
Before introducing the traffic protection function of ab splitting , let’s popularize some concepts and terminology of ab splitting.
Glossary:
- Experiment : A part of the traffic used to verify a function or strategy that determines how requests are processed. It is usually used to verify the impact of a certain function or strategy on system indicators (such as PV/UV, CRT, order conversion rate, etc.).
- Traffic : refers to all requests from access users
- Hash factor: It can be understood as the uuid of the user who accesses the experiment, that is, a unique identifier that can identify a certain traffic user.
- Hash algorithm: Itan inputof any length into a fixed-length output through a hash algorithm.It is a method of creating a small digital "fingerprint" from any file. Like fingerprints, hashing algorithms use shorter information to ensure the uniqueness of files.
- Bucket position: ab testing is also called bucket testing. When a user's request hits an experiment for offloading, the offloading engine willgenerate a global fixed valueto ensure that the more random and average the distribution to each bucket is, the better, then take the value modulo 100 to obtain a specific bucket number in the range of 0-100, and one percentage point corresponds to a bucket number.
- Experimental version :The experimental version is the experimental grouping. A/B experiments are usually used to verify the effect of a new strategy. During the experiment, the selected users were randomly assigned to group A and group B. Users in group A experienced the new strategy, while users in group B still experienced the old strategy. In this experimental process, Group A is the experimental group, and Group B is the control group. There are also experiments consisting of multiple experimental groups and a control group, and they jointly carry 100% of the traffic requests.
How to generate user bucket number
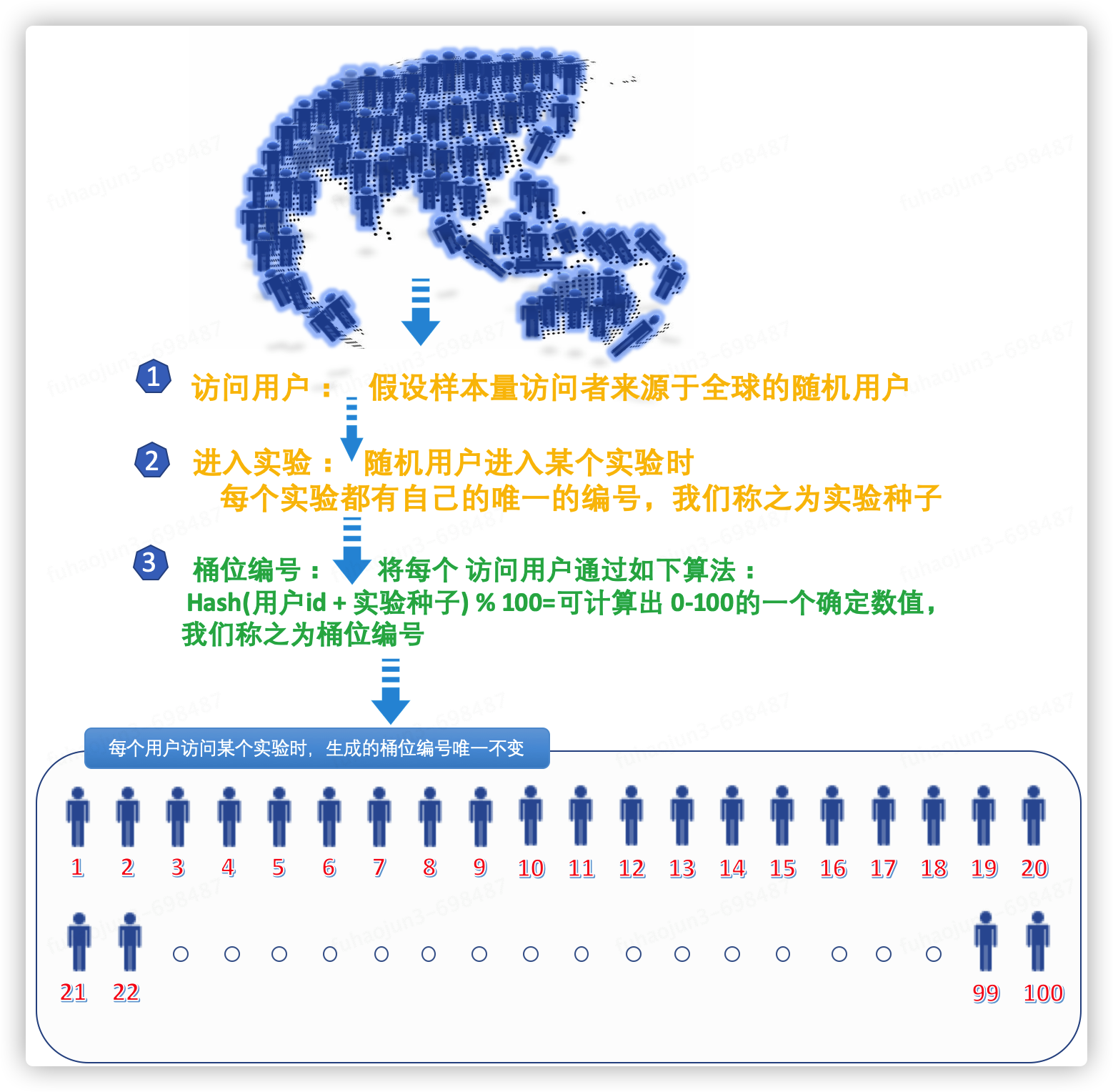
As shown in the figure above, everyone now knows that a user will have a unique and fixed number when accessing an experiment.
