1. Background
VGG is a common extremely deep convolutional network used for large-scale image recognition.
Here we mainly introduce the training and prediction of VGG network prediction on the ImageNet data set.
2. Introduction to ImageNet image data set
ImageNet contains 145W three-channel color image data sets of 224*224 pixels, and the images are divided into 1000 categories. Among them, there are 130,000 training sets, 5,000 verification sets, and 10,000 test sets.
Data loading and preprocessing:
3. VGG network
3.1 Network definition
from keras.models import Sequential
from keras.layers.convolutional import Conv2D, MaxPooling2D, ZeroPadding2D
from keras.layers.core import Activation, Flatten, Dense, Dropout
from keras.datasets import cifar10
from keras.utils import np_utils
from keras.optimizers import SGD, RMSprop
import cv2
import numpy as np
NB_EPOCH = 5
BATCH_SIZE = 128
VALIDATION_SPLIT = 0.2
# IMG_ROWS, IMG_COLS = 224, 224
IMG_ROWS, IMG_COLS = 32, 32
IMG_CHANNELS = 3
INPUT_SHAPE = (IMG_ROWS, IMG_COLS, IMG_CHANNELS) # 注意顺序
NB_CLASSES = 1000
class VGGNet:
@staticmethod
def build(input_shape, classes, weights_path=None):
model = Sequential()
model.add(ZeroPadding2D((1, 1), input_shape=input_shape))
model.add(Conv2D(64, kernel_size=3, activation='relu'))
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(64, kernel_size=3, activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(128, kernel_size=3, activation='relu'))
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(128, kernel_size=3, activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(256, kernel_size=3, activation='relu'))
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(256, kernel_size=3, activation='relu'))
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(256, kernel_size=3, activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(512, kernel_size=3, activation='relu'))
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(512, kernel_size=3, activation='relu'))
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(512, kernel_size=3, activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(512, kernel_size=3, activation='relu'))
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(512, kernel_size=3, activation='relu'))
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(512, kernel_size=3, activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(classes, activation='softmax'))
model.summary() # 概要汇总网络
if weights_path:
model.load_weights(weights_path)
return model3.2 Data loading
def load_and_proc_data():
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
print('X_train shape', X_train.shape)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
# 将类向量转换成二值类别矩阵
y_train = np_utils.to_categorical(y_train, NB_CLASSES)
y_test = np_utils.to_categorical(y_test, NB_CLASSES)
return X_train, X_test, y_train, y_test3.3 Model training and saving
def model_train(X_train, y_train):
OPTIMIZER = RMSprop()
model = VGGNet.build(input_shape=INPUT_SHAPE, classes=NB_CLASSES)
model.compile(loss='categorical_crossentropy', optimizer=OPTIMIZER, metrics=['accuracy'])
model.fit(X_train, y_train, batch_size=BATCH_SIZE, epochs=NB_EPOCH, verbose=0, validation_split=VALIDATION_SPLIT)
return model
def model_save(model):
# 保存网络结构
model_json = model.to_json()
with open('cifar10_architecture.json', 'w') as f:
f.write(model_json)
# 保存网络权重
model.save_weights('cifar10_weights.h5', overwrite=True)
3.4 Model evaluation and prediction
def model_evaluate(model, X_test, y_test):
score = model.evaluate(X_test, y_test, batch_size=BATCH_SIZE, verbose=1)
print('Test score: ', score[0])
print('Test acc: ', score[1])
def model_predict():
model = VGGNet().build(INPUT_SHAPE, NB_CLASSES, 'vgg16_weights.h5')
sgd = SGD()
model.compile(loss='categorical_crossentropy', optimizer=sgd)
img = cv2.imread('tain.png')
im = cv2.resize(img, (224, 224)).astype(np.float32)
im = im.transpose((2, 0, 1))
im = np.expand_dims(im, axis=0)
out = model.predict(im)
print(np.argmax(out))3.5 Testing
if __name__ == '__main__':
X_train, X_test, y_train, y_test = load_and_proc_data()
model = model_train(X_train, y_train)
# model_save(model)
model_evaluate(model, X_test, y_test)4. Use the VGG16 network that comes with keras
The models in keras are all pre-trained , and their weights are stored in ~/.keras/models/. The weights will be automatically downloaded when the model is initialized.
