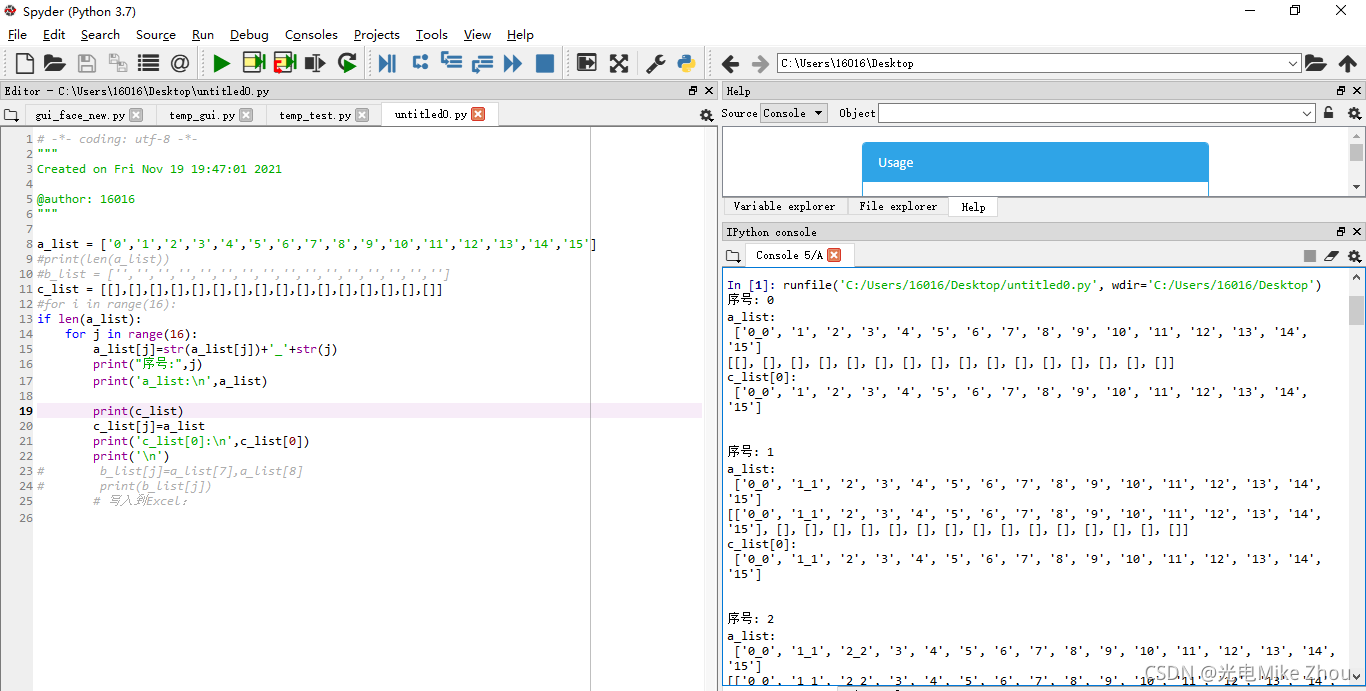
The first time a bug occurred. After the assignment, the value of c[0] was changed every time it was looped. It took a long time and it didn’t work out
No matter whether it is added with the append function or defined with a two-dimensional array or a third empty array is added for transition, it cannot be solved
Code improvements
Later, under the guidance of my Huake classmates, I suddenly thought that the assignment can be assigned to an address. The value in the address keeps changing, causing the assignment to keep changing. So I used the loop within loop deep copy in the second picture to implement it.