In order to better explain its meaning, assume that we have 26 traffic users, namely 26 users in AZ:
{A , B , C , D , E , F , G , H , I , J , K , L , M , N , O , P , Q , R , S , T , U , V , W , X , Y , Z }
When they accessed Experiment X , they generated the following experiment number through Hash (uid + Experiment
A_11,B_9,C_12,D_10,E_7,F_9,G_24,H_22,I_18,J_8,K_21,L_15,M_1,N_4,O_76,P_33,Q_40,
R_5,S_12,T_80,U_67,V_25,W_33,X_49,Y_87,Z_100

When they accessed experiment Y , they generated the following experiment number through Hash (uid + experiment X seed) (the naming rule is: user x_bucket number):
A_25,B_17,C_19,D_2,E_1,F_18,G_19,H_22,I_12,J_2,K_22,L_14,M_4,N_16,O_28,P_30,
Q_92,R_93,S_8,T_55,U_18,V_100,W_1,X_100,Y_50,Z_36
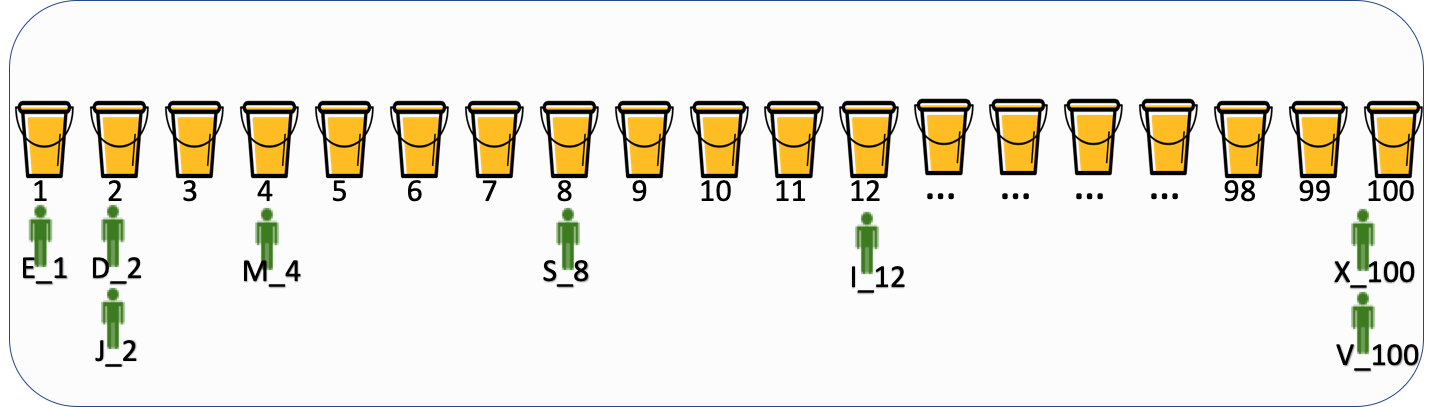
Through the above case description, when random traffic users access the experiment, the bucket numbers generated by some users will be the same, and then they will enter the same group in the experiment.
The relationship between experimental version and bucket position
One bucket number represents one percent of the total traffic (100%).