from keras.optimizers import SGD
from keras.applications.vgg16 import VGG16
import matplotlib.pyplot as plt
import numpy as np
import cv2
model = VGG16(weights='imagenet', include_top=True)
sgd = SGD(lr=0.1, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd)
im = cv2.resize(cv2.imread('tain.png'), (224, 224))
im = np.expand_dims(im, axis=0)
out = model.predict(im)
plt.plot(out.ravel())
plt.show()
print(np.argmax(out))
# 820 蒸汽火车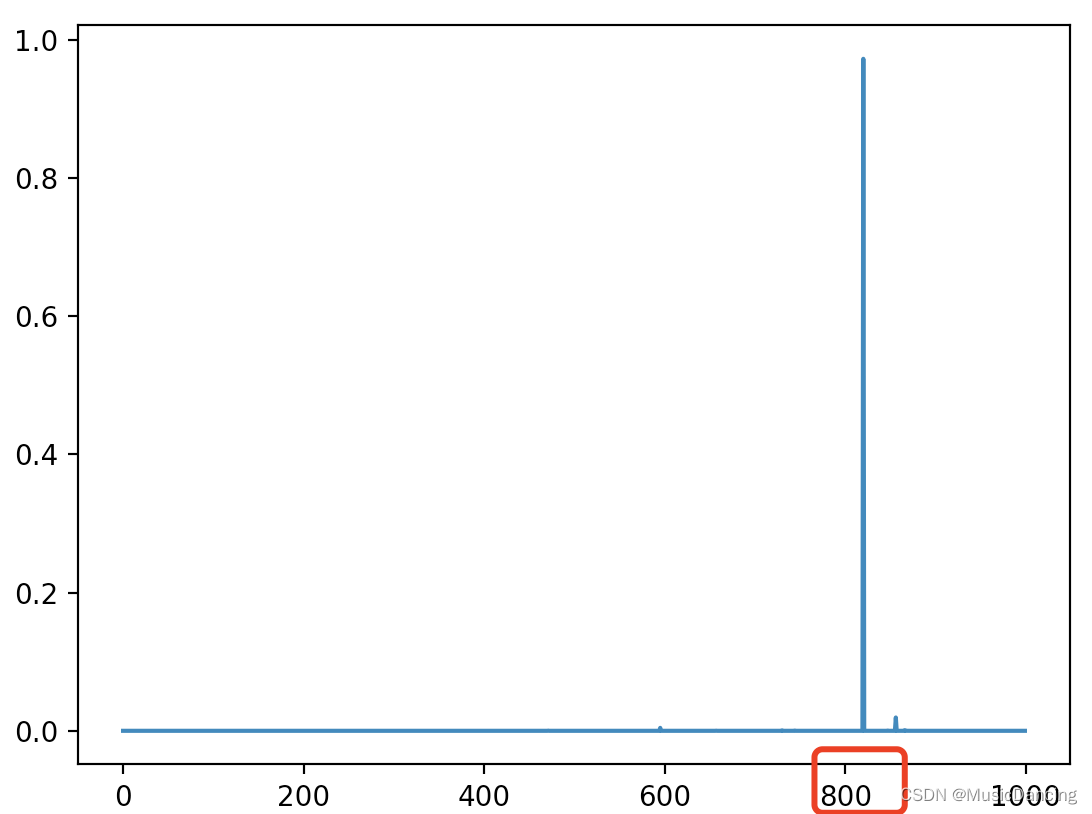
5. Extract features from specific network layers of deep learning models
Deep learning models are naturally reusable : an image classification or speech recognition model trained on large-scale data can be reused on another very different problem with only limited changes. Especially in the field of computer vision, many pre-trained models are now publicly available for download and reused on other problems to improve performance on small data sets.
5.1 Why extract features from the intermediate network layer of DCNN?
1. Each layer of the network learns to identify those features necessary for the final classification ;
2. The low-level network layer recognizes sequential features such as color and boundaries;
3. The advanced network layer combines these sequential features of the lower layers into higher sequential features , such as shapes or objects;
Therefore, the middle network layer has the ability to extract important features from the image, which may be beneficial for different classifications.
5.2 What are the benefits of feature extraction?
1. Can rely on large-scale publicly available training and transfer learning to new areas;
2. Can save time for large and time-consuming training;
3. Even if there are not enough training examples in the field, a reasonable solution can be provided (with a good initial network model).
5.3 Feature extraction from specific network layers of the VGG-16 network
from keras.models import Model
from keras.preprocessing import image
from keras.applications.vgg16 import VGG16, preprocess_input
from keras.optimizers import SGD
import numpy as np
import cv2
# 加载预训练好的VGG16模型
base_model = VGG16(weights='imagenet', include_top=True)
for i, layer in enumerate(base_model.layers):
print(i, layer.name, layer.output_shape)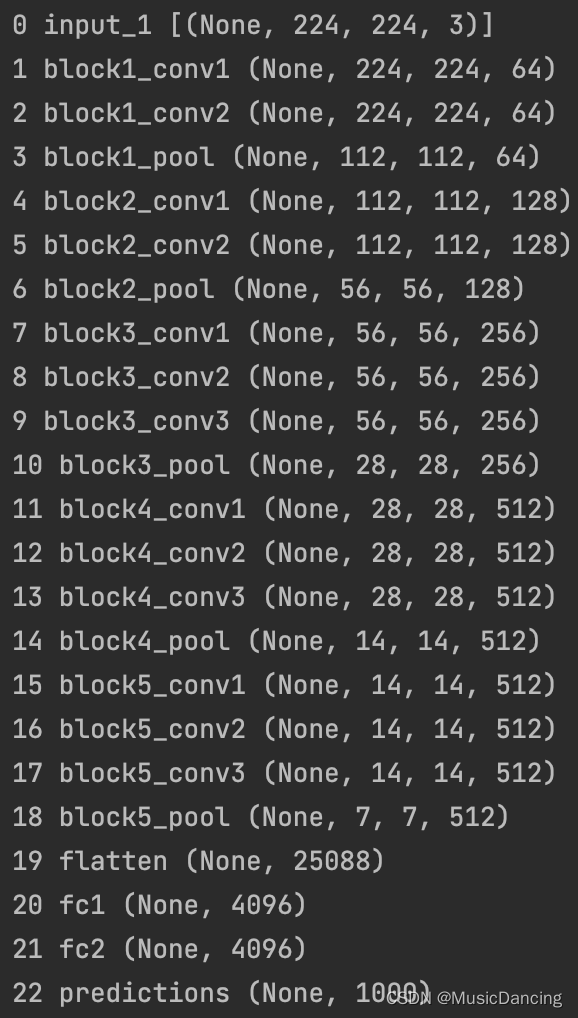
5.4 Extremely deep inception-v3 network middle layer feature extraction
Transfer learning is a very powerful deep learning technique. In those places where the data set is not large enough to train the entire CNN from scratch, a pre-trained CNN network is usually used to generate a proxy for the new task, and then the network is fine-tuned.