code show as below:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 19 19:47:01 2021
@author: 16016
"""
a_list = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15']
#print(len(a_list))
#b_list = ['','','','','','','','','','','','','','','','']
c_list = [[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]]
#for i in range(16):
if len(a_list):
for j in range(16):
a_list[j]=str(a_list[j])+'_'+str(j)
print("序号:",j)
print('a_list:\n',a_list)
for i in range(16):
c_list[j].append(a_list[i])
print('c_list[0]:\n',c_list[0])
print('\n')
# b_list[j]=a_list[7],a_list[8]
# print(b_list[j])
# 写入到Excel:
print(c_list,'\n')
solved the problem
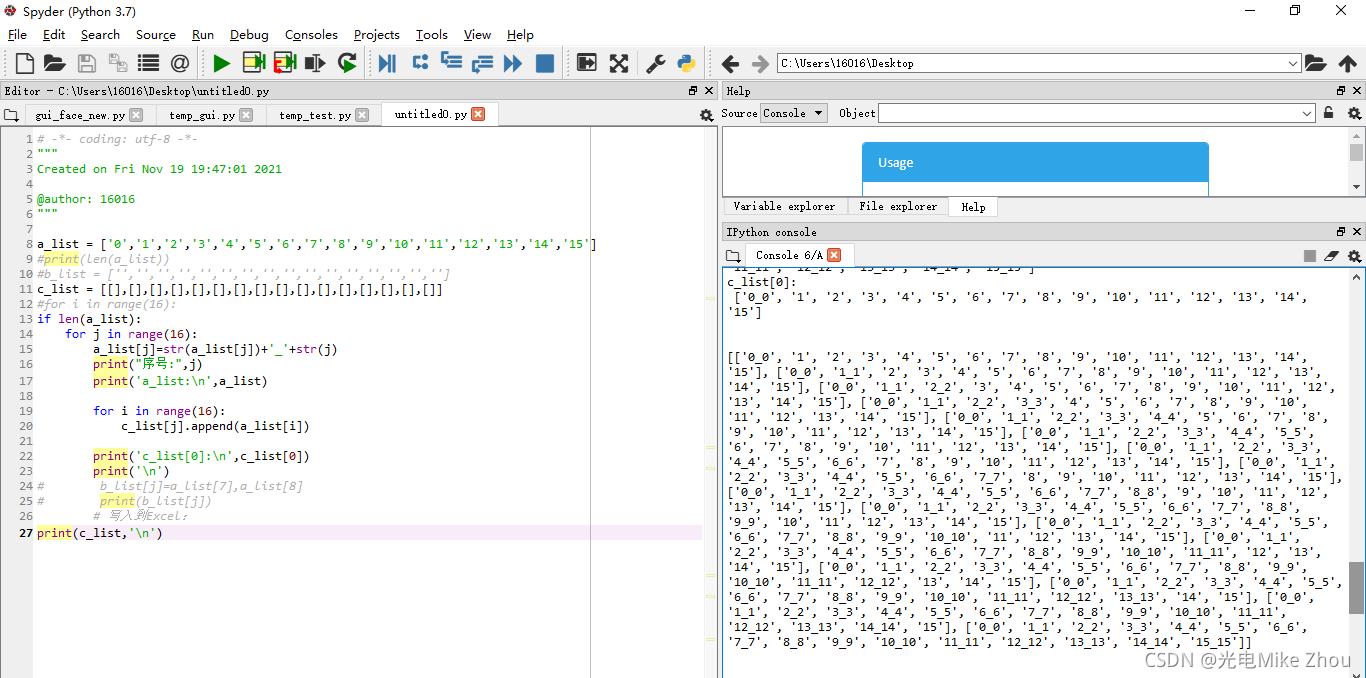
optimization
The third time I asked the teacher to use the copy function to assign a true value.
code show as below:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 19 19:47:01 2021
@author: 16016
"""
a_list = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15']
#print(len(a_list))
#b_list = ['','','','','','','','','','','','','','','','']
c_list = [[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]]
#for i in range(16):
if len(a_list):
for j in range(16):
a_list[j]=str(a_list[j])+'_'+str(j)
print("序号:",j)
print('a_list:\n',a_list)
c_list[j]=a_list.copy()
print('c_list[0]:\n',c_list[0])
print('\n')
# b_list[j]=a_list[7],a_list[8]
# print(b_list[j])
# 写入到Excel:
#print(c_list,'\n')
The problem can also be solved
Finally, the problem is concluded that the pointer is to blame!
a_list points to an address, not a value. a_list[i] points to a single value. The copy() function also copies a value, not an address.
If this is written in C language, it will be more intuitive. No wonder C language is the basis. If you don’t learn C in optical Python, you will not be able to solve such a problem.
C language yyds What kind of rubbish retarded language is Python?