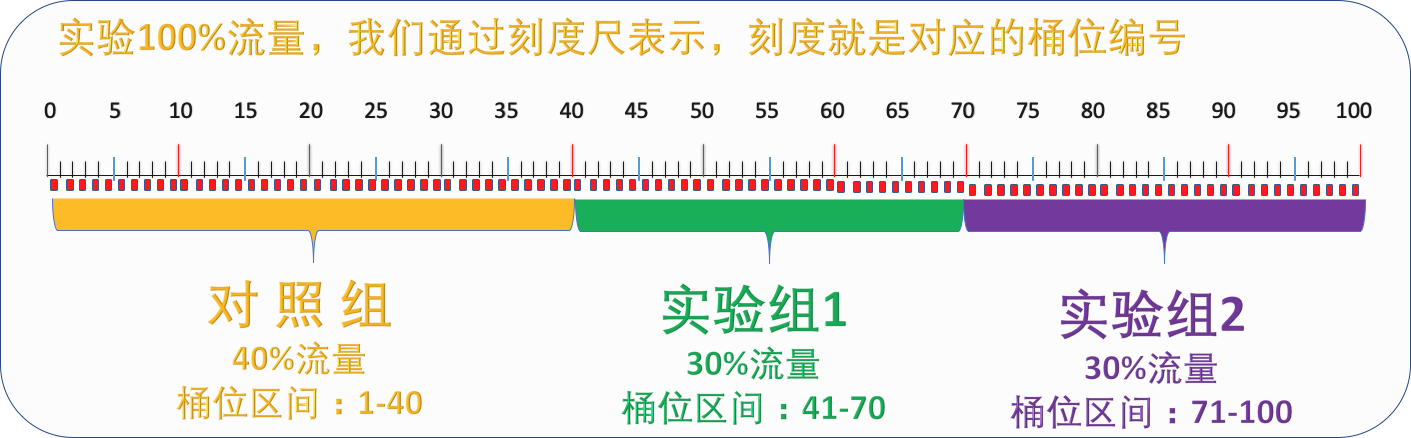
Experimental triage demonstration
Suppose we have three versions of an experiment, that is, three groups, namely experimental group 1 = VA, experimental group 2 = VB, and control group = VC.
The initial grouping ratio is: VA=10%, VB=10%, VC=80%
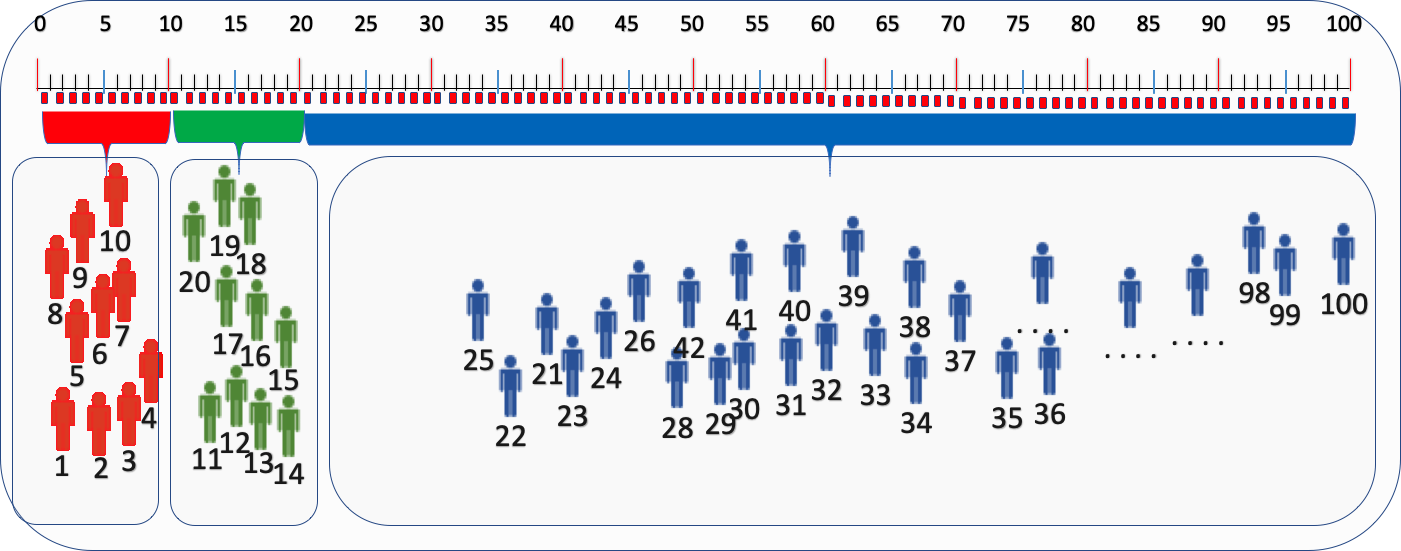
Next, we need to expand the traffic of the experimental group. The traffic is: VA=20%, VB=20%, VC=60%

This kind of diversion after expansion is OK from the perspective of diversion, but careful students may find that the users who previously entered experimental group 2 with bucket numbers 11-20 actually... actually after the expansion of the experimental group ...are assigned to experimental group 1. In this way, users jump to groups. If the scale continues to expand, there will always be such problems: users who have entered experimental group 2 will be assigned to experimental group 1 after expansion.