Inception-v3 is a deep network developed by Google.
1. Load and train the network model
Option to include top processing layer
from keras.applications.inception_v3 import InceptionV3
from keras.models import Model
from keras.preprocessing import image
from keras.layers import Dense, GlobalAveragePooling2D
# 加载预训练好的InceptionV3模型,不包括顶部的网络层,以便在新数据集上进行微调
base_model = InceptionV3(weights='imagenet', include_top=False)
for i, layer in enumerate(base_model.layers):
print(i, layer.name, layer.output_shape)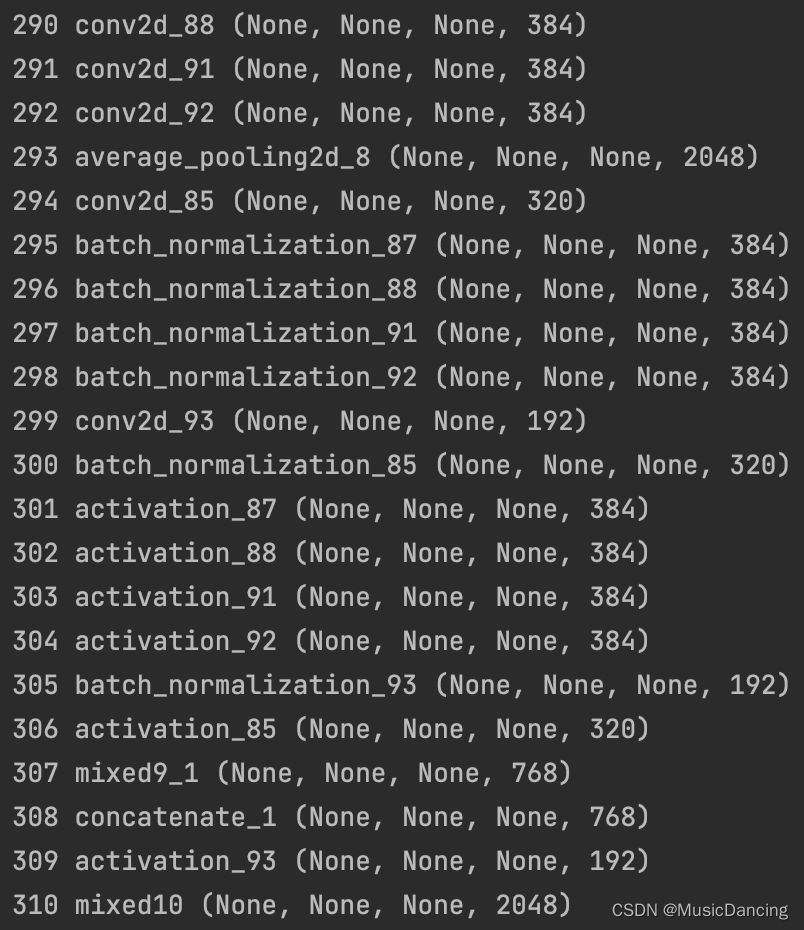
2. Freeze specific network layers and modify the network structure
# 冻结所有卷积InceptionV3层
for layer in base_model.layers:
layer.trainable = False
x = base_model.output # (n_samples, rows, cols, channels)
# shape=(None, None, None, 2048), name='mixed10/concat:0')
# 把输入转换成dense层可以处理的形状 (n_samples, channels)
x = GlobalAveragePooling2D()(x)
# shape=(None, 2048), name='global_average_pooling2d/Mean:0')
x = Dense(1024, activation='relu')(x)
# shape=(None, 1024), name='dense/Relu:0'
preds = Dense(200, activation='softmax')(x)
# shape=(None, 200), name='dense_1/Softmax:0'3. After adjusting and optimizing, recompile the model
model = Model(input=base_model.input, output=preds) # ????该句有问题
# 只冻结前172层
for layer in model.layers[:172]:
layer.trainable = False
for layer in model.layers[172:]:
layer.trainable = True
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
# 将模型在新数据集上进行训练
# model.fit_generator(...)