Summarize
Since Python cannot define a value as a pointer or an independent value, it can only be transferred using a list
As long as the assignment points to a list as a whole, it is a pointer memory address. There is only one solution, which is to deeply copy and assign each value (extract the elements in the sublist and reconnect them in sequence) or use the copy function to assign values individually
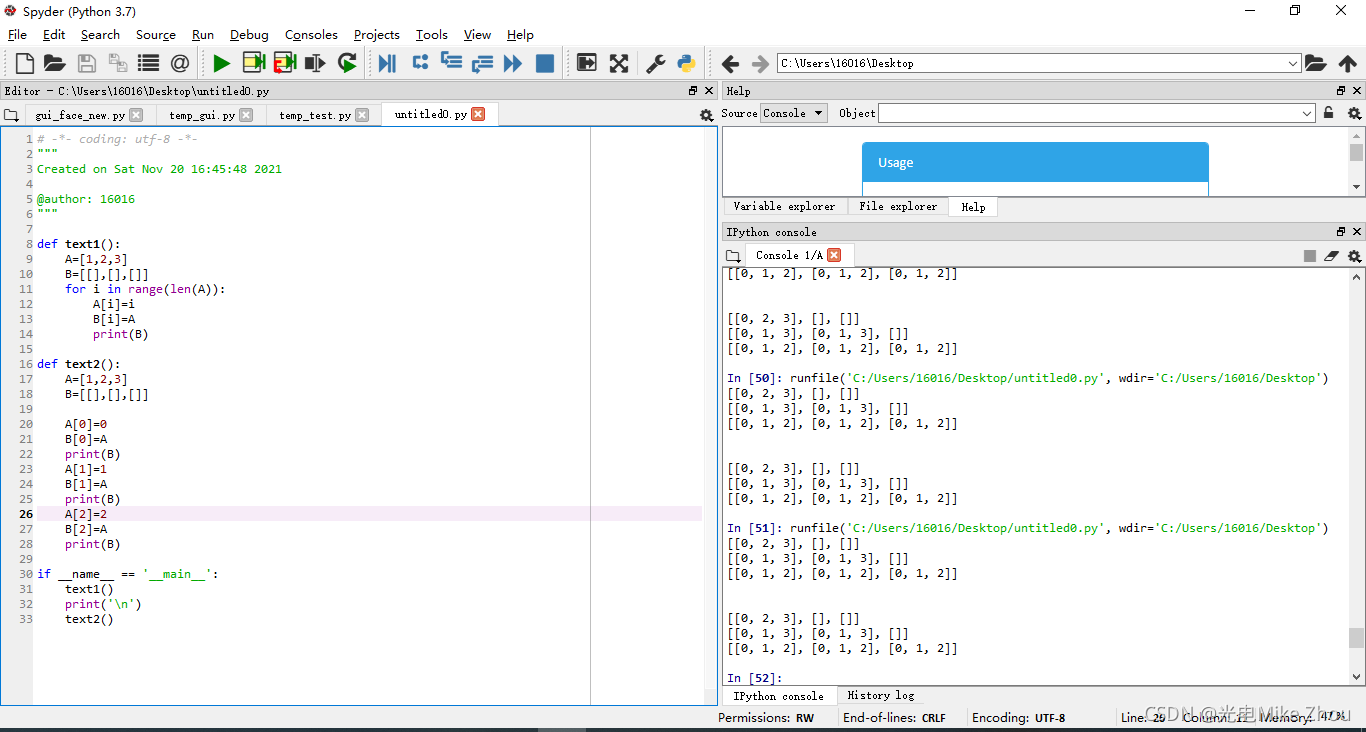
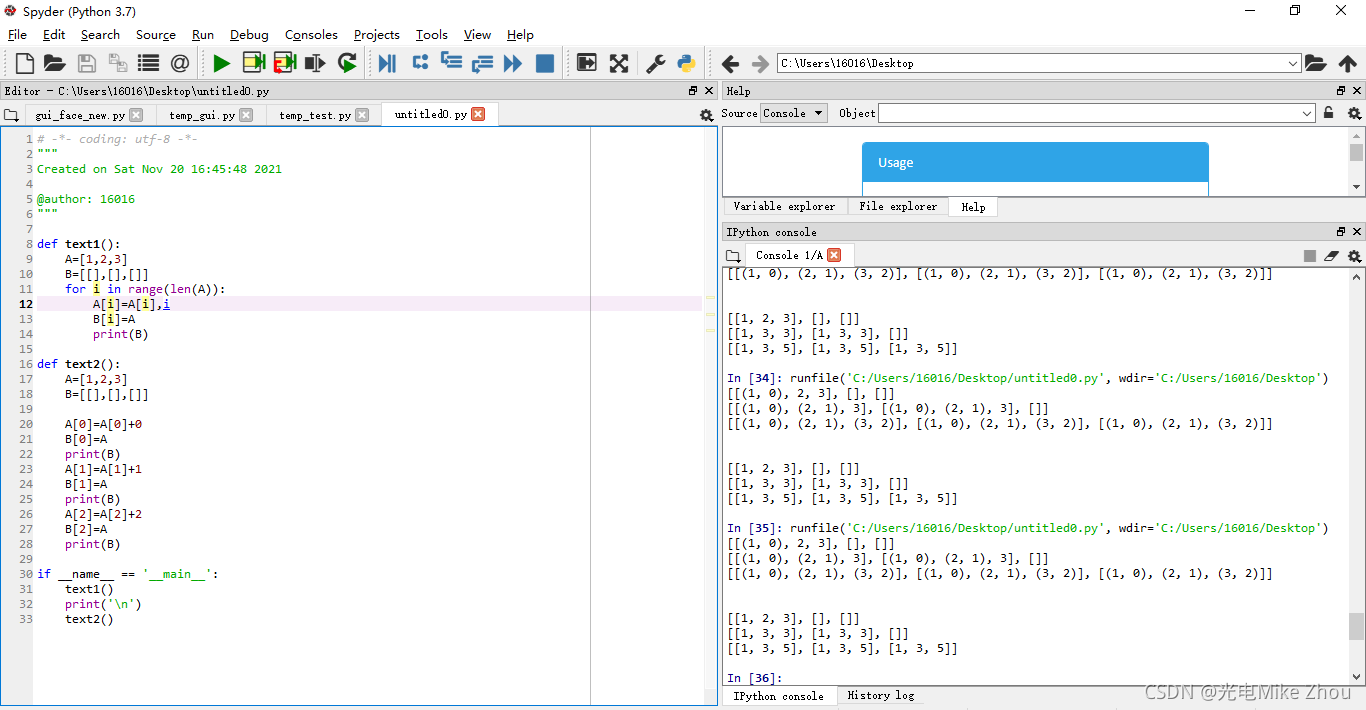
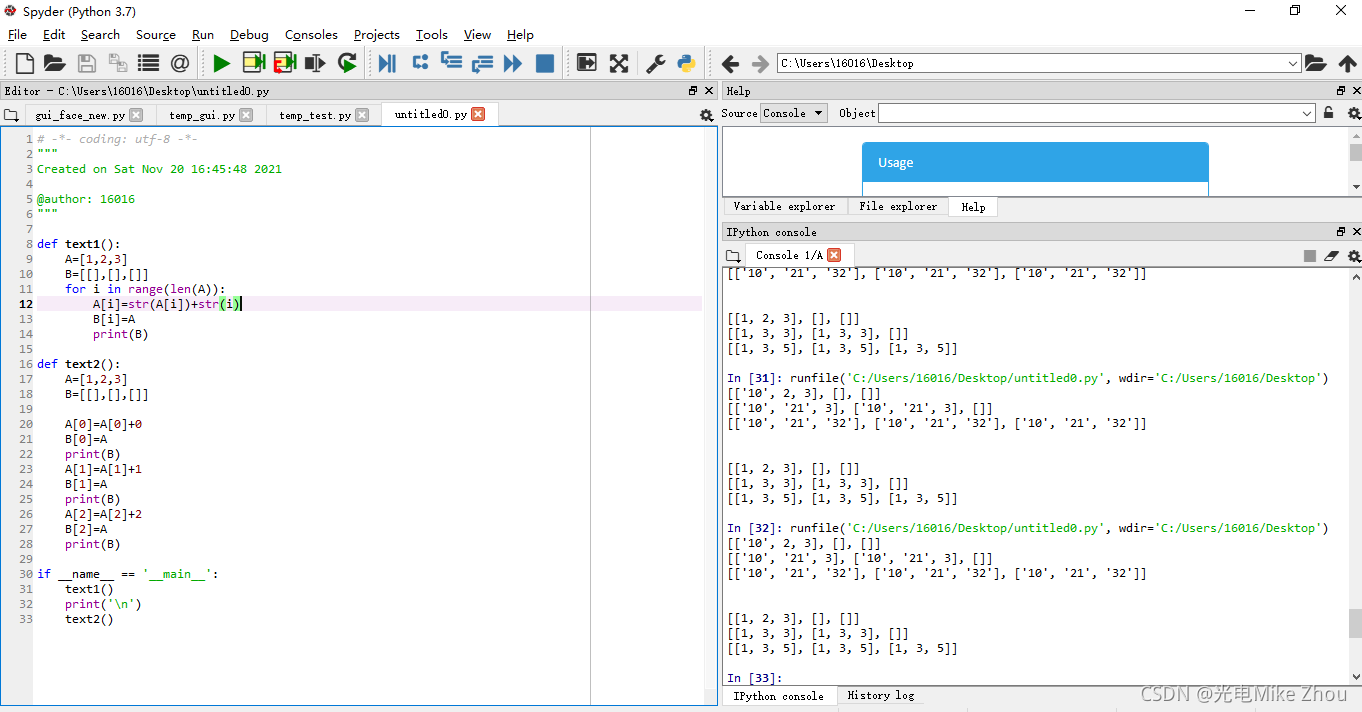
Test as shown:

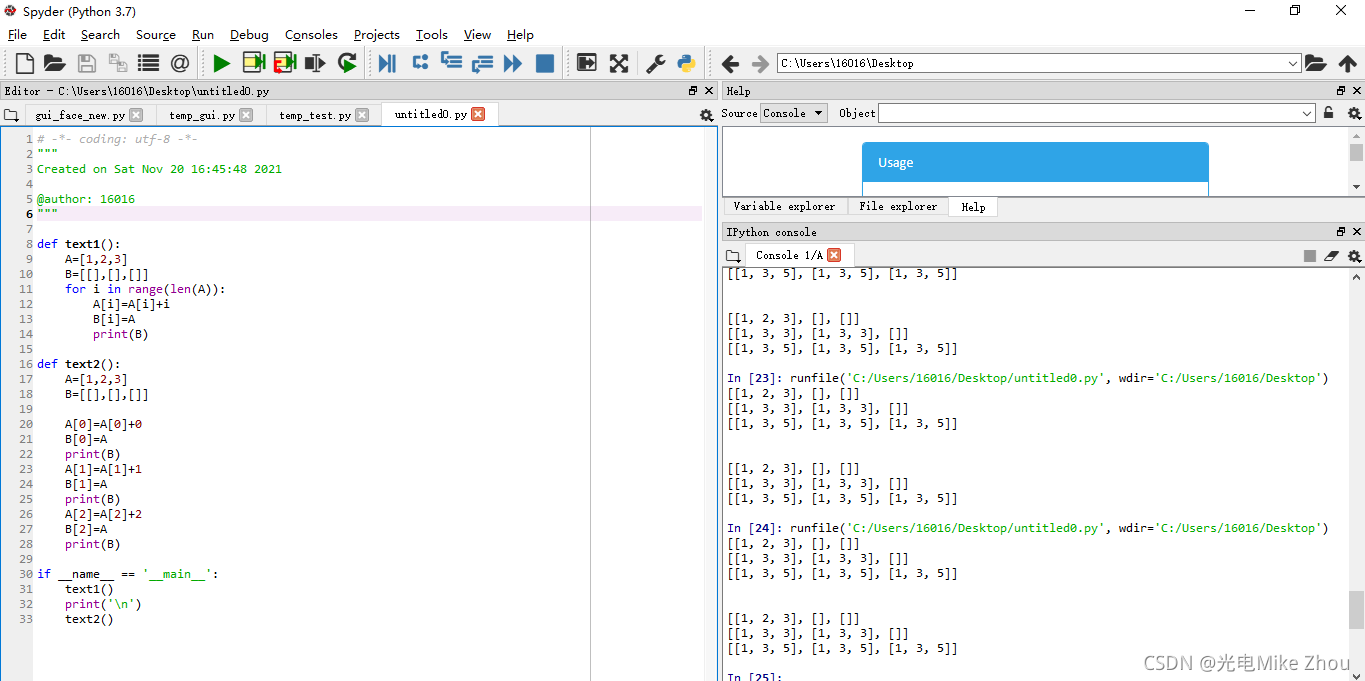