Every time there is the problem of user pollution in the experimental group, but the operation colleagues do not know the back-end allocation logic every time they adjust the ratio. They will take it for granted that the traffic allocation is OK. This allocation method will cause data analysis problems and user experience problems . , it is possible that users in other groups have been polluted after the proportion adjustment. Such a result is unacceptable in business.
So... what is the actual best allocation for this situation? Keep reading.
Correct diversion renderings

As shown in the rendering above:
The VA version has been expanded from the original 10% to 20%. The correct distribution is:
The new 10% traffic comes from the traffic users of the control group VC, that is, the bucket position range is 21-30.
After expansion, 20% of VA's traffic is divided into two bucket ranges: 1-10 and 21-30.
The VB version has been expanded from the original 10% to 20%. The correct distribution is:
The new 10% traffic comes from the traffic users of the control group VC, that is, the bucket range is 31-40.
After expansion, 20% of VB's traffic is divided into two bucket ranges: 11-20 and 31-40.
After this kind of expansion, there will be no group jumping among traffic users as before, that is, it is guaranteed that which version the original users enter after the expansion will still be the previous version.
We call this kind of offload optimization: traffic protection , which is the function we focus on in this article.
Why do traffic protection:
Answer: During the experiment iteration, increasing or decreasing versions and adjusting the ratio are the most frequent operations. At this time, the platform adopts the [Traffic Protection] function, that is, each modification first identifies the version with a reduced ratio, and splits the traffic from the version with a reduced ratio. Gives an increased scale version. Isolate traffic to the maximum extent and reduce mutual contamination between experimental groups;
Introducing traffic protection function
AB diversion urgently needs to solve this unscientific traffic adjustment problem. After upgrading the [traffic protection] function, let’s look at the derivation process of the traffic iteration of a set of experimental versions as follows (red represents group A, blue represents group B, green represents group C Group)

After many adjustments, each experiment minimizes the changes in its own range, ensuring the retention of its own users and reducing the impact on experimental indicators.
Traffic protection animation deduction
You can directly enjoy: the deduction of the proportion adjustment of the four versions ( you can pay attention to the changes in the color blocks of each version )

As can be seen from the above example, after multiple traffic adjustments, the interval distribution of each experiment will become more complicated. However, from the user's perspective, he only needs to care about the traffic ratio of each experiment, not the traffic ratio of each experiment. You need to care about the interval distribution of the underlying experimental traffic (this is a black box for him), so it will not increase the difficulty of user operations .
Traffic protection distribution rules
- Group version scaling adjustments: Compare data before and after version modifications. Identify three change groups in order: new, decreased, and unchanged proportions
- Split the buckets of the reduced version group: Split the reduced group version bucket range from the rightmost side and match until the bucket range segments meet the reduced floating ratio.
- Sort and move the split bucket ranges: Sort the split bucket ranges of the reduction group from left to right, and assign them to the new versions in turn.
- Sorting and merging the buckets after version changes: All versions after allocation are sorted by bucket intervals, and adjacent bucket intervals are merged.
Microsoft launches new "Windows App" .NET 8 officially GA, the latest LTS version Xiaomi officially announced that Xiaomi Vela is fully open source, and the underlying kernel is NuttX Alibaba Cloud 11.12 The cause of the failure is exposed: Access Key Service (Access Key) exception Vite 5 officially released GitHub report : TypeScript replaces Java and becomes the third most popular language Offering a reward of hundreds of thousands of dollars to rewrite Prettier in Rust Asking the open source author "Is the project still alive?" Very rude and disrespectful Bytedance: Using AI to automatically tune Linux kernel parameter operators Magic operation: disconnect the network in the background, deactivate the broadband account, and force the user to change the optical modemAuthor: Jingdong Technology Fu Haojun
Source: JD Cloud Developer Community Please indicate the source when reprinting