Part of the code:
# -*- coding: utf-8 -*-
"""
Created on Sat Nov 20 16:45:48 2021
@author: 16016
"""
def text1():
A=[1,2,3]
B=[[],[],[]]
for i in range(len(A)):
A[i]=A[i]+i
B[i]=A
print(B)
def text2():
A=[1,2,3]
B=[[],[],[]]
A[0]=A[0]+0
B[0]=A
print(B)
A[1]=A[1]+1
B[1]=A
print(B)
A[2]=A[2]+2
B[2]=A
print(B)
if __name__ == '__main__':
text1()
print('\n')
text2()
py package
Pyinstaller packages exe (including packaging resource files, never error version)
Dependent packages and their corresponding version numbers
PyQt5 5.10.1
PyQt5-Qt5 5.15.2
PyQt5-sip 12.9.0
pyinstaller 4.5.1
pyinstaller-hooks-contrib 2021.3
Pyinstaller -F setup.py package exe
Pyinstaller -F -w setup.py packaging without console
Pyinstaller -F -i xx.ico setup.py packages the specified exe icon package
Package exe parameter description:
-F: Only a single exe format file is generated after packaging;
-D: Default option, creates a directory containing exe files and a large number of dependent files;
-c: Default option, use the console (a black box similar to cmd);
-w: Do not use the console;
-p: Add a search path to find the corresponding library;
-i: Change the icon of the generated program.
If you want to package resource files
you need to convert the path in the code
Also note that if you want to package resource files py The path in the program needs to be changed from ./xxx/yy to xxx/yy and the path conversion is performed
But if the resource file is not packaged, it is best to use the path as ./xxx/yy and not perform the path conversion. Path conversion
def get_resource_path(relative_path):
if hasattr(sys, '_MEIPASS'):
return os.path.join(sys._MEIPASS, relative_path)
return os.path.join(os.path.abspath("."), relative_path)
Then add the directory in the datas part of the spec file
For example:
a = Analysis(['cxk.py'],
pathex=['D:\\Python Test\\cxk'],
binaries=[],
datas=[('root','root')],
hiddenimports=[],
hookspath=[],
hooksconfig={
},
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
Then directly Pyinstaller -F setup.spec
If the packaged file is too large, just change the excludes in the spec file and include the libraries you don’t need (but have already been installed in the environment).
These unnecessary libraries are output in the shell during the last compilation
For example:
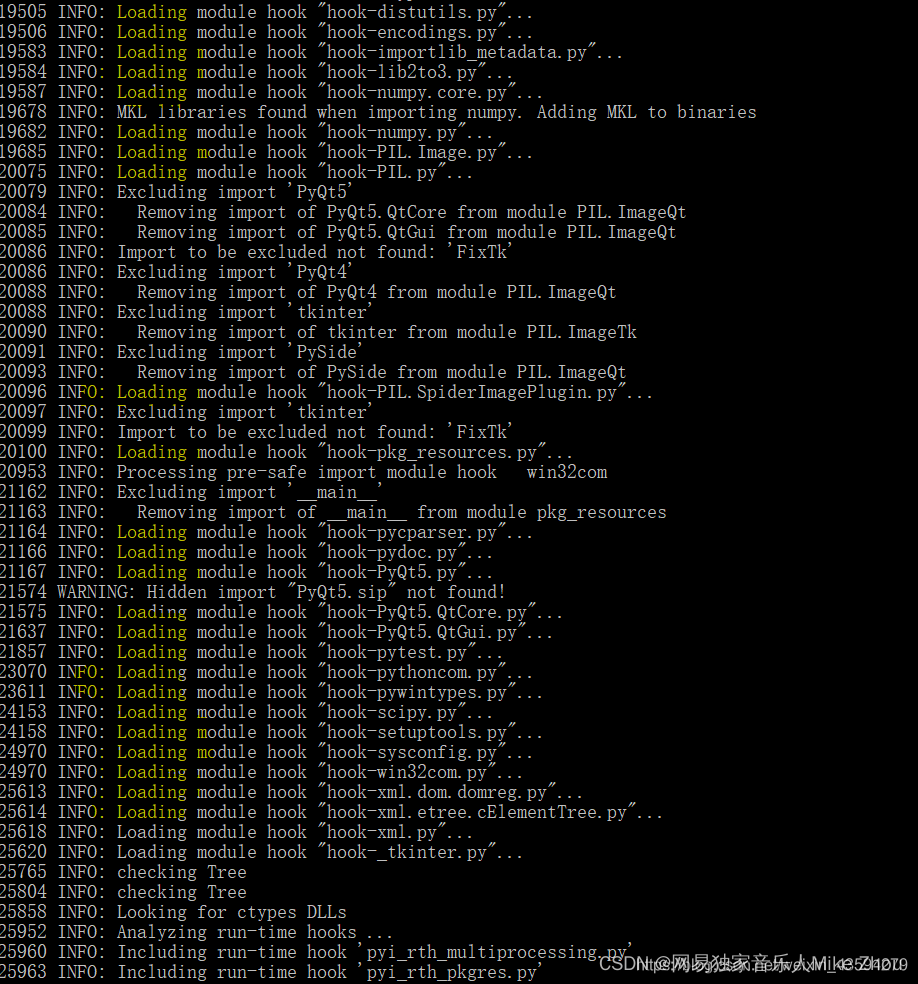

Then use pyinstaller --clean -F XX.spec